GraphRAG:知识图谱赋能的RAG技术革新与实践指南
系统阐述了GraphRAG技术的演进历程、核心架构与前沿实践。传统RAG存在关系理解缺失、多跳推理薄弱等局限,而GraphRAG通过知识图谱的语义网络结构实现突破性提升。文章详细解析了三阶段架构(知识图谱构建-图谱检索-增强生成),对比分析了Microsoft GraphRAG等四大前沿框架的技术特点,并建立了覆盖检索质量、生成效果与系统性能的评估体系。研究表明,GraphRAG在复杂查询场景下可
检索增强生成(RAG)已成为解决大型语言模型(LLM)知识陈旧与幻觉问题的核心方案,但传统RAG在复杂查询场景下的局限性日益凸显。随着知识图谱技术的融入,GraphRAG作为一种全新范式应运而生,通过显式建模实体语义关系,大幅提升了检索精准度与推理能力。本文将系统拆解GraphRAG的技术演进、核心架构、前沿框架、评估体系,并结合最新实践探讨生产部署的关键要点,为技术落地提供全面参考。
一、从传统RAG到GraphRAG:技术演进的必然逻辑
传统RAG通过检索-生成两阶段流程,在通用问答场景中展现了价值,但面对多跳推理、跨文档关联等复杂任务时,基于非结构化文本向量检索的核心机制暴露出诸多瓶颈,而GraphRAG的出现正是对这些痛点的针对性突破。
1.1 传统RAG的固有局限
尽管传统RAG缓解了LLM的知识更新难题,但其向量检索驱动的本质导致以下关键局限,难以支撑高复杂度任务需求:
- 关系理解缺失:向量检索仅关注语义相似性,无法捕捉实体间隐含的复杂关系(如因果、供应链关联)。当查询涉及多实体关联时,检索文本块缺乏逻辑关联,导致LLM推理断裂。
- 上下文碎片化:文本被切分为独立块索引,破坏了原始结构连续性。对于跨文档、长距离信息整合任务(如“某政策对产业链各环节的影响”),传统RAG往往力不从心。
- 幻觉风险居高不下:检索易返回噪声信息,干扰LLM判断。研究表明,传统RAG在事实性问答中的幻觉率仍较高,而知识图谱的引入可使幻觉率有效降低。
- 多跳推理能力薄弱:依赖线性文本检索,无法支持结构化知识导航。在HotpotQA等多跳问答数据集上,传统RAG的准确率比GraphRAG低15%-20%,且推理链完整性不足。
- 实体歧义与时效性不足:难以区分同名实体(如“苹果公司”与“苹果水果”),也无法有效建模时间属性,导致时序敏感问题(如“某公司2023年的子公司列表”)无法得到一致答案。
典型示例:查询“2019年收购A公司的企业,其母公司在2021年的主要投资对象是谁?”传统RAG需检索多段离散文本并手动拼接推理链,若任一文本缺失或存在歧义,整个推理过程即会中断。而GraphRAG可通过实体关系路径直接定位答案,推理成功率提升显著。
1.2 知识图谱赋能
知识图谱通过“实体-关系-属性”的图结构,将离散知识组织为语义网络,从根本上弥补了传统RAG的缺陷,其核心优势体现在:
- 结构化语义表达:直接编码显式关系(如“公司A-收购-公司B”、“紫杉醇-治疗-肺癌”),避免LLM隐式推断的偏差,为复杂查询提供清晰导航路径。
- 原生多跳推理能力:通过图遍历算法(如深度优先、广度优先),可发现间接关联。例如在医学场景中,能快速串联“肺癌→紫杉醇治疗→白细胞降低→升白针干预”的推理链。
- 事实性与可解释性双提升:答案可追溯至图中的推理路径,便于来源归因与冲突消解。牛津大学2025年提出的MedGraphRAG,正是借助这一特性在11个医学数据集上达成SOTA,事实一致性提升8%。
- 异构数据无缝集成:可整合结构化数据库(如患者电子病历)、非结构化文本(如医学论文)与半结构化数据(如表格),这在金融、医疗等领域至关重要。MedGraphRAG就整合了480万篇生物医学论文与UMLS医学术语图,实现循证问答。
- 时序与版本化支持:通过时间态边与版本化节点,支持时间旅行查询,可精准回答历史状态问题(如“某公司在2020年的股权结构”)。
1.3 从信息检索到知识利用
GraphRAG的核心突破在于检索目标的转变——从独立文本片段转向知识图谱中的实体、关系、路径或子图。这种转变使系统从被动匹配信息升级为主动利用知识,在上下文召回率、多跳问答准确率、事实一致性等关键指标上实现显著跃升。
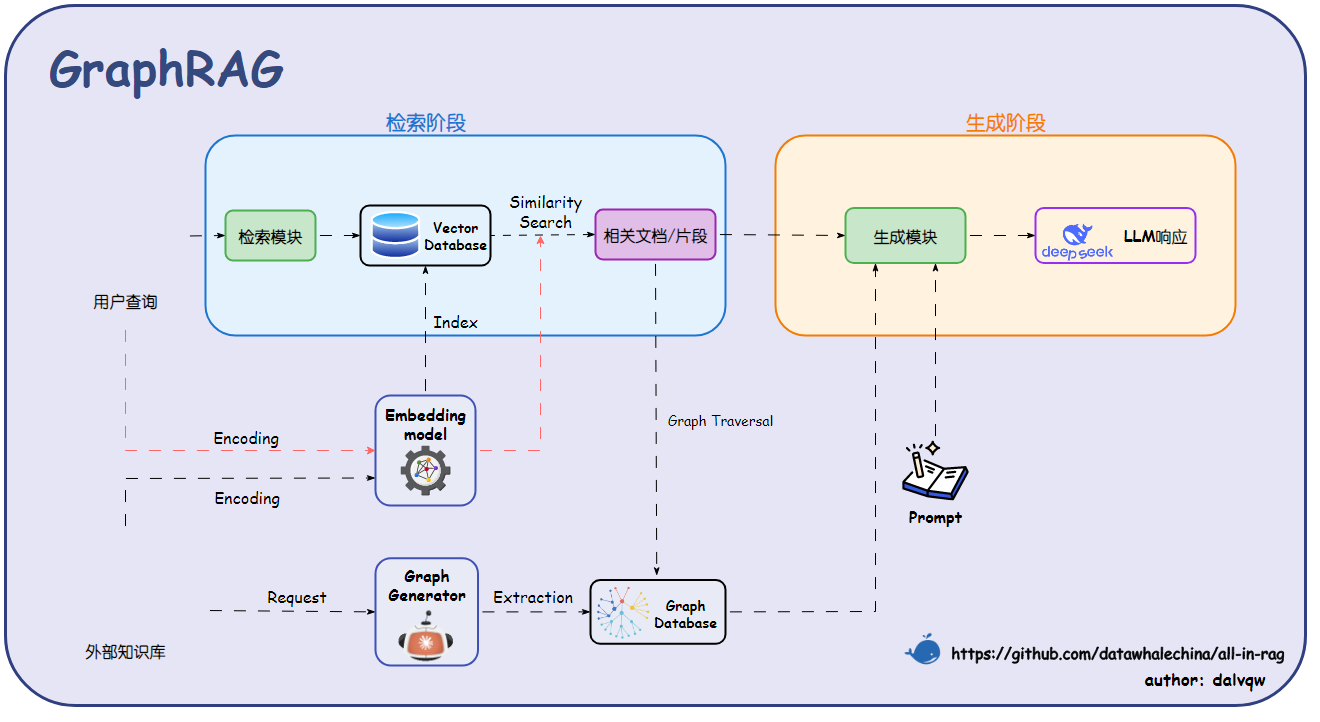
二、GraphRAG核心架构与工作流程详解
主流GraphRAG框架均遵循“知识图谱构建-图谱检索-增强生成”的三阶段闭环流程,各阶段环环相扣,共同决定系统性能。
2.1 三阶段通用架构
阶段一:知识图谱构建
该阶段目标是从原始数据中构建高质量知识图谱,直接影响后续检索与生成效果,核心步骤包括:
- 知识抽取:利用LLM或信息抽取(IE)管线,从非/半结构化文本中提取实体、关系与属性,同时完成指代消解(如他对应某CEO)、别名归一(如阿里统一为阿里巴巴)。
- 质量控制:通过置信度评分、人机协同抽检剔除错误三元组,利用本体约束(如药物不能与星球存在治疗关系)进行一致性校验。
- 图谱融合:执行实体对齐与去重,合并跨来源知识(如同时整合企业年报与新闻报道),并保留来源、时间戳等溯源信息。
- 存储与索引:落地至图数据库(Neo4j/NebulaGraph/TigerGraph等),建立实体属性、关系类型索引。对于大规模场景,推荐采用Milvus等向量数据库与图数据库协同存储,提升检索效率。
阶段二:图谱检索
与传统向量检索不同,GraphRAG采用混合检索策略,核心步骤包括:
- 实体定位:通过实体链接技术或向量检索,锁定查询中的核心实体节点(如“公司A”)。
- 子图探索:从核心节点出发,利用图查询语言(Cypher/Gremlin)或遍历算法进行邻域扩展,可限定关系类型、跳数、时间区间等约束条件。
- 结构化证据抽取:将检索到的路径、节点属性序列化为可读文本,或生成子图摘要,作为后续生成的证据。
- 高级检索优化:如Microsoft GraphRAG采用Leiden社区检测算法,生成全局-社区-局部多层级摘要,实现“全局概览+局部细节”的联合检索,提升复杂查询的响应质量。
Cypher查询示例(查询公司A两跳内收购路径及目标行业):
MATCH (a:Company {name: "A"})-[:ACQUIRED]->(b:Company)-[:IN_INDUSTRY]->(i:Industry)
RETURN a.name AS acquirer, b.name AS target, i.name AS industry
UNION
MATCH (a:Company {name: "A"})-[:ACQUIRED]->(:Company)-[:ACQUIRED]->(b2:Company)-[:IN_INDUSTRY]->(i2:Industry)
RETURN a.name AS acquirer, b2.name AS target, i2.name AS industry;
该查询通过 UNION 合并两个子查询,最终查询 公司 A 的直接收购 + 间接收购(二级收购)的目标公司,以及这些目标公司所属的行业,返回 “收购方(固定为 A)、目标公司、目标公司行业” 的结构化结果集。
阶段三:增强生成
将结构化图谱证据与原始查询一同注入LLM提示,核心实践要点包括:
- 提示工程设计:明确要求LLM引用图证据,必要时在答案后附加推理路径附录(如“证据来源:图谱中A-收购-B-所属行业-C”)。
- 多源证据融合:联合提供结构化三元组与原始文本片段,兼顾事实准确性与文本细节丰富度。在医疗场景中,MedGraphRAG就同时融合了图谱关系与论文原文证据。
- 领域约束输出:金融、医疗等敏感领域可采用模板化输出(如“诊断结论:XXX;证据路径:XXX”),并进行字段校验,进一步降低幻觉风险。
2.2 GraphRAG方法论分类与优劣对比
根据知识图谱与RAG的结合深度,现有方法可分为三类,适配不同场景需求:
| 方法论类型 | 核心逻辑 | 优势 | 劣势 | 典型场景 |
|---|---|---|---|---|
| 知识驱动型 | 检索完全依赖知识图谱,如文本转Cypher查询 | 高精度、高可解释性,事实一致性强 | 覆盖范围受限于图谱完备性,容错率低 | 金融风控、医疗诊断等强逻辑约束场景 |
| 索引驱动型 | 将图结构信息融入文本索引(如添加邻居实体元数据) | 集成成本低,兼容传统RAG架构 | 显式推理能力弱,可解释性一般 | 轻量级知识库、快速迭代的业务场景 |
| 混合型 | 联合图检索与文本检索,统一重排融合结果 | 综合性能稳健,适配复杂查询场景 | 系统复杂度高,工程实现成本高 | 企业级知识库、多源数据整合场景 |
三、2025年前沿GraphRAG框架解析
学术界与工业界涌现出一批代表性GraphRAG框架,各有技术侧重与场景适配性,以下为核心框架详解:
3.1 Microsoft GraphRAG:全局知识驱动的重量级方案
核心思想是先构建全局知识图谱,再按需分层检索,典型流程为:文本→三元组/子图构建→社区检测(Leiden算法)划分图谱→生成全局/社区/局部多层摘要→查询时先匹配高层摘要,再下钻局部子图与原文证据。
- 优势:提供强全局感知能力,可支持探索性分析、全景总结等复杂任务,可解释性极佳。在企业并购全景分析、产业链风险追踪等场景表现突出。
- 局限:前期图谱构建与分层摘要成本高,对数据持续变更场景需设计批处理增量更新与缓存策略。
3.2 LightRAG:轻量高效的极速落地方案
针对Microsoft GraphRAG的重量问题,LightRAG以轻量、快速、低依赖为核心目标,采用双层检索+图增强索引架构,弱化复杂社区发现流程,将图结构信号嵌入文本索引与重排环节。
3.3 FRAG:灵活模块化的自适应方案
核心亮点是“查询分流+模块化设计”,通过分类器将查询判定为简单/复杂两类:简单查询直接执行实体链接+属性查找,低延迟返回结果;复杂查询激活路径检索与多跳推理模块,再融合文本证据。
优势:可自适应不同复杂度查询,资源分配更高效;模块化设计支持预训练LLM能力复用,跨领域迁移成本低。适配场景:混合复杂度查询的企业级服务(如同时处理员工FAQ与深度业务分析查询)。
3.4 GraphIRAG:迭代检索的时序推理方案
引入多轮迭代检索思想,认为单次检索难以覆盖复杂任务的完整证据链。由控制器在生成过程中动态触发多轮图查询,以“新信息增益”为准则决定迭代停止时机。
- 优势:对时序敏感任务(如“某事件的连锁反应过程”)与超长推理链任务的鲁棒性更强。
- 适配场景:历史事件分析、供应链时序风险追踪、医疗病程演进分析等。
四、GraphRAG性能评估与基准测试
GraphRAG的评估需覆盖检索-生成-系统性能全链路,现有基准存在诸多不足,新基准框架正逐步完善。
4.1 核心评估指标体系
1. 检索质量指标
- 传统指标:精确率(Precision)、召回率(Recall)、F1值、命中率(Hit Rate@K)。
- RAG特有指标:上下文精确率(检索到的相关信息比例)、上下文召回率(标准证据的检回比例)、引用准确率(答案断言与证据的匹配度)。
2. 生成质量指标
- 问答任务:精确匹配(EM)、F1值;摘要任务:ROUGE-L、BLEU。
- 核心指标:事实一致性(Faithfulness),需通过逐句打标与归因检查验证。
3. 系统性能指标
- 响应延迟:从查询输入到答案返回的总时间(GraphRAG在复杂查询下延迟通常比传统RAG高2-3倍)。
- 吞吐量(QPS):单位时间处理的查询数量;资源成本:GPU/CPU占用、API调用次数、存储开销。
4.2 常用基准数据集与新基准进展
1. 经典基准数据集
- 多跳问答:HotpotQA、2WikiMultihopQA、MuSiQue(检验多跳推理能力)。
- 复杂问答:WebQSP、ComplexWebQuestions(CWQ,含结构化查询成分)。
- 图谱驱动QA:KGQAgen-10k(专门针对知识图谱问答设计)。
2. 现有基准的三大缺陷
- 任务过浅:多为事实拼接,缺乏真实复杂的因果链推理任务。
- 语料松散:缺乏结构化领域知识,图结构优势无法充分发挥。
- 指标片面:仅关注最终答案,忽略图构建质量、检索路径完整性等过程指标。
3. 新基准框架:GraphRAG-Bench
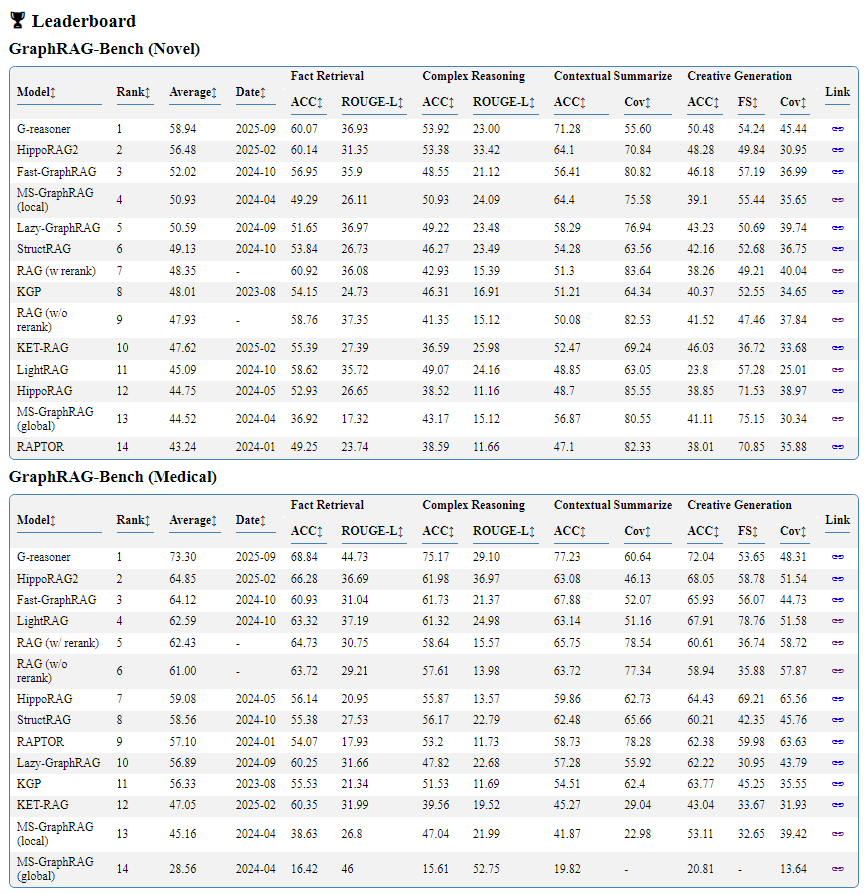
厦门大学等团队2025年提出的GraphRAG-Bench,从任务、语料、指标三方面优化:
- 设计“事实检索-多跳推理-上下文摘要-创意生成”阶梯式任务;
- 整合结构化领域知识与非结构化文本;
- 实现“图构建-检索-生成”全流程评估,更精准衡量GraphRAG的真实能力。
五、生产环境部署实践与挑战
将GraphRAG从实验室推向生产,需解决图谱维护、性能优化、安全防护等工程难题,以下为关键实践要点:
5.1 核心部署挑战
- 图谱构建与动态维护:高质量图谱构建耗时耗力;生产环境需支持增量更新(如每日新增企业年报),避免全量重建的高成本。
- 性能与可扩展性瓶颈:随着图谱规模扩大(千万级节点),检索延迟显著上升;高并发场景下吞吐量难以保障,易出现内存溢出。
- 安全与隐私风险:引入外部数据源可能导致隐私泄露;存在模型中毒(注入恶意数据)、检索模块攻击等安全隐患。
- 成本控制压力:图数据库存储、GPU向量化计算、多轮推理的API调用成本较高,大规模部署需精细化优化。
5.2 生产部署关键实践
1. 环境准备与依赖优化
系统级依赖:推荐Ubuntu 20.04/22.04,安装build-essential、poppler-utils、tesseract-ocr等工具;GPU推荐T4/A10/A100(至少6GB显存),内存≥16GB,SSD存储≥100GB。
Python环境:推荐Python 3.10,通过虚拟环境隔离依赖,核心包包括torch(CUDA版本)、图数据库驱动(如neo4j-python-driver)、向量嵌入模型(如text-embedding-3-small)。
2. 存储与检索优化
中小规模场景(文档数<100万):采用Docker Compose部署Milvus单机版,搭配Neo4j图数据库,简化运维:
# 下载Milvus Docker Compose配置
wget https://github.com/milvus-io/milvus/releases/download/v2.3.3/milvus-standalone-docker-compose.yml -O docker-compose.yml
# 启动服务
docker-compose up -d
# 验证状态
docker-compose ps
大规模场景(文档数>100万):部署Milvus集群(etcd+MinIO+Coordinator+Data Node+Query Node),实现负载均衡与高可用;建立实体属性、关系类型、时间戳多维度索引,提升检索效率。
3. 增量更新与缓存策略
采用全量构建+增量更新模式:
- 每日新增数据通过轻量IE管线抽取三元组,增量写入图谱;
- 对高频查询的子图结果建立缓存(如Redis),降低重复检索成本。
4. 安全防护措施
- 数据层面:对敏感数据(如患者病历)进行脱敏处理,采用私有化部署隔离外部风险;
- 模型层面:引入对抗训练,抵御恶意查询攻击;
- 接口层面:添加身份认证与权限控制,限制图谱访问范围。
总结
GraphRAG通过知识图谱的结构化语义建模,突破了传统RAG在复杂查询场景下的核心瓶颈,实现了从信息检索到知识利用的范式革新。2025年前沿框架已形成重量级全局方案-轻量级极速方案-模块化自适应方案-迭代时序方案的多元化格局,适配不同资源约束与场景需求。
未来发展方向集中在三方面:
- 轻量化优化,降低GraphRAG的部署成本与延迟,推动大规模普及;
- 动态图谱技术,提升增量更新效率与时序建模能力;
- 评估体系完善,基于GraphRAG-Bench等新基准实现更精准的性能衡量。
随着这些技术的成熟,GraphRAG将在金融、医疗、工业等领域发挥更大价值,成为企业级LLM应用的核心支撑技术。
参考文献
- From Local to Global: A Graph RAG Approach to Query-Focused Summarization. arXiv:2404.16130.
- Microsoft GraphRAG Documentation
- LightRAG: Simple and Fast Retrieval-Augmented Generation. arXiv:2410.05779.
- HKUDS LightRAG Repository
- FRAG: A Flexible Modular Framework for Retrieval-Augmented Generation based on Knowledge Graphs. arXiv:2501.09957
- [GraphIRAG: A Knowledge Graph-Based Iterative Retrieval-Augmented Generation Framework for Temporal Reasoning. arXiv:2503.14234]([2503.14234] Beyond Single Pass, Looping Through Time: KG-IRAG with Iterative Knowledge Retrieval (arxiv.org))
- RAG系统部署实战:从开发到生产的全流程
- LangChain太重?LightRAG性能实测
- [GraphRAG真的比传统RAG更强吗](

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)