
Diffusion Policy——斯坦福UMI所用的动作预测算法:基于扩散模型的扩散策略(从原理到其编码实现)
前言
本文一开始是属于此文《UMI——斯坦福刷盘机器人:从手持夹持器到动作预测Diffusion Policy(含代码解读)》的第三部分,考虑后Diffusion Policy的重要性很高,加之后续还有一系列基于其的改进工作
故独立成本文,且写的过程中
- 发现Diffusion Policy的实现代码值得好好剖析下,故直接在本文的第二部分 分析Diffusion Policy的代码实现
代码分析会侧重尽可能一目了然、一看就懂,如此,结合原理和对应的代码实现,会理解更深刻 - 把原属于另一篇文章的「Diff-Control、ControlNet详解」已归纳至本文,作为第三部分
第一部分 Diffusion Policy:基于扩散模型的机器人动作生成策略
1.1 什么是Diffusion Policy及其优势
1.1.1 什么是扩散策略
23年3月份,来自哥伦比亚大学Columbia University、Toyota Research Institute、MIT的研究者们提出了扩散策略
其将机器人的视觉运动策略表示为条件去噪扩散过程,从而来生成机器人行为(或者,说白了,Diffusion Policy就是应用Diffusion方法生成机器人动作的一种Policy,或者说的更直白点,扩散模型在图像生成领域已经应用广泛了,而扩散策略则探索的是扩散模型在机器人领域的动作生成)

- 其作者团队为:Cheng Chi1, Siyuan Feng2, Yilun Du3, Zhenjia Xu1, Eric Cousineau2, Benjamin Burchfiel2, Shuran Song1 (带下划线的表示同时也是UMI的作者)
直白讲,Diffusion Policy这个工作是哥伦比亚大学宋舒然团队和MIT教授Russ Tedrake带领的丰田机器人研究院共同创作
论文的一作迟宬目前是哥伦比亚大学的计算机科学博士生,在宋舒然的指导下做机器人操纵和感知相关的研究 - 其对应的论文为:Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
- 其对应的网站为:diffusion-policy.cs.columbia.edu
- 其对应的GitHub仓库为:real-stanford/diffusion_policy
进一步而言,如下图所示
- a)具有不同类型动作表示的显式策略(Explicit policy with different types of action representations)
- b)隐式策略学习以动作和观察为条件的能量函数,并优化能够最小化能量景观的动作
Implicit policy learns an energy function conditioned on both action and observation and optimizes for actions that minimize the energy landscape - c)通过“条件去噪扩散过程在机器人行动空间上生成行为”,即该扩散策略不是直接输出动作,而是根据视觉观察推断且经过K次去噪迭代的动作得分梯度
instead of directly outputting an action, the policy infers the action-score gradient, conditioned on visual observations, for K denoising iterations
1.1.2 扩散策略的优势:表达多模态动作分布、高维输出空间、稳定训练
扩散策略有以下几个关键特性
- 可以表达多模态动作分布
通过学习动作评分函数的梯度(Song和Ermon,2019),并在此梯度场上执行随机朗之万动力学采样,扩散策略可以表达任意可归一化的分布(Neal等,2011),其中包括多模态动作分布
By learning the gradient of the action score function Song and Ermon (2019) and performing Stochastic Langevin Dynamics sampling on this gradient field,Diffusion policy can express arbitrary normalizabledistributions Neal et al. (2011), which includes mul-timodal action distribution - 高维输出空间
正如其令人印象深刻的图像生成结果所示,扩散模型在高维输出空间中表现出了极好的可扩展性。这一特性使得策略能够联合推断一系列未来动作,而不是单步动作,这对于鼓励时间上的动作一致性和避免比较短浅的规划至关重要 - 稳定训练
训练基于能量的策略通常需要负采样来估计难以处理的归一化常数,这已知会导致训练不稳定(Du et al., 2020;Florence et al., 2021)
扩散策略通过学习能量函数的梯度绕过了这一要求,从而在保持分布表达能力的同时实现了稳定训练
进一步,为了充分释放扩散模型在物理机器人上进行视觉运动策略学习的潜力,作者团队提出了一套关键的技术贡献,包括将闭环动作序列、视觉条件化和时间序列扩散transformer结合起来
- 闭环动作序列
结合策略预测高维动作序列的能力与递推视界控制来实现稳健执行(We combine the policy’s capability to predict high-dimensional action sequences with receding-horizon control to achieve robust execution)
这种设计允许策略以闭环方式持续重新规划其动作,同时保持时间上的动作一致性,从而在长视距规划和响应性之间实现平衡 - 视觉条件化
引入了一种视觉条件化扩散策略,其中视觉观测被视为条件而不是联合数据分布的一部分。在这种公式化中,策略只需提取一次视觉表示,而无需考虑去噪迭代,从而大大减少了计算量,并实现了实时动作推理
where the visual observations are treated as conditioning instead of apart of the joint data distribution. In this formulation,the policy extracts the visual representation onceregardless of the denoising iterations,which drastically reduces the computation and enable sreal-time action inference - 时间序列扩散transformer
提出了一种基于transformer的新型扩散网络,该网络最小化了典型CNN模型的过度平滑效应,并在需要高频动作变化和速度控制的任务中实现了最先进的性能
1.2 Diffusion for Visuomotor Policy Learning
1.2.1 扩散策略背后的扩散过程回顾
- 众所周知,从高斯噪声中采样的
开始,DDPM「如果此前不了解什么是DDPM的,请详见此文《图像生成发展起源:从VAE、VQ-VAE、扩散模型DDPM、DETR到ViT、Swin transformer》的第二部分」执行
次去噪迭代,以生成一系列噪声逐渐减少的中间动作:
,直到形成所需的无噪声输出
(说白了,就是去噪)
该过程遵循下述所示的公式1
论文中 这个表述可能不太自然,我把部分上标换成下标,你可能会更习惯
总之,不管哪种表达,其中是第
步的状态(带有噪声的样本),通过去噪过程得到
是去噪步长的缩放系数,影响每次迭代的收敛速度
是学习率,控制每次更新的幅度
,或
,为通过学习优化参数的噪声估计网络
 为每次迭代时加入的高斯噪声
为每次迭代时加入的高斯噪声
该公式的实现在「Diffusion Policy」GitHub仓库中的diffusion_policy/models.py文件里,apply_denoising_step函数实现了这个去噪步骤:
可以看到,在代码中,apply_denoising_step函数实现了公式1的逐步去噪过程。函数中,epsilon_theta为噪声预测网络,np.random.normal添加了随机高斯噪声,模拟扩散过程中的扰动def apply_denoising_step(x_k, k, alpha, gamma, epsilon_theta, sigma): noise_pred = epsilon_theta(x_k, k) # 计算噪声预测 x_k_minus_1 = alpha * (x_k - gamma * noise_pred) + np.random.normal(0, sigma) return x_k_minus_1 - 且上面的公式1也可以理解为一个单一的噪声梯度下降步长,定义为如下公式2
此公式2表示一个简单的梯度下降步骤,用于调整样本的位置,以降低能量
「该公式2源于基于能量的模型EBM框架,目标是找到样本的低能量区域,这样生成的样本更加合理」
其中,噪声估计网络有效地预测了梯度场
——相当于能量函数的
此外,公式1中的作为与迭代步长
在代码实现中,公式2被实现为梯度更新的一部分。代码片段在diffusion_policy/models.py中的gradient_descent_step函数:
在此函数中,energy_grad是能量的梯度,gamma是学习率参数,实现了逐步降能的思想def gradient_descent_step(x, gamma, energy_grad): x_prime = x - gamma * energy_grad return x_prime - 再之后,训练过程首先从数据集中随机抽取未修改的样本
对于每个样本,随机选择一个去噪迭代
然后要求噪声估计网络从添加噪声的数据样本中预测噪声,如下公式3
此公式3
定义了去噪模型的均方误差(MSE)损失函数,用于训练噪声预测网络
其中,是真实噪声样本,
相当于是噪声估计网络的预测输出
总之,最小化公式3所示的损失函数,也同时最小化了数据分布和从DDPM
中提取的样本分布之间KL-散度的变分下界「minimizing the loss functionin Eq 3 also minimizes the variational lower bound of the KL-divergence between the data distribution p(x0) and the distribution of samples drawn from the DDPM q(x0) usingEq 1」
代码实现此损失函数的地方在diffusion_policy/losses.py中的denoising_loss函数def denoising_loss(pred_noise, true_noise): loss = np.mean((pred_noise - true_noise) ** 2) return lossdenoising_loss函数实现了均方误差 (MSE) 损失,用于在训练中衡量预测噪声与真实噪声之间的误差
1.2.2 改造DDPM 使其表达机器人视觉运动策略:闭环动作序列预测、视觉观察条件化
虽然DDPM通常用于图像生成,但该团队使用DDPM来学习机器人的视觉运动策略。这需要针对DPPM的公式进行两大修改
- 之前输出的是图像,现在需要输出:为机器人的动作(changing the output x to represent robot actions)
- 去噪时所依据的去噪条件为输入观测
(making the denoising processes conditioned on input observation Ot)
为了达到以上这两个修改的目的,需要做以下措施
- 一、闭环动作序列预测(Closed-loop action-sequence prediction)
一个有效的动作制定应该鼓励在长期规划中的时间一致性和平滑性,同时允许对意外观察做出迅速反应
为了实现这一目标,应该在重新规划之前,采用扩散模型生成的固定持续时间的行动序列预测
即如论文原文所说:“An effective action formulation should encourage temporal consistencyand smoothness in long-horizon planning while allowingprompt reactions to unexpected observations. To accomplishthis goal, we commit to the action-sequence prediction produced by a diffusion model for a fixed duration beforere planning”
具体来说,在时间步骤,策略将最新的
个观察数据
作为输入,并预测
个动作,其中
个动作在不重新规划的情况下在机器人上执行
(在此定义中,
这样做既促进了时间动作的一致性,又保持了响应速度
如下图所示
- a) 一般情况下,该策略在时间步长
作为输入,并输出
General formulation. At time step t, the policy takes the latest To steps of observation data Ot as input and outputs Ta steps of actions At- b) 在基于CNN的扩散策略中,对观测特征
In the CNN-based Diffusion Policy, FiLM (Feature-wise Linear Modulation) [Film: Visual reasoning with a general conditioning layer] conditioning of the observation feature Ot is applied to every convolution layer, channel-wise.
然后从高斯噪声中提取的减去噪声估计网络
「这个过程是扩散模型去噪的本质,如不了解DDPM,请详看此文:《图像生成发展起源:从VAE、扩散模型DDPM、DETR到ViT、Swin transformer》」
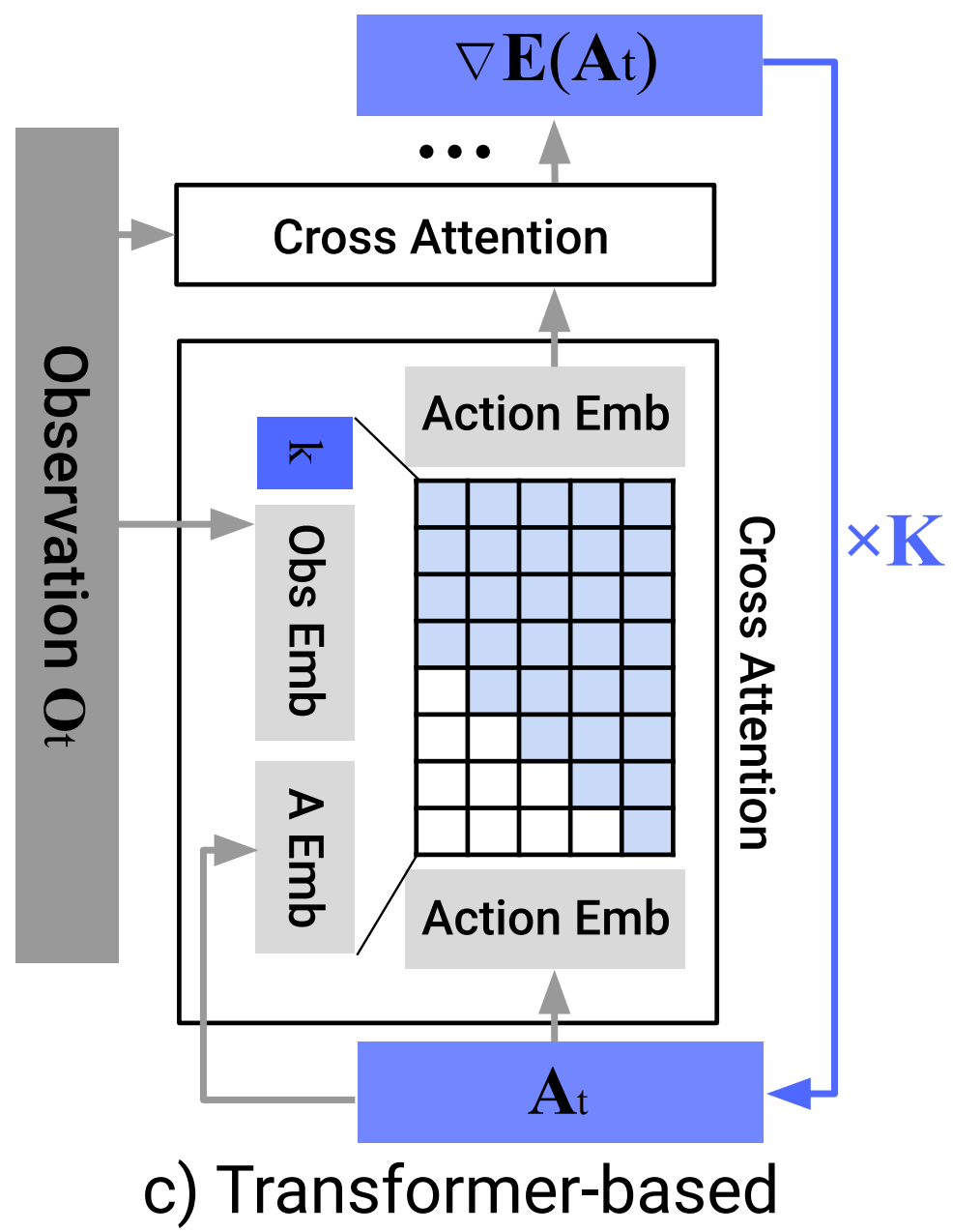
Starting from AtK drawn from Gaussian noise, the outputof noise-prediction network εθ is subtracted, repeating K times to get At0, the denoised action sequence.- c) 在基于Transformer的扩散策略中,观测
每个动作嵌入使用所示注意力掩码进行约束,使其仅关注自身和之前的动作嵌入(因果注意力,类似GPT的解码策略)
In the Transformer-based [52]Diffusion Policy, the embedding of observation Ot is passed into a multi-head cross-attention layer of each transformer decoder block.
Each action embedding is constrained to only attend to itself and previous action embeddings (causal attention) using the attention mask illustrated.

- 二、视觉观察条件化(Visual observation conditioning)
总之,他们使用DDPM来近似:条件分布——而不是Janner等人[20]用于规划的联合分布
「We use a DDPM toapproximate the conditional distribution p(At|Ot) instead of the joint distribution p(At,Ot) used in Janner et al. (2022a)for planning. 」
相当于通过DDPM去生成特定观察下的动作图像
这种形式使得模型能够在不推断未来状态的情况下预测基于观察的动作(This formulation allows the model to predict actionsconditioned on observations without the cost of inferringfuture states),加快了扩散过程并提高生成动作的准确性
首先,为了获取条件分布
修改为如下公式4
此公式4
是一个条件去噪公式,用于在输入当前观察
其代码实现在diffusion_policy/conditional_models.py中的apply_conditional_denoising_step函数:
该函数实现了条件去噪过程,在观察条件下的噪声预测网络def apply_conditional_denoising_step(A_k, O_t, k, alpha, gamma, epsilon_theta, sigma): noise_pred = epsilon_theta(O_t, A_k, k) A_k_minus_1 = alpha * (A_k - gamma * noise_pred) + np.random.normal(0, sigma) return A_k_minus_1——epsilon_theta考虑了观察
其次,将训练损失由下述公式3
修改为如下的公式5
该公式5
一个条件去噪损失函数,用于衡量噪声预测网络在给定观察条件下的预测误差
其中,是真实噪声,
是条件噪声预测网络的输出
代码实现在diffusion_policy/losses.py文件中定义为conditional_denoising_loss函数def conditional_denoising_loss(pred_noise, true_noise): loss = np.mean((pred_noise - true_noise) ** 2) return loss
1.3 几个关键设计:涉及模型选型等
第一个设计决策是选择的神经网络架构,对此,作者研究了两种常见的网络架构类型,即CNN和Transformer
1.3.1 噪声估计网络架构的选型:基于CNN还是基于transformer
1.3.1.1 CNN-based Diffusion Policy
基于CNN的扩散策略中,采用Janner等人[21]的1D temporal CNN,并做了一些修改,如下图所示

- 首先,仅通过特征线性调制(FiLM)将动作生成过程条件化在观察特征
we only model the conditional distribution p(At|Ot)by conditioning the action generation process on observation features Ot with Feature-wise Linear Modulation (FiLM) - 其次,仅预测动作轨迹,而非连接的观察动作轨迹
we only predict the action trajectory instead of the concatenated observation action trajectory - 第三,利用receding prediction horizon,删除了基于修复的目标状态条件反射。然而,目标条件反射仍然是可能的,与观测所用的FiLM条件反射方法相同
we removed inpainting-based goal state conditioning due to incompatibility with our framework utilizing a receding prediction horizon.However, goal conditioning is still possible with the same FiLM conditioning method used for observations
在实践中发现,基于CNN的骨干网络在大多数任务上表现良好且无需过多超参数调优。然而,当期望的动作序列随着时间快速而急剧变化时(如velocity命令动作空间),它的表现很差,可能是由于时间卷积的归纳偏差[temporal convolutions to prefer lowfrequency signals],以更倾向低频信号所致
1.1.1.2 Time-series diffusion transformer
此外,为减少CNN模型中过度平滑效应[49],他们还提出了一种基于Transformer架构、借鉴minGPT[42]思想的DDPM来进行动作预测,如下图所示
- 行动和噪声
作为transformer解码器块的输入tokens传入,扩散迭代
观测
“梯度”由解码器堆栈的每个对应输出token进行预测(The "gradient" εθ (Ot ,At k , k) is predicted by each corresponding output token of the decoder stack)
- 在基于状态的实验中,大多数性能最佳的策略都是通过Transformer骨干实现的,特别是当任务复杂度和动作变化率较高时。然而,他们发现Transformer对超参数更敏感
当然了,Transformer训练的困难[25]并不是Diffusion Policy所独有的,未来可以通过改进Transformer训练技术或增加数据规模来解决
However, we found the transformer to be more sensitive to hyperparameters. The difficulty of transformer training [25] is not unique to Diffusion Policy and could potentially be resolved in the future with improved transformer training techniques or increased data scale
故,一般来说
- 建议从基于CNN的扩散策略实施开始,作为新任务的第一次尝试
In general, we recommend starting with the CNN-based diffusion policy implementation as the first attempt at a new task - 但如果由于任务复杂性或高速率动作变化导致性能低下,那么可以使用时间序列扩散Transformer来潜在地提高性能,但代价是额外的调优
If performance is low due to task complexity or high-rate action changes, then the Time-series Diffusion Transformer formulation can be used to potentially improve performance at the cost of additional tuning
1.3.2 视觉编码器:把图像潜在嵌入化并通过扩散策略做端到端的训练
视觉编码器将原始图像序列映射为潜在嵌入,并使用扩散策略进行端到端的训练(The visual encoder maps the raw image sequence into a latent embedding Ot and is trained end-to-end with the diffusion policy)
不同的相机视图使用不同的编码器,以对每个时间步内的图像独立编码,然后连接形成,且使用标准的ResNet-18(未进行预训练)作为编码器,并进行以下修改:
- 使用空间softmax池化替代掉全局平均池化,以维护空间信息
1) Replace the global average pooling with a spatial softmax pooling to maintain spatial information[29] - 采用GroupNorm代替BatchNorm来实现稳定训练,这个修改对于把归一化层与指数移动平均一起使用时(通常应用于DDPM)很有必要
2) Replace BatchNorm with GroupNorm [57] for stabletraining. This is important when the normalization layer isused in conjunction with Exponential Moving Average [17](commonly used in DDPMs)
1.4 扩散策略的稳定性与好处
1.4.1 动作序列预测的好处(Benefits of Action-Sequence Prediction)
由于高维输出空间采样困难,在大多数策略学习方法中一般不做序列预测。例如,IBC将难以有效地采样具有非光滑能量景观的高维动作空间。类似地,BC-RNN和BET难以确定动作分布中存在的模式数量(需要GMM或k-means步骤)
相比之下,DDPM在不降低模型表现力的前提下,在输出维度增加时仍然保持良好扩展性,在许多图像生成应用中已得到证明。利用这种能力,扩散策略以高维动作序列的形式表示动作
如此文所说,关于Action Space Scalabiltiy或者sequential correlation问题,简单理解就是机器人对未来动作的预测不应该只局限于眼前的一步两步动作,而应该更有前瞻性,可以往前预测数十步动作
具体而言,在Robot Learning领域,机器人动作执行主要有三种方法:包括直接回归、分类预测和生成式模型
- 第一类回归,即将神经网络视为一个函数,输入是图片,输出是一个动作。这是最常见的方法,绝大多数强化学习都采用这种方式。然而,这种方法存在一些问题,正如之前提到的
相当于直接输出一个数值- 第二类分类预测,这种方法通过预测分类来生成动作
相当于将可能的数值分成几个区间,进行离散预测。在预测Multi-Modal Action的时候,人们倾向于采用离散预测,将连续值问题转化为分类问题,但这样做涉及的算力成本很高,尤其在处理高维空间时- 第三类生成模型,理论上所有的生成模型都可以预测连续的多模态分布,但很多生成模型的问题是训练不稳定
对于针对机器人控制问题,如果采用分类方法,每一步都需要预测下一步要执行的动作,而实际需求是希望一次性预测多步动作,这就涉及到了连续控制中的动作一致性问题。解决这个问题的挑战在于平衡成本和对高维连续控制的需求
总之,最终diffusion policy最终自然地解决了以下问题:
- 时间动作一致性,如下图所示,为了将T块从底部推入目标,策略可以从左或右绕T块走
相当于引入了概率分布,使得神经网络不再是一个输入一个输出的函数,而是一个输入可以有多个输出的函数
举个例子,就像人从两腿并拢然后往前迈步一样,有的人会先迈左脚,有的会先迈右脚,如果你让本质上是一个函数的前馈神经网络(即对于给定输入,只有一种输出),去预测人迈脚的动作则会冲突重重,而如果强行让神经网络处理这种情况——通常是通过预测一个中间值,试图最小化与数据之间的距离。但这可能导致不符合预期的行为,例如忽迈左、忽迈右,最终摔倒
然而,如果序列中的每个动作被预测为独立的多模态分布(如在BC-RNN和BET中所做的那样)。连续动作可能会从不同模式中提取出来,并导致两个有效轨迹之间交替出现抖动动作
However, suppose each action in the sequence is predicted as independent multimodal distributions (as done in BCRNN and BET). In that case, consecutive actions could be drawn from different modes, resulting in jittery actions that alternate between the two valid trajectories. - 对于空闲动作的鲁棒性:当演示暂停并导致相同位置或接近零速度的连续动作序列时,则会发生空闲行为。这在远程操作等任务中很常见
然而,单步策略容易过度适应这种暂停行为。例如,在实际世界实验中使用BC-RNN和IBC时经常会卡住,未删除训练数据集中包含的空闲行为(BC-RNN andIBC often get stuck in real-world experiments when the idleactions are not explicitly removed from training)
// 待更
1.4.2 扩散模型在训练中的稳定:识别动作的好坏
首先,隐式策略使用基于能量的模型(EBM)表示动作分布(An implicit policy represents the action distribution using an Energy-Based Model (EBM)),如下公式6所示:
该公式6表达的是基于能量的模型EBM)中给定观察条件 下的行动
的概率分布「用来判断在某种观察条件
下,一个动作
是否是“好”的动作」
- 其中
作为能量函数「用来衡量这个动作的“好”与“坏”,能量越低,代表这个动作越适合当前的观察条件
」,控制在给定观察条件下特定行动的概率
- 而
是一个难以计算的归一化常数(相对于a)「是一个用来“标准化”所有可能动作的常数,让所有动作的总和为1(就像是概率总和为1一样)」
总之,通过设定能量函数,模型会倾向于选择那些能量低的动作,表示这些动作更合理,在代码里,并没有明确写出公式6,因为我们不直接计算那个难算的 。而是通过训练一个网络,让它去预测能量(或者噪声),并让低能量的动作更可能被选中
其次,为了训练用于隐式策略的EBM,使用了infonce风格的损失函数「用于估计规范化常数,以此来训练基于能量的模型 (EBM)」,即下述公式7相当于公式6的负对数似然

其中的表示的是负样本的数量,在实践中,负采样的不准确性会导致EBMs的训练不稳定[11,48]
- 该infoNCE 损失相当于是一种“打分”机制,用来帮助模型识别哪个动作是“好的”。在这个公式中,
是我们想要模型认为是“好的”动作,而
是一些“坏”的动作(也叫“负样本”)
- 通过计算“好”动作和“坏”动作的能量差,我们教模型学会区分哪些是“好的”动作——也就是说,在给定的观察条件
总之,InfoNCE 损失帮助模型在“好”动作和“坏”动作之间建立对比,让模型更准确地识别“好的”动作
而在代码实现里,通过info_nce_loss函数实现这种对比损失。这个函数会把“好”动作的能量和多个“坏”动作的能量一起计算,最终得到一个分数,让模型逐渐倾向于选择那些能量较低的“好”动作
最后,扩散策略和DDPM通过建模公式6中相同动作分布的得分函数[46],回避了的估计问题:
该公式8表达了噪声预测网络在不考虑规范化常数情况下的梯度匹配
因此,扩散策略的推理过程(公式4)和训练过程(公式5)都不涉及对的评估,从而使扩散策略的训练更加稳定
总之,该公式8表示如何通过“得分匹配”来找到好动作。简单来说,就是利用能量的梯度(变化趋势)来找到最佳动作
- 上面在公式6中提到过,计算
很困难。但幸运的是,公式8告诉我们可以忽略这个
的梯度(即能量随动作的变化情况)——让我们在不计算复杂的
- 通过计算这个梯度,模型会朝着降低能量的方向去调整动作,从而逐渐找到最合适的动作
在代码里,gradient_descent_step函数实现了这种通过梯度来调整动作的操作。函数会计算能量梯度,然后更新动作,让它逐步朝着能量更低的方向移动,以找到更好的动作
1.5 总结:扩散策略的详细算法过程
最后借用此文所述的,来总结下整个的算法过程
- 训练阶段:学习“去噪”过程
在训练阶段,算法的目标是让模型学会从随机的初始动作(带有噪声的动作)逐步调整到合适的动作,这一过程称为“去噪扩散”
关键公式 1:去噪扩散过程
在这里,模型会从一个随机初始化的噪声动作开始,通过一系列迭代步骤,逐步去除噪声,让动作变得更合理
具体过程如下:
初始化:从高斯噪声中生成初始动作
去噪迭代:在每一步迭代中,模型根据当前噪声和观察条件预测噪声,通过网络
,并逐步去除噪声
最终,经过多次迭代去噪,模型生成出符合当前观察条件的“干净”动作
作用:去噪过程让模型在不确定性中找到合理的动作序列 - 得分匹配:优化动作的能量
模型不仅依赖去噪扩散过程,还会通过得分匹配来优化动作的能量。得分匹配帮助模型找到在当前观察条件下具有最低能量的动作,使得这些动作更符合环境要求
关键公式 8:得分匹配
在去噪的每一步,模型计算当前动作的能量梯度,并沿着降低能量的方向调整动作。这样一来,模型会逐渐选择更合理的动作
作用:通过能量优化找到更“合理”的动作,帮助模型生成高质量的动作序列 - InfoNCE 损失:区分“好”动作与“坏”动作
在训练过程中,模型不仅仅需要学会去噪,还需要学会区分“好”的动作(即符合演示的动作)和“坏”的动作(即不符合演示的动作)。InfoNCE损失用于帮助模型增强这种区分能力
关键公式 7:InfoNCE 损失
InfoNCE损失通过将“好”动作和多个“坏”动作进行比较,使得模型更倾向于选择符合演示的动作
作用:帮助模型更准确地区分“好”动作和“坏”动作,增强模型的学习效果 - 推理阶段:实时生成动作序列
在实际使用中,算法在给定观察条件后,执行去噪扩散生成过程以输出合理的动作。由于每次迭代都涉及去噪操作,算法使用了一些加速技巧(如减少迭代次数和硬件加速)来确保模型可以实时运行
加速推理的技巧:通过减少去噪迭代次数(例如,使用DDIM方法减少训练迭代数)来加速推理。这些加速技巧确保算法能够在复杂环境下保持实时性。
第二部分 Diffusion Policy的编码实现与源码解读
扩散策略(Diffusion Policy),包括网络的创建、数据处理、训练、推理和模型的序列化与反序列(且注意,本部分分析的代码来自DexCap库中的STEP3_train_policy/robomimic/algo/diffusion_policy.py,至于原装的扩散策略GitHub代码仓库则见:real-stanford/diffusion_policy)
- 导入依赖:代码开始部分导入了所需的库和模块。
- 算法配置到类的映射函数 (algo_config_to_class):这个函数根据算法配置(algo_config)来决定使用哪个算法类(DiffusionPolicyUNetDex 或 DiffusionPolicyUNet)以及传递给算法的额外参数。
- DiffusionPolicyUNetDex 类:这是一个算法类,继承自PolicyAlgo。它实现了扩散策略的核心功能,包括:
_create_networks:创建和配置网络结构
_adjust_brightness:调整图像的亮度
process_batch_for_training:处理训练数据
train_on_batch:在单个数据批次上训练模型
log_info:记录训练信息
reset:重置算法状态,为环境rollout做准备
get_action:根据观察和目标获取策略动作
_get_action_trajectory:获取动作轨迹
serialize 和 deserialize:序列化和反序列化模型参数 - DiffusionPolicyUNet 类:这个类与DiffusionPolicyUNetDex类似,但可能有一些不同的实现细节
比如在网络结构配置上
DiffusionPolicyUNetDex 类在创建网络时,会根据是否是单手或双手操作来设置不同的参数,如self.arm_split 和 self.action_arm_dim。这是为了适应不同的机械手臂配置。
DiffusionPolicyUNet 类没有这样的区分,它直接使用self.ac_dim作为动作维度
再比如在动作维度处理上
在DiffusionPolicyUNetDex中,有一个专门的处理流程来区分手臂和手部的动作维度,这在_get_action_trajectory方法中体现得尤为明显,其中会分别处理手臂和手部的动作。
DiffusionPolicyUNet则没有这样的区分,它直接处理整个动作序列
再比如在动作序列处理上
DiffusionPolicyUNetDex 类在get_action方法中,会从动作队列中弹出动作,并且每次只处理一个动作
DiffusionPolicyUNet 类在get_action方法中,会将整个动作序列放入动作队列,并逐个处理 - 辅助函数
replace_submodules 和 replace_bn_with_gn:这些函数用于替换网络中的特定模块,例如将BatchNorm替换为GroupNorm - 辅助类
SinusoidalPosEmb、Downsample1d、Upsample1d、Conv1dBlock、ConditionalResidualBlock1D 和 ConditionalUnet1D:这些类定义了网络的不同组件,如卷积块、下采样、上采样和条件残差块
相当于定义了一个基于UNet的网络结构,用于处理时间序列数据(如动作和观察)。这个网络结构包括多个层,每层都有条件残差块和可能的下采样或上采样操作 - 扩散调度器:代码中使用了DDPMScheduler和DDIMScheduler,这些是扩散模型中用于控制噪声添加和去除的调度器
- 指数移动平均(EMA):代码中还提到了EMA,这是一种用于平滑模型权重的技术,可以提高训练的稳定性
本第二部分的目录 如下
第二部分 Diffusion Policy的编码实现与源码解读
2.1 DiffusionPolicyUNetDex:实现扩散策略的核心功能
2.1.1 _create_networks:创建和配置网络结构(包含观察编码、噪声预测、噪声调度)
2.1.2 _adjust_brightness:调整图像帧的亮度
2.1.3 process_batch_for_training:处理从数据加载器中采样的数据批次
2.1.4 train_on_batch:在单个数据批次上训练模型(含添加噪声、预测噪声)
2.1.5 log_info:从train_on_batch方法中获取信息,并记录到TensorBoard
2.1.8 _get_action_trajectory:生成动作轨迹(接受当前观察和目标,返回动作序列)
2.2 辅助函数:替换网络中的特定模块(例如将BatchNorm替换为GroupNorm)
2.2.1 replace_submodules:替换符合条件的子模块
2.2.2 replace_bn_with_gn:调用上面的replace_submodules执行相关模块的替换
2.3.1 SinusoidalPosEmb:实现正弦位置嵌入
2.3.2 Downsample1d与Upsample1d:下采样与下采样的实现
2.3.4 ConditionalResidualBlock1D:实现条件残差块
2.3.4 ConditionalUnet1D:实现条件一维U-Net
2.1 DiffusionPolicyUNetDex:实现扩散策略的核心功能
2.1.1 _create_networks:创建和配置网络结构(包含观察编码、噪声预测、噪声调度)
这个方法负责创建和配置网络结构,包括观察编码器(obs_encoder)和噪声预测网络(noise_pred_net)。它还设置了噪声调度器(noise_scheduler)和指数移动平均(EMA)模型。
- 设置观察组:设置不同的观察组,并从配置中获取编码器的参数
def _create_networks(self): """ 创建网络并将它们放置在 @self.nets 中。 """ # 为 @MIMO_MLP 设置不同的观察组 if "label" 在 self.obs_shapes.keys(): del self.obs_shapes["label"] observation_group_shapes = OrderedDict() observation_group_shapes["obs"] = OrderedDict(self.obs_shapes) encoder_kwargs = ObsUtils.obs_encoder_kwargs_from_config(self.obs_config.encoder) - 创建观察编码器:创建观察编码器,并将所有 BatchNorm 替换为 GroupNorm,以配合EMA 使用
obs_encoder = ObsNets.ObservationGroupEncoder( observation_group_shapes=observation_group_shapes, encoder_kwargs=encoder_kwargs, ) # 重要! # 将所有 BatchNorm 替换为 GroupNorm 以配合 EMA 使用 # 如果忘记这样做,性能会大幅下降! obs_encoder = replace_bn_with_gn(obs_encoder) obs_dim = obs_encoder.output_shape()[0] - 设置手部噪声和动作维度:设置是否使用手部噪声,并根据手部类型(单手或双手)设
置动作维度self.use_handnoise = True if self.obs_shapes["robot0_eef_pos"][0] == 3: # 单手 self.arm_split = 3 self.action_arm_dim = 7 else: # 双手 self.arm_split = 6 self.action_arm_dim = 14 - 创建网络对象:通过ConditionalUnet1D(下文2.3.5节会详述)创建噪声预测网络「基于当前观察条件和目标的轨迹,逐步去除噪声,生成一系列“高层次”动作指令」,并将观察编码器obs_encoder和噪声预测网络noise_pred_net放置在 self.nets中
# 创建网络对象 noise_pred_net = ConditionalUnet1D( input_dim=self.ac_dim, global_cond_dim=obs_dim * self.algo_config.horizon.observation_horizon ) # 最终架构有两部分 nets = nn.ModuleDict({ 'policy': nn.ModuleDict({ 'obs_encoder': obs_encoder, 'noise_pred_net': noise_pred_net }) }) nets = nets.float().to(self.device) - 设置噪声调度器:根据配置设置噪声调度器
如果启用了DDPM,则使用DDPMScheduler——控制去噪过程的步数和每一步的噪声水平
如果启用了DDIM,则使用DDIMScheduler# 设置噪声调度器 noise_scheduler = None if self.algo_config.ddpm.enabled: noise_scheduler = DDPMScheduler( num_train_timesteps=self.algo_config.ddpm.num_train_timesteps, beta_schedule=self.algo_config.ddpm.beta_schedule, clip_sample=self.algo_config.ddpm.clip_sample, prediction_type=self.algo_config.ddpm.prediction_type )
否则,抛错elif self.algo_config.ddim.enabled: noise_scheduler = DDIMScheduler( num_train_timesteps=self.algo_config.ddim.num_train_timesteps, beta_schedule=self.algo_config.ddim.beta_schedule, clip_sample=self.algo_config.ddim.clip_sample, set_alpha_to_one=self.algo_config.ddim.set_alpha_to_one, steps_offset=self.algo_config.ddim.steps_offset, prediction_type=self.algo_config.ddim.prediction_type )else: raise RuntimeError() - 设置 EMA:根据配置设置 EMA 模型
# 设置 EMA ema = None if self.algo_config.ema.enabled: ema = EMAModel(model=nets, power=self.algo_config.ema.power) - 设置属性:设置类的属性,包括网络、噪声调度器、EMA 模型、动作检查标志、观察队
列和动作队列# 设置属性 self.nets = nets self.noise_scheduler = noise_scheduler self.ema = ema self.action_check_done = False self.obs_queue = None self.action_queue = None
2.1.2 _adjust_brightness:调整图像帧的亮度
调整图像帧的亮度。这个方法确保输入张量在CUDA设备上,并为每个批次生成一个随机的亮度调整因子,然后应用这个因子并限制值的范围在0到1之间
- 方法定义
def _adjust_brightness(self, tensor): """ 调整一批图像帧的亮度。 期望张量的形状为 [batch_size, frame_sequence, channels, height, width]。 每批次的亮度调整是相同的,但在批次之间有所不同。 Args: tensor (torch.Tensor): 输入张量。 Returns: torch.Tensor: 亮度调整后的张量。 """ - 确保张量在 CUDA 设备上:检查输入张量是否在 CUDA 设备上。如果不是,则抛出一个错误
# 确保张量在 CUDA 设备上 if not tensor.is_cuda: raise ValueError("输入张量不是 CUDA 张量") - 生成随机亮度调整因子:为每个批次生成一个随机的亮度调整因子。因子的范国在 0.8
到1.2 之间,但可以根据需要调整范围# 为每个批次生成一个随机的亮度调整因子 # 因子的范围例如在 0.5 到 1.5 之间,但可以调整范围 batch_size = tensor.size(0) brightness_factor = torch.empty(batch_size, 1, 1, 1, 1).uniform_(0.8, 1.2).to(tensor.device) - 应用亮度调整:将亮度调整因子应用到输入张量上
# 应用亮度调整 adjusted_tensor = tensor * brightness_factor - 剪辑值以确保它们在。到1范围内:将调整后的张量值剪辑到 0 到1的范围内,以确保亮度调整后的值在有效范围内
# 剪辑值以确保它们在 0 到 1 范围内 adjusted_tensor.clamp_(0, 1) - 返回调整后的张量:返回亮度调整后的张量
return adjusted_tensor
2.1.3 process_batch_for_training:处理从数据加载器中采样的数据批次
处理从数据加载器中采样的数据批次,以过滤相关信息并准备用于训练的批次。它还检查动作是否被归一化到[-1,1]的范围内。
2.1.4 train_on_batch:在单个数据批次上训练模型(含添加噪声、预测噪声)
该函数train_on_batch在单个数据批次上训练模型,具体而言,逐一执行以下步骤
- 定义
def train_on_batch(self, batch, epoch, validate=False): """ 在单个数据批次上进行训练 Args: batch (dict): 从数据加载器中采样并由 @process_batch_for_training 过滤的包含 torch.Tensors 的字典 epoch (int): 纪元编号 - 某些算法需要执行分阶段训练和提前停止 validate (bool): 如果为 True,则不执行任何学习更新 Returns: info (dict): 包含相关输入、输出和损失的字典,可能与日志记录相关 """ - 获取时间步长和动作维度:从算法配置中获取观察、动作和预测的时间步长,以及动作维度
To = self.algo_config.horizon.observation_horizon # 获取观察时间步长 Ta = self.algo_config.horizon.action_horizon # 获取动作时间步长 Tp = self.algo_config.horizon.prediction_horizon # 获取预测时间步长 action_dim = self.ac_dim # 获取动作维度 B = batch['actions'].shape[0] # 获取批次大小 - 进入无梯度上下文:如果 validate 为 True,则不计算梯度
with TorchUtils.maybe_no_grad(no_grad=validate): # 进入无梯度上下文,如果 validate 为 True,则不计算梯度 info = super(DiffusionPolicyUNetDex, self).train_on_batch(batch, epoch, validate=validate) # 调用父类的 train_on_batch 方法 actions = batch['actions'] # 获取动作张量 - 添加手部噪声:如果使用手部噪声并且存在手部观察,则生成手部噪声并添加到手部观察中
if self.use_handnoise and "robot0_eef_hand" in self.obs_shapes.keys(): # 如果使用手部噪声并且存在手部观察 handnoise = torch.randn_like(batch["obs"]["robot0_eef_hand"]) * 0.03 # 生成手部噪声 batch["obs"]["robot0_eef_hand"] += handnoise # 将噪声添加到手部观察中 - 编码观察:将观察和目标编码为特征,并将观察特征展平
# 编码观察 inputs = { 'obs': batch["obs"], # 获取观察 'goal': batch["goal_obs"] # 获取目标观察 } for k in self.obs_shapes: # 遍历观察形状 # 输入的前两个维度应该是 [B, T] assert inputs['obs'][k].ndim - 2 == len(self.obs_shapes[k]) obs_features = TensorUtils.time_distributed(inputs, self.nets['policy']['obs_encoder'], inputs_as_kwargs=True) # 编码观察 assert obs_features.ndim == 3 # [B, T, D] obs_cond = obs_features.flatten(start_dim=1) # 将观察特征展平 - 采样噪声并添加到动作中:生成噪声,并根据扩散迭代时间步长将噪声添加到动作中
# 采样噪声以添加到动作中 noise = torch.randn(actions.shape, device=self.device) # 生成噪声 # 为每个数据点采样一个扩散迭代 timesteps = torch.randint( 0, self.noise_scheduler.config.num_train_timesteps, (B,), device=self.device ).long() # 生成扩散迭代时间步长 # 根据每次扩散迭代的噪声幅度将噪声添加到干净的动作中 # (这是前向扩散过程) noisy_actions = self.noise_scheduler.add_noise(actions, noise, timesteps) # 添加噪声到动作中 - 预测噪声残差:使用噪声预测网络noise_pred_net 预测噪声残差
# 预测噪声残差 noise_pred = self.nets['policy']['noise_pred_net'](noisy_actions, timesteps, global_cond=obs_cond) # 预测噪声残差 noise_arm = noise[..., :self.action_arm_dim].contiguous() # 获取手臂噪声 noise_pred_arm = noise_pred[..., :self.action_arm_dim].contiguous() # 获取预测的手臂噪声 noise_hand = noise[..., self.action_arm_dim:].contiguous() # 获取手部噪声 noise_pred_hand = noise_pred[..., self.action_arm_dim:].contiguous() # 获取预测的手部噪声 - 计算 L2 损失:计算手臂和手部的L2 损失
# L2 损失 loss = F.mse_loss(noise_pred_arm, noise_arm) * 0.7 + F.mse_loss(noise_pred_hand, noise_hand) * 0.3 # 计算 L2 损失 - 日志记录:记录 L2 损失,并将损失从计算图中分离
# 日志记录 losses = { 'l2_loss': loss # 记录 L2 损失 } info["losses"] = TensorUtils.detach(losses) # 将损失从计算图中分离 - 梯度步骤:如果不是验证模式,则执行梯度步骤,并更新 EMA
if not validate: # 如果不是验证模式 # 梯度步骤 policy_grad_norms = TorchUtils.backprop_for_loss( net=self.nets, # 网络 optim=self.optimizers["policy"], # 优化器 loss=loss, # 损失 ) # 更新模型权重的指数移动平均值 if self.ema is not None: # 如果启用了 EMA self.ema.step(self.nets) # 更新 EMA step_info = { 'policy_grad_norms': policy_grad_norms # 记录梯度范数 } info.update(step_info) # 更新信息字典 - 返回信息字典:返回包含相关输入、输出和损失的信息字典
return info # 返回信息字典
2.1.5 log_info:从train_on_batch方法中获取信息,并记录到TensorBoard
处理训练批次的信息,以汇总要传递给TensorBoard进行记录的信息。
2.1.6 reset
重置算法状态,为环境rollout做准备。这包括设置观察队列和动作队列
2.1.7 get_action:获取策略动作输出
get_action这个方法用于获取策路动作输出。它接受当前观察和可选的目标作为输入,并返回动作张量
def get_action(self, obs_dict, goal_dict=None):
"""
获取策略动作输出。
Args:
obs_dict (dict): 当前观察 [1, Do]
goal_dict (dict): (可选)目标
Returns:
action (torch.Tensor): 动作张量 [1, Da]
"""具体步骤包括:
- 获取观察和动作的时问步长:从算法配置中获取观察和动作的时间步长
(注,如上文1.2.2节中所述,# obs_dict: key: [1,D] To = self.algo_config.horizon.observation_horizon Ta = self.algo_config.horizon.action_horizon - 检查动作队列是否为空:如果动作队列为空,则运行推理以生成动作序列,并将其放入动作队列中
至于其中的_get_action_trajectory,下一节会讲其实现if len(self.action_queue) == 0: # 没有剩余动作,运行推理 # 将 obs_queue 转换为张量字典(在 T 维度上连接) # import pdb; pdb.set_trace() # obs_dict_list = TensorUtils.list_of_flat_dict_to_dict_of_list(list(self.obs_queue)) # obs_dict_tensor = dict((k, torch.cat(v, dim=0).unsqueeze(0)) for k,v in obs_dict_list.items()) # 运行推理 # [1,T,Da] action_sequence = self._get_action_trajectory(obs_dict=obs_dict) # 将动作放入队列 self.action_queue.extend(action_sequence[0][3:13]) - 执行动作:从动作队列中取出一个动作,并将其维度扩展为[1,Da],然后返回该动作
# 有动作,从左到右执行 # [Da] action = self.action_queue.popleft() # [1,Da] action = action.unsqueeze(0) return action
2.1.8 _get_action_trajectory:生成动作轨迹(接受当前观察和目标,返回动作序列)
这段代码实现了一个名为-get_action_trajectory 的方法,用于生成动作轨迹,它接受当前观察和可选的目标作为输入,并返回动作序列
def _get_action_trajectory(self, obs_dict, goal_dict=None):
assert not self.nets.training具体步骤包括:
- 获取时间步长和动作维度:从算法配置中获取观察、动作和预测的时间步长,以及动作维度
To = self.algo_config.horizon.observation_horizon Ta = self.algo_config.horizon.action_horizon Tp = self.algo_config.horizon.prediction_horizon action_dim = self.ac_dim - 设置推理时问步长:根据配置设置推理时间步长
if self.algo_config.ddpm.enabled is True: num_inference_timesteps = self.algo_config.ddpm.num_inference_timesteps elif self.algo_config.ddim.enabled is True: num_inference_timesteps = self.algo_config.ddim.num_inference_timesteps else: raise ValueError - 选择网络:选择用于推理的网络。如果启用了 EMA,则使用 EMA 的平均模型
# 选择网络 nets = self.nets if self.ema is not None: nets = self.ema.averaged_model - 编码观察:将观察和目标编码为特征
首先,确保输入的前两个维度是 [B,T〕,然后,使用时问分布编码器将输入编码为特征# 编码观察 inputs = { 'obs': obs_dict, 'goal': goal_dict } for k in self.obs_shapes: # 前两个维度应该是 [B, T] assert inputs['obs'][k].ndim - 2 == len(self.obs_shapes[k]) obs_features = TensorUtils.time_distributed(inputs, self.nets['policy']['obs_encoder'], inputs_as_kwargs=True) assert obs_features.ndim == 3 # [B, T, D] B = obs_features.shape[0] - 重塑观察:将观察特征重塑为 (B,obs_horizon * obs_dim)的形状
# 将观察重塑为 (B,obs_horizon*obs_dim) obs_cond = obs_features.flatten(start_dim=1) - 从高斯噪声初始化动作:从高斯噪声初始化动作
# 从高斯噪声初始化动作 noisy_action = torch.randn( (B, Tp, action_dim), device=self.device) naction = noisy_action - 初始化调度器:初始化噪声调度器
# 初始化调度器 self.noise_scheduler.set_timesteps(num_inference_timesteps) - 预测噪声并进行逆扩散步骤:在每个时间步长上预测噪声,并进行逆扩散步骤以去除噪声
for k in self.noise_scheduler.timesteps: # 预测噪声 noise_pred = nets['policy']['noise_pred_net']( sample=naction, timestep=k, global_cond=obs_cond ) # 逆扩散步骤(去除噪声) naction = self.noise_scheduler.step( model_output=noise_pred, timestep=k, sample=naction ).prev_sample - 处理动作并返回:使用动作时间步长处理动作,并返回动作序列
# 使用 Ta 处理动作 start = To - 1 end = start + Ta action = naction[:, start:end] return action
2.1.9 serialize 和 deserialize
序列化和反序列化模型参数。serialize 方法返回一个包含网络参数的字典,而 deserialize 方法从这个字典中加载模型参数
2.2 辅助函数:替换网络中的特定模块(例如将BatchNorm替换为GroupNorm)
2.2.1 replace_submodules:替换符合条件的子模块
该函数用于替换符合条件的子模块
- 方法定义
它接受三个参数:def replace_submodules( root_module: nn.Module, predicate: Callable[[nn.Module], bool], func: Callable[[nn.Module], nn.Module]) -> nn.Module: """ Replace all submodules selected by the predicate with the output of func. predicate: Return true if the module is to be replaced. func: Return new module to use. """
。root_module:根模块,类型为 nn. Module
。predicate :谓词函数,接受一个模块作为输入,返回一个布尔值,表示该模块是
否需要被替换
。func:函数,接受一个模块作为输入,返回一个新的模块,用于替换原模块 - 检查根模块是否符合条件,如果符合条件,则直接返回替换后的模块
if predicate(root_module): return func(root_module) - 检查pytorch版本是否大于1.9,如果版本过低,则抛出导入错误
if parse_version(torch.__version__) < parse_version('1.9.0'): raise ImportError('This function requires pytorch >= 1.9.0') -
查找符合条件的子模块
bn_list = [k.split('.') for k, m in root_module.named_modules(remove_duplicate=True) if predicate(m)] -
替换符合条件的子模块,具体而言
首先获取父模块for *parent, k in bn_list: parent_module = root_module if len(parent) > 0: parent_module = root_module.get_submodule('.'.join(parent))其次获取源模块
if isinstance(parent_module, nn.Sequential): src_module = parent_module[int(k)] else: src_module = getattr(parent_module, k)接着使用func函数生成目标模块
tgt_module = func(src_module)最后将源模块替换为目标模块
if isinstance(parent_module, nn.Sequential): parent_module[int(k)] = tgt_module else: setattr(parent_module, k, tgt_module) -
验证所有模块已被替换
# verify that all modules are replaced bn_list = [k.split('.') for k, m in root_module.named_modules(remove_duplicate=True) if predicate(m)] assert len(bn_list) == 0这部分代码再次查找所有符合条件的子模块,并确保它们已被替换,如果还有未被替换的模块,则抛出断言错误
-
返回根模块
return root_module
2.2.2 replace_bn_with_gn:调用上面的replace_submodules执行相关模块的替换
该函数用于将所有的BatchNorm层替换为GroupNorm层
- 方法定义,其接受两个参数
root_module:根模块,类型为 nn.Module。def replace_bn_with_gn( root_module: nn.Module, features_per_group: int=16) -> nn.Module: """ 将所有 BatchNorm 层替换为 GroupNorm 层。 Args: root_module (nn.Module): 根模块 features_per_group (int): 每组的特征数,默认为 16 Returns: nn.Module: 替换后的根模块 """
features_per_group:每组的特征数,默认为 16 - 调用replace_submodules函数
1.根模块:传递根模块 root_module
2.谓词函数:传递一个匿名函数 Lambda x: isinstanceCx, nn. BatchNorm2d),用于检查模块是否为 nn. BatchNorm2dreplace_submodules( root_module=root_module,
3.替换函数:传递一个匿名函数 Lambda x:nn. GroupNorm(num_groups=x.num_features // features_per_group,num-channel s=x.num_features),用于将 BatchNorm 层替换为 GroupNorm层predicate=lambda x: isinstance(x, nn.BatchNorm2d),func=lambda x: nn.GroupNorm( num_groups=x.num_features // features_per_group, num_channels=x.num_features) )
2.3 UNet for Diffusion
2.3.1 SinusoidalPosEmb:实现正弦位置嵌入
SinusoidalPosEmb这个类实现了正弦位置嵌入,用于将输入张量转换为正弦和余弦形式的嵌入
class SinusoidalPosEmb(nn.Module):
// 初始化方法接收一个参数dim,表示嵌入的维度,并将其存储在实例变量self.dim中
def __init__(self, dim):
super().__init__()
self.dim = dim
// 前向传播方法,接受一个输入张量x
def forward(self, x):
device = x.device
half_dim = self.dim // 2
emb = math.log(10000) / (half_dim - 1)
// 生成嵌入向量
emb = torch.exp(torch.arange(half_dim, device=device) * -emb)
// 输入张量和嵌入向量相乘
emb = x[:, None] * emb[None, :]
// 将正弦和余弦嵌入拼接在一起
emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
return emb2.3.2 Downsample1d与Upsample1d:下采样与下采样的实现
Downsample1d这个类则实现了一维下采样,永远将输入张量的时间维度减半
- 初始化
初始化方法接受一个参数 dim,表示输入和输出的通道数,并创建一个一维卷积层def __init__(self, dim): super().__init__() self.conv = nn.Conv1d(dim, dim, 3, 2, 1)
self.conv,用于下采样
- 前向传播
前向传播方法接受一个输入张量 x,并通过卷积层 self.conv 进行下采样,然后返回def forward(self, x): return self.conv(x)
下采样后的张量
Upsample1d这个类则实现了一维上采样,用于将输入张量的时间维度加倍
- 初始化
初始化方法接受一个参数dim,表示输入和输出的通道数,并创建一个一维转置卷积层def __init__(self, dim): super().__init__() self.conv = nn.ConvTranspose1d(dim, dim, 4, 2, 1)
self.conv ,用于上采样 - 前向传播
def forward(self, x): return self.conv(x)
2.3.3 Conv1dBlock:实现一维卷积块
class Conv1dBlock(nn.Module):
'''
Conv1d --> GroupNorm --> Mish
一维卷积 --> 组归一化 --> Mish 激活函数
'''
def __init__(self, inp_channels, out_channels, kernel_size, n_groups=8):
super().__init__() # 调用父类的初始化方法
# 使用 nn.Sequential 创建一个顺序容器
self.block = nn.Sequential(
nn.Conv1d(inp_channels, out_channels, kernel_size, padding=kernel_size // 2), # 一维卷积层,带有适当的填充
nn.GroupNorm(n_groups, out_channels), # 组归一化层
nn.Mish(), # Mish 激活函数
)
def forward(self, x):
return self.block(x) # 前向传播方法,将输入 x 通过顺序容器 self.block 进行处理可以看到
- • 初始化方法接受四个参数:
。inp_channels:输入通道数
。out_channels:输出通道数
。kernel_size:卷积核大小
。n_groups:组归一化的组数,默认为 8 - 然后初始化方法创建一个顺序容器 self.block,包含以下层:
1.一维卷积层:nn. Conv1d,输入通道数为 inp_channels,输出通道数为out_channels,卷积核大小为 kernel-size,填充为 kernel-size // 2
2.组归一化层:nn.GroupNorm
2.3.4 ConditionalResidualBlock1D:实现条件残差块
这个类ConditionalResidualBlock1D用于实现条件一维残差块
- 类定义
class ConditionalResidualBlock1D(nn.Module): # 定义 ConditionalResidualBlock1D 类,继承自 nn.Module - 初始化方法
def __init__(self, in_channels, # 输入通道数 out_channels, # 输出通道数 cond_dim, # 条件维度 kernel_size=3, # 卷积核大小,默认为 3 n_groups=8): # GroupNorm 的组数,默认为 8 super().__init__() # 调用父类的初始化方法 - 定义卷积块
self.blocks = nn.ModuleList([ # 定义卷积块列表 Conv1dBlock(in_channels, out_channels, kernel_size, n_groups=n_groups), # 第一个卷积块 Conv1dBlock(out_channels, out_channels, kernel_size, n_groups=n_groups), # 第二个卷积块 ]) - 定义条件编码器
# FiLM modulation https://arxiv.org/abs/1709.07871 # predicts per-channel scale and bias cond_channels = out_channels * 2 # 条件通道数为输出通道数的两倍 self.out_channels = out_channels # 设置输出通道数 self.cond_encoder = nn.Sequential( # 定义条件编码器 nn.Mish(), # Mish 激活函数 nn.Linear(cond_dim, cond_channels), # 线性层 nn.Unflatten(-1, (-1, 1)) # 取消展平 ) - 定义残差卷积
# make sure dimensions compatible self.residual_conv = nn.Conv1d(in_channels, out_channels, 1) \ # 定义残差卷积,如果输入通道数不等于输出通道数,则进行卷积 if in_channels != out_channels else nn.Identity() # 否则使用 Identity 层 - 前向传播方法
def forward(self, x, cond): # 定义前向传播方法 ''' x : [ batch_size x in_channels x horizon ] cond : [ batch_size x cond_dim] returns: out : [ batch_size x out_channels x horizon ] ''' - 通过第一个卷积块
out = self.blocks[0](x) # 通过第一个卷积块 - 编码条件
embed = self.cond_encoder(cond) # 编码条件 embed = embed.reshape( # 重新调整条件编码的形状 embed.shape[0], 2, self.out_channels, 1) scale = embed[:,0,...] # 获取缩放因子 bias = embed[:,1,...] # 获取偏置 out = scale * out + bias # 应用 FiLM 调制 - 通过第二个卷积块
out = self.blocks[1](out) # 通过第二个卷积块 - 添加残差连接
out = out + self.residual_conv(x) # 添加残差连接 return out # 返回输出
2.3.5 ConditionalUnet1D:实现条件一维U-Net——预测扩散过程中的噪声
ConditionalUnet1D这个类继承自nn.Module,用于实现条件一维U-Net,其用于预测扩散过程中的噪声
- 首先,其接受多个参数,用于配置 U-Net 的结构和参数
def __init__(self, input_dim, # 动作的维度 global_cond_dim, # 全局条件的维度,通常是 obs_horizon * obs_dim diffusion_step_embed_dim=256, # 扩散迭代 k 的位置编码大小 down_dims=[256,512,1024], # 每个 U-Net 层的通道大小,数组的长度决定了层数 kernel_size=5, # 卷积核大小 n_groups=8 # GroupNorm 的组数 ): - 初始化父类和设置维度
super().__init__() # 调用父类的初始化方法 all_dims = [input_dim] + list(down_dims) # 设置所有层的维度 start_dim = down_dims[0] # 设置起始维度 - 定义扩散步骤编码器:用于对扩散步骤进行编码,并计算条件维度
dsed = diffusion_step_embed_dim # 扩散步骤编码维度 diffusion_step_encoder = nn.Sequential( # 定义扩散步骤编码器 SinusoidalPosEmb(dsed), # 正弦位置嵌入 nn.Linear(dsed, dsed * 4), # 线性层 nn.Mish(), # Mish 激活函数 nn.Linear(dsed * 4, dsed), # 线性层 ) cond_dim = dsed + global_cond_dim # 条件维度 - 定义中间模块:使用条件残差块
in_out = list(zip(all_dims[:-1], all_dims[1:])) # 输入输出维度对 mid_dim = all_dims[-1] # 中间层维度 self.mid_modules = nn.ModuleList([ # 定义中间模块 ConditionalResidualBlock1D( mid_dim, mid_dim, cond_dim=cond_dim, kernel_size=kernel_size, n_groups=n_groups ), ConditionalResidualBlock1D( mid_dim, mid_dim, cond_dim=cond_dim, kernel_size=kernel_size, n_groups=n_groups ), ]) - 定义下采样模块:使用条件残差块ConditionalResidualBlock1D和下采样层Downsample1d
down_modules = nn.ModuleList([]) # 定义下采样模块列表 for ind, (dim_in, dim_out) in enumerate(in_out): # 遍历输入输出维度对 is_last = ind >= (len(in_out) - 1) # 判断是否为最后一层 down_modules.append(nn.ModuleList([ # 添加下采样模块 ConditionalResidualBlock1D( dim_in, dim_out, cond_dim=cond_dim, kernel_size=kernel_size, n_groups=n_groups), ConditionalResidualBlock1D( dim_out, dim_out, cond_dim=cond_dim, kernel_size=kernel_size, n_groups=n_groups), Downsample1d(dim_out) if not is_last else nn.Identity() # 如果不是最后一层,则添加下采样层,否则添加 Identity 层 ])) - 定义上采样模块:使用条件残差块ConditionalResidualBlock1D和上采样层Upsample1d
up_modules = nn.ModuleList([]) # 定义上采样模块列表 for ind, (dim_in, dim_out) in enumerate(reversed(in_out[1:])): # 遍历反转后的输入输出维度对 is_last = ind >= (len(in_out) - 1) # 判断是否为最后一层 up_modules.append(nn.ModuleList([ # 添加上采样模块 ConditionalResidualBlock1D( dim_out*2, dim_in, cond_dim=cond_dim, kernel_size=kernel_size, n_groups=n_groups), ConditionalResidualBlock1D( dim_in, dim_in, cond_dim=cond_dim, kernel_size=kernel_size, n_groups=n_groups), Upsample1d(dim_in) if not is_last else nn.Identity() # 如果不是最后一层,则添加上采样层,否则添加 Identity 层 ])) - 定义最终卷积层:用于生成输出
final_conv = nn.Sequential( # 定义最终卷积层 Conv1dBlock(start_dim, start_dim, kernel_size=kernel_size), nn.Conv1d(start_dim, input_dim, 1), ) - 设置模块属性
self.diffusion_step_encoder = diffusion_step_encoder # 设置扩散步骤编码器 self.up_modules = up_modules # 设置上采样模块 self.down_modules = down_modules # 设置下采样模块 self.final_conv = final_conv # 设置最终卷积层 print("number of parameters: {:e}".format( # 打印参数数量 sum(p.numel() for p in self.parameters())) ) - 前向传播方法:
接受输入张量def forward(self, sample: torch.Tensor, # 输入张量 timestep: Union[torch.Tensor, float, int], # 扩散步骤 global_cond=None): # 全局条件 """ x: (B,T,input_dim) timestep: (B,) 或 int,扩散步骤 global_cond: (B,global_cond_dim) output: (B,T,input_dim) """
处理扩散步骤sample = sample.moveaxis(-1,-2) # 将输入张量的最后一个维度移动到第二个维度 # (B,C,T)
计算全局特征timesteps = timestep # 获取扩散步骤 if not torch.is_tensor(timesteps): # 如果扩散步骤不是张量 timesteps = torch.tensor([timesteps], dtype=torch.long, device=sample.device) # 将其转换为张量 elif torch.is_tensor(timesteps) and len(timesteps.shape) == 0: # 如果扩散步骤是标量张量 timesteps = timesteps[None].to(sample.device) # 将其扩展为一维张量 timesteps = timesteps.expand(sample.shape[0]) # 将扩散步骤扩展到批次维度
下采样过程global_feature = self.diffusion_step_encoder(timesteps) # 计算全局特征 if global_cond is not None: # 如果全局条件不为空 global_feature = torch.cat([ # 将全局特征和全局条件拼接在一起 global_feature, global_cond ], axis=-1)
中间过程x = sample # 获取输入张量 h = [] # 定义中间结果列表 for idx, (resnet, resnet2, downsample) in enumerate(self.down_modules): # 遍历下采样模块 x = resnet(x, global_feature) # 通过第一个条件残差块 x = resnet2(x, global_feature) # 通过第二个条件残差块 h.append(x) # 将结果添加到中间结果列表 x = downsample(x) # 通过下采样层
上采样过程for mid_module in self.mid_modules: # 遍历中间模块 x = mid_module(x, global_feature) # 通过中间模块
最终卷积层for idx, (resnet, resnet2, upsample) in enumerate(self.up_modules): # 遍历上采样模块 x = torch.cat((x, h.pop()), dim=1) # 将当前结果和中间结果拼接在一起 x = resnet(x, global_feature) # 通过第一个条件残差块 x = resnet2(x, global_feature) # 通过第二个条件残差块 x = upsample(x) # 通过上采样层
最终,返回输出张量x = self.final_conv(x) # 通过最终卷积层x = x.moveaxis(-1,-2) # 将输出张量的第二个维度移动到最后一个维度 # (B,T,C) return x # 返回输出
第三部分(选读) Diff-Control:改进UMI所用的扩散策略(含ControlNet简介)
3.1 Diff-Control是什么及其提出的背景
3.1.1 背景
自从24年年初斯坦福等一系列机器人横空出世以来,模仿学习已经成为训练机器人的重要方法,其中,基于扩散的策略「4-Diffusion policy: Visuomotor policy learning via action diffusion」——因其有效建模多模态动作分布的能力而脱颖而出,从而提升了性能
然而,在实践中,动作表示的不一致性问题仍然是一个持续的挑战,这种不一致性可能导致机器人轨迹分布与底层环境之间的明显差异,从而限制控制策略的有效性[5-Robot learning from human demonstrations with inconsistent contexts]
这种不一致性的主要原因通常源于
- 人类演示的丰富上下文性质[6-What matters in learning from offline human demonstrations for robot manipulation]
- 分布转移问题[7- A reductionof imitation learning and structured prediction to no-regret online learning]
- 以及高动态环境的波动性
其实本质上是无状态的,缺乏将记忆和先验知识纳入控制器的机制,从而导致动作生成的不一致性,即they are fundamentally stateless, lackingprovisions for incorporating memory and prior knowledgeinto the controller, potentially leading to inconsistent actiongeneration
先前的方法,如
- 动作分块「8-Learning fine-grained bimanual manipulation with low-cost hardware,即ACT,其原理详见此文《ACT的原理解析:斯坦福炒虾机器人Moblie Aloha的动作分块算法ACT》」和预测闭环动作序列[4-扩散策略],已被提出以解决这一问题
- 此外,Hydra[9]和基于航点的操作[10]修改动作表示以确保一致性
然而,这些方法通过改变动作表示来解决问题,而不是直接使用原始动作
相反,能否通过在扩散策略中加入时间转换来明确地施加时间一致性?在深度状态空间模型领域[11- Deep state space models for time series forecasting]–[13-How to train your differentiable filter],有效学习状态转换模型能够识别潜在的动态模式
3.1.2 什么是Diff-Control:通过ControlNet将状态信息融入扩散策略中
对此,作者团队于2024年7月提出了Diff-Control「其对应的论文为Diff-Control: A Stateful Diffusion-based Policy for Imitation Learning」,一种基于扩散的状态策略,它生成动作并同时学习动作转换模型,其基于[14- Adding conditional control to text-to-image diffusion models]在图像生成中引入的ControlNet框架,利用它作为转换模型,为基础扩散策略提供时间调控
关于Diff-Control的构建基础,即什么是ControlNet,详见此文《AI绘画原理解析:从CLIP、BLIP到DALLE、DALLE 2、DALLE 3、Stable Diffusion(含ControlNet详解)》的第3.3节 给SD装上方向盘之ControlNet的详解及其应用:微调SD
如下图所示,先前的动作序列(蓝色)在生成新的动作序列(红色)时用作条件

Diff-Control的关键目标是学习如何将状态信息融入扩散策略的决策过程中
下图展示了这种行为的一个示例:

- 如上图中部所示,一个学习近似余弦函数的策略,在时间点
- 相比之下,如上图左侧所示,Diff-Control通过整合时间条件,使其能够在生成轨迹时考虑过去的状态
为此,所提出的方法利用了最新的ControlNet架构,以确保机器人动作生成中的时间一致性
在CV领域中,ControlNet用于稳定扩散模型,以在生成图像或视频序列时启用额外的控制输入或附加条件
Diff-Control团队将ControlNet的基本原理从图像生成扩展到动作生成,并将其用作状态空间模型,在该模型中,系统的内部状态、观测(摄像头输入)、和人类语言指令共同影响策略的输出「Our method extends the basic principle of ControlNet from image generation to action generation, and use it as a state-space model in which the internal state of the system affects the output of the policy in conjunction with observations (camerainput) and human language instructions」
如下图所示,是Diff-Control在“打开盖子”任务中的实际应用

- 每个时间窗口内(如红色所示),Diff-Control 生成动作序列
Within each time window (depicted in red), Diff-Control generates action sequences - 在生成后续动作序列时,它利用先前的动作作为额外的控制输入,如蓝色所示
When generat-ing subsequent action sequences, it utilizes previous actionsas an additional control input, shown in blue.
这种时间过渡是通过贝叶斯公式实现的,有效地弥合了独立策略与状态空间建模之间的差距
This temporaltransition is achieved through Bayesian formulation, effec-tively bridging the gap between standalone policies and statespace modeling
3.2 Diff-Control的技术架构
3.2.1 从扩散模型到递归贝叶斯公式
回顾一下扩散模型的背景知识
扩散模型通过迭代的将高斯噪声映射到目标分布,且可以选择性的基于上下文信息进行条件生成
- 比如给定初始点
,扩散模型预测输出序列为
,其中每个后续输出都是前一个输出的去噪版本(说白了,整个过程就是去噪的过程),故
就是扩散过程的输出
- 然后使用去噪扩散概率模型(DDPM)作为骨干网络。在训练过程中,噪声输入可以通过不同的噪声水平生成:
,其中
是方差调度,
是随机噪声,
- 接下来,可以训练一个神经网络
来预测添加到输入中的噪声,通过最小化以下公式
其中,表示观察和动作对,
是去噪时间步,
在采样步骤中,迭代运行去噪过程
整个过程相当于不断减掉每一步添加的噪声
接下来,目标是学习一个以条件和观察
为输入的策略
在这个背景下,定义为包含机器人末端执行器姿态的轨迹。与之前的方法[4],[32]一致,现在的目标也是将多个条件作为输入。然而,正如在上文所提到的,尽管之前的工作[4], [8], [9]已经努力探索稳健的动作生成,但它们并没有考虑到a的状态性
故下面通过在动作空间中引入转移,从贝叶斯的角度解决动作一致性问题(We address the action consistency from a Bayesian perspective by introducing transition in action spaces)
- 首先,有如下方程
- 令
,应用马尔可夫性质,即假设下一个生成的轨迹仅依赖于当前的轨迹,得到
其中,是归一化因子,
是观测模型,
是转移模型,这个转移模型描述了系统动力学演化的规律,而观测模型则确定了系统内部状态与观测到的噪声测量值之间的关系
3.2.2 Diff-Control Policy:结合贝叶斯公式与扩散模型
接下来,展示如何将贝叶斯公式和扩散模型结合在一起,使得一个策略可以生成有状态的动作序列,从而促进一致的机器人行为
他们提出了如下图所示的Diff-Control策略,其参数为
其中,代表执行时间范围,
表示以自然人类指令形式出现的语言条件,
表示由场景的RGB相机捕获的一系列图像
策略生成一个轨迹窗口
,其中
指的是窗口大小或预测时间范围
贝叶斯公式中的Diff-Control策略包含两个关键模块
- 转换模块接收先前的动作
并生成潜在的嵌入,以供基础策略后续使用
- 作为观测模型,基础策略结合了与
这种双模块结构使得Diff-Control策略能够巧妙地捕捉时间动态,并有助于准确且一致地生成后续动作
3.2.3 基础策略与转换模型
对于基础策略,如下图左侧所示

- 首先,按照第2.2.1节中的步骤训练一个基于扩散的策略[4]作为基础策略
- 然后采用[15-Planning with diffusion for flexible behavior synthesis]中的一维时间卷积网络,并构建U-net骨干网络
- 策略
可以自主执行并生成动作,而无需依赖任何时间信息
对于转换模型,如下图右侧所示,作者团队将ControlNet纳入为转换模块「Diff-Control Policy通过使用锁定的 U-net 扩散策略架构来实现。该策略复制了编码器和中间模块,并引入了零卷积层,即The Diff-Control Policy is implemented through the utilization of a locked U-net diffusion policy architecture. It replicates the encoder and middle blocks and incorporates zero convolution layers」
这种利用有效地扩展了策略网络的能力,使其包含时间条件(This utilization extends the capability of the policy networkto include temporal conditioning effectively)
- 为实现这一目标,利用先前生成的动作序列
作为ControlNet的提示输入
To achieve this,we utilize the previously generated action sequences as the prompt input to ControlNet. - 通过这样做,基础策略
By doing so, the base policy¯πψψψ becomes informed about the previous actions a[Wt−h].We implement ControlNet by creating a trainable replica of the ¯πψψψ encoders and then freeze the base policy ¯πψψψ.
且可训练的副本通过零卷积层[33]连接到固定模型
The trainable replica is connected to the fixed model with zero convolutional layers [33] - 最终,ControlNet可以将
ControlNet can then take a[Wt−h] as the conditioning vector and reuses the trained base policy¯πψψψ to construct the next action sequence a[Wt]
3.2.4 策略的训练与相关模型的选择
在策略的训练上,其中
- 对于基础策略
的训练
首先将观察和语言条件
编码到相同的嵌入维度
然后我们利用方程中定义的学习目标来训练基础策略
- 在微调ControlNet时也使用相同的学习目标:
整个扩散模型的总体学习目标是,
是对应的由
参数化的神经网络,且基础策略和Diff-Control策略都是端到端训练的
在模型的选择上,他们采用了基于CNN的U-net架构。这种基于CNN的骨干网络选择已被证明适用于多种任务,无论是在模拟环境还是现实场景中
在整个的模型架构中,如之前的下图所示
编码器和解码器块使用了具有不同核大小的1D卷积层
- 为了实现ControlNet的零卷积层,采用了权重初始化为零的1D1×1卷积层
这种方法确保在训练的初始阶段,任何潜在的有害噪声不会影响可训练神经网络层的隐藏状态[14] - 且在所有实验中使用窗口大小W=24作为默认预测范围,执行范围h在
因为根据[4],执行范围过大或过小都可能导致性能下降
此外,在实施语言条件任务时,他们还观察到基于扩散的策略在利用复杂的CLIP语言特征作为条件学习多样化动作时达到了某种能力上限
为了解决这个问题,更实用的方法是引入融合层并增加视觉和语言表示的嵌入大小,而不是直接将它们拼接在一起「To address this,a more practical approach is to incorporate a fuse layerand increasing embedding size for visual and language representations, instead of concatenating them directly」,这一修改可以提升策略在语言条件任务中的整体表现
3.3 实验与评估:围绕4个任务与4种基线方法PK
3.3.1 对4个任务的一般性建模
通过将Diff-Control策略与四种基线方法在五个不同的机器人任务上进行比较,包含的任务包括:(a)语言条件下的厨房任务,(b)厨房场景中的开盖任务,作为高精度任务,(c)动态场景中的捞鸭任务,(d)作为周期性任务的打鼓任务
- UR5机器人手臂的动作表示为
,其中每个动作表示为
,
其中,包括末端执行器在笛卡尔坐标系中的位置
、方向
和夹爪的关节角度
- 且对于所有任务,输入模态包括两种模态:
和
第一种模态,,对应于RGB图像
第二种模态,
下表 按主观难度升序排列任务,提供了任务特征的摘要,如干扰物数量(Dis)、专家演示数量(Dem)、不同动作数量(Act)以及是否需要高精度(HiPrec)

以下是具体的4个任务
- 语言条件厨房任务:该任务旨在模拟厨房场景中的多个任务 [35], [36]
机器人工作区由一个缩小的现实模型厨房组成,如下图所示
厨房环境包含各种物体,包括锅、平底锅、碗和类似毛绒蔬菜的干扰物。在数据收集过程中,干扰物会被随机放置。训练有素的专家负责远程操作机器人在厨房环境中执行两个特定动作。这些动作包括取回一个西红柿,并根据给定的语言指令将其放置在炉灶上的锅中(A)或水槽中(B) - 高精度开盖:任务包括抬起盖子并随后将其放置在附近的碗上,这需要精确的控制,如下图所示,盖子的把手相对较小,且盖子的表面是反光的

为了收集此任务的数据,他们获得了50次专家示范。每次示范中,引入了5个或更多干扰物体的随机放置,以及锅的位置和盖子的旋转的轻微变化 - 鸭子舀取:受[37]的启发,他们为机器人配备了一个勺子,机器人的目标是将鸭子从水中舀出来,如下图右下角所示,这一任务由于勺子进入水中引起的扰动而具有挑战性

水流影响橡皮鸭的位置,要求机器人执行精确而谨慎的动作,以成功捕捉鸭子 - 鼓点:该任务专门为机器人学习周期性动作而设计,由于需要独特的动作表示,这是一项具有挑战性的任务[38],如下图所示

该任务的难点在于机器人必须准确地计数鼓点的次数并确定何时停止敲鼓。通过远程操作机器人在每次示范中敲击鼓三次,共获得了150次专家示范
3.3.2 与4种基线在性能上的PK
为了评估diff-control的泛化能力、整体性能及其优势,他们提出的基线如下:
- Image-BC:这个基线采用图像到动作的代理框架,类似于BC-Z[2],它基于ResNet-18骨干网络,并使用FiLM [39]通过CLIP语言特征进行条件处理
- ModAttn[32]:该方法采用transformer风格的神经网络,并使用模块化结构通过神经注意力来处理任务的各个子方面,它需要人类专家正确识别每个任务的组件和子任务
- BC-Z LSTM:这个基线代表了一种受BC-Z架构启发的有状态策略。通过使用MLP和LSTM层将先前的动作和语言条件融合,实现了先前输入的整合
- 扩散策略[4]:这个基线是一个标准的扩散策略
所有基线模型均使用相同的专家演示数据进行再现和训练,总共训练3,000个周期
- 在整个训练过程中,每300个周期保存一次检查点。在他们的分析中,他们报告了这些保存的检查点中每种基线方法所获得的最佳结果
- 每个实验均在单个NVIDIA Quadro RTX 8000 GPU上以64的批量大小进行,持续约24小时
- 对于所有任务,使用Adamw优化器,学习率为1e-4
具体PK结果详见原论文

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 94
94 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)