核函数 详解
支持向量机通过某非线性变换 φ( x) ,将输入空间映射到高维特征空间。特征空间的维数可能非常高。如果支持向量机的求解只用到内积运算,而在低维输入空间又存在某个函数 K(x, x′) ,它恰好等于在高维空间中这个内积,即K( x, x′) =<φ( x) ⋅φ( x′) > 。那么支持向量机就不用计算复杂的非线性变换,而由这个函数 K(x, x′) 直接得到非线性变换的
参考资料
参考视频:
https://royalsociety.org/science-events-and-lectures/2014/11/milner-lecture/ 英文的
http://www.powercam.cc/slide/6552 建议看这个,中文的
http://www.powercam.cc/home.php?user=chli&f=slide&v=&fid=4097 ,这里面会讲解kernel 的基本概念, SVM,LDA,LR,PCA等如何使用kernel版本
书籍推荐:
《Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond 》购某东买链接:https://item.jd.com/1103869618.html
《kernel methods for pattern analysis》
某东购买链接:https://item.jd.com/1105344994.html
核函数定义
本文大致讲解核函数的定义,限制,使用等
机器学习中,对于线性可分的情况研究的比较透彻,可以采用svm/lr/感知机等成熟的机器学习模型,但是很多情况是我们希望我们的模型学习非线性的模型。通常的做法就是选择一个函数ϕ(x)ϕ(x)将xx映射到另一个空间中,这里的核心就是如何选择ϕ(x)ϕ(x).一般有三种做法
1)通过核函数,比如RBF。如果 φ(x) 具有足够高的维数,我们总是有足够的能力来拟合训练集,但是对于测试集的泛化往往不佳。非常通用的特征映射通常只基于局部光滑的原则,并且没有将足够的先验信息进行编码来解决高级问题。
2)另一种选择是手动地设计 φ,在深度学习以前,这种方法对于每个单独的任务都需要人们数十年的努力,从业者各自擅长特定的领域(如语音识别或计算机视觉),并且不同领域之间很难迁移 (transfer)。
3)深度学习方式是去学习这个函数ϕ(x)ϕ(x)
上面这段话来自《深度学习》
假设X是输入空间,H是特征空间,存在一个映射ϕϕ使得X中的点x能够计算得到H空间中的点h
对于所有的X中的点都成立,x,z是X空间中的点。函数k(x,z)满足条件:
都成立,则称k为核函数,而 ϕϕ为映射函数。
举个例子,如下图所示:
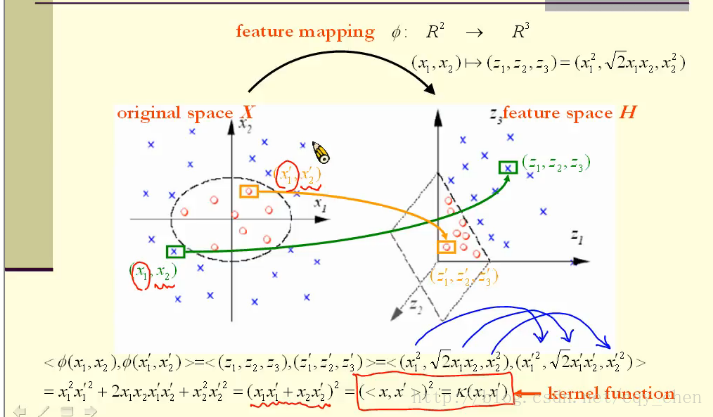
特征空间在三维空间中,原空间在二维,我们定义映射函数为, x=(x1,x2)x=(x1,x2):
那么如图所示:
原始空间的点x到特征空间的点为:
同时我们可以验证,
我们要进行高维空间的线性可分,首先要将原始空间的点通过函数ϕϕ映射到特征空间中,然后学习,而所谓的学习,其实就是要计算高维空间的点的距离和夹角。那么能不能不通过映射函数而直接使用核函数计算高维空间的点的距离以及夹角呢?
答案是可以的,核函数的技巧就是不显示的定义映射函数,而在高维空间中直接使用核函数进行计算。

所以我们在高维空间中进行计算的时候,其实根本不必要进行映射,然后再计算,而是直接先进行内积,然后使用核函数。
核函数的要求
首先介绍kernel矩阵,如下图所示: 
核矩阵,就是每个点之间的高维映射之后的内积构成的矩阵。
要称为核函数,核矩阵必须是半正定的。
常用的核函数有: 
在实际计算中,通常会选用高斯核。
核函数带来的好处很明显,如果先要映射到高维空间然后进行模型学习,计算量远远大于在低维空间中直接直接采用核函数计算
但是也有缺点,如果 φ(x) 具有足够高的维数,我们总是有足够的能力来拟合训练集,但是对于测试集的泛化往往不佳。非常通用的特征映射通常只基于局部光滑的原则,并且没有将足够的先验信息进行编码来解决高级问题
局部光滑原则,应该是区分传统机器学习和深度学习的重要特性。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)