视觉理解与图片问答,学习如何使用 GPT-4o (GPT-4 Omni) 来理解图像
视觉理解与图片问答,学习如何使用 GPT-4o (GPT-4 Omni) 来理解图像
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/
一、引言
OpenAI 最新发布的 GPT-4 Omni 模型,也被称为 GPT-4o,是一个多模态 AI 模型,旨在提供更加自然和全面的人机交互体验。
GPT-4o 与 GPT-4 Turbo 都具备视觉功能,这意味着模型能够处理图片并回答相关问题,为用户提供更丰富、更直观的交互体验。历史上,语言模型系统主要局限于处理文本这一单一输入模式,这在很大程度上限制了如 GPT-4 等强大模型的应用范围。之前,该模型有时被称为 GPT-4V 或在 API 中以 gpt-4-vision-preview 的形式出现。然而,请留意,当前的 Assistants API 尚不支持图片输入功能。
在用户消息中支持传递图片。模型获取图片主要有两种方式:一是通过传递图片链接,二是直接在请求中传递 Base64 编码的图片。
GPT-4 Vision 官方文档:https://platform.openai.com/docs/guides/vision,指导用户如何使用 GPT-4 的视觉功能:
- GPT-4 视觉功能:介绍了 GPT-4 模型如何理解图片,以及如何通过 API 使用这项功能。API 还能够处理多个图片输入,并根据所有图片信息来回答问题。
- 快速开始指南:提供了如何通过链接或直接在请求中传递 Base64 编码的图片来使用模型的方法。
- 图片细节控制:通过设置细节参数(低、高或自动),可以控制模型如何处理图片并生成文本理解。
- 图片处理限制:列出了模型在处理图片时的一些限制,例如:目前限制图片上传大小为每张 20MB、模型能够理解图片中的对象及其关系,但不适合精确空间定位或解读专业医学图像(例如 CT 扫描图像,高分辨率病理组织切片图像),以及可能无法正确理解非拉丁字母的文本等。
- 成本计算:解释了图片输入如何按 token 计费,以及如何根据图片大小和细节选项确定 token 成本。
总的来说,GPT-4 的图片理解功能对开发者而言极为实用,可广泛应用于食物识别以提供营养指南、社交媒体内容分析、艺术品鉴赏和科学图表解读等多个领域。
二、代码示例
安装所需的依赖库:
pip install -U openai
pip install requests==2.29.0
pip install urllib3==1.25.11
示例 1:使用图片 URL,以及英文 Prompt。
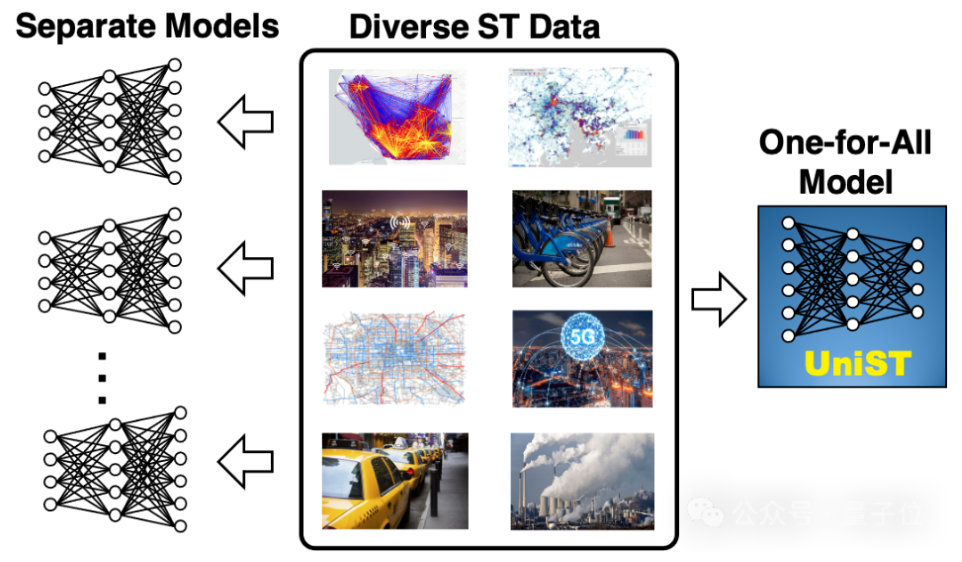
👇 测试图片如下所示,图片的链接为:https://s3.bmp.ovh/imgs/2024/06/22/88ba888d9fddda32.jpg

图片来源:UniST: A Prompt-Empowered Universal Model for Urban Spatio-Temporal Prediction
👇 Python 代码如下:
import base64
import requests
from openai import OpenAI
client = OpenAI(
api_key="sk-your_api_key",
base_url="https://api.openai.com/v1",
)
prompt = "Your task is to describe the content and details of this image in detail. Then explain what this image means."
image_url = "https://s3.bmp.ovh/imgs/2024/06/22/88ba888d9fddda32.jpg"
messages_template = [
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": image_url, "detail": "auto"}},
],
}
]
response = client.chat.completions.create(
model="gpt-4o",
messages=messages_template,
n=1,
max_tokens=1024,
temperature=0,
seed=42,
)
# print(response.json())
result = response.choices[0].message.content
print(result)
👇 生成结果如下:
The image is a conceptual diagram illustrating the transition from using multiple separate models to a unified model for handling diverse spatiotemporal (ST) data. Here is a detailed description of the content and its meaning:
Content Description:
-
Left Section (Separate Models):
- This section shows multiple neural network diagrams, each representing a separate model. These models are depicted as traditional neural networks with interconnected nodes and layers.
- Each model is associated with an arrow pointing towards the central section, indicating that each model is designed to handle specific types of data.
-
Central Section (Diverse ST Data):
- This section contains various images representing different types of spatiotemporal data:
- The first image appears to be a heatmap or density map.
- The second image shows a map with data points or clusters.
- The third image is a cityscape with some form of wireless communication overlay.
- The fourth image shows bicycles, likely indicating bike-sharing data.
- The fifth image is a map with routes or paths, possibly representing transportation networks.
- The sixth image shows a 5G network symbol, indicating telecommunications data.
- The seventh image depicts taxis, likely representing taxi service data.
- The eighth image shows industrial smokestacks, indicating pollution or environmental data.
- This section contains various images representing different types of spatiotemporal data:
-
Right Section (One-for-All Model):
- This section shows a single neural network diagram labeled “UniST,” representing a unified model.
- An arrow points from the diverse ST data to this unified model, indicating that this single model is designed to handle all types of spatiotemporal data.
Meaning:
The image illustrates the concept of moving from multiple specialized models to a single, unified model for processing diverse spatiotemporal data. Traditionally, different types of spatiotemporal data (such as traffic patterns, environmental data, telecommunications data, etc.) would require separate models, each tailored to the specific characteristics of the data. This approach can be resource-intensive and complex to manage.
The “One-for-All” model, labeled as “UniST,” represents a more efficient and streamlined approach. This unified model is designed to handle various types of spatiotemporal data within a single framework. The benefits of such a model include reduced complexity, improved scalability, and potentially better performance due to the shared learning across different data types.
In summary, the image conveys the transition from using multiple specialized models to a single, versatile model capable of handling a wide range of spatiotemporal data, thereby simplifying the modeling process and enhancing efficiency.
示例 2:本地多张图片,上传 Base64 编码的图片,以及中文 Prompt。
上传 Base64 编码的图片。若你本地有图片,无论是单张还是多张,都可以将其转换为 Base64 编码格式,然后传给模型。
多图输入:Chat Completions API 能够接收并处理多个图片输入,无论是 Base64 编码格式还是图片 URL。该模型将一同处理每张图片,并使用所有图片的信息来回答问题。
👇 测试的两张图片如下所示:

图片一来源:https://news.yxrb.net/2024/0621/4254.html
图片二来源:https://s3.bmp.ovh/imgs/2024/06/22/88ba888d9fddda32.jpg
👇 Python 代码如下:
import os
import base64
import requests
def encode_image(image_path):
"""
对图片文件进行 Base64 编码
输入:
- image_path:图片的文件路径
输出:
- 编码后的 Base64 字符串
"""
# 二进制读取模式打开图片文件,
with open(image_path, "rb") as image_file:
# 将编码后的字节串解码为 UTF-8 字符串,以便于在文本环境中使用。
return base64.b64encode(image_file.read()).decode("utf-8")
# 中文 Prompt 指令
prompt = (
"你的任务是详细描述图片包含的内容和细节。进而解释图片的含义。"
)
# 对本地多张图片进行 Base64 编码
images = os.listdir("./images")
images.sort()
print(images)
base64_images = [encode_image("./images/" + image) for image in images]
# 组织用户消息
user_content = [{"type": "text", "text": prompt}]
base64_images = [
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
"detail": "high",
},
}
for base64_image in base64_images
]
user_content.extend(base64_images)
messages_template = [{"role": "user", "content": user_content}]
# 构造请求参数
payload = {
"model": "gpt-4o",
"messages": messages_template,
"max_tokens": 1600,
"temperature": 0,
"seed": 2024,
}
# OpenAI API Key
api_key = "sk-your_api_key"
# 请求头
headers = {"Content-Type": "application/json", "Authorization": f"Bearer {api_key}"}
# 发送 POST 请求
response = requests.post(
"https://api.chatanywhere.com.cn/v1/chat/completions",
headers=headers, json=payload
)
# 打印生成结果
print(response.json())
result = response.json()["choices"][0]["message"]["content"]
print(result)
👇 生成结果如下:
图片一:游戏《王者荣耀国际服》登顶苹果商店免费游戏排行榜
内容和细节描述:
-
背景和主题:
- 图片的背景是橙色和白色的渐变,带有一些抽象的图案。
- 左上角有 “Honor of Kings” 的标志,表明这是关于《王者荣耀》的内容。
-
主要人物形象:
- 图片左侧有一个穿着红色和白色服装的女性角色,手持长棍,姿势英姿飒爽,显得非常有力量和自信。
-
文字信息:
- 图片顶部有大字标题:“《王者荣耀国际服》登顶苹果商店免费游戏排行榜”。
- 下面列出了多个国家和地区的名称,如“印尼/马来/菲律宾/柬埔寨/缅甸/老挝/新加坡/文莱/美国/加拿大/澳大利亚/新西兰/秘鲁/玻利维亚”,表明该游戏在这些地区的苹果商店中排名第一。
-
排行榜截图:
- 右侧有一个苹果商店排行榜的截图,显示《Honor of Kings》在免费游戏排行榜中排名第一。
- 下面有一个 “Download on the App Store” 的按钮,提示用户可以在苹果商店下载该游戏。
图片含义:
这张图片主要是宣传《王者荣耀国际服》在多个国家和地区的苹果商店免费游戏排行榜中登顶,展示了该游戏的全球受欢迎程度和影响力。通过展示排行榜截图和游戏角色形象,吸引更多玩家下载和体验这款游戏。
图片二:UniST 模型的概念图
内容和细节描述:
-
左侧:Separate Models:
- 左侧有多个独立的神经网络模型图示,表示传统方法中针对不同数据集使用不同的模型。
-
中间:Diverse ST Data:
- 中间部分展示了多种时空数据(ST Data)的图片,包括:
- 热力图
- 城市夜景
- 自行车共享系统
- 5G 网络
- 出租车
- 工业排放
- 这些图片展示了不同类型的时空数据,表明数据的多样性。
- 中间部分展示了多种时空数据(ST Data)的图片,包括:
-
右侧:One-for-All Model:
- 右侧展示了一个统一的神经网络模型,标注为 “UniST”。
- 这个模型整合了所有不同类型的数据,形成一个 “一体化” 的模型。
图片含义:
这张图片展示了一个名为 “UniST” 的统一模型的概念。传统方法中,不同类型的时空数据需要使用不同的模型进行处理,而 UniST 模型则能够整合多种不同类型的数据,形成一个通用的模型。这种方法可以提高模型的泛化能力和处理效率,适用于多种时空数据的分析和预测。
三、总结
总的来说,GPT-4o 在回答图片中存在什么这样的一般性问题上表现卓越。虽然它能理解图片中物体间的关联,但尚未能精确回答涉及物体具体位置的详细问题。例如,询问车辆的颜色或基于冰箱内容提供晚餐建议,GPT-4o 基本都能应对自如。然而,若展示一个房间图片并询问椅子位置,它可能无法给出准确答案。因此,在探索视觉理解应用时,务必考虑到模型的这些局限性。
注意:GPT-4 虽配备视觉功能,功能强大且适用广泛,但了解其局限性同样关键。以下是模型已知的一些局限:
- 在医学图片方面,该模型不适宜解读专业的 CT 扫描、病理组织切片等医学图像,故不宜用于医疗建议。
- 对于非英语文本,如日语或韩语等含有非拉丁字母的图片,模型可能无法发挥最佳性能。
- 放大图片文本以提高可读性时,需避免裁剪重要细节。
- 模型在处理旋转或颠倒的文本 / {/} /图片时,可能产生误解。
- 当图形或文本中的颜色、样式(如实线、虚线、点线)各异时,模型可能难以准确理解。
- 在需要精确空间定位的任务(如棋盘位置识别)上,模型表现不佳。
- 某些情况下,模型可能会生成错误的描述或标题。
- 模型在处理全景和鱼眼图片时存在一定困难。
- 模型不处理原始文件名或元数据,且在分析前会调整图片大小,可能影响其原始尺寸。
- 对于图片中的对象计数,模型可能仅能提供大致数量(可能不准确)。
- 出于安全考虑,OpenAI 实施了一个系统来阻止提交验证码图片。
常见问题解答
我可以微调 gpt-4 的视觉功能吗?
不能,目前不支持微调 gpt-4 的视觉功能。
我可以使用 gpt-4 来生成图片吗?
不能,但其实你可以使用 dall-e-3 来生成图片,再使用 gpt-4o 或 gpt-4-turbo 来理解图片。
我可以上传哪种类型的文件?
目前支持 PNG(.png)、JPEG(.jpeg 和 .jpg)、WEBP(.webp)和非动画 GIF(.gif)。
上传的图片大小有限制吗?
是的,目前限制图片上传大小为每张 20MB。
我可以删除我上传的图片吗?
不能,OpenAI 声明会在模型处理完图片后自动为你删除。
我在哪里可以了解更多关于 GPT-4 与视觉方面的注意事项?
你可以在 GPT-4 带视觉系统卡中找到 OpenAI 的评估、准备和缓解工作的详细信息。OpenAI 进一步实施了一个系统,以阻止提交验证码图片。
带视觉功能的 GPT-4 的速率限制是如何工作的?
OpenAI 在 token 级别处理图片,所以其处理的每张图片都会计入你的每分钟 token(TPM)限制。有关用于确定每张图片 token 计数的公式的详细信息,请参见计算成本部分。
带视觉功能的 GPT-4 可以理解图片元数据吗?
不能,模型不接收图片元数据。
如果我的图片不清晰会怎么样?
如果一张图片模糊不清,模型会尽力解释它。但是,结果可能不那么准确。一个好的经验法则是,如果一个普通人在低
/
{/}
/高分辨率模式下看不清图片中的信息,那么模型也同样看不清。
📚️ 相关链接:

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 53
53 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

{kind=link}
所有评论(0)