Ext 系列文件系统进阶:inode 映射、路径解析、挂载与软硬链接全解析
在上一篇博客中,我们掌握了 Ext 文件系统的核心框架 —— 块组结构,包括超级块、inode 表、数据块等基础组件。但文件系统的完整工作流程还涉及三个关键问题:inode 如何关联文件数据块?系统如何通过路径找到目标文件?多个分区如何协同工作?以及 Linux 中灵活的软硬链接本质是什么?本文深入剖析 inode 与数据块的映射机制、路径解析原理、分区挂载逻辑以及软硬链接的底层差异,帮你彻底打通

🎬 博主简介:

文章目录
前言:
在上一篇博客中,我们掌握了 Ext 文件系统的核心框架 —— 块组结构,包括超级块、inode 表、数据块等基础组件。但文件系统的完整工作流程还涉及三个关键问题:inode 如何关联文件数据块?系统如何通过路径找到目标文件?多个分区如何协同工作?以及 Linux 中灵活的软硬链接本质是什么?本文深入剖析 inode 与数据块的映射机制、路径解析原理、分区挂载逻辑以及软硬链接的底层差异,帮你彻底打通 Ext 文件系统的全链路工作流程。
一. inode 与数据块映射:文件属性与内容的桥梁
inode 的核心功能是关联文件属性与数据块,其内部通过i_block[EXT2_N_BLOCKS]数组(共 15 个指针)实现这一映射。这种设计兼顾了小文件的访问效率和大文件的存储需求,采用 “直接块 + 间接块” 的分层结构。
1.1 映射结构详解(EXT2 为例)
i_block数组的 15 个指针分为四类,各司其职:
12 个直接块指针(i_block [0]~i_block [11]):直接指向存储文件内容的数据块。
适用场景:小文件(如 4KB 块大小的文件,12 个直接块可存储 48KB 数据)。
优势:无需间接查找,一次 IO 即可访问数据,效率最高。1 个一级间接块指针(i_block [12]):指向一个 “间接块”,该块中存储的不是文件内容,而是多个数据块的地址(指针)。
容量计算:若块大小为 4KB,每个指针 4 字节,则一个间接块可存储 1024 个数据块地址,对应 4MB 数据(1024×4KB)。1 个二级间接块指针(i_block [13]):指向一个 “一级间接块”,该块中存储的是多个 “间接块” 的地址,每个间接块再存储数据块地址。
容量计算:1024×1024×4KB = 4GB 数据。1 个三级间接块指针(i_block [14]):指向一个 “二级间接块”,层层嵌套,支持超大文件存储。
容量计算:1024×1024×1024×4KB = 4TB 数据。
1.2 映射逻辑示意图和核心优势
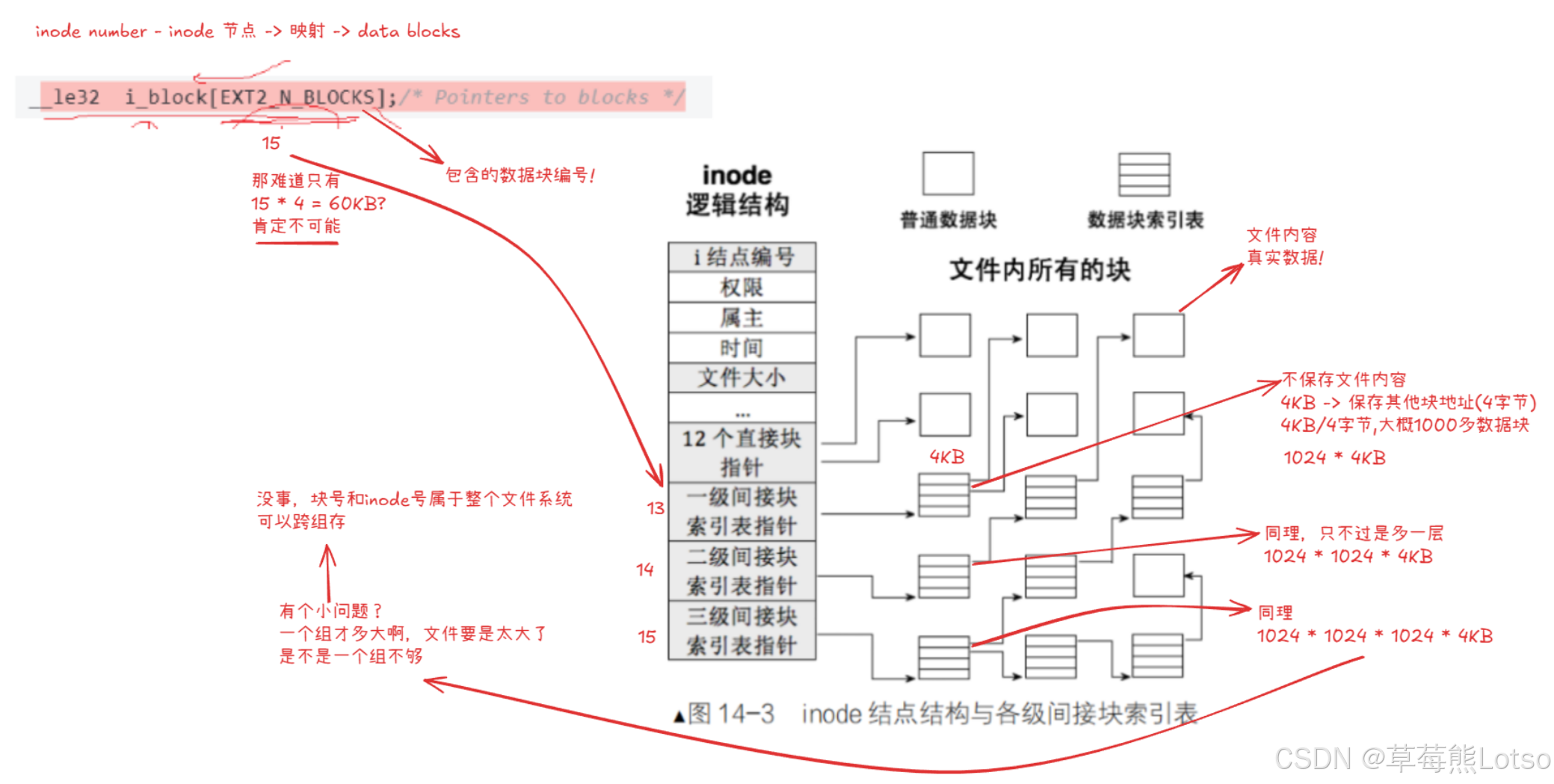
核心优势:
- 分层设计:小文件用直接块提升效率,大文件用间接块扩展容量;
- 空间紧凑:inode 仅占用 128/256 字节,通过指针间接关联,无需存储大量数据块地址。
- 还有一些问题的解答上篇博客的图中已经讲解了
二. 目录与文件名:inode 的 “索引目录”
我们访问文件时使用文件名,但 inode 中并未存储文件名 —— 文件名的存储由 “目录” 负责,而目录本质也是一种文件。
2.1 目录文件的核心作用
目录文件的属性存储在自己的 inode 中,内容则存储 “文件名→inode 号” 的映射关系(键值对)。
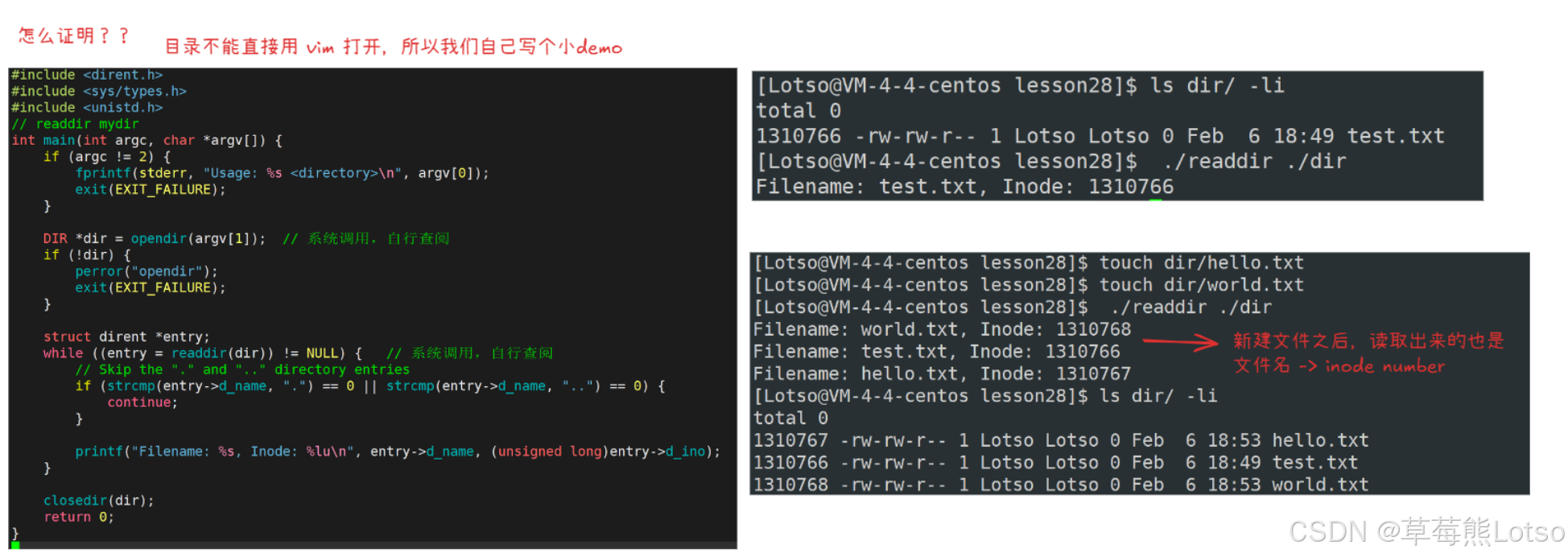
2.2 实战验证:目录与 inode 的映射
通过自定义代码读取目录内容,验证 “文件名→inode 号” 的映射关系:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <dirent.h>
#include <sys/types.h>
#include <unistd.h>
// readdir mydir
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "Usage: %s <directory>\n", argv[0]);
exit(EXIT_FAILURE);
}
DIR *dir = opendir(argv[1]); // 系统调用,自行查阅
if (!dir) {
perror("opendir");
exit(EXIT_FAILURE);
}
struct dirent *entry;
while ((entry = readdir(dir)) != NULL) { // 系统调用,自行查阅
// Skip the "." and ".." directory entries
if (strcmp(entry->d_name, ".") == 0 || strcmp(entry->d_name, "..") == 0) {
continue;
}
// 打印文件名和对应的inode号
printf("Filename: %s, Inode: %lu\n", entry->d_name, (unsigned long)entry->d_ino);
}
closedir(dir);
return 0;
}
三. 路径解析:从根目录到目标文件的 “导航”(附路径缓存)
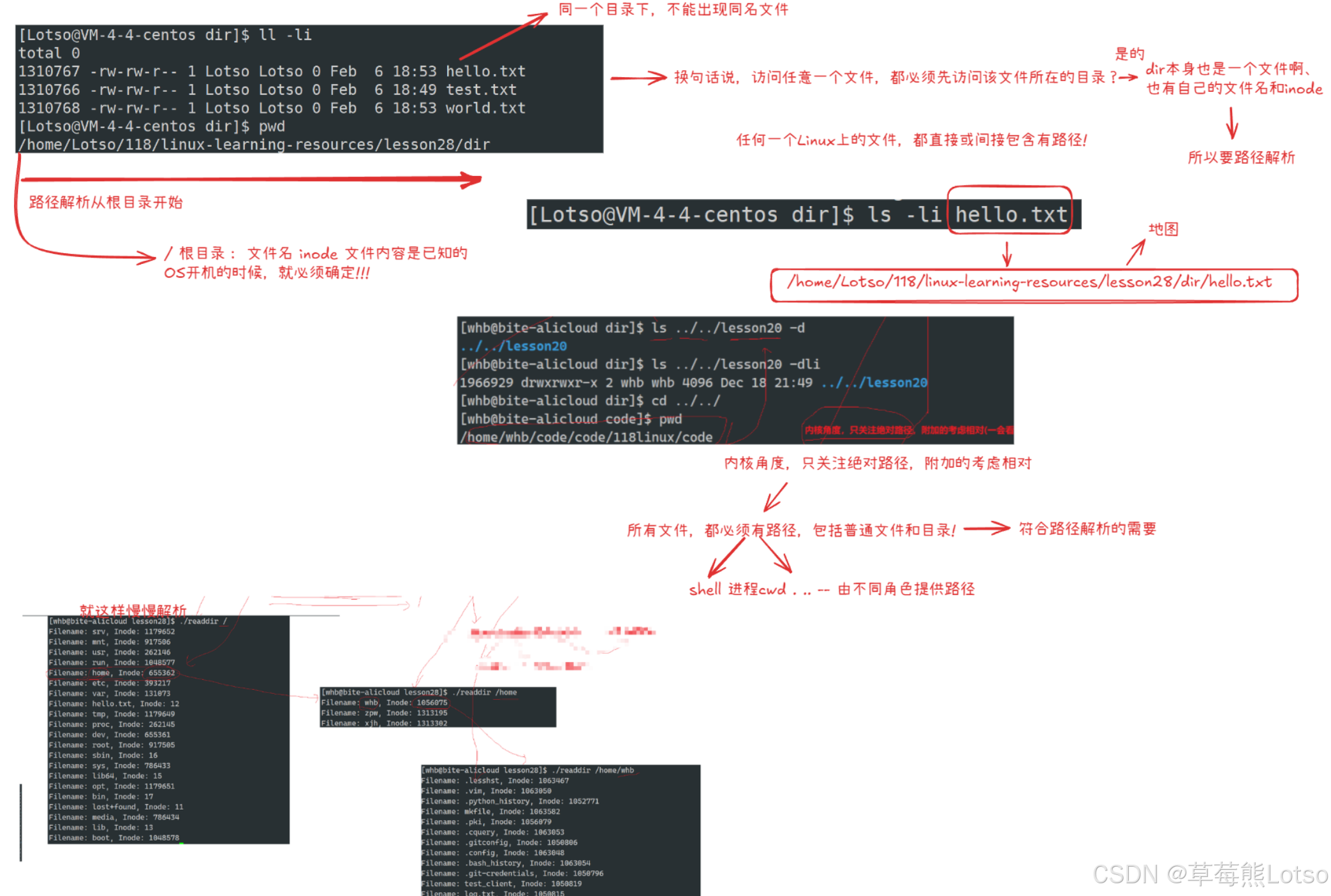
如果访问当前工作目录需要知道它的 inode,而这个 inode 又需要通过上级目录才能获得,这似乎形成了一个递归依赖。实际上,系统是通过 从根目录开始逐级解析 的方式来解决的。在 Linux 系统中,访问一个文件(包括目录文件)需要经过 路径解析 的过程。
3.1 路径解析的完整流程
当我们输入路径(如/home/Lotso/test.c)访问文件时,系统需要通过 “路径解析” 找到目标文件的 inode,本质是一个从根目录开始的递归查找过程。
- 以
/home/Lotso/test.c为例:- 定位根目录:根目录(/)的 inode 号是固定的(通常为 2),系统开机后直接加载其 inode;
- 解析第一个目录(home):打开根目录的数据块,查找 “home” 对应的 inode 号(假设为 786433);
- 解析第二个目录(Lotso):通过 inode 号 786433 找到 “home” 的 inode,进而找到其数据块,查找 “Lotso” 对应的 inode 号(假设为 1596260);
- 解析目标文件(test.c):通过 inode 号 1596260 找到 “Lotso” 的 inode 和数据块,查找 “test.c” 对应的 inode 号(1052007);
- 访问目标文件:通过 inode 号 1052007 获取文件属性和数据块地址,完成读写操作。
❓️问题引入:
- 问题1:Linux磁盘中,存在真正的目录吗?
答案:不存在,只有文件。只保存文件属性+文件内容- 问题2:访问任何文件,都要从根目录()开始进行路径解析?
答案:原则上是,但是这样太慢,所以Linux会缓存历史路径结构- 问题2:Linux目录的概念,怎么产生的?
答案:打开的文件是目录的话,由OS自己在内存中进行路径维护
所以我们接着往下来看看路径缓存吧!
3.2 路径缓存:dentry 结构体
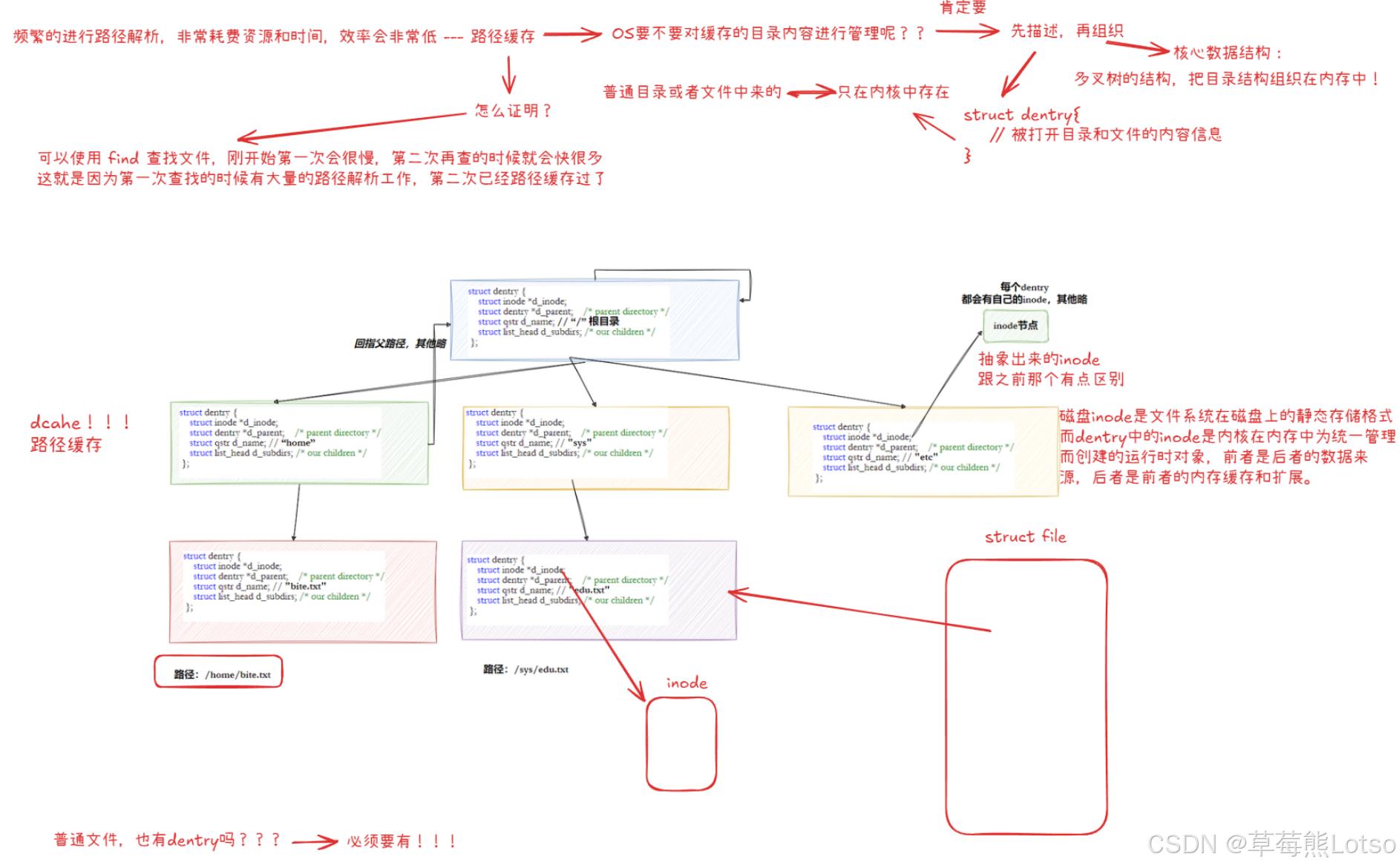
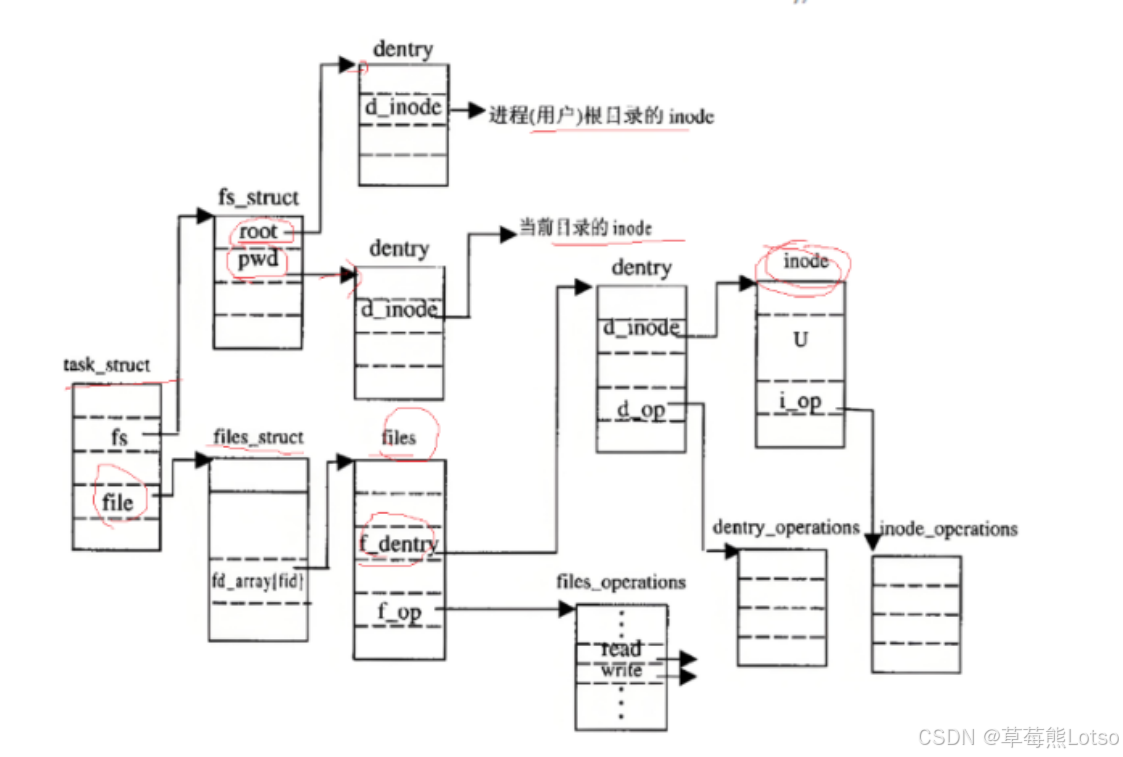
频繁的路径解析会消耗 IO 资源,Linux 内核通过struct dentry(目录项)结构体缓存已解析的路径,形成内存中的树形结构(路径缓存):
struct dentry {
struct inode *d_inode; // 关联的inode
struct dentry *d_parent; // 父目录的dentry
struct qstr d_name; // 文件名
struct list_head d_subdirs; // 子目录的dentry链表
};
核心优势:
- 后续访问同一文件时,直接从 dentry 缓存中查找,无需重复解析路径;
- dentry 通过 LRU(最近最少使用)机制淘汰不常用节点,平衡内存占用和访问效率。
- 更详细点的源码:
struct dentry {
atomic_t d_count; /* 引用计数 */
unsigned int d_flags; /* 由 d_lock 保护 */
spinlock_t d_lock; /* 每个 dentry 的锁 */
struct inode *d_inode; /* 对应的 inode,NULL 表示负状态 */
/* 以下三个字段由 __d_lookup 使用,放在同一缓存行 */
struct hlist_node d_hash; /* 哈希链表 */
struct dentry *d_parent; /* 父目录 */
struct qstr d_name; /* 目录项名称 */
struct list_head d_lru; /* LRU 链表 */
union {
struct list_head d_child; /* 父目录的子项链表 */
struct rcu_head d_rcu; /* RCU 机制 */
} d_u;
struct list_head d_subdirs; /* 子目录项链表 */
struct list_head d_alias; /* inode 别名链表 */
unsigned long d_time; /* 用于重新验证 */
struct dentry_operations *d_op; /* dentry 操作函数表 */
struct super_block *d_sb; /* 所属超级块 */
void *d_fsdata; /* 文件系统私有数据 */
#ifdef CONFIG_PROFILING
struct dcookie_struct *d_cookie; /* 用于 profiling 的 cookie */
#endif
int d_mounted; /* 是否挂载点 */
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* 短文件名内联存储 */
};
注意:
- 每个文件其实都要有对应的dentry结构,包括普通文件。这样所有被打开的文件,就可以在内存中形成整个树形结构
- 整个树形节点也同时会隶属于LRU(Least Recently Used,最近最少使用)结构中,进行节点淘汰
- 整个树形节点也同时会隶属于Hash,方便快速查找
- 更重要的是,这个树形结构,整体构成了Linux的路径缓存结构,打开访问任何文件,都在先在这棵树下根据路径进行查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry结构,缓存新路径
- 和之前学过的一些知识串联起来

四. 分区挂载:多个文件系统的 “统一入口”
inode 号是分区级唯一的,无法跨分区识别。Linux 通过 “挂载” 机制将多个分区(文件系统)整合到统一的目录树中,实现跨分区文件访问。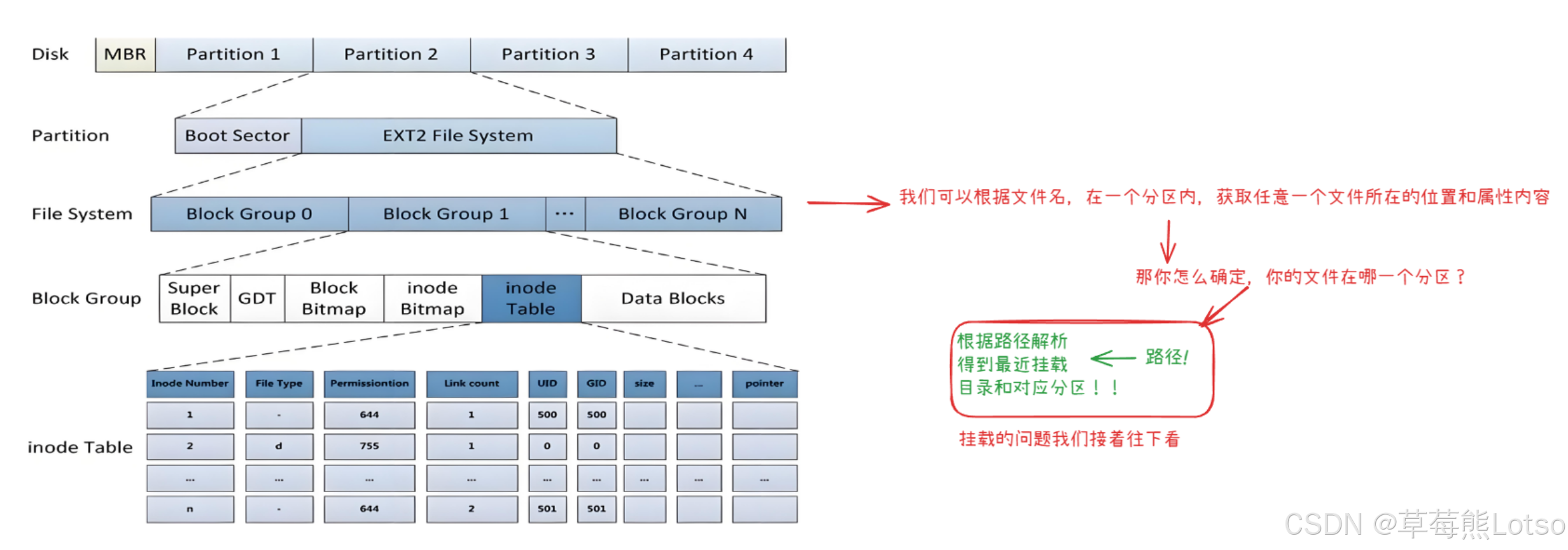
4.1 挂载的核心概念
- 挂载点:一个空目录(如
/mnt/mydisk),作为分区的 “访问入口”; - 挂载本质:将分区的文件系统与挂载点目录关联,使得访问挂载点目录时,实际访问的是该分区的文件系统;
- 关键结论:通过路径前缀即可判断文件所在分区(如
/mnt/mydisk/test.txt的前缀/mnt/mydisk对应挂载的分区)。

4.2 实战:模拟分区挂载与卸载
- 创建虚拟分区文件(模拟物理分区)
# 创建5MB的虚拟磁盘文件
dd if=/dev/zero of=disk.img bs=1M count=5
# 格式化为ext4文件系统
mkfs.ext4 disk.img
- 创建挂载点并挂载
# 创建挂载点目录
mkdir /mnt/mydisk
# 挂载虚拟分区(ext4格式)
sudo mount -t ext4 ./disk.img /mnt/mydisk
- 验证挂载
# 查看挂载情况
df -h
运行之后可以看到多出来的这个虚拟分区:
Filesystem Size Used Avail Use% Mounted on
/dev/loop0 4.9M 24K 4.5M 1% /mnt/mydisk
/dev/loop0:循环设备,将disk.img文件模拟为块设备;- 此时访问
/mnt/mydisk,实际操作的是disk.img中的 ext4 文件系统。
- 卸载分区
sudo umount /mnt/mydisk
实际演示的跟示例的目录不太一样,但是整体思路一致: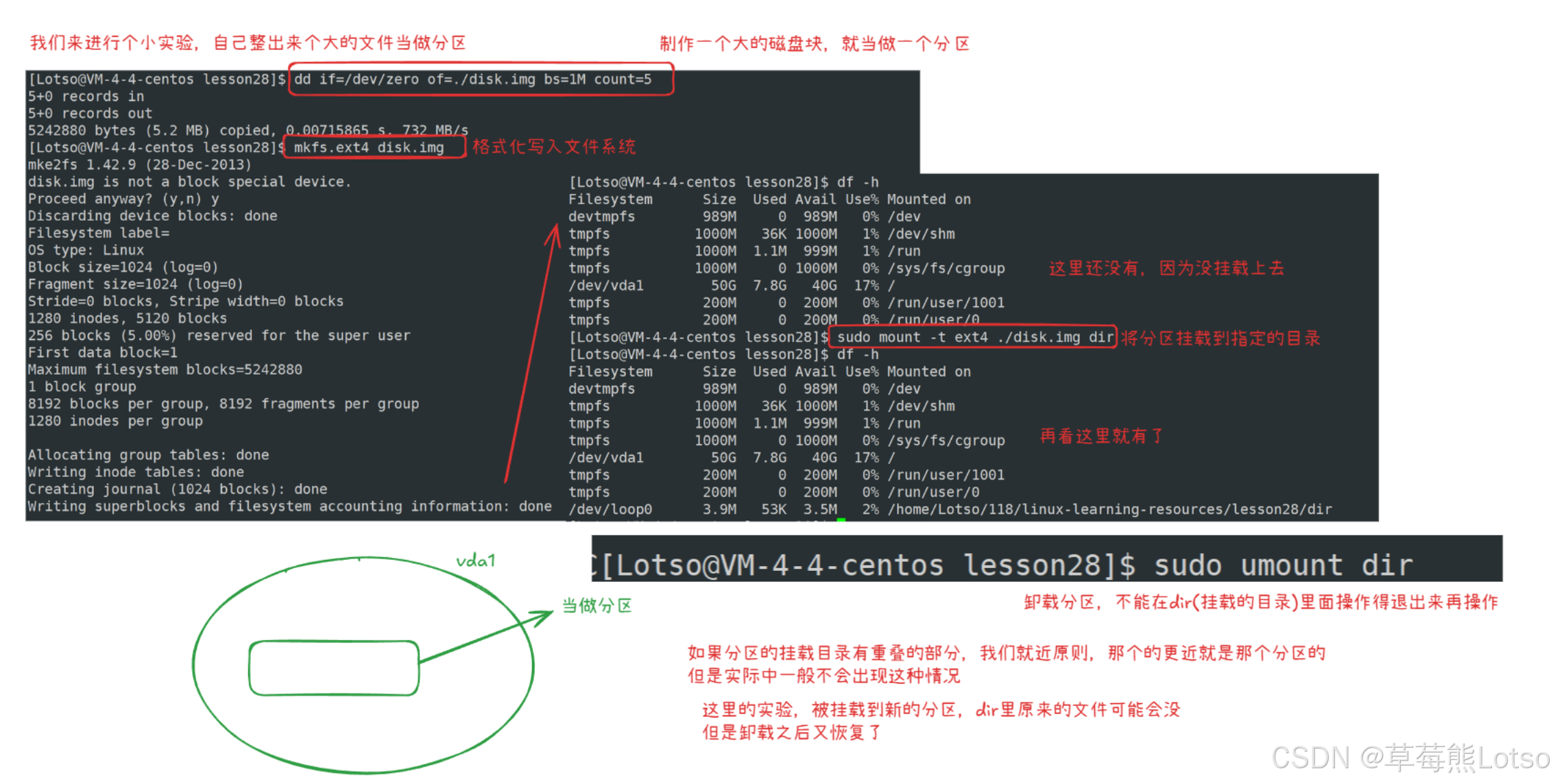
✅️结论:
- 分区写入文件系统,无法直接使用,需要和指定的目录关联,进行挂载才能使用。
- 所以,可以根据访问目标文件的 “路径前缀” 准确判断我在哪一个分区。(理解到这个层面)
4.3 挂载的核心原理
挂载后,系统会在 dentry 缓存中建立挂载点目录与分区根目录的关联:当访问/mnt/mydisk时,系统会自动跳转到该分区的根目录 inode,后续路径解析在该分区内进行。
五. 文件系统总结:理清思路
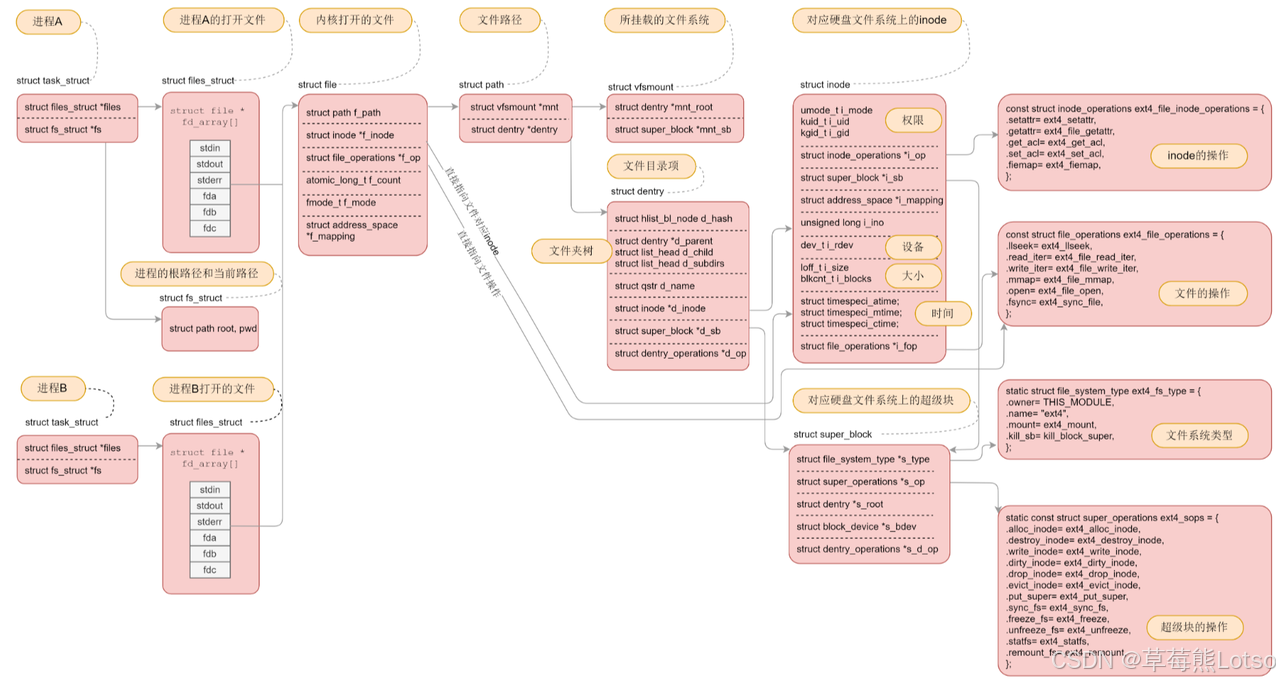
文件系统是操作系统用于管理磁盘数据的完整解决方案,它由磁盘上的静态结构和内存中的动态管理机制协同构成,并通过文件描述符向普通用户提供统一、简洁的访问入口。
具体可以理解为三个层次的整合:
- 磁盘层:静态的“仓库设计”
磁盘上存放着文件系统的“蓝图”与“账本”,如超级块(记录文件系统整体信息)、位图(管理空闲块与inode)、inode表(存储文件元数据)和数据块(存放实际内容)等等。这一层定义了数据的组织规则和存储位置,如同一个设计好的仓库货架系统和库存目录。 - 内核层:动态的“运营管理”
操作系统将关键的磁盘结构(如超级块、常用inode、目录项dentry)加载到内存中,并建立更高效的管理结构(如页缓存、dentry缓存)。这一层负责路径解析、权限检查、缓存优化、读写调度等实时管理工作,让对磁盘的随机、低速访问,转变为对内存的快速、有序操作。 - 接口层:用户的“取货窗口”
用户程序无需关心底层细节。当打开一个文件时,内核会返回一个文件描述符(fd)。这个fd就是用户与整个文件系统交互的句柄,所有后续的读、写、定位等操作,都通过这个简单的整数标识符来完成。
因此,真正的文件系统是 “磁盘设计” + “内存管理” 共同营造的一套高效、透明、易用的数据管理生态系统,而文件描述符正是用户进入这个系统的核心通行证。
Ext 系列文件系统的工作流程可总结为 “四大核心环节”,环环相扣:
- 存储组织:通过块组划分分区,用 inode 存储属性、数据块存储内容,inode 通过分层指针映射数据块;
- 名称关联:目录文件存储 “文件名→inode 号” 映射,解决 “文件名如何找到 inode” 的问题;
- 路径导航:从根目录开始递归解析路径,通过 dentry 缓存提升效率,找到目标文件 inode;
- 跨区协同:通过挂载机制整合多个分区,软硬链接基于 inode 和目录机制实现文件共享(软硬链接下面就会讲的)。
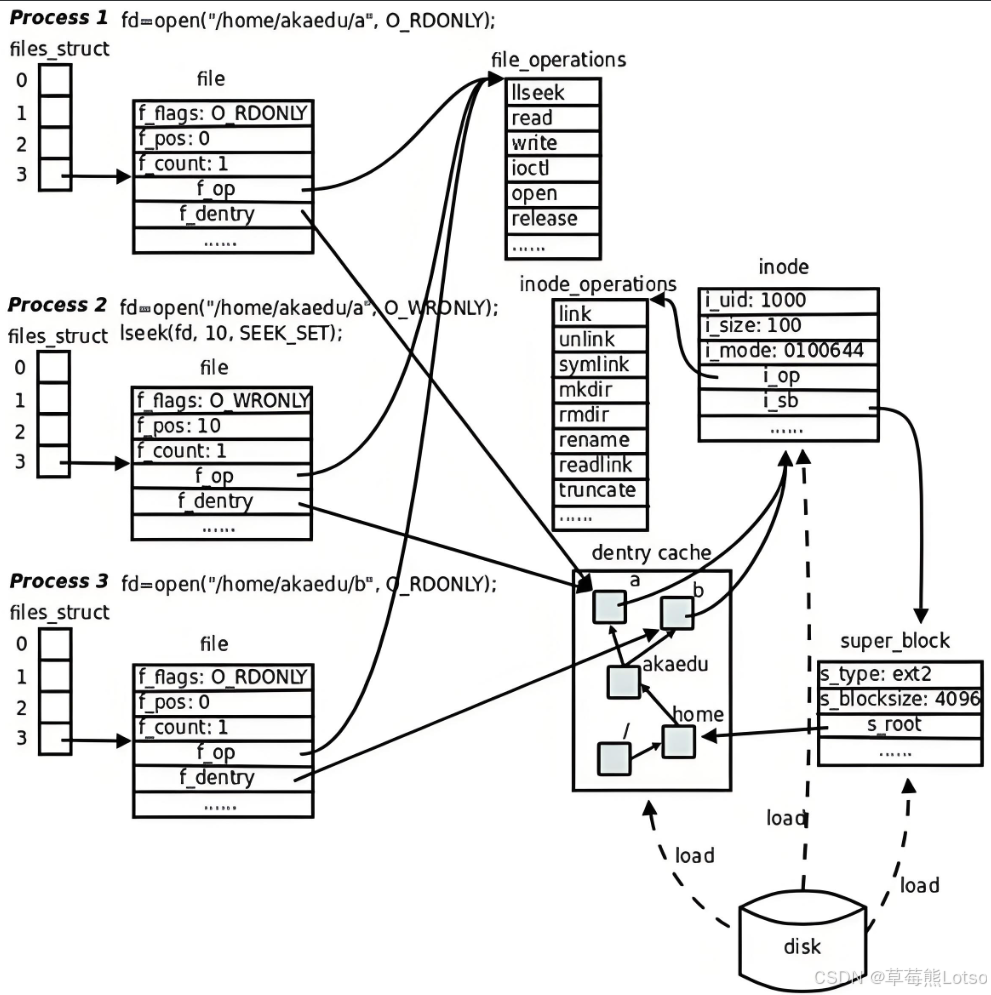
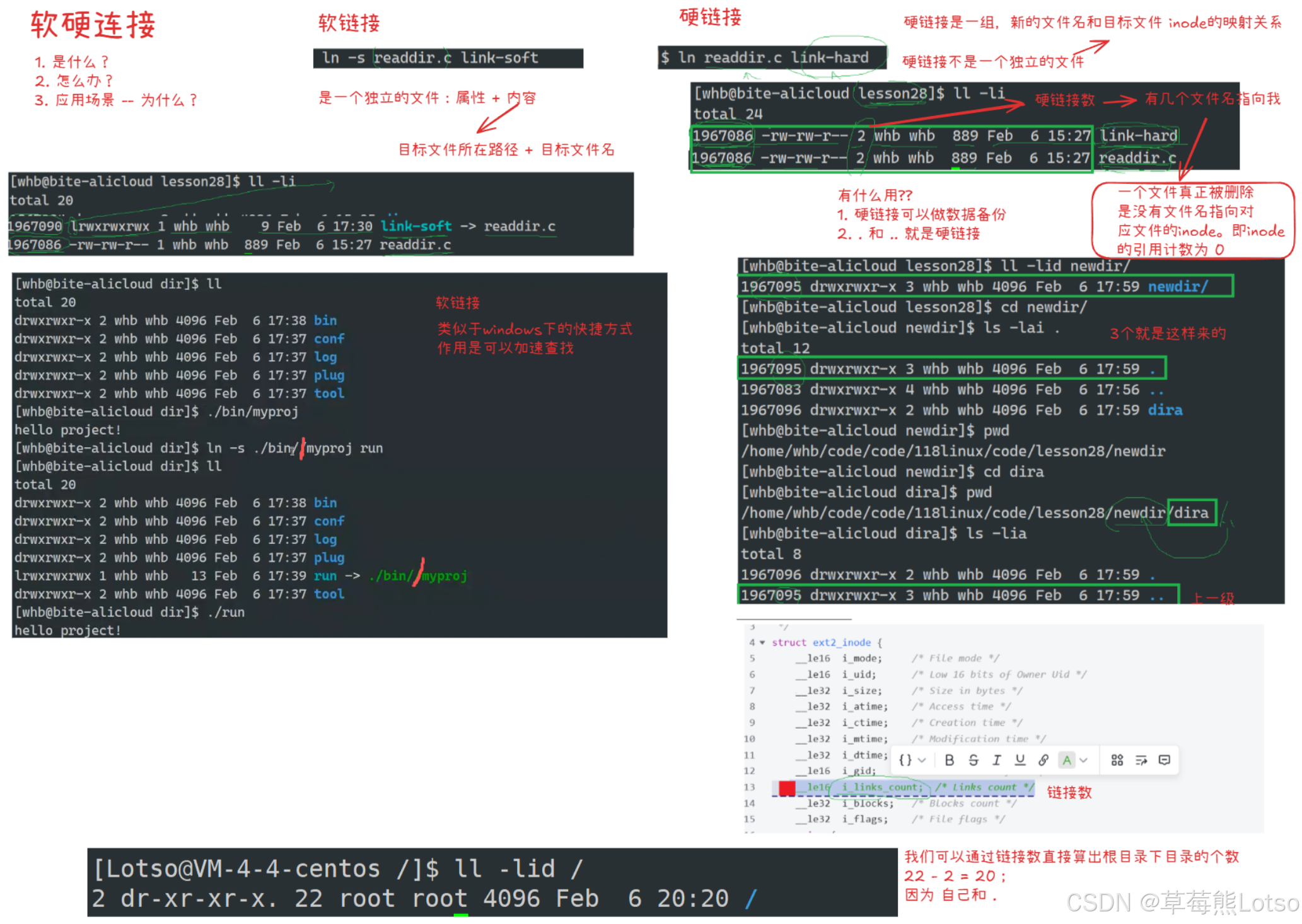
六. 软硬链接:文件的 “别名” 与 “快捷方式”
Linux 中的软硬链接是基于 inode 和目录机制实现的文件共享方式,二者本质完全不同,适用场景也各有侧重。
6.1 硬链接(Hard Link)
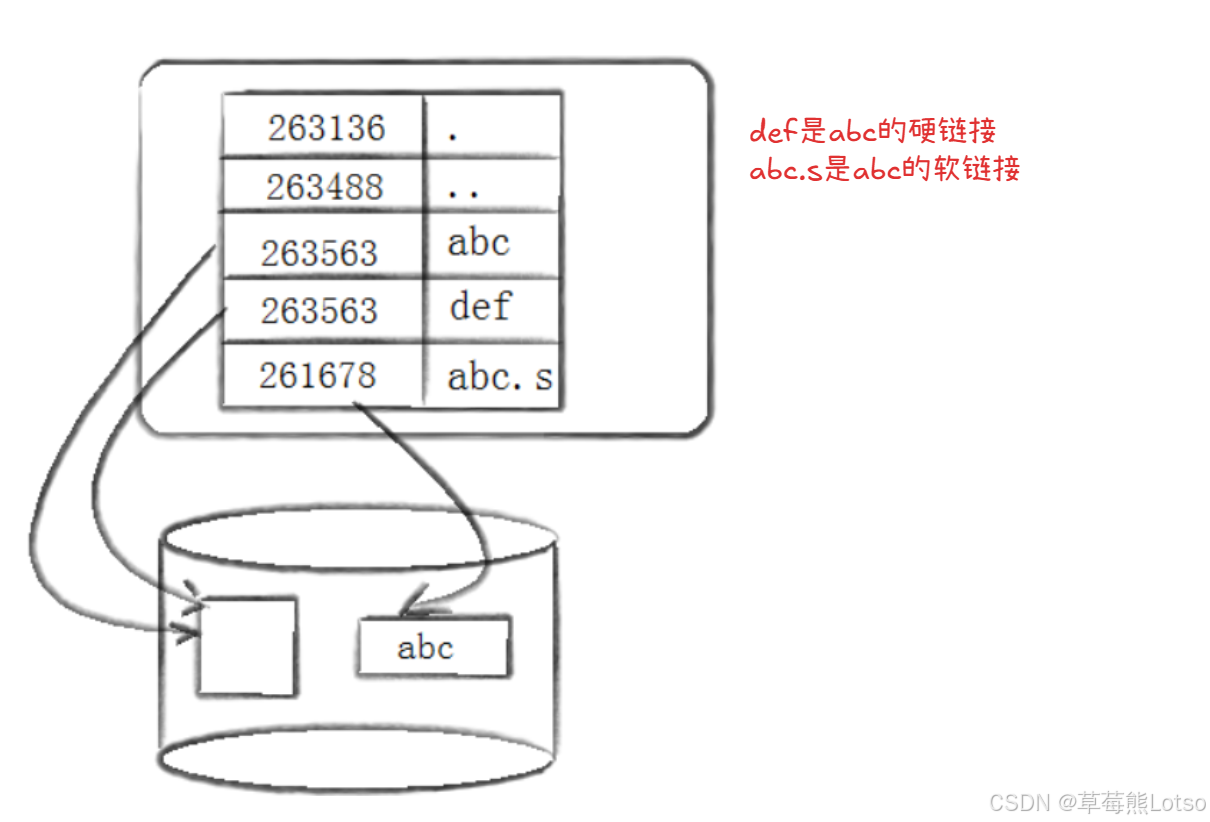
底层原理
硬链接是文件名与 inode 号的额外映射—— 在目录中添加一条 “新文件名→目标文件 inode 号” 的记录,不创建新的 inode,也不复制文件内容。
关键特性- 硬链接与目标文件共享同一个 inode,拥有相同的权限、大小、修改时间;
- 硬链接数记录在 inode 的
i_links_count字段(创建硬链接时 + 1,删除时 - 1); - 只有当硬链接数为 0 时,文件的 inode 和数据块才会被释放(真正删除);
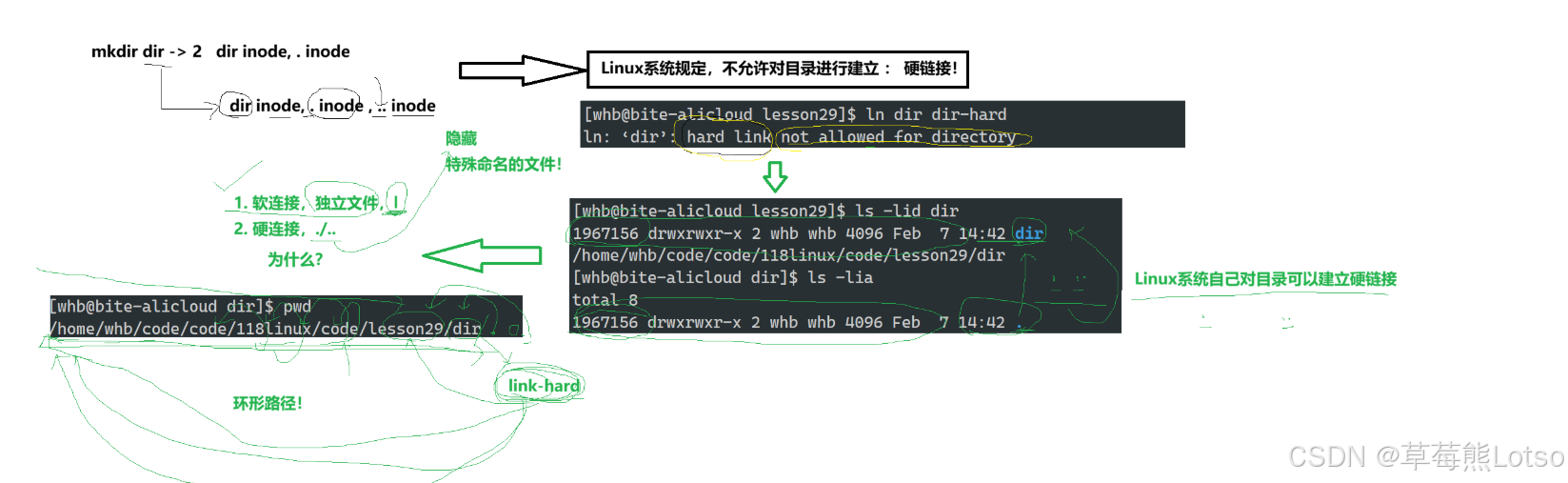
- 限制:不能跨分区创建(inode 号分区唯一),不能链接目录(避免循环引用),
. 和 ..是特例:由内核在目录创建时一次性建立,有固定语义和受控的引用关系。
实战创建与验证
# 创建源文件
touch test.txt
# 创建硬链接(ln 源文件 硬链接文件)
ln test.txt test_hard.link
# 查看inode号和硬链接数
ls -li
1052007 -rw-rw-r-- 2 whb whb 0 Oct 29 10:00 test.txt
1052007 -rw-rw-r-- 2 whb whb 0 Oct 29 10:00 test_hard.link
- 两个文件的 inode 号相同(1052007),硬链接数为 2;
- 修改任意一个文件的内容,另一个会同步变化(共享数据块)。
6.2 软链接(Symbolic Link)
底层原理
软链接是一个独立的文件—— 创建新的 inode 和数据块,数据块中存储的是 “目标文件的路径”(如./test.txt),类似 Windows 的快捷方式。
关键特性- 软链接有自己独立的 inode,与目标文件的 inode 无关;
- 软链接的大小等于目标文件路径的长度(如./test.txt长度为 9 字节);
- 目标文件删除后,软链接会失效(变为 “死链接”);
- 无限制:可跨分区创建,可链接目录。
实战创建与验证
# 创建软链接(ln -s 源文件 软链接文件)
ln -s test.txt test_soft.link
# 查看inode号和属性
ls -li
1052007 -rw-rw-r-- 2 whb whb 0 Oct 29 10:00 test.txt
1052663 lrwxrwxrwx 1 whb whb 8 Oct 29 10:01 test_soft.link -> test.txt
- 软链接的 inode 号(1052663)与源文件不同,权限为
lrwxrwxrwx(l表示软链接);- 删除
test.txt后,test_soft.link会显示为红色,访问时提示 “没有那个文件或目录”。
6.3 软硬链接对比总结
| 特性 | 硬链接 | 软链接 |
|---|---|---|
| inode 关联 | 共享目标文件 inode | 拥有独立 inode |
| 本质 | 文件名→inode 的额外映射 | 独立文件,存储目标路径 |
| 跨分区 | 不支持 | 支持 |
| 链接目录 | 不支持 | 支持 |
| 目标文件删除后 | 仍可正常访问(链接数 > 0) | 失效(死链接) |
| 权限继承 | 与目标文件相同 | 固定为 lrwxrwxrwx |
| 适用场景 | 文件备份、防止误删 | 目录快捷方式、跨分区文件访问 |
结尾:
🍓 我是草莓熊 Lotso!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!
结语:Ext 系列文件系统的工作流程可总结为 “四大核心环节”,环环相扣:存储组织,名称关联,路径导航,跨区协同。理解这一流程,就能彻底搞懂 Linux 文件系统的底层逻辑,无论是排查磁盘问题、优化 IO 性能,还是理解命令行操作的本质,都能游刃有余。
✨把这些内容吃透超牛的!放松下吧✨ ʕ˘ᴥ˘ʔ づきらど


助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 55
55 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)