HTTP HTTPS源迁移教程
阿里云在线迁移服务是阿里云提供的存储产品数据通道。使用在线迁移服务,您可以将第三方数据轻松迁移至阿里云对象存储OSS,也可以在对象存储OSS之间进行灵活的数据迁移。使用在线迁移服务,您只需在控制台填写源数据地址和目的OSS地址信息,并创建迁移任务即可。启动迁移后,您可以通过控制台管理迁移任务,查看迁移进度、流量等信息。
概述
阿里云在线迁移服务是阿里云提供的存储产品数据通道。使用在线迁移服务,您可以将第三方数据轻松迁移至阿里云对象存储OSS,也可以在对象存储OSS之间进行灵活的数据迁移。
使用在线迁移服务,您只需在控制台填写源数据地址和目的OSS地址信息,并创建迁移任务即可。启动迁移后,您可以通过控制台管理迁移任务,查看迁移进度、流量等信息。
流程图
迁移流程
迁移流程如下图所示:
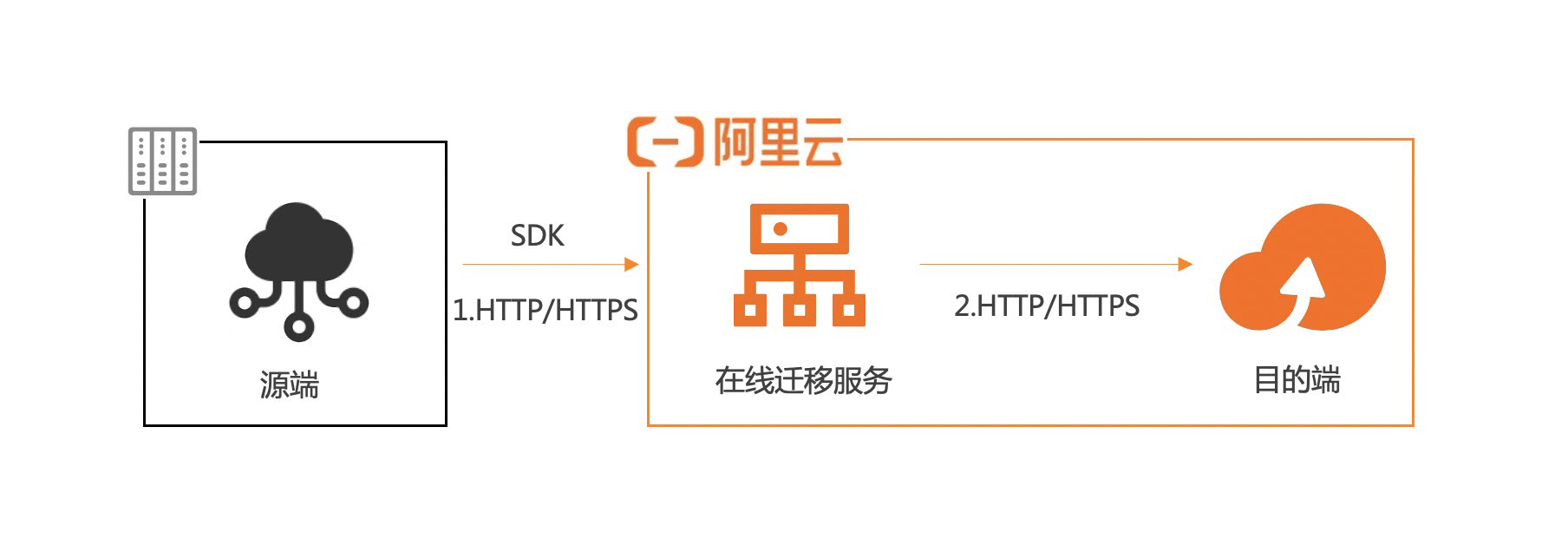
-
出于数据安全性和一致性考虑,建议您使用HTTPS。
-
在迁移任务完成后,请您务必自行做好源端和目的端数据一致性校验。
警告
请您务必在迁移任务完成后,校验目的端迁移数据。您在删除源数据前,未校验目的端迁移数据无误,导致数据丢失所引起的一切损失和后果均由您自行承担。
创建迁移任务流程
创建迁移任务流程如下图所示:
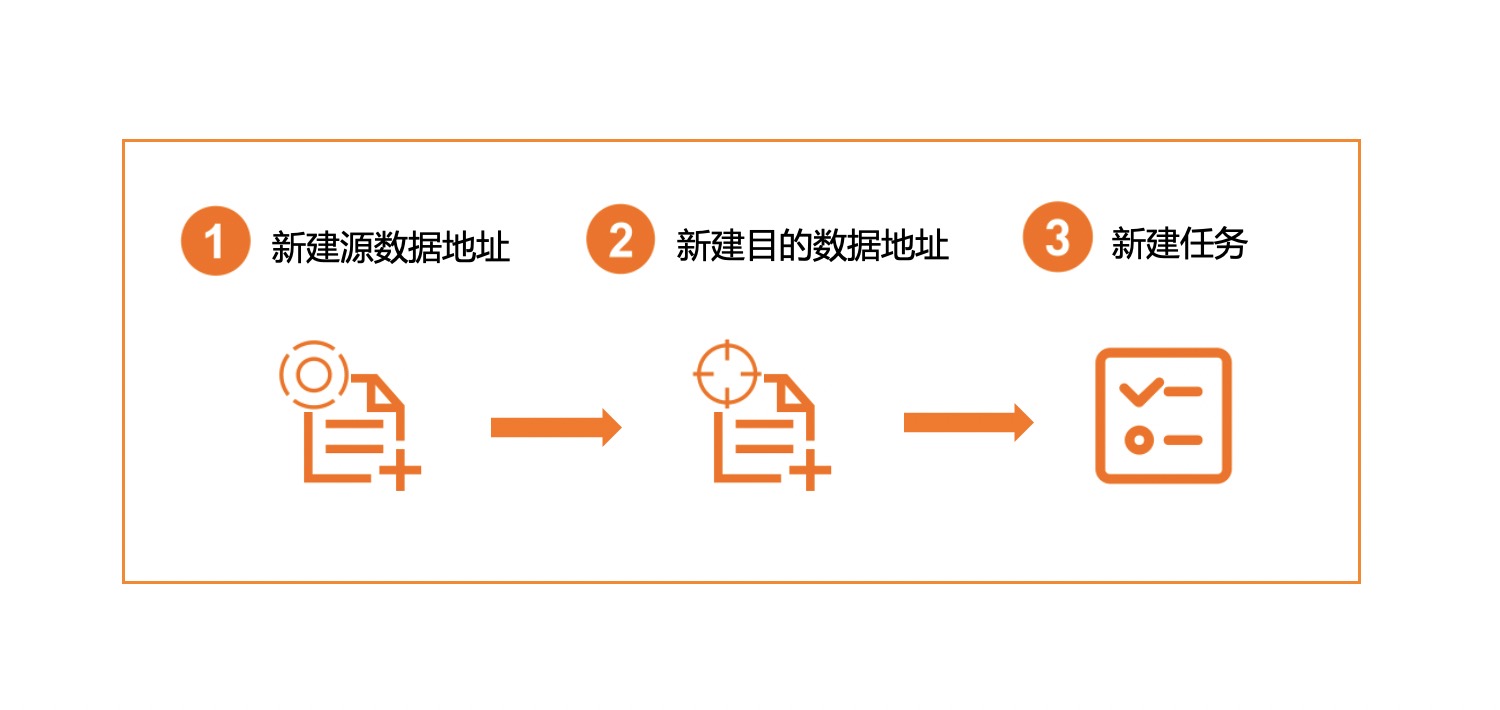
准备工作
介绍数据迁移之前的准备工作。
步骤一:上传列表文件
HTTP/HTTPS列表文件包括2类文件,1个manifest.json文件和1个或多个example.csv.gz文件,example.csv.gz为CSV压缩后的列表文件,单个example.csv.gz文件大小不超过50 MB,manifest.json为对CSV文件进行项配置的文件,支持上传至OSS或者AWS S3。
-
创建CSV列表文件
在本地创建CSV格式的列表文件。列表文件最多支持8项,项与项之间用英文逗号(,)分隔;每行一个文件,文件之间用
\n换行。各项的含义如下表所示。重要
Key和Url为必填项,其余项可以不填写。
-
必填项
名称
是否必填
描述
说明
Url
是
在线迁移服务使用该链接的Get请求下载文件内容,Head请求获取文件元数据。
说明
Url需确保可以直接使用[curl --HEAD "$Url"]、[curl --GET "$Url"]等命令正常访问。在线迁移服务不支持重定向的$Url。
Url和Key项必须要做编码处理,不做编码处理、包含特殊字符可能会导致文件迁移失败。
-
Url项的编码原则:在
curl等命令行工具(非重定向)可正常访问的基础上,再进行一次Url编码。 -
Key项的编码原则:在您期望该文件在OSS上的ObjectName基础之上,再进行一次Url编码。
重要
Url和Key项做编码处理后,请务必进行以下内容确认,否则可能会导致文件迁移失败,或迁移到目的端的文件路径与您的预期不符。
-
原字符串中的加号(+)已被编码成%2B。
-
原字符串中的百分号(%)已被编码成%25。
-
原字符串中的半角逗号(,)已被编码成%2C。
例如,原字符串为
a+b%c,d.file,编码后的字符串应该是a%2Bb%25c%2Cd.file。Key
是
迁移后的Object Name为prefix+文件名。
假设您已生成未进行url编码的CSV文件,名称为plain_example.csv,该文件仅有两列,第一列为Url,这些Url可直接使用curl命令进行访问;第二列为Key,这些Key即为您期望该文件在OSS上的ObjectName。如下:
https://help-static-aliyun-doc.aliyuncs.com/assets/img/zh-CN/1354977961/p486238.jpg,assets/img/zh-CN/1354977961/p486238.jpg https://www.example-fake1.com/%E7%BC%96%E7%A0%81%E5%90%8E%E6%89%8D%E8%83%BD%E8%AE%BF%E9%97%AE%E7%9A%84url/123.png,编码后才能访问的url/123.png https://www.example-fake2.com/无需编码即可访问的url/123.png,无需编码即可访问的url/123.png https://www.example-fake3.com/汉语/日本語にほんご/한국어/123.png,汉语/日本語にほんご/한국어/123.png重要
请勿在Windows系统下使用自带的记事本软件编辑manifest.json或plain_example.csv,因为该软件可能会在文件内容起始3个字节添加特殊标记(0xefbbbf),从而可能引发在线迁移服务的解析异常。您可以在Linux或macOS下执行
od -c plain_example.csv | less确认文件内容的起始3字节是否包含特殊标记。Windows系统下建议您使用Notepad++、Visual Studio Code等软件创建或编辑文件。如下Python编码示例代码将会按行读取plain_example.csv,并将编码后的结果输出到example.csv。代码仅供您参考,请根据实际需要进行适当修改。
# -*- coding: utf-8 -*- import sys if sys.version_info.major == 3: from urllib.parse import quote_plus else: from urllib import quote_plus reload(sys) sys.setdefaultencoding("utf-8") # Source CSV file path. src_path = "plain_example.csv" # URL-encoded file path. out_path = "example.csv" # The sample CSV contains only two columns: url and key. with open(src_path) as fin, open(out_path, "w") as fout: for line in fin: items = line.strip().split(",") url, key = items[0], items[1] enc_url = quote_plus(url.encode("utf-8")) enc_key = quote_plus(key.encode("utf-8")) # The enc_url and enc_key vars are encoded format. fout.write(enc_url + "," + enc_key + "\n")运行上述代码,输出后的example.csv内容为:
https%3A%2F%2Fhelp-static-aliyun-doc.aliyuncs.com%2Fassets%2Fimg%2Fzh-CN%2F1354977961%2Fp486238.jpg,assets%2Fimg%2Fzh-CN%2F1354977961%2Fp486238.jpg https%3A%2F%2Fwww.example-fake1.com%2F%25E7%25BC%2596%25E7%25A0%2581%25E5%2590%258E%25E6%2589%258D%25E8%2583%25BD%25E8%25AE%25BF%25E9%2597%25AE%25E7%259A%2584url%2F123.png,%E7%BC%96%E7%A0%81%E5%90%8E%E6%89%8D%E8%83%BD%E8%AE%BF%E9%97%AE%E7%9A%84url%2F123.png https%3A%2F%2Fwww.example-fake2.com%2F%E6%97%A0%E9%9C%80%E7%BC%96%E7%A0%81%E5%8D%B3%E5%8F%AF%E8%AE%BF%E9%97%AE%E7%9A%84url%2F123.png,%E6%97%A0%E9%9C%80%E7%BC%96%E7%A0%81%E5%8D%B3%E5%8F%AF%E8%AE%BF%E9%97%AE%E7%9A%84url%2F123.png https%3A%2F%2Fwww.example-fake3.com%2F%E6%B1%89%E8%AF%AD%2F%E6%97%A5%E6%9C%AC%E8%AA%9E%E3%81%AB%E3%81%BB%E3%82%93%E3%81%94%2F%ED%95%9C%EA%B5%AD%EC%96%B4%2F123.png,%E6%B1%89%E8%AF%AD%2F%E6%97%A5%E6%9C%AC%E8%AA%9E%E3%81%AB%E3%81%BB%E3%82%93%E3%81%94%2F%ED%95%9C%EA%B5%AD%EC%96%B4%2F123.png -
-
全部项
名称
是否必填
说明
Key
是
迁移后的Object Name为prefix+文件名。
Url
是
在线迁移服务使用该链接的Get请求下载文件内容,Head请求获取文件元数据。
Size
否
迁移文件的大小,单位为字节(Byte)。
StorageClass
否
源Bucket的存储类型。
LastModifiedDate
否
待迁移文件的最后修改时间。
ETag
否
待迁移文件的ETag。
HashAlg
否
待迁移文件的Hash算法。
HashValue
否
待迁移文件的Hash值。
说明
以上示例中各项的顺序并非固定顺序,只需与manifest.json文件中fileSchema项顺序保持一致即可。
-
-
压缩CSV文件
需要将CSV文件压缩为csv.gz文件,压缩方法如下:
-
压缩单个文件
例如dir目录下有一个文件example.csv,需执行如下压缩命令:
gzip -c example.csv > example.csv.gz说明
执行以上
gzip命令压缩文件,不会保留源文件,如需保留源文件压缩,请执行命令gzip -c 源文件 > 源文件.gz。压缩后得到
.csv.gz文件。 -
压缩多个文件
例如dir目录下有三个文件example1.csv、example2.csv和 example3.csv,需执行如下压缩命令:
gzip -r dir说明
gzip命令不会打包目录,而是将指定目录下所有子文件分别进行压缩,且不会保留对应的源文件。压缩后在dir目录下得到三个文件example1.csv.gz、example2.csv.gz和example3.csv.gz。
-
-
创建manifest.json文件
支持配置多个CSV文件,具体内容如下。
-
fileFormat:指定列表文件格式为CSV
-
fileSchema:对应CSV中文件项,请注意顺序。
-
files:
-
key:CSV文件在Bucket中的位置。
-
MD5checksum:16进制的MD5字符串,不区分大小写。例如:91A76757B25C8BE78BC321DEEBA6A5AD,如果不填写该值,则不会做校验。
-
size:列表文件大小。
-
如下示例仅供您参考。
{ "fileFormat":"CSV", "fileSchema":"Url, Key", "files":[{ "key":"dir/example1.csv.gz", "MD5checksum":"", "size":0 },{ "key":"dir/example2.csv.gz", "MD5checksum":"", "size":0 }] } -
-
您可以选择将创建的2类列表文件上传到OSS或AWS S3。
-
将创建的2类列表文件上传到OSS的具体操作,请参见简单上传。
说明
-
列表文件上传到OSS后,在线迁移服务会下载列表文件,并根据指定的地址迁移文件。
-
新建任务时,请填写文件列表所在Bucket信息,列表路径的格式为
列表所在目录/manifest.json,例如dir/manifest.json。
-
-
将创建的2类列表文件上传到AWS S3。
说明
-
列表文件上传到AWS S3后,在线迁移服务会下载列表文件,并根据指定的地址迁移文件。
-
新建任务时,请填写文件列表所在Bucket信息,列表路径的格式为
列表所在目录/manifest.json,例如dir/manifest.json。
-
-
步骤二:创建目标存储空间
创建目标存储空间,用于存放迁移的数据。具体操作,请参见创建存储空间。
步骤三:创建RAM用户并添加权限
重要
-
该RAM用户用于迁移使用。在创建角色和进行迁移实施操作时,需要在该用户下进行操作。请尽量在源Bucket或者目的Bucket所在的主账号下创建该RAM用户。
-
如果没有创建RAM用户,可以创建RAM用户并授权。
登录主账号所在的RAM控制台,在用户页面,单击刚创建的RAM用户 操作 列的 添加权限。
-
系统策略:管理OSS在线迁移服务的权限(AliyunOSSImportFullAccess)。
-
自定义权限策略:该策略必须包含
ram:CreateRole、ram:CreatePolicy、ram:AttachPolicyToRole、ram:ListRoles权限。可参考创建自定义权限策略进行权限管理,以下是相关的权限策略脚本代码:
{ "Version":"1", "Statement":[ { "Effect":"Allow", "Action":[ "ram:CreateRole", "ram:CreatePolicy", "ram:AttachPolicyToRole", "ram:ListRoles" ], "Resource":"*" } ] }
步骤四:清单Bucket授权
请根据清单Bucket是否归属于本账号,完成相应的操作。
清单Bucket归属于本账号
清单Bucket不归属于本账号
-
一键自动授权:
强烈建议您使用迁移控制台授权角色进行一键授权操作,该操作请在迁移实施 > 步骤二 > 列表授权角色 中实施。
-
手动授权:
1、清单Bucket授权
在角色页面,单击刚创建的RAM角色 操作 列的 新增授权。
-
自定义权限策略:该策略必须包含
oss:List*、oss:Get*权限。
可参考创建自定义权限策略进行权限管理,以下是相关的权限策略脚本代码:
说明
以下权限策略仅供您参考,其中<myInvBucket>为本账号下的清单Bucket名称,请根据实际值替换。
关于OSS权限策略的更多信息,请参见RAM Policy常见示例。
{ "Version": "1", "Statement": [ { "Effect": "Allow", "Action": [ "oss:List*", "oss:Get*" ], "Resource": [ "acs:oss:*:*:<myInvBucket>", "acs:oss:*:*:<myInvBucket>/*" ] } ] } -
步骤五:目的Bucket授权
请根据目的Bucket是否归属于本账号,完成相应的操作。
目的Bucket归属于本账号
目的Bucket不归属于本账号
-
一键自动授权:
强烈建议您使用迁移控制台自动授权角色进行一键授权操作,该操作请在迁移实施 > 步骤三 > 授权角色 中实施。
-
手动授权:
1、目的Bucket授权
在角色页面,单击刚创建的RAM角色 操作 列的 新增授权。
-
自定义策略:该策略必须包含
oss:List*、oss:Get*、oss:Put*、oss:AbortMultipartUpload*权限。
可参考创建自定义权限策略 进行权限管理,以下是相关的权限策略脚本代码:
说明
以下权限策略仅供您参考,其中<myDestBucket>为 本账号下的目的Bucket名称,请根据实际值替换。
关于OSS权限策略的更多信息,请参见RAM Policy常见示例。
{ "Version": "1", "Statement": [ { "Effect": "Allow", "Action": [ "oss:List*", "oss:Get*", "oss:Put*", "oss:AbortMultipartUpload" ], "Resource": [ "acs:oss:*:*:<myDestBucket>", "acs:oss:*:*:<myDestBucket>/*" ] } ] } -
迁移实施
介绍如何对源端为HTTP/HTTPS的数据进行数据迁移的注意事项、迁移限制说明和操作步骤。
注意事项
使用在线迁移服务迁移数据时需要注意以下事项:
-
在线迁移服务使用源站存储服务提供商公开的标准接口来访问源数据,其行为依赖于源站存储服务提供商的具体实现。
-
在线迁移会占用源地址和目的地址的资源,可能会影响业务正常运行。若您的业务比较重要,请提前做好评估后对迁移任务设置限速,或在空闲时间启动迁移任务。
-
在线迁移前会检查源地址和目的地址的文件,但是若您源和目的地址有相同文件名的文件,且在迁移任务中配置了覆盖方式为覆盖,迁移时会直接覆盖目的地址的文件。若两个文件内容不同,必须更改文件名或做好备份。
-
在线迁移会保留源文件的最后修改时间属性,如果目的Bucket设置了生命周期规则,且迁移后文件处于该生命周期规则生效的时间范围内,则该文件可能会在规则生效时被删除或转为指定的归档类型。
迁移限制说明
HTTP/HTTPS迁移数据的属性说明如下:
-
支持迁移的属性:LastModifyTime ,Content-Type,Cache-Control,Content-Encoding,Content-Disposition。Content-Language 、Expires。
-
不支持迁移的属性:暂不明确,以实际迁移完成的内容为准。
步骤一:选择地域
-
使用创建的RAM用户登录阿里云在线迁移服务管理控制台。
-
在顶部菜单栏左上角处的地域选择代表“迁移服务部署地域”,因此请选择数据源所在地域或距离数据源最近的地域,如下图所示。
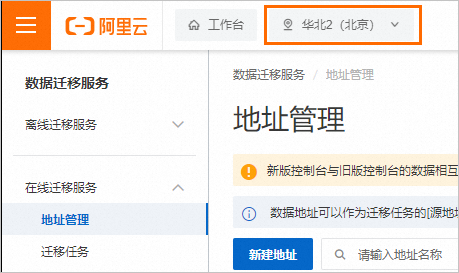
控制台上方所选地域(代表在线迁移服务的部署地域),中国内地地域包含北京、上海、杭州、深圳、乌兰察布,其他地域包含中国香港、新加坡、德国(法兰克福)、美国(弗吉尼亚)。
重要
-
不同地域内的数据地址和迁移任务不通用,请谨慎选择。
-
优先选择源数据所在的地域,如果没有源数据所在地对应的地域,请尽可能选择接近源数据所在的地域创建迁移任务。
-
跨境迁移时,推荐您开启传输加速,提高迁移速度。开启了传输加速的Bucket会收取传输加速费用。关于传输加速的更多信息,请参见传输加速。
-
步骤二:创建源地址
-
在左侧导航栏,选择在线迁移服务 > 地址管理,单击新建地址。
-
在新建地址面板,配置如下参数,然后单击确定。
-
参数
是否必选
说明
名称
是
输入源数据地址名称。名称命名规则如下:
-
名称不能为空,长度为3~63个字符。
-
支持英文小写字母、数字和特殊字符短划线(-)和下划线(_),且区分大小写。
-
UTF-8编码不能以短划线(-)和下划线(_)开头。
类型
是
选择HTTP/HTTPS。
协议
是
选择HTTP或HTTPS。
端口
是
输入指定端口号,HTTP默认为80端口,HTTPS默认为443端口,端口范围为0~65535。
列表位置
是
清单文件所在的存储空间,可选择Alibaba OSS或AWS S3。
列表域名或区域
是
-
当列表位置选择Alibaba OSS时,输入OSS清单所在的地域。
-
当列表位置选择AWS S3时,输入AWS S3清单的访问域名。更多信息,请参见Amazon S3终端节点。
授权角色
是(列表位置选择Alibaba OSS )
-
清单Bucket归属于在线迁移控制台账号
-
清单Bucket不归属于在线迁移控制台账号
存储桶(Bucket)
是
输入当前控制台所在账号下待迁移列表所在的存储桶(Bucket)名称。
列表AccessKeyId
是(列表位置选择AW3 S3 )
当列表位置选择AWS S3时,输入用于访问AWS S3清单的密钥,迁移完成后删除。
列表SecretAccessKey
通道
否
选择需要使用的通道名称。
重要
-
仅通过专线或VPN迁移数据上云、自建存储数据迁移上云需要使用该参数。
-
目的数据地址是LOCALFS的以及需要走专线(金融云、专有云等)的场景需要关联代理。
代理
否
选择需要使用的代理名称。
重要
-
仅通过专线或VPN迁移数据上云、自建存储数据迁移上云需要使用该参数。
-
指定通道下,最多可同时选择30个代理。
-
步骤三:创建目的地址
|
参数 |
是否必选 |
说明 |
|
名称 |
是 |
输入目的数据地址名称。名称命名规则如下:
|
|
类型 |
是 |
选择Alibaba OSS。 |
|
自定义域名 |
否 |
支持用户的自定义域名 |
|
地域 |
是 |
选择目的地址所在的地域,例如华东1(杭州)。 |
|
授权角色 |
是 |
|
|
存储桶(Bucket) |
是 |
输入当前控制台所在账号下迁移后数据所在的存储桶(Bucket)名称。 |
|
前缀 |
否 |
您可以指定数据路径前缀将源数据迁移至指定目录下。格式要求不能以正斜线(/)开头,必须以正斜线(/)结尾,例如
|
|
通道 |
否 |
选择需要使用的通道名称。 重要
|
|
代理 |
否 |
选择需要使用的代理名称。 重要
|
-
在左侧导航栏,选择在线迁移服务 > 地址管理,单击新建地址。
-
在新建地址面板,配置如下参数,然后单击确定。
步骤四:创建迁移任务
-
在左侧导航栏,选择在线迁移服务 > 迁移任务,单击新建任务。
-
在选择地址页面,配置如下参数,然后单击下一步。
参数
是否必选
说明
名称
是
输入迁移任务名称。名称命名规则如下:
-
名称不能为空,长度为3~63个字符。
-
支持英文小写字母、数字和特殊字符短划线(-)和下划线(_),且区分大小写。
-
UTF-8编码不能以短划线(-)和下划线(_)开头。
源地址
是
选择已创建的源地址。
目的地址
是
选择已创建的目的地址。
-
-
在配置任务页面,配置如下参数。
参数
是否必选
说明
迁移带宽
否
选择迁移带宽。
-
默认:默认最大带宽,实际速度取决于文件大小和文件数量。
-
指定上限:根据控制台提示指定具体的带宽上限。
重要
-
实际迁移带宽与数据源、网络、目的限流、文件大小等因素有关,不一定能达到指定上限。
-
请您评估数据源、迁移目的、业务情况、网络带宽等,并根据实际情况选择合理数值,限流不恰当可能会影响业务的正常运行。
每秒迁移文件数
否
选择每秒迁移文件数。
-
默认:每秒迁移文件数。
-
指定上限:根据控制台提示指定具体的每秒迁移文件数。
重要
-
实际迁移带宽与数据源、网络、目的限流、文件大小等因素有关,不一定能达到指定上限。
-
请您评估数据源、迁移目的、业务情况、网络带宽等,并根据实际情况选择合理数值,限流不当可能会影响业务的正常运行。
覆盖方式
否
选择同名文件的覆盖方式。
警告
-
根据最后修改时间覆盖无法严格保证一定不会覆盖更新的文件,存在旧文件覆盖新文件的风险。
-
若您选择根据最后修改时间覆盖的覆盖方式,请务必确保源端文件能返回最后修改时间、Size、Content-Type等信息,否则覆盖策略可能失效,产生非预期的迁移结果。
-
选择不覆盖或根据最后修改时间覆盖时,为执行后续覆盖判断,会分别请求源端和目的端meta信息一次,因此会在源端和目的端产生对应的请求费用。
-
不覆盖:不迁移该文件。
-
全部覆盖:源地址中的文件会覆盖目的地址中的文件。
-
根据最后修改时间覆盖:
-
当源地址中的文件最后修改时间晚于目的地址中的文件最后修改时间时,目的地址中的文件会被覆盖。
-
当源地址中的文件最后修改时间与目的地址中的文件最后修改时间相同时,若二者的Size和Content-Type有一项不同,则目的地址中的文件会被覆盖。
-
迁移报告
是
迁移报告推送方式。
-
不推送(默认):不推送迁移报告至目的bucket。
-
推送:将迁移报告推送至目的bucket,详细路径请参考后续操作。
重要
-
迁移报告推送会占用目的端一定的存储空间。
-
迁移报告的推送可能会存在一定的时间延迟,请您耐心等待迁移报告的生成。
-
每个任务执行记录都有一个唯一的ID,请注意,迁移报告只会推送一次,请谨慎删除!
迁移日志
是
迁移日志推送方式。
-
不推送(默认):不推送迁移日志。
-
推送:将迁移日志推送至日志服务SLS,可在SLS上查看迁移日志。
-
仅推送文件错误日志:仅将错误迁移日志推送至日志服务SLS,可在SLS上查看错误迁移日志。
当选择推送或仅推送文件错误日志时,在线迁移服务会在日志服务SLS中创建名称为aliyun-oss-import-log-阿里云账号ID-当前迁移服务部署地域的Project,例如aliyun-oss-import-log-137918634953****-cn-hangzhou。
重要
请务必完成以下操作后,再选择推送或仅推送文件错误日志,否则可能会导致迁移任务异常。
-
已开通SLS服务。
-
已在日志服务授权项授权页面中同意授权。
日志服务授权
否
当迁移日志选择推送或仅推送文件错误日志时出现该选项。
单击授权进入云资源访问授权页面,页面会对应创建AliyunOSSImportSlsAuditRole角色,并对角色做授权,请单击同意授权完成授权。
执行时间
否
重要
-
正在迁移中的任务,在下一个指定时间前仍未结束本轮迁移,则会在本轮迁移结束后,自动顺延至下一个指定时间启动任务,直至完成指定次数的迁移。
-
迁移任务并发数量限制:迁移服务部署地域选择中国香港或中国内地时最多支持10个任务并发,选择海外地域时最多支持5个,超出限制后可能导致定时任务调度无法按预期执行。
确定迁移任务的执行时间。
-
立即执行:立即执行当前任务。
-
指定执行时间:指定任务执行期间每天的执行时间段。默认情况下,任务将在指定的起始时间启动,在指定的停止时间暂停。
-
周期调度:通过调整执行频率和执行次数来启动任务。
-
执行频率:支持以每小时、每天、每周、一周中某些天、自定义等5种频率,具体请查看执行频率参考。
-
执行次数:指定任务的执行次数,如不设置则默认执行一次,最大执行次数请参考控制台提示。
-
重要
可随时手动启动和暂停任务,不受自定义执行时间的影响。
-
-
阅读在线迁移服务协议,选中我已理解并确认,合规承诺声明且当迁移任务完成时,我有确认迁移数据一致性的义务和责任,然后单击下一步。
-
检查配置信息,确认无误后,单击确定,等待迁移任务执行。
执行频率参考
|
执行频率 |
说明 |
示例 |
|
每小时 |
选择以每小时为频率,可搭配执行次数一起使用。 |
当前时间为8:05分,指定每小时为频率,执行3次任务,则会在下一个整点9点钟开始第一次任务。
|
|
每天 |
选择以每天为频率时,需设置0~23小时中任意整点时间启动任务,可搭配执行次数一起使用。 |
当前时间为8:05分,指定每天10点,执行5次,会在当天10点开始第一次任务。
|
|
每周 |
选择每周时,需指定周内任意一天,并设置0~23小时中任意整点时间启动任务,可搭配执行次数一起使用。 |
当前时间为周一8:05分,指定每周一的10点,执行10次,则会在当天10点时开始第一次任务。
|
|
一周中某些天 |
选择一周中某些天时,支持选择周内任意几天,并设置0~23小时中任意整点时间启动任务。 |
当前为周三8:05,指定每周一、三、五的10点,则会在当天的10点时开始第一次任务。
|
|
自定义 |
使用Cron表达式自定义设置任务启动时间。 |
说明 Cron表达式由6个字段组成,每个字段之间使用空格分隔,依次表示任务的执行时间规则:秒 分钟 小时 日 月 星期。 以下Cron表达式示例仅供参考,更多请参照Cron表达式生成器:
|
步骤五:校验数据
迁移服务仅负责数据的迁移,无法保证数据的一致性和完整性。迁移任务完成后,请您全量校验迁移的数据,务必自行做好源端和目的端数据一致性校验。
警告
请您务必在迁移任务完成后,校验目的端迁移数据。您在删除源数据前,未校验目的端迁移数据无误,导致数据丢失所引起的一切损失和后果均由您自行承担。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)