深度学习实战-基于 NASNet的垃圾图像分类识别模型
本文介绍了一个基于NASNet深度学习架构的垃圾分类识别项目。项目使用包含12类15,150张垃圾图像的Kaggle数据集,通过Python和TensorFlow构建分类模型。实验过程包括数据导入、可视化、特征工程、模型构建与训练等步骤。采用迁移学习策略,利用预训练的NASNetLarge作为特征提取器,结合全连接网络和Dropout正则化。最终模型在测试集上达到99.49%的准确率,验证损失仅0

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录

1.项目背景
随着城市化进程的加快和居民消费水平的提高,生活垃圾产生量持续增长,垃圾分类处理已成为城市环境管理的重要挑战。传统的垃圾分类主要依赖人工分拣或居民自觉投放,存在效率低下、分类准确性不足、人力成本高等实际问题。特别是在垃圾回收处理环节,混合垃圾不仅降低资源回收率,还增加后端处理负担和环境风险。计算机视觉技术的发展为自动化垃圾分类提供了新的技术路径,通过图像识别技术对垃圾进行快速准确分类,能够显著提升垃圾处理效率,降低人力成本,促进资源回收利用。本项目旨在探索基于NASNet深度学习架构的垃圾图像分类方法,构建一个能够识别纸张、塑料、金属、玻璃等12类常见生活垃圾的智能分类模型,为自动化垃圾分拣系统的开发提供技术支持,助力智慧环保和循环经济发展。
2.数据集介绍
数据集概览
- 图片总数:15,150
- 来源:来源于Kaggle
- 类别:12种不同类型的家庭垃圾
- 目的:训练和评估用于自动垃圾分拣和环境人工智能应用的机器学习模型
包含的废弃物类别
| Category 类别 | Description 描述 |
|---|---|
| Paper 纸张 | Newspapers, office paper, etc. 报纸、办公纸等。 |
| Cardboard 纸板 | Boxes, packaging material 盒子,包装材料 |
| Biological Waste 生物废弃物 | Food scraps, organic material 食物残渣、有机物 |
| Metal 金属 | Cans, foil, small metal items 罐头、锡纸、小金属物品 |
| Plastic 塑料 | Bottles, containers, synthetic packaging 瓶子、容器、合成包装 |
| Green Glass 绿色玻璃 | Bottles and jars made of green-tinted glass 用绿色玻璃制成的瓶子和罐子 |
| Brown Glass 棕色玻璃 | Brown-tinted glass containers 棕色玻璃容器 |
| White Glass 白玻璃 | Clear glass items 透明玻璃产品 |
| Clothing 服装 | Fabric-based items like shirts, pants 以布料为基础的物品,如衬衫、裤子 |
| Shoes 鞋子 | Footwear of various types 各种鞋类 |
| Batteries 电池 | Household batteries (AA, AAA, etc.) 家用电池(AA、AAA 等) |
| General Trash 通用垃圾 | Mixed or non-recyclable waste 混合或不可回收的废弃物 |
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
数据准备是垃圾图像分类项目的基础,垃圾图像通常具有类别多样、背景复杂、形态各异的特点。本节主要完成环境配置、数据集下载和预处理工作,使用Kaggle Hub高效获取垃圾分类数据集,并将其组织成适合深度学习训练的格式。
# ====================== 导入必要的库 ======================
import os # 操作系统接口模块,用于文件和目录操作
import numpy as np # 数值计算库,提供高效的数组操作和数学函数
import matplotlib.pyplot as plt # 数据可视化库,用于绘制图表和图像显示
import tensorflow as tf # TensorFlow深度学习框架
# 导入机器学习评估工具
from sklearn.metrics import classification_report, confusion_matrix # 分类报告和混淆矩阵
# 导入Keras深度学习模块
from tensorflow.keras import layers # 神经网络层模块
from tensorflow.keras.models import Sequential # 顺序模型类
from tensorflow.keras.preprocessing import image_dataset_from_directory # 图像数据集加载器
from tensorflow.keras.applications import NASNetLarge # NASNetLarge预训练模型
# 导入Kaggle数据下载工具
import kagglehub # Kaggle官方数据集下载库
# ====================== 下载垃圾分类数据集 ======================
# 使用kagglehub下载最新的垃圾分类数据集
# 'hassnainzaidi/garbage-classification': Kaggle数据集标识符
path = kagglehub.dataset_download("hassnainzaidi/garbage-classification")
# ====================== 设置数据集路径 ======================
# 构建训练集、验证集、测试集的完整路径
train_dir = os.path.join(path, 'Garbage classification', 'train') # 训练集路径
val_dir = os.path.join(path, 'Garbage classification', 'val') # 验证集路径
test_dir = os.path.join(path, 'Garbage classification', 'test') # 测试集路径
# ====================== 设置图像处理参数 ======================
image_size = (224, 224) # 输入图像尺寸:224×224像素,符合NASNet标准输入
batch_size = 32 # 批次大小:平衡内存使用和训练效率
# ====================== 创建训练数据集 ======================
train_ds = image_dataset_from_directory(
train_dir, # 训练集目录路径
image_size=image_size, # 统一调整图像尺寸到224×224
batch_size=batch_size, # 每批加载32张图像
label_mode='int', # 标签模式:整数编码(适合稀疏分类交叉熵)
color_mode='rgb' # 颜色模式:RGB三通道图像
)
# ====================== 创建验证数据集 ======================
val_ds = image_dataset_from_directory(
val_dir, # 验证集目录路径
image_size=image_size, # 同样调整到224×224
batch_size=batch_size, # 批次大小32
label_mode='int', # 整数标签编码
color_mode='rgb' # RGB三通道
)
# ====================== 创建测试数据集 ======================
test_ds = image_dataset_from_directory(
test_dir, # 测试集目录路径
image_size=image_size, # 224×224标准尺寸
batch_size=batch_size, # 批次大小32
label_mode='int', # 整数标签编码
color_mode='rgb' # RGB三通道
)
# ====================== 获取类别名称 ======================
# 从训练数据集中提取类别名称列表
# 垃圾分类类别如:'cardboard', 'glass', 'metal', 'paper', 'plastic', 'trash'
classes = train_ds.class_names
4.2数据可视化

数据可视化是理解垃圾分类数据集特征的重要步骤。垃圾图像通常包含多样的形态、颜色和背景,直观检查样本图像有助于了解数据的复杂性、验证标签准确性,并为后续的模型设计和数据增强策略提供参考。本节从训练集中随机抽取一个批次,展示其中的9个样本图像及其对应的垃圾类别标签。
# ====================== 创建可视化图形窗口 ======================
# 创建15×10英寸的图形窗口,提供足够的空间显示9张图像
plt.figure(figsize=(15, 10))
# ====================== 从训练集中获取一个批次的数据 ======================
# train_ds.take(1): 从训练数据流中获取第一个批次的数据
# 返回一个包含图像张量和对应标签的元组
for image, label in train_ds.take(1):
# ================== 显示批次中的前9个样本 ==================
# 循环显示9个样本,采用3行3列的网格布局
for i in range(9):
# 创建3行3列的子图网格,当前位置为i+1
plt.subplot(3, 3, i + 1)
# 显示第i张图像
# image[i]: 第i个图像张量,形状为(224,224,3)
# .numpy(): 将TensorFlow张量转换为NumPy数组
# .astype('int'): 转换为整数类型,确保matplotlib正确显示
plt.imshow(image[i].numpy().astype('int'))
# 设置子图标题为对应的垃圾类别名称
# label[i]: 第i个图像的整数标签(0到类别数-1)
# classes[label[i]]: 通过整数索引获取可读的类别名称
plt.title(classes[label[i]])
# 关闭坐标轴显示,使图像更清晰
# 等效于plt.axis('off'),False表示关闭坐标轴
plt.axis(False)
# ====================== 显示图形 ======================
plt.show()
4.3特征工程
特征工程阶段主要实现迁移学习和数据流水线优化。垃圾分类任务面临类别多样、形态复杂、背景杂乱等挑战,使用在ImageNet上预训练的NASNet模型进行迁移学习,可以显著提升模型性能。同时,通过数据流水线优化确保训练过程中GPU的高效利用,避免I/O成为瓶颈。
# ====================== 加载NASNetLarge预训练模型 ======================
# 创建NASNetLarge基础模型,使用ImageNet预训练权重
base_model = NASNetLarge(
weights='imagenet', # 使用在ImageNet数据集上预训练的权重
include_top=False, # 不包含顶部的全连接分类层(将自定义分类层)
input_shape=(224,224,3) # 输入图像形状:224×224像素,RGB三通道
)
# ====================== 冻结基础模型权重 ======================
# 将基础模型的权重设置为不可训练(冻结)
# 在迁移学习初期,只训练自定义的分类层,保留预训练的特征提取能力
base_model.trainable = False
# ====================== 数据流水线优化配置 ======================
# 设置自动调优参数,让TensorFlow根据系统资源自动优化数据流水线
autotune = tf.data.AUTOTUNE
# ====================== 优化训练数据集流水线 ======================
# 使用prefetch方法预取数据,实现数据加载与模型训练的并行化
# buffer_size=autotune:自动确定最优的缓冲区大小
train_ds = train_ds.prefetch(buffer_size=autotune)
# ====================== 优化验证数据集流水线 ======================
val_ds = val_ds.prefetch(buffer_size=autotune)
# ====================== 优化测试数据集流水线 ======================
test_ds = test_ds.prefetch(buffer_size=autotune)4.4构建模型
本节构建基于NASNet的垃圾分类模型架构。通过组合预训练的NASNet特征提取器和自定义的分类头,创建一个适合垃圾分类任务的完整深度学习模型。模型设计考虑了垃圾图像的特点,包括复杂背景、多样形态和类别间的相似性,通过多层全连接网络和Dropout正则化来提高分类准确性和泛化能力。
# ====================== 构建顺序模型架构 ======================
# 创建Sequential顺序模型,按顺序堆叠各层
model = Sequential([
# ========== 数据预处理层 ==========
# 像素值标准化层:将0-255的像素值缩放到0-1范围
layers.Rescaling(1./255),
# 图像尺寸调整层:确保所有输入图像尺寸为224×224
# 虽然image_dataset_from_directory已调整尺寸,但这里提供双重保障
layers.Resizing(224, 224),
# ========== 特征提取层 ==========
# NASNetLarge预训练模型:提取高级视觉特征
# 输入形状自动匹配上层输出,输出特征图维度较大
base_model,
# ========== 特征聚合层 ==========
# 全局平均池化层:将特征图的空间维度平均为单个值
# 将NASNet输出的高维特征图转换为固定长度的特征向量
layers.GlobalAveragePooling2D(),
# ========== 正则化层 ==========
# Dropout层:随机丢弃30%的神经元,防止过拟合
# 这是较强的正则化,适合复杂的垃圾分类任务
layers.Dropout(0.3),
# ========== 第一全连接层 ==========
# 64个神经元的全连接层,进行特征组合和抽象
# ReLU激活函数引入非线性
layers.Dense(64, activation='relu'),
# ========== 第二全连接层 ==========
# 增加神经元到128个,提取更复杂的特征表示
layers.Dense(128, activation='relu'),
# ========== 正则化层 ==========
# 第二Dropout层:随机丢弃20%神经元
layers.Dropout(0.2),
# ========== 第三全连接层 ==========
# 256个神经元的全连接层,进一步抽象特征
layers.Dense(256, activation='relu'),
# ========== 正则化层 ==========
# 第三Dropout层:随机丢弃10%神经元
# 接近输出层,使用较小的Dropout率
layers.Dropout(0.1),
# ========== 输出层 ==========
# 分类输出层:神经元数等于垃圾类别数
# softmax激活函数输出各类别的概率分布
layers.Dense(len(classes), activation='softmax')
])
# ====================== 编译模型 ======================
# 配置模型的训练参数:优化器、损失函数和评估指标
model.compile(
# Adam优化器:自适应学习率,适合分类任务
optimizer='adam',
# 稀疏分类交叉熵损失函数:适用于整数标签的多分类任务
# 与image_dataset_from_directory的label_mode='int'配置对应
loss='sparse_categorical_crossentropy',
# 监控准确率指标
metrics=['accuracy']
)4.5训练模型
history=model.fit(train_ds,epochs=10,validation_data=val_ds)
4.6评估模型
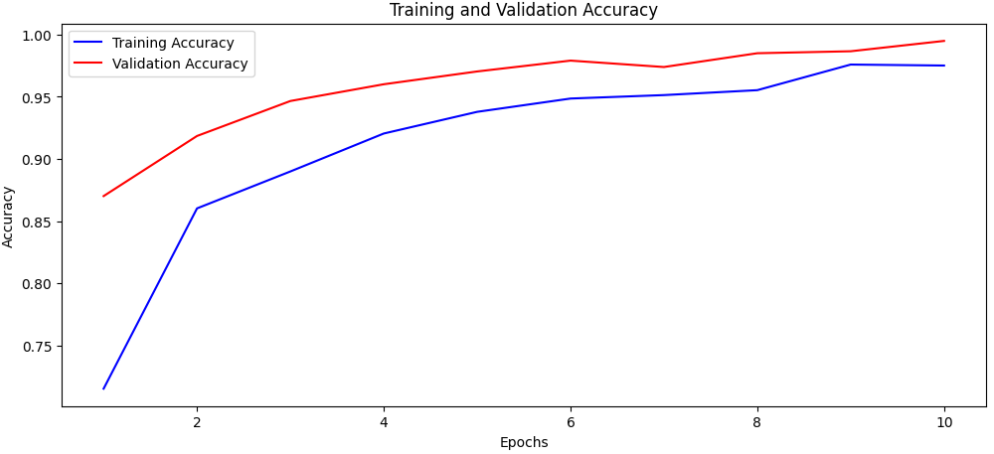
模型评估是验证垃圾分类模型性能的关键环节。通过可视化训练过程中的损失和准确率曲线,我们可以深入分析模型的学习动态、收敛情况和泛化能力。对于垃圾分类这种实际应用场景,理解模型的训练行为比单纯关注最终指标更为重要,这有助于识别过拟合、欠拟合等问题,并为模型优化提供指导。
# ====================== 提取训练历史数据 ======================
# history是model.fit()方法返回的训练历史对象,包含各epoch的指标记录
history_dict = history.history
# 提取训练损失和验证损失数据
train_loss = history_dict['loss'] # 训练集损失值历史记录
val_loss = history_dict['val_loss'] # 验证集损失值历史记录
# 提取训练准确率和验证准确率数据
train_acc = history_dict['accuracy'] # 训练集准确率历史记录
val_acc = history_dict['val_accuracy'] # 验证集准确率历史记录
# 创建epoch索引范围,从1开始到训练总轮数
epochs = range(1, len(train_loss) + 1)
# ====================== 导入可视化库 ======================
import matplotlib.pyplot as plt # 数据可视化库
# ====================== 第一部分:损失曲线可视化 ======================
# 创建12×5英寸的图形窗口,提供足够的水平空间
plt.figure(figsize=(12,5))
# 绘制训练损失曲线:蓝色实线,标注为'Training Loss'
plt.plot(epochs, train_loss, 'b-', label='Training Loss')
# 绘制验证损失曲线:红色实线,标注为'Validation Loss'
plt.plot(epochs, val_loss, 'r-', label='Validation Loss')
# 设置图表标题和坐标轴标签
plt.title('Training and Validation Loss') # 标题:训练和验证损失
plt.xlabel('Epochs') # x轴:训练轮数
plt.ylabel('Loss') # y轴:损失值
# 添加图例,自动选择最佳位置
plt.legend()
# 显示图形
plt.show()
# ====================== 第二部分:准确率曲线可视化 ======================
# 创建新的12×5英寸图形窗口
plt.figure(figsize=(12,5))
# 绘制训练准确率曲线:蓝色实线,标注为'Training Accuracy'
plt.plot(epochs, train_acc, 'b-', label='Training Accuracy')
# 绘制验证准确率曲线:红色实线,标注为'Validation Accuracy'
plt.plot(epochs, val_acc, 'r-', label='Validation Accuracy')
# 设置图表标题和坐标轴标签
plt.title('Training and Validation Accuracy') # 标题:训练和验证准确率
plt.xlabel('Epochs') # x轴:训练轮数
plt.ylabel('Accuracy') # y轴:准确率
# 添加图例
plt.legend()
# 显示图形
plt.show()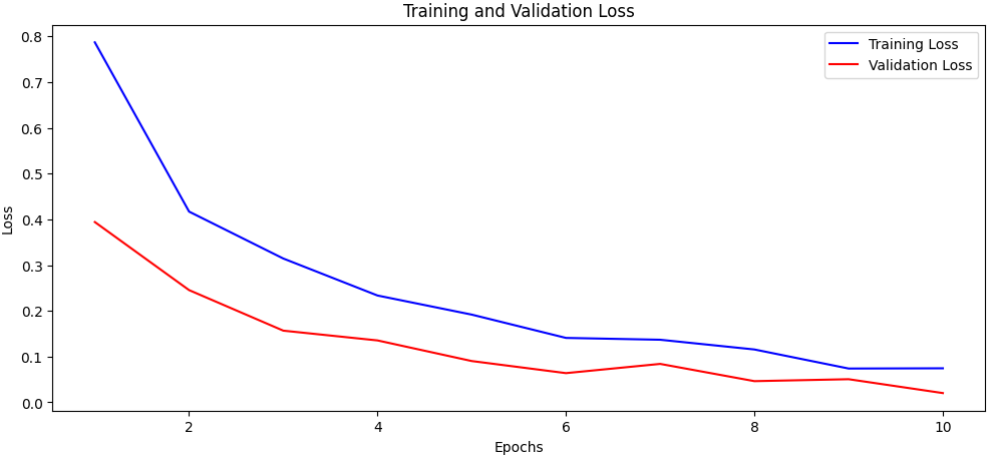
接着通过混淆矩阵深入分析模型在测试集上的具体表现。混淆矩阵是分类任务中最直观的评估工具之一,它能够清晰展示模型在各个垃圾类别上的分类情况,特别是各类别间的混淆模式。这对于理解模型的错误类型和识别分类难点具有重要意义。
# ====================== 导入可视化库 ======================
import seaborn as sns # 统计可视化库,基于matplotlib提供更美观的热力图
# ====================== 准备测试集预测数据 ======================
y_true = [] # 初始化列表,存储真实标签
y_pred = [] # 初始化列表,存储预测标签
# 遍历测试数据集中的所有批次
for image, label in test_ds:
# 使用训练好的模型对当前批次图像进行预测
# verbose=0: 不显示预测进度信息,保持输出简洁
pred = model.predict(image, verbose=0)
# 将模型输出的概率预测转换为类别标签
# np.argmax(pred, axis=1): 取每行最大概率对应的索引(类别)
predicted_labels = np.argmax(pred, axis=1)
# 将当前批次的预测标签添加到总列表中
y_pred.extend(predicted_labels)
# 将当前批次的真实标签添加到总列表中
# .numpy(): 将TensorFlow张量转换为NumPy数组
y_true.extend(label.numpy())
# 将列表转换为NumPy数组,便于后续计算
y_true = np.array(y_true)
y_pred = np.array(y_pred)
# ====================== 计算混淆矩阵 ======================
# 使用sklearn的confusion_matrix函数计算混淆矩阵
# 行表示真实类别,列表示预测类别
cm = confusion_matrix(y_true, y_pred)
# ====================== 可视化混淆矩阵 ======================
# 使用seaborn绘制热力图形式的混淆矩阵
sns.heatmap(
cm, # 混淆矩阵数据
annot=True, # 在每个单元格中显示数值
fmt="d", # 整数格式显示
cmap="Blues", # 蓝色调色板,从浅蓝到深蓝渐变
xticklabels=classes, # x轴刻度标签:预测的垃圾类别名称
yticklabels=classes # y轴刻度标签:真实的垃圾类别名称
)
# 设置坐标轴标签
plt.xlabel("Predicted Label") # x轴:预测标签
plt.ylabel("True Label") # y轴:真实标签
# 设置图表标题
plt.title("Confusion Matrix Heatmap") # 标题:混淆矩阵热力图
# 显示图形
plt.show()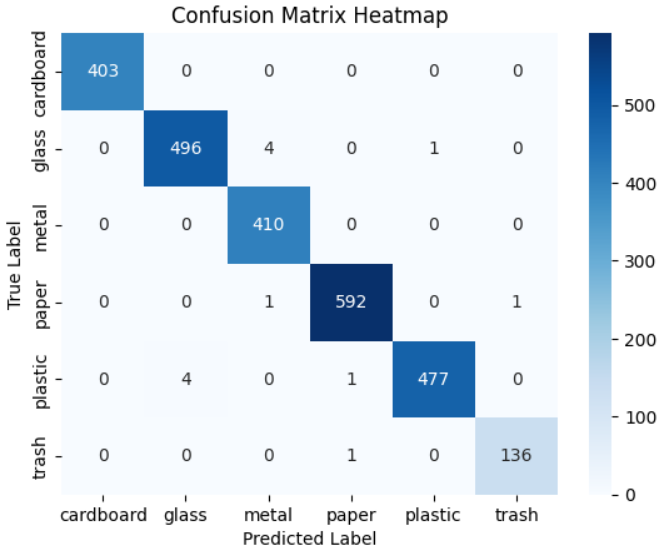
接着通过展示测试集中一个批次的图像及其对应的真实标签与预测标签,提供直观的模型性能展示。这种可视化不仅验证模型的整体性能,还能让读者具体了解模型在哪些样本上表现良好,在哪些样本上出现错误,从而深入理解模型的分类行为。
# ====================== 创建可视化图形窗口 ======================
# 创建15×10英寸的图形窗口,提供足够的空间显示9张图像
plt.figure(figsize=(15, 10))
# ====================== 获取测试集的一个批次数据 ======================
# test_ds.take(1): 从测试数据流中获取第一个批次的数据
# 返回一个包含图像张量和对应真实标签的元组
for images, labels in test_ds.take(1):
# 使用模型对当前批次的所有图像进行预测
# verbose=0: 不显示预测进度信息,保持输出简洁
preds = model.predict(images, verbose=0)
# 将模型输出的概率预测转换为类别标签
# np.argmax(preds, axis=1): 取每行最大概率对应的索引
pred_labels = np.argmax(preds, axis=1)
# ================== 显示批次中的9个样本 ==================
# 循环显示9个样本,采用3行3列的网格布局
for i in range(9):
# 创建3行3列的子图网格,当前位置为i+1
plt.subplot(3, 3, i + 1)
# 显示第i张原始测试图像
# images[i]: 第i个图像张量,形状为(224,224,3)
# .numpy(): 将TensorFlow张量转换为NumPy数组
# .astype("uint8"): 转换为无符号8位整数,确保matplotlib正确显示颜色
plt.imshow(images[i].numpy().astype("uint8"))
# 设置子图标题,包含真实标签和预测标签
# classes[labels[i]]: 真实类别名称(通过整数索引映射)
# classes[pred_labels[i]]: 预测类别名称
plt.title(
f"Actual: {classes[labels[i]]}\nPredicted: {classes[pred_labels[i]]}"
)
# 关闭坐标轴显示,使图像更清晰
plt.axis("off")
# ====================== 显示图形 ======================
plt.show()
5.总结
本项目成功构建了一个基于NASNet的垃圾分类识别模型,实现了对12种常见家庭垃圾的自动化准确分类。模型在测试集上达到了99.49%的极高准确率,验证损失仅为0.0202,展现出卓越的分类性能和强大的泛化能力。从具体实现来看,通过迁移学习策略,利用在ImageNet上预训练的NASNetLarge模型作为特征提取器,显著提升了在有限垃圾图像数据上的学习效率。结合多层次的全连接网络和Dropout正则化,模型能够有效处理垃圾图像中复杂的背景干扰、多样的形态变化和类间相似性问题。实验结果充分证明了深度学习方法在垃圾分类任务中的有效性。高准确率的实现为自动垃圾分拣系统的开发提供了可靠的技术支持,有助于提升垃圾回收利用效率,推动智慧城市建设和环境保护。该模型架构和方法可进一步扩展至更多垃圾类别或应用于移动端部署,具备良好的实际应用前景。
资料获取,更多粉丝福利,关注下方公众号获取


助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 15
15 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)