CC-Switch 使用攻略:一键管理多款 AI CLI 工具配置
CC-Switch 简介与下载地址
在日常的开发工作中,我们经常会同时使用多个命令行界面的 AI 编程辅助工具,例如 Claude Code、OpenCode、Codex 或 Gemini CLI。这些工具默认都有各自独立的配置文件和目录。当我们需要切换 API 供应商、更改模型或者更新 API Key 时,通常需要手动打开多个不同的 JSON、TOML 或环境变量文件进行修改。
CC-Switch 是一个基于 Tauri 和 Rust 开发的桌面客户端工具,它的主要作用是为上述多个 AI 编程工具提供一个统一的图形化配置界面。通过它,开发者可以在一个软件中管理所有 AI CLI 工具的配置信息。
![[图片: CC-Switch 软件的主界面展示,包含服务商列表和应用切换标签]](https://i-blog.csdnimg.cn/direct/666a158578484c6cbb7ebaf4cae636d5.png)
下载地址与安装方式
CC-Switch 支持跨平台使用。你可以通过以下方式获取并安装:
-
GitHub 发布页 (推荐)
访问项目的官方开源仓库:https://github.com/farion1231/cc-switch
在右侧的 Releases 页面中,你可以找到对应操作系统的安装包:- macOS: 下载
.dmg文件(已通过 Apple 签名和公证,可直接安装)。 - Windows: 下载
.exe或.msi安装程序。 - Linux: 下载
.AppImage或.deb包。
- macOS: 下载
-
包管理器安装
如果你习惯使用命令行,也可以通过包管理器进行安装:- macOS (Homebrew): 可以通过
brew install cc-switch命令安装。 - Arch Linux (paru): 可以通过
paru -S cc-switch命令安装。
- macOS (Homebrew): 可以通过
对于没有图形界面环境的服务器或纯终端用户,该项目还有一个名为 cc-switch-cli 的纯命令行分支版本,提供与桌面版相同的数据同步和配置管理功能。
CC-Switch 的主要好处
使用 CC-Switch 管理 AI 编程工具的配置,主要可以带来以下几个方面的便利:
统一的服务商与模型管理
工具内置了常见的 API 服务商预设。开发者可以添加多个不同的服务商信息(包括 Base URL、API Key 和支持的模型列表)。配置完成后,通过界面上的切换按钮,可以将选定的服务商配置直接应用到目标 CLI 工具中,不需要再手动查找和编辑底层的配置文件。
多套系统提示词(Prompts)管理
不同的开发项目可能需要 AI 遵循不同的代码规范或前置条件。CC-Switch 提供了一个支持 Markdown 的编辑器,允许你建立多套系统提示词。你可以根据当前的项目需求,在工具中选中对应的提示词模板,它会自动同步到类似 CLAUDE.md 或 AGENTS.md 这样的文件中。
![[图片: CC-Switch 的提示词编辑界面]](https://i-blog.csdnimg.cn/direct/b0168dfac52647a6bf569f9832f96546.png)
清晰的会话管理
在使用 AI 编程工具时,每次交互都会产生相应的会话记录。CC-Switch 提供了可视化的会话管理面板。它会自动读取各个目标 CLI 工具的本地缓存目录,将所有的历史会话进行集中展示。在界面上,可以直接查看每一个会话的起始时间、绑定的项目目录路径以及当前已经消耗的 Token 统计信息。这种集中管理方式避免了手动进入多个隐藏文件夹逐一删除缓存文件的繁琐步骤,确保了工作区环境的整洁。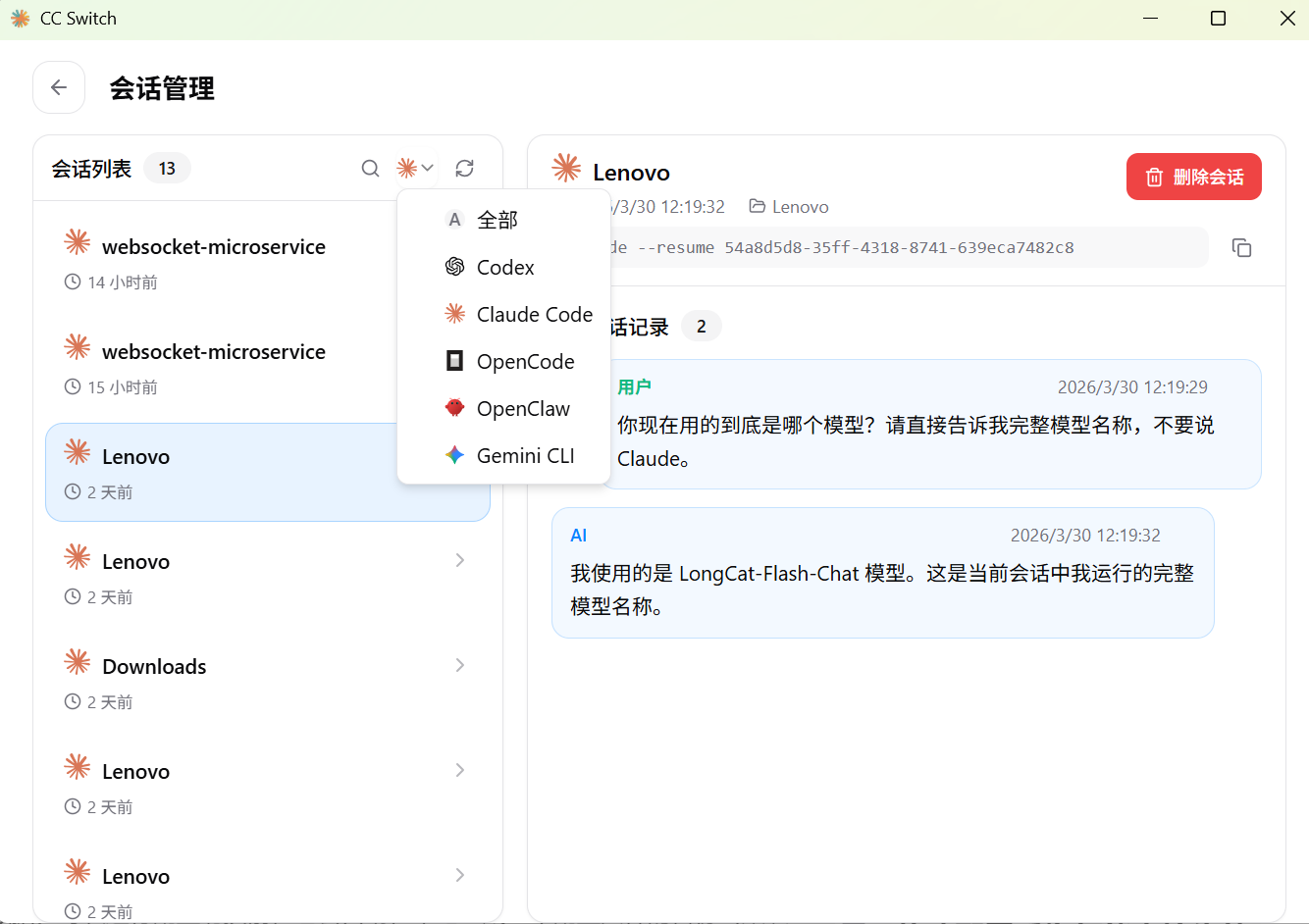
配置数据的本地存储与备份
CC-Switch 使用 SQLite 数据库(存放在 ~/.cc-switch/cc-switch.db)来保存你的所有配置数据。每次进行配置切换前,它会自动在本地生成一个配置文件的备份(默认保留最近 10 个版本)。如果新的配置导致工具运行异常,你可以随时恢复到之前的状态。
修改配置后为何能直接生效
在使用 CC-Switch 时,你会发现只要在界面上点击了切换,或者修改了某个参数,接下来直接在终端里运行 Claude Code 或 OpenCode,新的配置就已经生效了,通常不需要重启终端或执行额外的重载命令。
这背后的原理涉及这些 AI 编程工具读取配置的机制以及 CC-Switch 的写入策略。
目标工具的配置文件读取机制
无论是 Claude Code 还是 OpenCode,它们在每次执行命令或发起新的 API 请求前,都会去读取本地的配置文件。
- Claude Code 主要读取全局的
~/.claude/settings.json以及项目目录下的.claude/settings.json。 - OpenCode 主要读取
~/.config/opencode/目录下的相关配置文件。
这些工具在设计时并没有将配置信息永久缓存在常驻内存中,或者它们实现了对配置文件的热重载(Hot-reload)监听。因此,只要底层的文件内容被改变,工具在下一次执行动作时就会使用新的参数。
CC-Switch 的原子写入操作
当你通过 CC-Switch 修改配置时,它并不是简单地发送一个系统通知,而是直接去修改上述的底层配置文件。为了防止在写入过程中发生文件损坏(例如写入一半时断电或进程被杀),CC-Switch 采用了原子写入(Atomic Writes)技术。
具体的流程是:
- CC-Switch 将新的配置数据格式化为目标工具所需的格式(JSON 或 TOML)。
- 将数据写入一个同一目录下的临时文件中(例如
settings.json.tmp)。 - 调用操作系统的文件重命名接口,将临时文件瞬间覆盖原有的配置文件。
这种方式保证了配置文件的更新是瞬间完成且完整的。因此,当你在终端中按下回车键让 Claude Code 或 OpenCode 执行任务时,它们读取到的永远是格式正确的最新配置,从而实现了“即改即生效”的使用体验。
MCP 与 SKILL 的随地配置与导入
在现代的 AI 编程工具中,MCP(Model Context Protocol,模型上下文协议)和 SKILL(技能/自定义函数)是扩展 AI 能力的两种主要方式。CC-Switch 对这两者提供了统一的管理方案。
MCP 服务的配置方式
MCP 是一种标准化协议,允许 AI 模型与外部的本地工具、文件系统或远程服务进行通信。在没有 CC-Switch 的情况下,你需要分别为 Claude Code 和 OpenCode 等AI编辑工具编写不同的 JSON 配置段落来注册 MCP 服务器。
在 CC-Switch 中,MCP 服务器的配置被抽象出来,放在了统一的面板中。你可以添加一个 MCP 服务器,并指定它的传输协议,目前主要支持三种:
- stdio:通过标准输入输出与本地进程通信。你需要提供可执行文件的路径和运行参数。
- http / sse:通过 HTTP 或 Server-Sent Events 与网络上的服务进行通信。你需要提供对应的 URL 端点。
配置完成后,CC-Switch 会利用其内置的双向同步机制(Bidirectional Sync)。当你勾选将某个 MCP 服务应用于 OpenCode 和 Claude Code 时,工具会自动将这个 MCP 的配置信息分别转化为这两个工具能识别的特定格式,并写入它们各自的配置文件中。这样就实现了 MCP 服务的一次配置、随地可用。
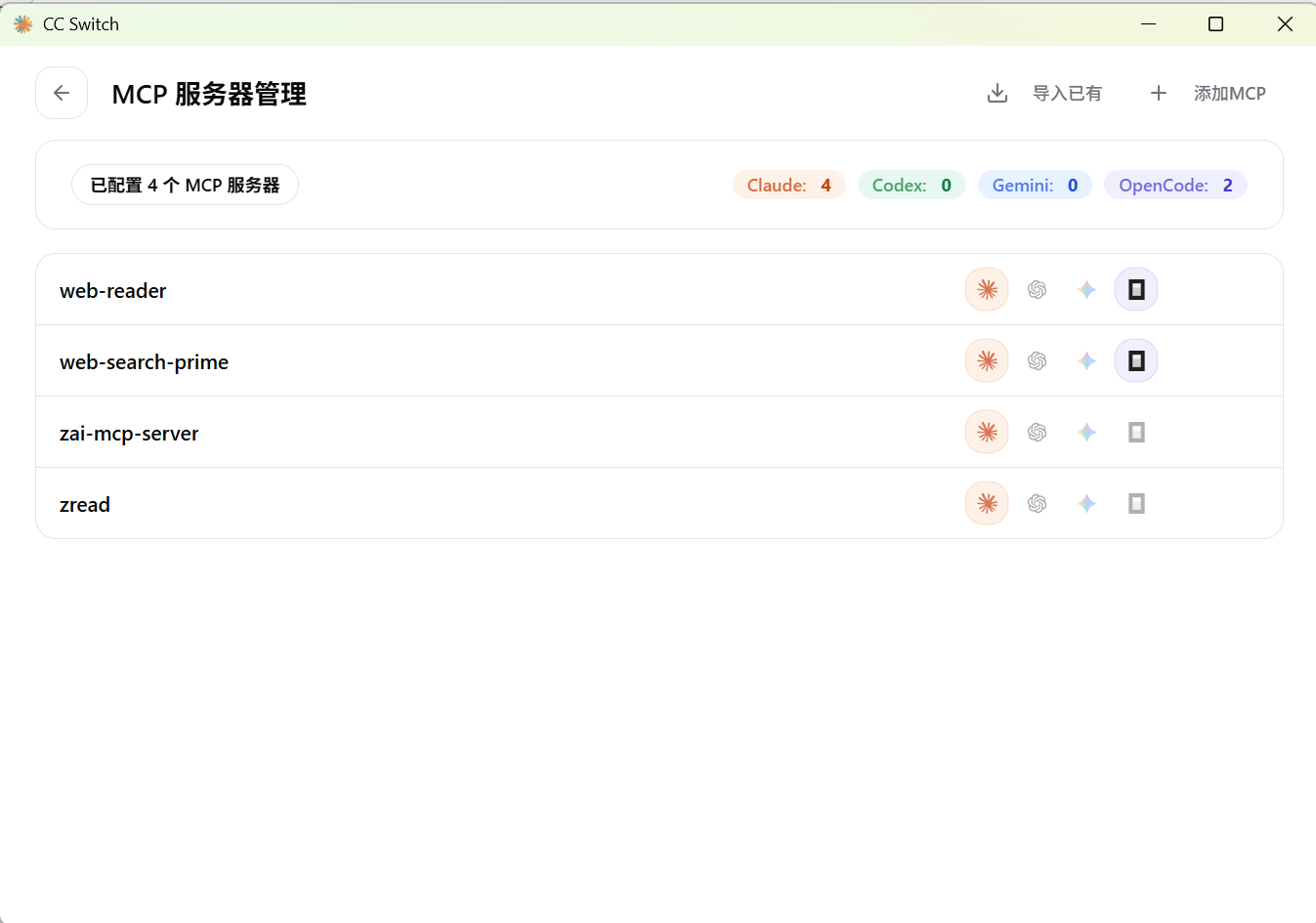
SKILL 的配置与旧配置导入
SKILL 通常是一组预定义的操作脚本或特定的功能包,用于让 AI 执行特定的任务链。
如果你之前一直在使用 OpenCode,并且在本地积累了很多 SKILL 和提示词,当你开始使用 CC-Switch 时,不需要从零开始重新配置。CC-Switch 具备自动发现和导入功能。
旧配置的自动导入
当你首次安装并运行 CC-Switch 时,它的后台服务会扫描系统中常见的 AI 工具配置目录(包括 ~/.config/opencode/)。
如果它检测到 OpenCode 的目录下存在已配置的 SKILL 文件夹(例如 ~/.config/opencode/skills/)以及自定义的提示词文件,它会触发导入流程。
- 读取与解析:工具会读取这些遗留的 JSON 或 Markdown 文件,解析其中的字段(如 SKILL 的名称、执行路径、环境变量要求等)。
- 入库记录:将这些解析后的数据写入到 CC-Switch 自己的 SQLite 数据库中。
- 建立软链接或复制:为了保持单一事实来源(SSOT),CC-Switch 会将你的 SKILL 统一存放在
~/.cc-switch/skills/目录下。对于原有的 OpenCode 目录,它会建立软链接指向新目录,或者根据你的选择进行文件复制。
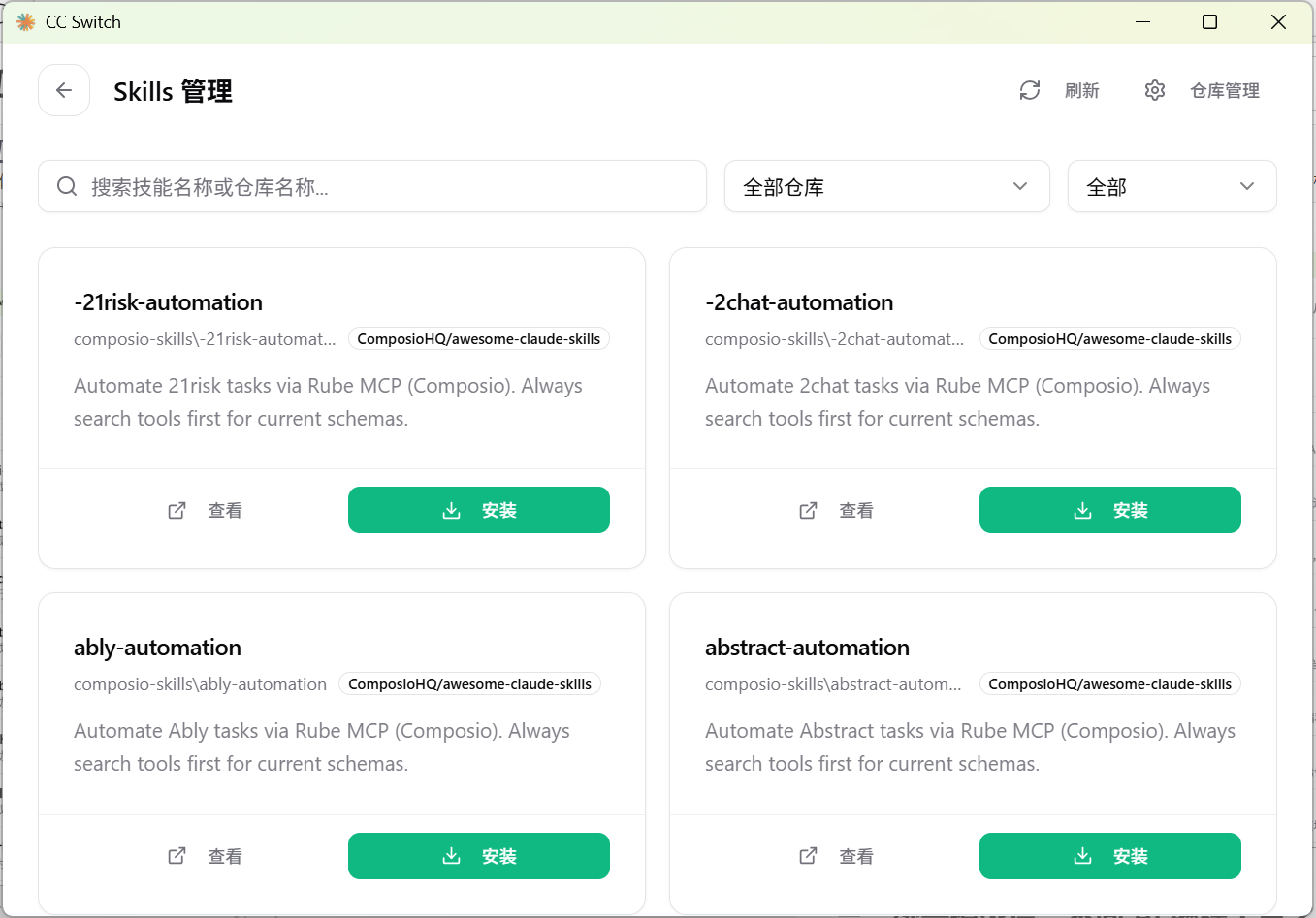
后续的管理与安装
完成导入后,就可以在 CC-Switch 的 SKILL 管理界面看到之前的配置。如果需要安装新的 SKILL,可以直接在界面中输入 GitHub 仓库的地址或者选择本地的 ZIP 压缩包。CC-Switch 会自动下载、解压,并将其注册到所有你启用的 AI 编程工具中。之前在 OpenCode 中的提示词也会被收录到 Prompts 面板中,供随时分配给不同的项目使用。
统一模型后,不同 AI 编程工具之间的差异
注意:一下并没有对 Claude Code 有吹捧的意思,各个 AI 编程工具都有各自的优势
在使用 CC-Switch 将不同工具(如 Claude Code 和 OpenCode)的 API 地址和模型(例如都指向某个兼容的 Claude 3.5 Sonnet 节点)统一后,会产生一个疑问:既然底层的模型供应商都换成了同一个,那使用 Claude Code、OpenCode 或其他类似的工具,出来的结果和体验不是都差不多吗?
实际上,AI 编程工具的运行依赖于两个核心部分:一个是“模型层”,另一个是“执行框架层”。虽然通过配置统一了模型层,但不同工具在执行框架层上存在着显著的技术差异。以下是具体的不同之处:
1. 上下文管理与代码库读取策略
即便向相同的模型发送请求,工具在发送请求前需要先将你的本地代码转化为文本上下文。这个组装上下文的过程,各家工具的实现方式完全不同。
Claude Code 拥有其特定的文件树遍历算法和文件分块(Chunking)策略。当它面对一个庞大的前端项目时,它内置的逻辑会决定先读取哪些核心文件(如 package.json),忽略哪些文件,以及如何将大文件截断,以适应模型的上下文窗口。
其它工具,其上下文收集机制可能采用了不同的逻辑。它们可能依赖于普通的 grep 或 ripgrep 命令结果,或者采用了不同的抽象语法树(AST)解析库。这意味着,即使模型相同,这些AI编程工具喂给模型的“初始信息”是不同的,这直接导致模型输出的代码质量和准确度存在差异。
2. 内置工具集(Tool Calling)的实现
现代的大语言模型具备调用工具(Tool Calling / Function Calling)的能力,但具体能调用哪些工具,是由外层的 CLI 软件决定的。
Claude Code 在其内部注册了一系列由 Anthropic 官方编写的系统级工具,比如特定的文件搜索工具、Bash 执行环境、文件差异比较(Diff)应用工具等。它在系统提示词中会告诉模型如何使用这些工具,并且这些工具的执行反馈格式是专门为了匹配 Claude 模型进行过优化的。
实现文件编辑的方式也可能仅仅是覆盖写入,而不是像 Claude Code 那样使用复杂的差异匹配写入。在执行 Bash 命令时的权限控制、超时时间设置、以及标准错误输出的捕获方式都会有所不同。这导致在使用相同模型时,不同AI编程工具修改文件的成功率、执行复杂终端命令的稳定性会有实质性的区别。
3. Agent 循环(Agentic Loop)与思维链控制
这两种工具在处理复杂任务时,都采用了 Agent 循环结构(例如接收指令 -> 思考 -> 执行工具 -> 获取结果 -> 再次思考)。
工具的开发者会在后台向模型注入隐藏的系统提示词(System Prompts),这些提示词定义了 Agent 的行为模式。Claude Code 的底层提示词经过了大量测试,强制要求模型在执行任何破坏性操作前进行深度的思维链(Chain of Thought)分析,并且严格规定了什么时候该停止循环向用户提问。
其它的 Agent 循环逻辑可能更为精简,或者采用了不同的规划-执行(Plan-and-Solve)架构。因此,可能会发现,在解决同一个复杂的系统 Bug 时,即使两者使用了相同的底层模型,Claude Code 可能会分成十个严谨的步骤去排查,而其它可能会尝试用三步直接修改代码。这就体现了执行框架层面的差异。
4. 错误处理与重试机制
当模型生成的代码存在语法错误,或者模型尝试调用的工具因为参数不对而报错时,CLI 工具的介入方式是不同的。
某些商业化的工具在捕获到这类错误时,会在后台静默地将错误信息整理后重新发送给模型,要求模型自我修正。用户可能只看到了一次短暂的等待。而一些开源工具可能没有实现复杂的自动重试逻辑,一旦遇到工具调用失败,就会直接将错误抛出到终端,要求用户介入手动解决。
总结
综上所述,虽然 CC-Switch 帮助我们极大地简化了 API 和模型的配置工作,让我们可以在不同的工具中自由复用相同的模型资源,但模型仅仅是“引擎”。Claude Code 和 OpenCode 相当于两辆设计不同、底盘不同、传动系统不同的“汽车”。
工具之间的差异体现在提示词工程、系统工具的健壮性、上下文的处理能力以及 Agent 执行架构上。因此,即使模型供应商已经统一,根据你所面对的具体开发任务(是简单的代码补全,还是复杂的大规模重构),选择合适的编程工具外壳依然是非常必要的。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)