系统分析师-2024年11月案例真题及参考答案(回忆版本)
本文摘要包含三套计算机系统设计试题的答案要点: 超市自助结算系统DFD设计题,重点解答了数据流图与流程图的区别,补充了系统各模块的数据流关系,并列举了DFD常见的三类错误(黑洞/奇迹/灰洞)。 面向对象设计题,解析了边界类、实体类和控制类的划分标准,并以论文管理系统为例进行分类,同时阐述了开闭原则的实现要求(通过抽象层扩展而非修改原有代码)。 农业物联网系统设计题,分析了时序数据库(IoTDB)适
目录
试题一
【说明】
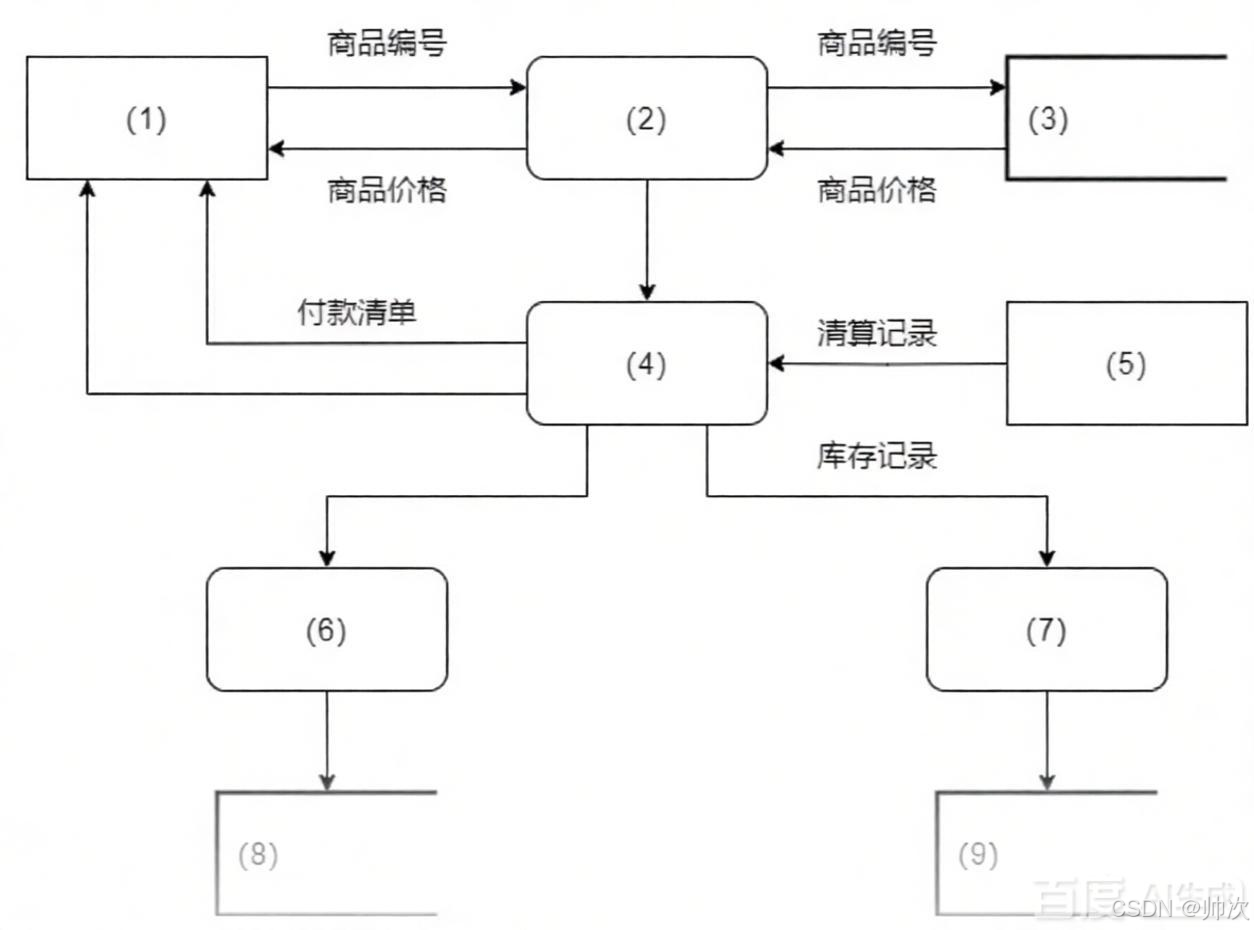
必选题:(DFD),超市自助结算系统,给了数据流图的,少实体和加工的内容,让填空
- 1.自动计价:顾客通过扫描商品,在屏幕上显示商品信息,系统计算并返回商品总价
- 2.付款管理:顾客付款后财务清算系统通知支付完成
- 3.库存管理:根据订单相应减少库存商品,并记入库存表
- 4.交易管理:记录交易详情,以备后续查询
【问题 1】
请给出流程图和数据流图的含义与区别
【问题 2】
请根据题目描述,在下列选项里选择合适的填入图中(1)-(9)空
选项:顾客、财务清算系统、商品、计算总价、付款结算、库存管理、库存记录、交易管理、交易记录
【问题 3】
请给出DFD中常见的三种错误(6分)。
【答案】
【问题 1】
数据流图作为一种图形化工具。说明业务处理过程、系统边界内所包含的功能、系统中的数据流,适用于系统分析中的逻辑建模阶段;
流程图以图形化方式展示应用程序从数据输入到获得输出为止的逻辑过程,描述处理过程的控制流,往往涉及具体技术、环境,适用于系统设计中的物理建模阶段;
区别:
- 数据流图的处理过程可并行;流程图在某时间点只能处于一个处理过程
- 数据流图展现系统的数据流;流程图展现系统的控制流
- 数据流图展现全局处理过程,过程间遵循不同的计时标准;流程图的处理过程遵循一致的计时标准
【问题 2】
(1)顾客、(2)计算总价、(3)商品、(4)付款结算、(5)财务清算系统、
(6)库存管理、(7)交易管理、(8)库存信息、(9)交易信息
【问题 3】
- 父图数据流必须在子图中出现;
- 一个处理至少有一个输入流和一个输出流;
- 黑洞::只有输入而无输出;
- 奇迹:只有输出而无输入;
- 灰洞:输入数据流无法通过加工产生输出数据流;
- 输入数据流与输出数据流名称相同;
- 一个存储必定有流入和流出;
- 一个数据流至少有一端是处理端;
- 模型表达的信息是全面的、完整的、正确的和一致的。
试题二
【说明&问题】
说明:无。
【问题 1】
说明边界类、实体类、控制类的含义和作用,并将以下选项里的内容分别归属到三种设计类里。
选项:论文、课题、学生、选题窗口、课题列表、论文上传、论文批阅、登录界面、用户管理。
【问题 2】
时序图填空,图未还原
【问题 3】
说明开闭原则的定义和具体要求
【答案】
【问题 1】
实体类的对象表示现实世界中真实的实体,如人、物等。
接口类(边界类)的对象为用户提供一种与系统合作交互的方式,分为人和系统两大类,其中人的接口可以是显示屏、窗口、Web窗体、对话框、菜单、列表框、其他显示控制、条形码、二维码或者用户与系统交互的其他方法。系统接口涉及到把数据发送到其他系统,或者从其他系统接收数据。
控制类的对象用来控制活动流,充当协调者。
实体类:论文、课题、学生;
控制类:论文上传、论文批阅、用户管理;
边界类:选题窗口、课题列表、登录界面。
【问题 3】
开闭原则是指软件实体应对扩展开放,而对修改关闭,即尽量在不修改原有代码的情况下进行扩展。此处的"实体"可以指一个软件模块、一个由多个类组成的局部结构或一个独立的类。
应用开闭原则可扩展已有的系统,并为之提供新的行为,以满足对软件的新需求,使变化中的系统具有一定的适应性和灵活性。对于已有的软件模块,特别是最重要的抽象层模块不能再修改,这就使变化中的系统有一定的稳定性和延续性,这样的系统同时满足了可复用性与可维护性。
在OOD中,开闭原则一般通过在原有模块中添加抽象层(例如,接口或抽象类)来实现,它也是其他OOD原则的基础,而其他原则是实现开闭原则的具体措施。
试题三嵌入式(略)
试题四
【说明】
某公司为鼓励员工考取技能证书,对项目的技能需求和员工的技能水平进行统一管理,以提升项目竞争力。王工对该系统做了分析,并设计了如下关系模型:
- 技能表:技能ID,技能描述。主键:技能ID。
- 员工表:员工ID,姓名,部门,联系方式。主键:员工ID。
- 项目表:项目ID,项目名称,项目描述。主键:项目ID。
- 员工技能表:员工ID,技能ID,技能水平。用于记录每位员工在各技能上的水平。
- 项目技能需求表:项目ID,技能ID,需求水平。用于记录每个项目对各技能的水平要求。
业务说明:
- 技能水平分为:初级、中级、高级(可视为有序:初级 < 中级 < 高级)。
- 一名员工可拥有多种技能(每种技能一个水平);一个项目可需求多种技能;同一项目对同一技能也可有多种需求水平(例如既需要高级也需要初级)。
【问题 1】
(1)员工技能表的主键是什么?有哪些函数依赖?至少满足第几范式?
(2)项目技能需求表的主键是什么?有哪些函数依赖?至少满足第几范式?
【问题 2】
为查询各项目中、满足技能需求的员工姓名及其技能水平,王工写了如下视图的伪代码,其中 (1)(2)(3) 需补全:
SELECT 项目名称, (1), 技能ID, 技能水平
FROM 员工表 t1, 项目表 t2, (2) t3, 项目技能需求表 t4
WHERE t3.员工ID = t1.员工ID
AND t4.项目ID = t2.项目ID
AND (3)
AND t3.技能ID = t4.技能ID请帮忙完善上述伪代码的空(1)(2)(3),同时,此语句连接有性能问题,该如何优化,优化的好处和缺点是什么?
【问题 3】
王工觉得还有数据冗余指出更新会异常,请问如何优化?请给出新表。
【答案】
【问题 1】
(1)员工技能表
- 主键:(员工ID,技能ID)。
- 函数依赖:(员工ID,技能ID) → 技能水平。(仅此非平凡函数依赖。)
- 范式:满足 BCNF。决定因素均为候选键,无部分依赖与传递依赖。
(2)项目技能需求表(仅含 项目ID、技能ID、需求水平 时)
- 主键:(项目ID,技能ID,需求水平)。因同一项目对同一技能可需求多种水平,需将需求水平纳入主键以唯一标识一行。
- 函数依赖:在仅含上述三属性时,全表即主键,无非主属性,无非平凡函数依赖;若表中还有“需求人数”等属性,则需根据实际语义重新分析函数依赖。
- 范式:在仅三属性情况下满足 BCNF(全键表)。
【问题 2】
(1)补全
- (1):员工姓名
- (2):员工技能表
- (3):t3.技能水平 >= t4.需求水平(或等价写法:员工技能水平不低于项目需求水平)
(2)性能与优化
- 可能问题:多表笛卡尔积再过滤(尤其是用旧式逗号连接时),易造成全表扫描与大量中间结果;若缺少索引,连接和比较会较慢。
- 优化思路:
- 在 员工技能表(员工ID, 技能ID)、项目技能需求表(项目ID, 技能ID) 等连接列上建索引;
- 将逗号连接改为显式 JOIN,并先过滤再连接;
- 若查询频繁且数据更新不频繁,可考虑物化视图或汇总表。
- 好处:减少全表扫描、降低 IO、缩短响应时间。
- 代价:写操作与维护成本增加、占用更多存储,物化视图还需维护刷新策略。
【问题 3】
题干不完整,下面全是猜测,可跳过
可能的冗余与异常(示例)
- 若在员工技能表或项目技能需求表中直接存储“技能描述”“项目名称”等文字,则同一技能/项目会在多行重复,产生冗余;修改技能描述或项目名称时需更新多行,易产生修改异常。
- 若在项目表中冗余存储“所需技能列表”或“需求水平”等本应属于项目技能需求的信息,也会造成类似问题。
优化思路与表结构示例
在保持题干中 技能表、员工表、项目表 不变的前提下,仅对“技能相关”部分做规范化示例:
1. 技能表:技能ID(主键),技能描述。
仅存技能本身信息,避免在员工技能、项目需求中重复描述。
2. 员工表:员工ID(主键),姓名,部门,联系方式。
仅存员工本身信息。
3. 项目表:项目ID(主键),项目名称,项目描述。
仅存项目本身信息。
4. 员工技能表:员工ID,技能ID,技能水平。主键:(员工ID,技能ID)。
只存“谁具备哪种技能、什么水平”,不存技能描述。
5. 项目技能需求表:项目ID,技能ID,需求水平。主键:(项目ID,技能ID,需求水平)。
只存“项目需要哪种技能、什么水平”,不存项目名称、技能描述。
试题五
【说明】
某单位拟建设农业物联网项目,主要建设内容如下:
- 数据采集:接入多种通信协议与多种农业传感器(如温湿度、土壤墒情、光照、CO₂ 等),实现多源异构农业数据的统一采集与上报。
- 物联网平台:建设统一的物联网平台,负责设备接入、数据汇聚、存储与下发。
- 技术选型:采用 IoTDB 作为时序数据库存储传感器数据,使用 Netty 实现高性能网络通信,使用 Kafka Cluster 作为消息中间件,实现采集数据与下游业务的解耦与流式处理。
请结合上述场景回答下列问题。
【问题 1】
简述时序数据库的典型特点,并说明本项目为何选用时序数据库(如 IoTDB)存储农业传感器数据。
【问题 2】
填空:简述本项目为什么采用 Kafka Cluster 模式。请在叙述中合理使用下列 5 个概念完成填空:消费组、消费者、提供者(生产者)、Topic、Partition。
(说明:原答案未还原,此处仅保留题目形式与概念列表,不提供填空答案。)
【问题 3】
从扩展性、稳定性等多方面简述本项目采用 Netty 作为网络通信框架的原因。
【答案】
【问题 1】
1. 时序数据库的典型特点
- 按时间组织与高写入:数据按时间戳有序写入,写多读少或按时间范围查询为主,适合传感器、监控等场景。
- 高压缩比:针对时间序列采用列式存储与专用压缩算法(如 Delta 编码、Gorilla 等),在保证精度的前提下显著降低存储与 IO。
- 时序查询与聚合:支持按时间范围、降采样、滑动窗口、多序列对齐等时序特有查询与聚合。
- 多序列/多测点模型:天然支持“设备 × 测点 × 时间”的多维建模,便于按设备、按测点统一管理。
- 可扩展与高可用:多数产品支持分布式、副本与故障转移,便于随数据量和并发增长做水平扩展。
2. 本项目为何使用时序数据库
农业传感器数据本质是按时间产生的测点序列,具有强时间属性、写多读少、按时间查询与聚合等典型时序特征,与时序数据库的存储和查询模型高度匹配。选用 IoTDB 等时序库可以:提高写入与查询性能、通过压缩降低存储成本、利用内置时序函数做统计与告警,并便于与大数据/AI 平台集成,实现农业数据的统一管理与智能分析。
【问题 2】
无
【问题 3】
1. 高性能
- 基于 NIO(非阻塞 I/O),用少量线程处理大量并发连接,适合物联网场景下海量设备长连接。
- 通过内存池(Pooled ByteBuf)、零拷贝等技术减少堆分配与数据拷贝,降低 GC 压力,提高吞吐与延迟稳定性。
- 事件驱动模型便于在协议解析、数据转发等环节做流水线处理,提高 CPU 利用率。
2. 易用性
- API 相对简洁,内置多种编解码器,支持 TCP、UDP、HTTP、WebSocket 等常见协议,便于快速实现多协议接入,减少开发工作量。
- 文档与社区丰富,与 Spring、gRPC 等生态集成良好,便于在物联网平台中与业务服务、消息队列、数据库协同使用。
3. 可扩展性
- ChannelPipeline 与 ChannelHandler 设计高度模块化,可按协议、按业务分层扩展(如多协议解码、加密、压缩、业务处理),新增协议或逻辑时只需增删 Handler,无需大改框架。
- 支持多种传输与协议,便于在多协议、多种农业传感器接入场景下统一接入层,并与 Kafka、IoTDB 等组件对接,便于后续增加节点做水平扩展。
4. 稳定性
- 修复了 JDK NIO 的诸多已知问题,线程模型清晰(如 Boss/Worker 线程组),有利于减少误用导致的阻塞与死锁。
- 提供连接管理、空闲检测、异常关闭等机制,便于实现断线重连、心跳保活,适应农业现场网络不稳定情况。
- 具备完善的错误处理与恢复机制,便于在上层做限流、背压、熔断等保护,避免设备突发流量拖垮平台。
5. 社区支持与广泛应用
- 开源活跃,版本迭代快,问题能较快得到修复,并持续引入新特性。
- 在互联网、大数据、物联网、企业应用等领域得到广泛验证,具备成熟的商业应用基础。
相关推荐
软件需求工程的软件需求概述、需求获取、需求分析![]() https://shuaici.blog.csdn.net/article/details/155570041数据库系统-数据库管理系统&关系数据库&非关系型数据库
https://shuaici.blog.csdn.net/article/details/155570041数据库系统-数据库管理系统&关系数据库&非关系型数据库![]() https://shuaici.blog.csdn.net/article/details/149676562
https://shuaici.blog.csdn.net/article/details/149676562

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 30
30 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)