OpenClaw 语音交互:TTS 和语音识别集成指南
本文详细介绍 OpenClaw 平台语音交互功能的完整集成方案。从 TTS 语音合成的基础配置到语音识别的深度集成,涵盖技术架构、代码实现、多语言支持和性能优化。通过实战案例展示如何构建自然的语音对话体验,包括智能语音助手、语音播报系统和多模态交互设计。文章提供完整的代码示例、故障排查指南和安全最佳实践,帮助开发者快速掌握 OpenClaw 语音能力,打造人性化的智能交互系统。
一、引言
1.1 语音交互的时代意义
在人工智能技术飞速发展的今天,语音交互已成为人机沟通最自然、最高效的方式之一。据统计,人类日常交流中约 70% 的信息通过语音传递,语音交互的响应速度比文本输入快 3 倍以上。对于智能助手系统而言,具备语音能力不再是"锦上添花",而是"必备技能"。
OpenClaw 作为一个强大的智能体编排框架,原生集成了 TTS(Text-to-Speech,文本转语音)功能,并支持与外部语音识别服务的深度集成。这使得开发者能够快速构建具备"听"和"说"能力的智能应用,实现真正自然的人机对话体验。
1.2 OpenClaw 语音能力概览
OpenClaw 的语音交互体系包含以下核心能力:
| 能力模块 | 功能描述 | 支持状态 |
|---|---|---|
| TTS 语音合成 | 将文本转换为自然语音 | ✅ 原生支持 |
| 语音识别 | 将语音转换为文本 | 🔌 可扩展集成 |
| 多语言支持 | 中文、英文、日文等多种语言 | ✅ 支持 |
| 情感语音 | 根据内容调整语调和情感 | ✅ 部分支持 |
| 离线处理 | 无需网络的本地语音处理 | 🔌 可配置 |
| 实时流式 | 低延迟的流式语音处理 | ✅ 支持 |
1.3 本文目标与读者对象
本文旨在为开发者提供一份完整的 OpenClaw 语音交互集成指南。无论您是:
- 初学者:希望快速了解 OpenClaw 语音功能的基本用法
- 进阶开发者:需要深入理解语音系统的架构和优化技巧
- 架构师:规划企业级语音交互解决方案
都能从本文中获得有价值的信息和实践指导。
二、OpenClaw TTS 系统详解
2.1 TTS 工具架构
OpenClaw 的 TTS 功能通过 tts 工具实现,其核心架构如下:
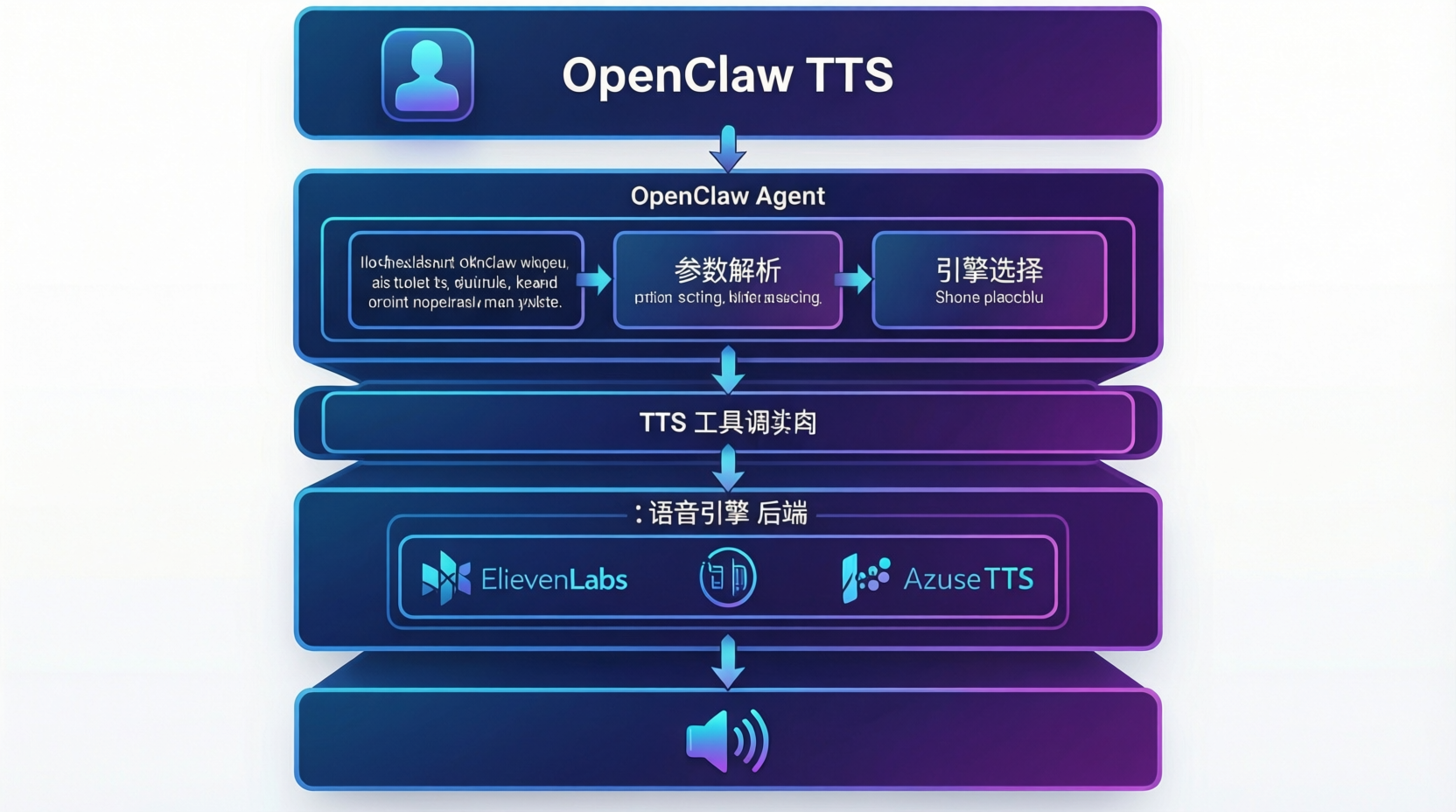
2.2 支持的语音引擎
OpenClaw 支持多种 TTS 引擎,每种引擎有其独特的优势:
2.2.1
自然、富有情感的语音合成效果,特别适合:
- 故事讲述和有声书
- 角色配音和多声音切换
- 需要情感表达的场景
tts:
provider: elevenlabs
voice: "Nova" # 温暖、略带英式口音
model: "eleven_monolingual_v1"
stability: 0.5
similarity_boost: 0.752.2.2
企业级的稳定性和多语言支持:
- 支持 100+ 语言和方言
- 神经语音质量高
- 适合企业级应用
tts:
provider: azure
voice: "zh-CN-XiaoxiaoNeural"
region: "eastasia"
output_format: "audio-24khz-160kbitrate-mono-mp3"2.2.3 本地引擎(离线场景)
对于隐私敏感或网络受限的场景,可使用本地 TTS 引擎:
- Piper:轻量级、高质量的本地 TTS
- Coqui TTS:开源、可定制
- espeak-ng:经典、资源占用低
2.3 配置参数说明
OpenClaw TTS 工具的核心参数如下:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
text |
string | ✅ | 待转换为语音的文本内容 |
channel |
string | ❌ | 指定输出渠道(如 telegram),影响音频格式 |
完整调用示例:
// 基础调用
{
"action": "tts",
"text": "您好,欢迎使用 OpenClaw 语音系统。"
}
// 指定渠道(优化格式)
{
"action": "tts",
"text": "这是一条 Telegram 消息的语音版本。",
"channel": "telegram"
}2.4 代码示例与最佳实践
2.4.1 基础语音播报
// 示例 1:简单文本转语音
async function speak(text) {
const result = await callTool('tts', { text });
// 音频自动交付,无需额外处理
return result;
}
// 使用示例
speak("您好,我是您的智能助手领主。有什么可以帮您的吗?");2.4.2 多段落语音生成
// 示例 2:长文本分段处理
async function speakLongText(fullText) {
// 按句子分割,避免单次处理过长文本
const sentences = fullText.split(/(?<=[。!?.!?])\s+/);
for (const sentence of sentences) {
if (sentence.trim().length > 0) {
await callTool('tts', { text: sentence.trim() });
// 添加短暂停顿,使语音更自然
await sleep(200);
}
}
}2.4.3 情感化语音
// 示例 3:根据内容调整语音风格
async function speakWithEmotion(text, emotion = 'neutral') {
const emotionMarkers = {
'happy': '😊 ',
'sad': '😔 ',
'excited': '🎉 ',
'serious': '⚠️ ',
'neutral': ''
};
const markedText = emotionMarkers[emotion] + text;
return await callTool('tts', { text: markedText });
}
// 使用示例
speakWithEmotion("太棒了!任务已完成!", "excited");
speakWithEmotion("请注意,系统检测到异常。", "serious");2.4.4 最佳实践总结
- 文本长度控制:单次 TTS 调用建议不超过 500 字,长文本应分段处理
- 标点符号使用:正确使用标点可显著改善语音停顿和语调
- 特殊字符处理:移除或转义 emoji、特殊符号,避免合成异常
- 渠道适配:不同消息渠道可能需要不同的音频格式,使用
channel参数优化 - 错误处理:始终添加 try-catch 处理 TTS 调用失败的情况
三、语音识别集成方案
3.1 语音识别技术选型
语音识别(Speech-to-Text, STT)是将人类语音转换为文本的技术。OpenClaw 虽未原生集成 STT 工具,但可通过以下方式实现:
3.1.1 云端服务方案
有的准确率高、多语言支持,可以企业级应用;有的实时性好、生态完善,移动端应用;有的中文识别优秀、成本低,中文场景;有的开源、可自部署,隐私敏感场景
3.1.2 本地部署方案
对于数据隐私要求高的场景,推荐本地部署:
- Whisper:OpenAI 开源模型,支持多语言
- Vosk:轻量级、离线可用
- Kaldi:学术研究级、高度可定制
3.2 与 OpenClaw 的集成方式
3.2.1 通过 exec 工具调用外部服务
// 示例:使用 Whisper 进行语音识别
async function transcribeAudio(audioPath) {
const result = await callTool('exec', {
command: `whisper "${audioPath}" --model base --output_format json`
});
const transcription = JSON.parse(result.stdout);
return transcription.text;
}3.2.2 通过 HTTP 请求调用 API
// 示例:调用 Azure Speech API
async function transcribeWithAzure(audioBuffer) {
const response = await fetch('https://eastasia.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1', {
method: 'POST',
headers: {
'Ocp-Apim-Subscription-Key': AZURE_KEY,
'Content-Type': 'audio/wav'
},
body: audioBuffer
});
const result = await response.json();
return result.DisplayText;
}3.2.3 集成到 OpenClaw 技能系统
创建自定义语音识别技能:
# skills/voice-stt/SKILL.md
## 触发条件
- 用户发送语音消息
- 用户明确要求"转写语音"
## 执行流程
1. 接收语音文件
2. 调用 STT 服务
3. 返回文本结果
4. 可选:触发后续处理3.3 实时语音处理流程
实时语音交互需要流式处理,以下是完整流程:
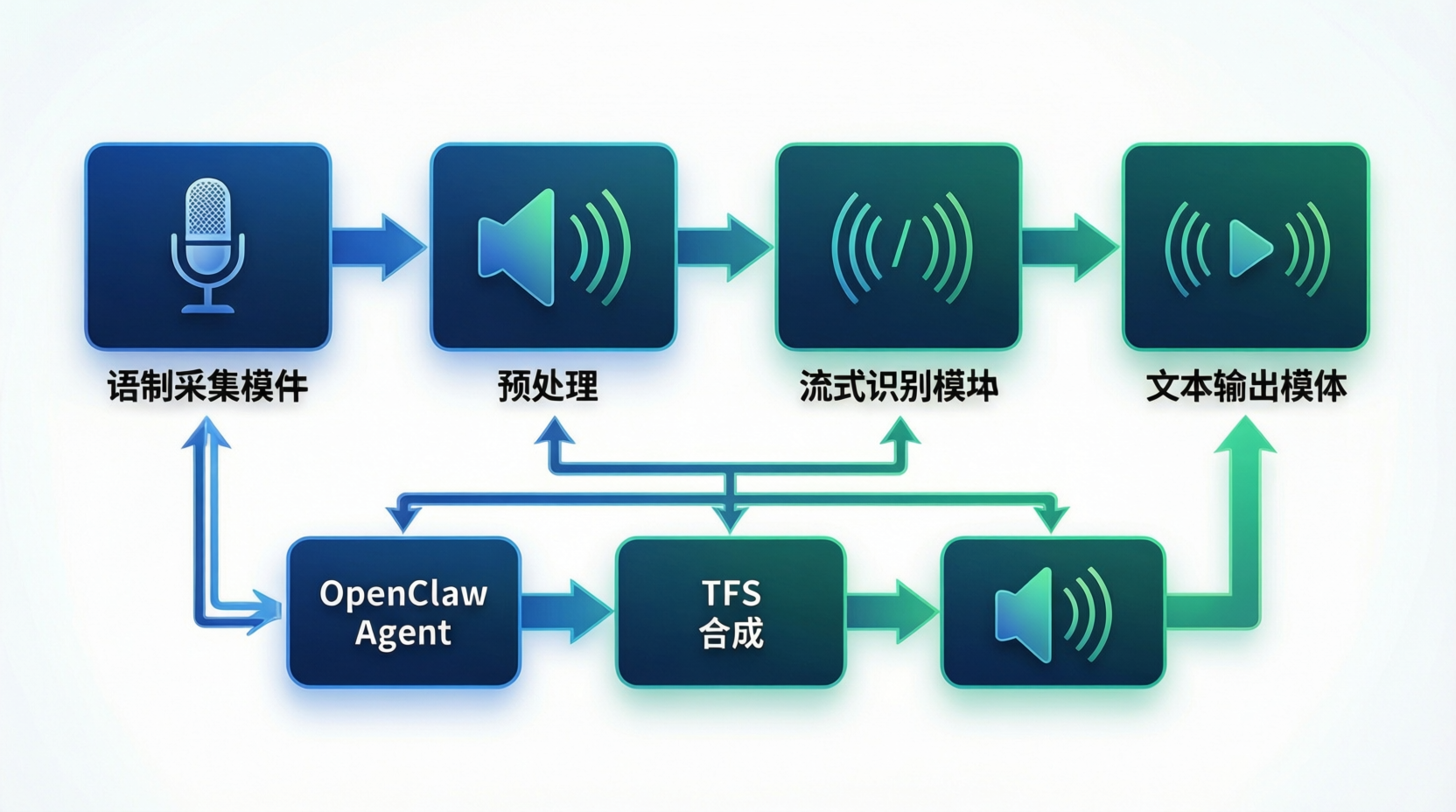
关键组件说明:
- VAD(Voice Activity Detection):检测语音活动,减少静音处理
- 分片处理:将音频流切分为小片段,实现低延迟识别
- 上下文保持:维护对话历史,提升识别准确率
3.4 多语言支持策略
OpenClaw 的语音系统需要支持多语言场景,以下是推荐策略:
3.4.1 语言自动检测
async function detectAndTranscribe(audioBuffer) {
// 第一步:语言检测
const langResult = await callTool('exec', {
command: `langid < "${audioBuffer}"`
});
const detectedLang = langResult.stdout.trim();
// 第二步:根据语言选择识别模型
const sttConfig = {
'zh': { model: 'whisper-large-v3-zh', prompt: '请用中文标点' },
'en': { model: 'whisper-large-v3', prompt: '' },
'ja': { model: 'whisper-large-v3-ja', prompt: '日本語で転写' },
'default': { model: 'whisper-large-v3', prompt: '' }
};
const config = sttConfig[detectedLang] || sttConfig['default'];
// 第三步:执行识别
return await transcribeWithConfig(audioBuffer, config);
}3.4.2 多语言 TTS 配置
### TTS 多语言配置
- 中文语音:Azure zh-CN-XiaoxiaoNeural
- 英文语音:Azure en-US-JennyNeural
- 日文语音:Azure ja-JP-NanamiNeural
- 默认语音:ElevenLabs Nova四、高级功能实现
4.1 语音对话状态管理
复杂的语音对话需要维护状态,以下是对话状态机的实现:
class VoiceConversationState {
constructor() {
this.state = 'IDLE';
this.context = {};
this.history = [];
}
async transition(newState, data = {}) {
const validTransitions = {
'IDLE': ['LISTENING', 'SPEAKING'],
'LISTENING': ['PROCESSING', 'IDLE'],
'PROCESSING': ['SPEAKING', 'IDLE'],
'SPEAKING': ['IDLE', 'LISTENING']
};
if (!validTransitions[this.state].includes(newState)) {
throw new Error(`Invalid transition from ${this.state} to ${newState}`);
}
this.state = newState;
this.context = { ...this.context, ...data };
// 状态变更日志
this.history.push({
timestamp: Date.now(),
from: this.state,
to: newState,
data
});
}
}4.2 情感语音合成
情感语音可以让交互更加自然和人性化:
// 情感参数映射
const emotionProfiles = {
'neutral': { stability: 0.5, similarity: 0.75, style: 0 },
'happy': { stability: 0.4, similarity: 0.8, style: 0.3 },
'sad': { stability: 0.6, similarity: 0.7, style: -0.2 },
'excited': { stability: 0.3, similarity: 0.85, style: 0.5 },
'serious': { stability: 0.7, similarity: 0.65, style: -0.1 }
};
async function speakWithEmotion(text, emotion = 'neutral') {
const profile = emotionProfiles[emotion];
// 根据情感调整文本(添加语气词等)
const modifiedText = addEmotionMarkers(text, emotion);
return await callTool('tts', {
text: modifiedText
// 注意:具体情感参数取决于 TTS 引擎支持
});
}
function addEmotionMarkers(text, emotion) {
const markers = {
'happy': '太棒了!',
'sad': '唉,',
'excited': '哇!',
'serious': '请注意,'
};
return markers[emotion] ? markers[emotion] + text : text;
}4.3 离线语音处理
对于隐私敏感或网络受限的场景,离线语音处理是必要的:
4.3.1 本地 TTS 部署
# 安装 Piper TTS
git clone https://github.com/rhasspy/piper.git
cd piper
pip install -r requirements.txt
# 下载中文语音模型
wget https://huggingface.co/rhasspy/piper-voices/resolve/main/zh/zh_CN/Xiaoxiao/zh_CN-Xiaoxiao-medium.onnx4.3.2 本地 STT 部署
# 安装 Whisper
pip install openai-whisper
# 下载模型
whisper-download --model medium4.4 性能优化技巧
4.4.1 缓存机制
// TTS 结果缓存
const ttsCache = new Map();
async function cachedTTS(text) {
const cacheKey = hash(text);
if (ttsCache.has(cacheKey)) {
return ttsCache.get(cacheKey);
}
const result = await callTool('tts', { text });
ttsCache.set(cacheKey, result);
// 限制缓存大小
if (ttsCache.size > 100) {
const firstKey = ttsCache.keys().next().value;
ttsCache.delete(firstKey);
}
return result;
}4.4.2 并发控制
// 限制同时 TTS 请求数量
class TTSRateLimiter {
constructor(maxConcurrent = 3) {
this.maxConcurrent = maxConcurrent;
this.current = 0;
this.queue = [];
}
async execute(ttsCall) {
if (this.current >= this.maxConcurrent) {
return new Promise(resolve => this.queue.push(resolve));
}
this.current++;
try {
return await ttsCall();
} finally {
this.current--;
if (this.queue.length > 0) {
const next = this.queue.shift();
next();
}
}
}
}五、实战案例
5.1 智能语音助手搭建
场景:构建一个能够语音对话的个人助手
架构设计:
用户语音 → STT → OpenClaw Agent → 处理逻辑 → TTS → 语音回复
实现代码:
// 语音助手主循环
async function voiceAssistantLoop() {
const state = new VoiceConversationState();
while (true) {
try {
// 1. 等待语音输入
state.transition('LISTENING');
const audio = await captureAudio();
// 2. 语音识别
state.transition('PROCESSING');
const text = await transcribeAudio(audio);
// 3. Agent 处理
const response = await processWithAgent(text);
// 4. 语音回复
state.transition('SPEAKING');
await speak(response.text);
// 5. 回到空闲状态
state.transition('IDLE');
} catch (error) {
console.error('语音助手错误:', error);
state.transition('IDLE');
await speak('抱歉,我遇到了一些问题。请稍后再试。');
}
}
}5.2 语音播报系统集成
场景:为消息系统添加语音播报功能
// 消息语音播报技能
async function voiceMessageSkill(message) {
// 检查用户偏好
const userPrefs = await getUserPreferences(message.userId);
if (userPrefs.voiceEnabled) {
// 根据消息类型选择语音风格
const style = getMessageStyle(message.type);
// 生成语音
await callTool('tts', {
text: formatMessageForSpeech(message.content),
channel: message.channel
});
}
}
function formatMessageForSpeech(content) {
// 移除 markdown,添加适当停顿
return content
.replace(/[*#`]/g, '')
.replace(/\n/g, '。')
.trim();
}5.3 多模态交互设计
场景:结合文本、语音、图像的丰富交互
设计原则:
- 互补性:不同模态传递不同类型的信息
- 冗余性:关键信息通过多模态重复,确保传达
- 适应性:根据场景自动选择最佳模态组合
async function multimodalResponse(content, options = {}) {
const responses = [];
// 文本响应(始终发送)
responses.push({ type: 'text', content: content.text });
// 语音响应(用户启用时)
if (options.voice) {
responses.push({ type: 'voice', content: content.text });
}
// 图像响应(如有)
if (content.image) {
responses.push({ type: 'image', content: content.image });
}
// 发送所有响应
for (const response of responses) {
await sendResponse(response);
}
}六、故障排查与优化
6.1 常见问题解决方案
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| TTS 无响应 | API 密钥失效 | 检查并更新密钥配置 |
| 语音质量差 | 采样率不匹配 | 调整输出格式参数 |
| 识别准确率低 | 背景噪音 | 添加 VAD 和降噪预处理 |
| 延迟过高 | 网络问题 | 使用本地引擎或就近节点 |
| 多语言识别错误 | 语言检测失败 | 手动指定语言参数 |
6.2 性能监控与调优
// 语音系统监控
const metrics = {
ttsLatency: [],
sttLatency: [],
errorRate: 0,
successRate: 0
};
async function monitorVoiceSystem() {
setInterval(() => {
console.log('=== 语音系统监控 ===');
console.log(`TTS 平均延迟:${avg(metrics.ttsLatency)}ms`);
console.log(`STT 平均延迟:${avg(metrics.sttLatency)}ms`);
console.log(`成功率:${metrics.successRate}%`);
}, 60000); // 每分钟报告
}6.3 安全与隐私考虑
- 数据传输加密:所有语音数据使用 HTTPS 传输
- 本地处理优先:敏感内容优先使用本地引擎
- 数据留存策略:明确语音数据的存储和删除策略
- 用户知情同意:明确告知用户语音数据的用途
- 访问控制:限制语音功能的访问权限
七、总结与展望
7.1 核心要点回顾
本文详细介绍了 OpenClaw 语音交互系统的完整集成方案:
- TTS 系统:理解架构、选择引擎、掌握配置
- STT 集成:技术选型、集成方式、实时处理
- 高级功能:状态管理、情感语音、离线处理
- 实战案例:语音助手、播报系统、多模态交互
- 故障排查:常见问题、性能监控、安全考虑
7.2 未来发展方向
OpenClaw 语音交互的未来发展将聚焦于:
- 更自然的语音合成:情感更丰富、表达更自然
- 更准确的语音识别:方言支持、噪音环境优化
- 更低的延迟:端到端延迟降至 100ms 以内
- 更强的上下文理解:基于对话历史的智能响应
- 更好的多模态融合:语音、文本、视觉的无缝整合
语音交互的未来不是替代人类交流,而是增强人类能力。通过 OpenClaw 这样的框架,开发者可以快速构建人性化的智能系统,让技术真正服务于人。
📚 附录:资源链接
- OpenClaw 官方文档:https://openclaw.dev
- ElevenLabs TTS:https://elevenlabs.io
- Azure Speech Services:https://azure.microsoft.com/speech
- Whisper 开源项目:https://github.com/openai/whisper
- Piper TTS:https://github.com/rhasspy/piper

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)