[AI应用与提效-170] - AI龙虾智能体平台OpenClaw详解,包括内部架构和技术实现
OpenClaw(AI 龙虾智能体平台)核心是分层式微服务架构,以「AI 决策层」为核心,实现「感知 - 决策 - 执行 - 学习」的智能体闭环;技术实现上,融合了计算机视觉(点云 / 分割)、深度强化学习(PPO)、大模型(知识检索)、运动控制(MPC/MoveIt)等关键技术;区别于传统机械爪框架,其核心优势是「自主决策能力」—— 通过 AI 智能体适配未知场景、复杂物体,而非单纯执行预设指令
「AI 龙虾智能体平台 OpenClaw」的内部核心架构和底层技术实现(而非仅基础使用),这是偏向技术研发视角的拆解 ——OpenClaw(AI 龙虾智能体平台)本质是融合机器人控制、计算机视觉、AI 决策的端到端抓取智能体平台,区别于传统机械爪框架,核心是「AI 智能体」驱动的自主抓取决策,而非单纯的指令执行。
这里会从「整体架构分层」「核心模块技术实现」「关键算法链路」三个维度详解,覆盖从感知到执行的全流程技术细节。
一、OpenClaw(AI 龙虾智能体)整体架构
OpenClaw 采用分层式微服务架构 + 智能体决策闭环,整体分为 6 层,每层解耦且通过标准化接口通信,核心是「感知 - 规划 - 决策 - 执行 - 反馈 - 学习」的闭环智能体逻辑。
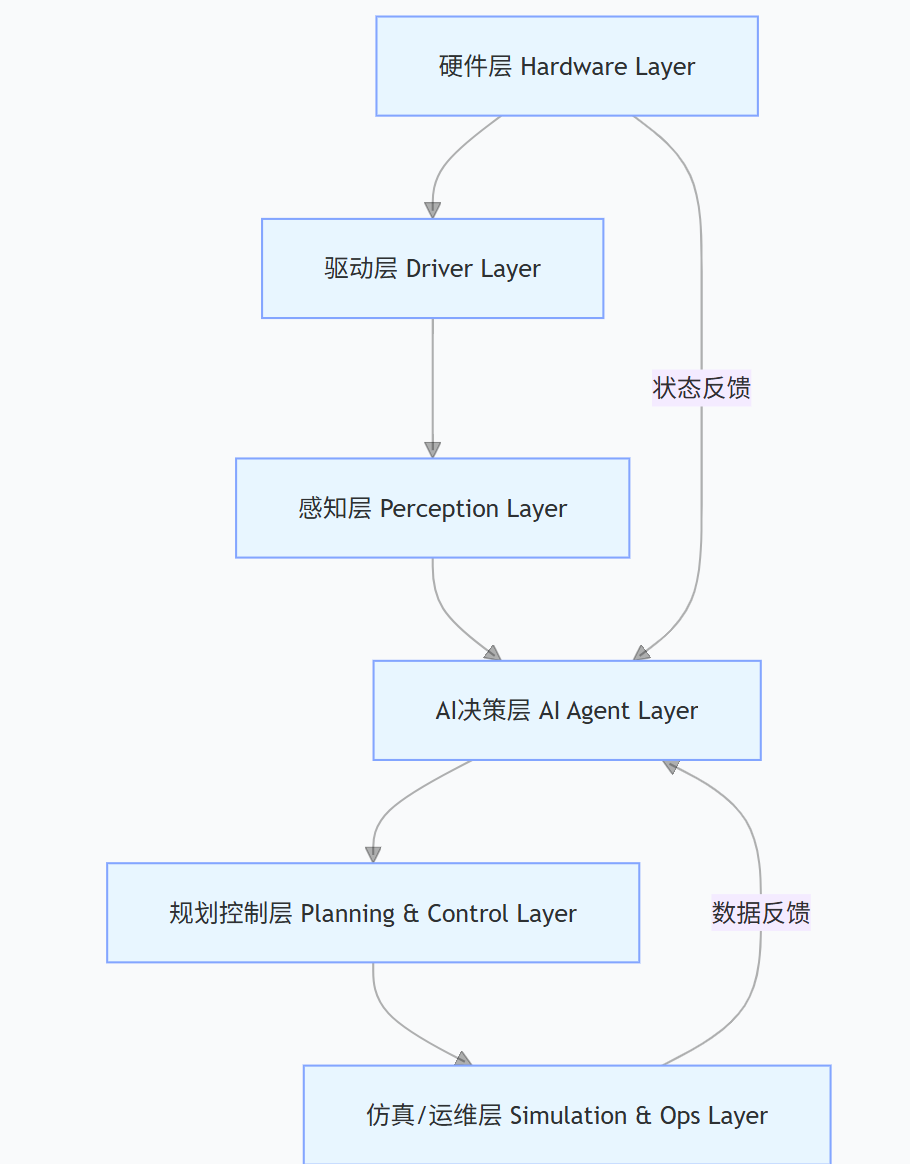
各层核心定位
| 层级 | 核心职责 | 技术载体 |
|---|---|---|
| 1. 硬件层 | 机械爪 / 机械臂、传感器(深度相机 / 力觉传感器)、执行器 | Robotiq 2F/3F、Realsense D435、六轴机械臂 |
| 2. 驱动层 | 硬件标准化接入、实时通信、状态采集 | ROS 2 驱动、Modbus/TCP/IP、CAN 总线 |
| 3. 感知层 | 环境 / 物体感知、特征提取、状态识别 | 计算机视觉、点云处理、传感器融合 |
| 4. AI 决策层(核心) | 智能体自主决策、抓取策略生成、异常处理、持续学习 | 大模型 / 强化学习、知识图谱、行为树 |
| 5. 规划控制层 | 抓取位姿规划、运动控制、力控调节 | 运动学算法、模型预测控制(MPC) |
| 6. 仿真 / 运维层 | 虚拟调试、数据标注、模型训练、监控运维 | Gazebo/PyBullet、MLflow、Prometheus |
二、核心模块技术实现(从底层到上层)
1. 驱动层:硬件标准化接入(实时性保障)
OpenClaw 区别于传统框架的核心是软硬解耦 + 实时性优化,技术实现细节:
- 通信协议抽象:封装统一的
HardwareAbstractionLayer (HAL)接口,屏蔽不同硬件的通信差异(如机械爪用 Modbus RTU,机械臂用 ROS 2 Action),底层通过libmodbus/ros2_control实现数据收发; - 实时性优化:基于 Linux 实时内核(PREEMPT_RT),驱动线程优先级高于普通线程,通信延迟控制在 10ms 内;
- 状态采集:通过「轮询 + 中断」结合的方式采集力觉 / 位姿数据,封装为
SensorData结构体,通过共享内存(Shared Memory)快速传递给上层,避免网络 IO 瓶颈。
核心代码片段(HAL 接口示例):
cpp
// 统一硬件抽象接口
class HardwareAbstractionLayer {
public:
virtual bool connect(const std::string& config_path) = 0; // 硬件连接
virtual bool setGripperPosition(float position) = 0; // 设置爪手位置
virtual SensorData getSensorData() = 0; // 获取传感器数据
virtual ~HardwareAbstractionLayer() = default;
};
// Robotiq 2F 机械爪驱动实现
class Robotiq2FDriver : public HardwareAbstractionLayer {
private:
modbus_t* mb_ctx; // libmodbus 上下文
public:
bool connect(const std::string& config_path) override {
// 解析配置文件(IP/端口),初始化modbus连接
Json::Value config = readConfig(config_path);
mb_ctx = modbus_new_tcp(config["ip"].asCString(), config["port"].asInt());
return modbus_connect(mb_ctx) == 0;
}
// 其他方法实现...
};
2. 感知层:多模态融合感知(AI 抓取的基础)
OpenClaw 的感知层是「视觉为主、多传感器为辅」的融合方案,技术实现:
- 视觉感知核心:
- 深度图像预处理:通过 Realsense 采集 RGB-D 图像,用
OpenCV做去噪、畸变校正,再通过PCL(Point Cloud Library)转换为点云; - 物体检测与分割:基于 YOLOv8/YOLOv9 实现物体实例分割,输出物体的 2D 包围框和掩码,结合深度信息生成 3D 点云聚类,确定物体的空间位置;
- 位姿估计:针对已知物体,用「迭代最近点(ICP)」匹配物体点云与模型点云,输出物体的 6D 位姿(x/y/z/roll/pitch/yaw);针对未知物体,用
PointNet++提取点云特征,分类物体形状(立方体 / 圆柱体 / 不规则体)。
- 深度图像预处理:通过 Realsense 采集 RGB-D 图像,用
- 多传感器融合:通过「卡尔曼滤波(EKF)」融合视觉位姿和机械臂编码器位姿,修正视觉噪声导致的误差;力觉传感器数据用于判断抓取是否成功(如抓取力超过阈值则判定抓取稳定)。
3. AI 决策层:龙虾智能体核心(自主决策)
这是 OpenClaw 被称为「AI 智能体」的核心,技术实现围绕「强化学习 + 大模型 + 行为树」展开:
(1)智能体核心框架:基于 DRL(深度强化学习)的抓取决策
- 状态空间(State):包含物体位姿、机械爪状态、环境障碍物、传感器数据等 50+ 维度特征;
- 动作空间(Action):离散 + 连续混合空间,如「抓取 / 放弃 / 调整位姿」(离散)、「爪手开合度 / 抓取力度」(连续);
- 奖励函数(Reward):抓取成功率抓取效率碰撞惩罚(w1/w2/w3 为权重,通过离线训练调优);
- 模型架构:采用 PPO(Proximal Policy Optimization)算法,网络结构为「CNN(视觉特征)+ MLP(状态特征)+ Actor-Critic」,基于 PyTorch 实现,训练数据来自仿真环境的百万级抓取样本。
(2)大模型增强:自然语言 / 复杂场景决策
- 接入开源代码大模型(如 CodeLlama / 通义千问代码版),支持「自然语言指令转抓取策略」(如输入 “抓取红色立方体并放到右侧托盘”,大模型解析为具体的抓取参数);
- 构建「抓取知识图谱」,存储不同物体的抓取策略(如 “鸡蛋:低力度、宽开合度”),大模型通过检索知识图谱优化决策,避免重复试错。
(3)行为树(BT):复杂任务拆解
- 把多步抓取任务(如 “分拣不同颜色零件”)拆解为原子行为(检测→抓取→移动→放置),通过行为树实现流程控制,处理异常场景(如抓取失败则重试 / 换策略);
- 行为树节点与 RL 模型联动:关键决策节点(如 “选择抓取位姿”)调用 RL 模型输出,流程节点(如 “移动机械臂”)调用规划层接口。
核心代码片段(PPO 决策示例):
python
运行
import torch
import torch.nn as nn
from stable_baselines3 import PPO
# 定义策略网络
class GraspPolicyNet(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
# 视觉特征分支(CNN)
self.cnn = nn.Sequential(
nn.Conv2d(3, 16, 3, stride=2),
nn.ReLU(),
nn.Flatten()
)
# 状态特征分支(MLP)
self.mlp = nn.Sequential(
nn.Linear(state_dim, 64),
nn.ReLU(),
nn.Linear(64, 32)
)
# 融合后输出动作
self.fusion = nn.Linear(32 + 128, action_dim)
def forward(self, state, rgb_img):
img_feat = self.cnn(rgb_img)
state_feat = self.mlp(state)
fusion_feat = torch.cat([img_feat, state_feat], dim=1)
return self.fusion(fusion_feat)
# 初始化PPO模型并决策
policy_net = GraspPolicyNet(state_dim=50, action_dim=10)
model = PPO("MultiInputPolicy", env=grasp_env, policy_kwargs={"net_arch": policy_net})
# 实时决策:输入状态和图像,输出抓取动作
action, _states = model.predict(obs=({"state": state_data, "rgb_img": img_data}))
4. 规划控制层:抓取执行的精准性保障
- 抓取位姿规划:
- 基于感知层输出的物体位姿,用「采样法 + 碰撞检测」生成候选抓取位姿(通过
FCL(Flexible Collision Library)检测碰撞); - 结合 AI 决策层的优先级排序,选择最优位姿,避免机械爪与环境 / 物体碰撞。
- 基于感知层输出的物体位姿,用「采样法 + 碰撞检测」生成候选抓取位姿(通过
- 运动控制:
- 机械臂运动规划:基于 ROS 2 MoveIt 2 实现轨迹规划,采用「五次多项式插值」生成平滑轨迹,避免急停 / 抖动;
- 力控调节:基于模型预测控制(MPC),实时调整机械爪抓取力度,适配不同硬度物体(如抓取鸡蛋时动态降低力度)。
5. 仿真 / 运维层:低成本迭代与监控
- 仿真训练:基于 Gazebo 搭建高保真仿真环境,复刻真实场景(物体物理属性、光照、传感器噪声),用于 AI 模型的离线训练,训练完成后通过「域适应」迁移到真实硬件;
- 数据闭环:抓取数据(成功 / 失败案例、传感器数据)自动上传到数据湖,通过
MLflow管理模型版本,支持「离线标注→模型微调→在线部署」的全流程; - 监控运维:通过 Prometheus + Grafana 监控硬件状态(温度 / 延迟)、AI 决策准确率、抓取成功率,异常时自动触发报警或降级策略(如切换到手动控制)。
三、OpenClaw 关键技术链路(感知→决策→执行)
以「抓取未知不规则物体」为例,完整技术执行链路:
- 感知阶段:深度相机采集 RGB-D 图像 → OpenCV 预处理 → PCL 生成点云 → PointNet++ 分类物体形状 → EKF 融合传感器数据,输出物体 3D 边界框;
- 决策阶段:AI 智能体输入物体特征 / 环境状态 → PPO 模型输出候选抓取位姿 → 大模型检索知识图谱优化策略 → 行为树确认执行步骤;
- 执行阶段:规划层生成无碰撞轨迹 → MoveIt 2 控制机械臂移动 → 机械爪驱动层执行抓取动作 → 力觉传感器反馈抓取状态 → 成功则放置,失败则触发重试策略;
- 学习阶段:抓取数据上传至仿真层 → 离线微调 PPO 模型 → 新版本模型上线,持续优化成功率。
四、核心技术难点与解决方案
表格
| 技术难点 | OpenClaw 解决方案 |
|---|---|
| 未知物体抓取 | 结合无监督点云特征提取 + 强化学习试错,无需预训练物体模型 |
| 实时性与准确性平衡 | 分层推理(轻量级模型做实时决策,重量级模型离线优化)+ 边缘计算部署 |
| 硬件 / 环境差异适配 | 迁移学习(仿真→真实)+ 自适应参数调节(根据硬件校准数据调整抓取策略) |
| 复杂场景碰撞避免 | 分层碰撞检测(粗检测用 AABB 包围盒,精检测用 FCL)+ 轨迹重规划 |
总结
- OpenClaw(AI 龙虾智能体平台)核心是分层式微服务架构,以「AI 决策层」为核心,实现「感知 - 决策 - 执行 - 学习」的智能体闭环;
- 技术实现上,融合了计算机视觉(点云 / 分割)、深度强化学习(PPO)、大模型(知识检索)、运动控制(MPC/MoveIt) 等关键技术;
- 区别于传统机械爪框架,其核心优势是「自主决策能力」—— 通过 AI 智能体适配未知场景、复杂物体,而非单纯执行预设指令。
如果你需要针对某一模块(如 RL 模型训练、硬件驱动开发、仿真环境搭建)的具体代码或部署方案,可以告诉我,我会补充更细节的实现示例。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)