机器学习全景指南-启蒙篇——人工智能与机器学习的宏观版图
深度学习是机器学习的一种特殊方法,而机器学习是实现人工智能的主要途径。
目录规划
为了将这所有博客里的知识点逻辑顺畅地串联起来,特此设计了以下目录结构。这个顺序遵循了“概念引入 -> 基础回归 -> 分类进阶 -> 无监督学习”的学习路径:
- 第一章:启蒙篇——人工智能与机器学习的宏观版图
- 来源博客:人工智能和机器学习
- 核心内容:AI、ML、DL的关系,机器学习的分类(监督/无监督/强化),基本工作流程。
- 第二章:基石篇——预测连续值的线性回归
- 来源博客:线性回归
- 核心内容:一元/多元线性回归,损失函数,梯度下降,代码实战。
- 第三章:进阶篇——解决分类问题的逻辑回归
- 来源博客:逻辑回归
- 核心内容:从回归到分类的跨越,Sigmoid函数,决策边界,代码实战。
- 第四章:直觉篇——基于距离的K-近邻(KNN)
- 来源博客:KNN算法
- 核心内容:KNN原理,K值选择,距离计算,优缺点分析,代码实战。
- 第五章:探索篇——发现数据内在结构的聚类算法
- 来源博客:聚类算法
- 核心内容:K-Means原理,簇的概念,与分类的区别,应用场景。
- 第六章:总结与展望
- 综合对比五大算法,如何选择适合的模型。
文章目录
第一章:启蒙篇——人工智能与机器学习的宏观版图
导读:在深入具体的算法之前,我们必须先理清概念。很多人容易混淆“人工智能”、“机器学习”和“深度学习”。本章将为你绘制一张清晰的认知地图,并解释机器学习究竟是如何工作的。
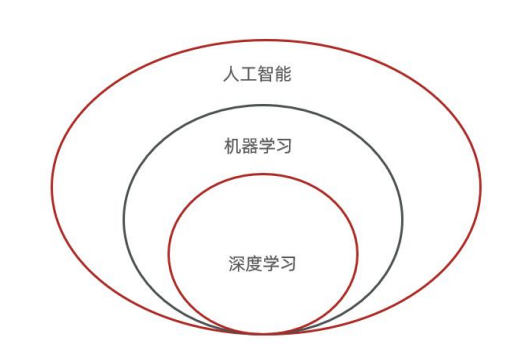
1.1 三者关系:套娃式的包含关系
想象三个大小不同的俄罗斯套娃,或者三个同心圆:
-
**人工智能 **(Artificial Intelligence, AI):最大的圆。
- 定义:这是一个宏大的领域,旨在让机器模拟人类的智能行为(如视觉、听觉、推理、决策)。
- 历史:早在1956年达特茅斯会议就提出了这个概念。
- 范围:它不仅包含机器学习,还包含专家系统、规则引擎、搜索算法等不需要“学习”就能运行的传统AI技术。
-
**机器学习 **(Machine Learning, ML):中间的圆,是AI的核心子集。
- 定义:一种让计算机不从显式编程中,而是从数据中学习规律的技术。
- 核心逻辑:传统编程是
输入 + 规则 = 输出;机器学习是输入 + 输出 = 规则(模型)。 - 地位:目前实现AI最主要的手段。
-
**深度学习 **(Deep Learning, DL):最小的圆,是机器学习的子集。
- 定义:基于人工神经网络(尤其是深层神经网络)的机器学习方法。
- 特点:擅长处理图像、语音、自然语言等非结构化数据,需要大量数据和算力。
一句话总结:深度学习是机器学习的一种特殊方法,而机器学习是实现人工智能的主要途径。
1.2 机器学习的三大流派
根据训练数据和学习方式的不同,机器学习主要分为三类:
🟢 1. 监督学习 (Supervised Learning)
- 特点:数据既有**特征 (X),也有标签 **(Y)(即正确答案)。就像老师带着学生做题,做完后告诉学生正确答案是什么。
- 目标:学习一个映射关系
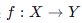 ,以便对新的数据进行预测。
,以便对新的数据进行预测。 - 主要任务:
- 回归 (Regression):预测连续数值。
- 例子:预测房价、气温、股票价格。
- 对应算法:线性回归(后续章节详解)。
- 分类 (Classification):预测离散类别。
- 例子:判断邮件是否为垃圾邮件、识别图片是猫还是狗。
- 对应算法:逻辑回归、KNN(后续章节详解)。
- 回归 (Regression):预测连续数值。
🔵 2. 无监督学习 (Unsupervised Learning)
- 特点:数据只有**特征 **(X),**没有标签 **(Y)。就像给学生一堆杂乱的积木,没有说明书,让他们自己找规律分类。
- 目标:发现数据内部的结构、模式或分布。
- 主要任务:
- **聚类 **(Clustering):将相似的数据归为一组。
- 例子:用户细分(将消费者分为高价值、低价值群体)、新闻主题聚合。
- 对应算法:K-Means聚类(后续章节详解)。
- **降维 **(Dimensionality Reduction):在保留主要信息的前提下减少特征数量。
- **聚类 **(Clustering):将相似的数据归为一组。
🟠 3. 强化学习 (Reinforcement Learning)
- 特点:没有静态的数据集。智能体(Agent)通过与环境交互,根据**奖励 **(Reward) 或 **惩罚 **(Penalty) 来调整策略。
- 目标:找到一种策略,使得长期累积的奖励最大化。
- 例子:AlphaGo下围棋、机器人学走路、自动驾驶决策。
1.3 机器学习的标准工作流程
无论使用哪种算法,一个完整的机器学习项目通常遵循以下步骤:
- **数据收集 **(Data Collection):获取原始数据(数据库、爬虫、传感器等)。
- **数据预处理 **(Data Preprocessing):
- 清洗数据(处理缺失值、异常值)。
- 特征工程(提取特征、归一化/标准化)。
- 注:这是最耗时但最关键的一步,“Garbage In, Garbage Out”。
- **模型选择 **(Model Selection):根据问题类型(回归/分类/聚类)选择合适的算法(如线性回归、KNN等)。
- **模型训练 **(Training):使用训练集数据,让算法学习参数。
- **模型评估 **(Evaluation):使用测试集数据,验证模型的效果(准确率、误差等)。
- **模型调优 **(Tuning):调整超参数(如KNN中的K值),优化性能。
- **部署与应用 **(Deployment):将模型应用到实际生产环境中。
1.4 代码小试牛刀:理解“拟合”的概念
为了让大家更直观地理解机器学习中“从数据中学习规则”的过程,我们用一段简单的 Python 代码来模拟线性回归(监督学习中最基础的算法)的拟合过程。
这段代码展示了如何生成一些带有噪音的数据,并让机器去“猜”出背后的直线规律。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 1. 生成模拟数据 (模拟现实世界的不完美)
# 假设真实规律是 y = 2x + 1,但我们加入了一些随机噪音
np.random.seed(42) # 固定随机种子,保证每次运行结果一样
X = 2 * np.random.rand(100, 1) # 100个样本,特征x在0-2之间
y = 1 + 2 * X + np.random.randn(100, 1) # y = 1 + 2x + 噪音
# 2. 模型初始化与训练
# 这就是机器学习库帮我们做的“黑盒”工作
model = LinearRegression()
model.fit(X, y) # 核心步骤:模型通过数据计算出了最佳的 w 和 b
# 3. 查看模型学到的规律
print(f"截距 (b): {model.intercept_[0]:.4f}") # 应该接近 1
print(f"斜率 (w): {model.coef_[0][0]:.4f}") # 应该接近 2
# 4. 可视化结果
plt.scatter(X, y, alpha=0.5, label='原始数据 (含噪音)')
plt.plot(X, model.predict(X), 'r-', linewidth=2, label='机器学习拟合的直线')
plt.title('机器学习:从噪音数据中寻找规律')
plt.xlabel('特征 X')
plt.ylabel('目标 Y')
plt.legend()
plt.show()
代码解读:
- 我们没有告诉计算机公式是
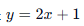 。
。 - 我们只给了它一堆看起来乱糟糟的点(
X和y)。 - 通过
model.fit(),计算机自己算出了斜率接近2,截距接近1。 - 这就是机器学习的本质:数据驱动,自动发现规律。
1.5 本章小结
- AI > ML > DL:理清了层级关系。
- 监督 vs 无监督:关键区别在于数据是否有“标签”(正确答案)。
- 流程标准化:从数据清洗到模型部署,每一步都不可或缺。
在接下来的章节中,我们将深入具体的算法世界。首先,我们将走进线性回归,看看机器是如何预测连续数值的;随后,我们将学习逻辑回归和KNN来解决分类问题;最后,我们将探索聚类算法,看看在没有标签的情况下,机器如何发现数据的内在结构。
下一章预告:《第二章:基石篇——预测连续值的线性回归》,我们将深入探讨如何用一条直线撬动数据预测。
器是如何预测连续数值的;随后,我们将学习逻辑回归和KNN来解决分类问题;最后,我们将探索聚类算法,看看在没有标签的情况下,机器如何发现数据的内在结构。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)