
【论文阅读】ControlVideo: Training-free Controllable Text-to-Video Generation
controlvideo模型论文阅读
ControlVideo: Training-free Controllable Text-to-Video Generation
- 原文摘要
- 背景与问题:
- 文本驱动的diffusion model在图像生成方面取得了显著进展,但在视频生成方面仍落后。
- diffusion model的讲解可以参考这篇博客(https://blog.csdn.net/weixin_42392454/article/details/137458318)
- 视频生成的主要挑战包括:
- 时间建模的高训练成本。
- 生成视频的外观不一致性和结构闪烁问题,尤其是在生成长视频时。
- 文本驱动的diffusion model在图像生成方面取得了显著进展,但在视频生成方面仍落后。
- 解决方案:
- 提出了一种无需训练的框架 ControlVideo,旨在实现自然且高效的文本到视频生成。
- ControlVideo 基于 ControlNet,利用输入运动序列的粗略结构一致性,并引入了三个模块来改进视频生成:
- 全跨帧交互:在自注意力模块中添加跨帧交互,确保帧之间的外观一致性。
- 交错帧平滑器:通过对交替帧插值减少闪烁效应,即实现平滑效果。
- 闪烁效应:在视频生成中,闪烁效应是指视频帧之间出现不一致或突变的现象,比如颜色、亮度或结构在帧与帧之间突然变化。这种问题会导致视频看起来不连贯、不自然,尤其是在生成长视频时
- 分层采样器:通过分别合成每个短片段并保持整体一致性,来保证长视频生成的高效性。
- 性能与优势:
- ControlVideo 在大量运动-提示对上定量和定性评估中优于现有技术。
- 由于其高效设计,仅使用一块 NVIDIA 2080Ti 显卡即可在几分钟内生成短视频和长视频。
- 背景与问题:
一、介绍
1.1 背景与问题
-
文本到图像生成的突破:
- 大规模扩散模型在文本到图像生成及其创意应用方面取得了巨大突破。
-
文本到视频生成的挑战:
- 训练文本到视频模型需要大量高质量视频数据和计算资源,限制了研究和应用。
1.2 研究目标
- 利用文本到图像模型实现可控的文本到视频生成。
- 该任务的目标是基于文本描述和运动序列(例如深度图或边缘图)生成视频。
- 这种方法不是从零开始学习视频分布,而是高效利用预训练的文本到图像生成模型的生成能力,以及运动序列的粗略时间一致性,来生成生动的视频。
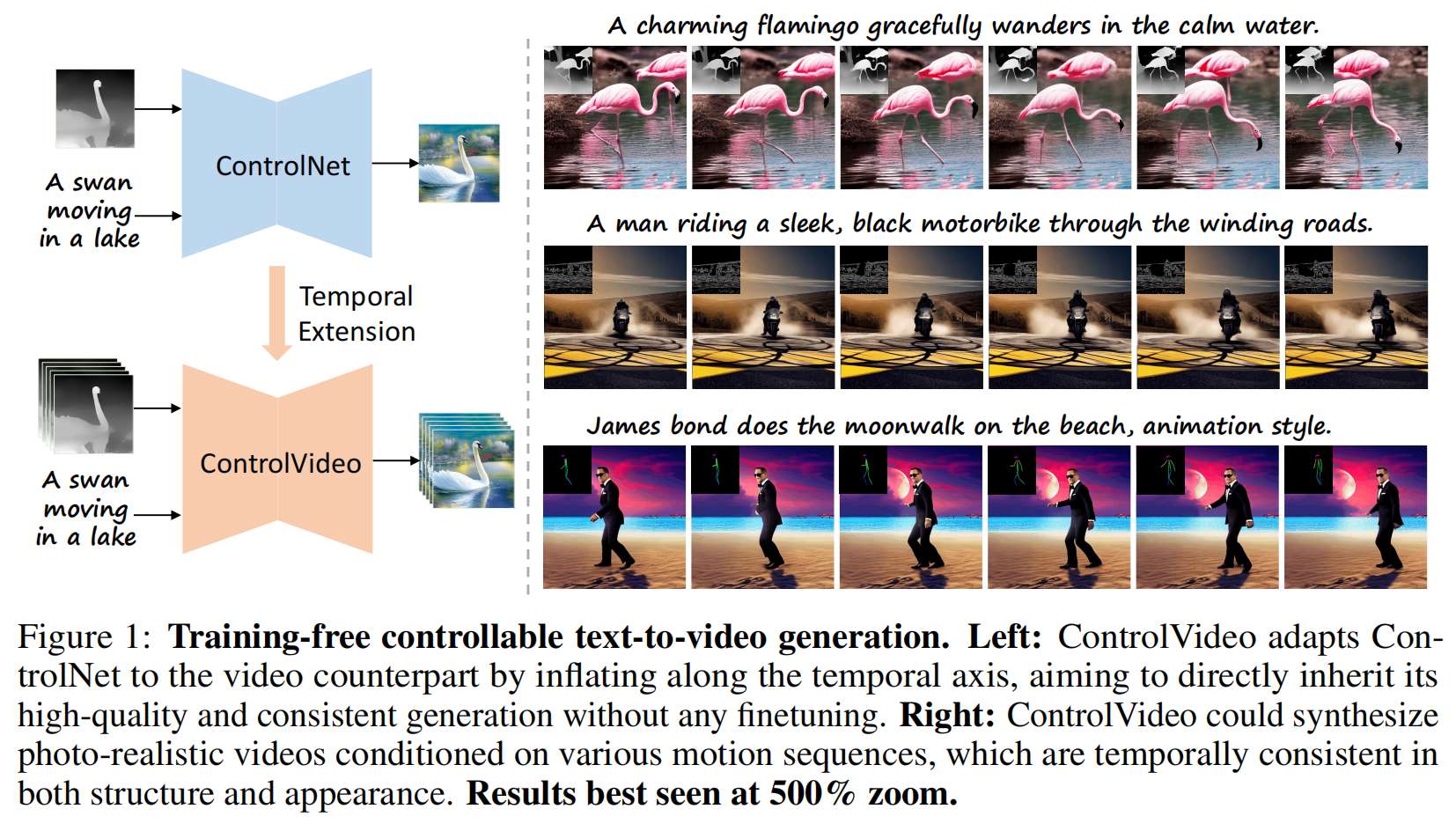
- 左图:ControlVideo 通过沿时间轴扩展 ControlNet,将其适配到视频生成任务中,旨在直接继承其高质量和一致的生成能力,无需任何微调
- 右图:ControlVideo 能够基于各种运动序列生成逼真的视频,这些视频在结构和外观上都具有时间一致性。建议以 500% 缩放查看最佳效果。
1.3 现有方法的局限性
- 现有方法: 与独立合成所有帧不同,现有方法通过用更稀疏的跨帧注意力替换原始自注意力,增强了外观一致性。然而,它们的视频质量仍然远未达到逼真视频的水平,仍存在以下问题:
- 部分帧之间外观不一致。
- 大运动视频中可见伪影。
- 帧间过渡时的结构闪烁。
- 原因:
- 稀疏跨帧机制增加了自注意力模块中查询和键的差异,进而阻碍了从预训练文本到图像模型中继承高质量和一致的生成。
- 预训练的文本到图像模型通常依赖于全局信息来生成高质量和一致的结果。稀疏跨帧机制限制了全局信息的利用,从而阻碍了从预训练模型中继承高质量和一致的生成能力
- 输入运动序列仅提供视频的粗略结构,无法实现帧间的平滑过渡。
- 稀疏跨帧机制增加了自注意力模块中查询和键的差异,进而阻碍了从预训练文本到图像模型中继承高质量和一致的生成。
1.4 ControlVideo的提出
-
核心设计:
-
全跨帧交互:
- 将所有帧拼接为“更大的图像”,直接从 ControlNet 继承高质量和一致的生成。
-
交错帧平滑器: 通过在选定的时间步长进行交错插值,减少整个视频的结构闪烁。
-
选择交错的三帧片段(例如第1帧、第3帧、第5帧)。
-
对中间帧(例如第2帧、第4帧)进行插值,生成平滑的过渡帧。
-
通过这种方式,减少三帧片段之间的闪烁效应。
-
由于平滑操作仅在少数时间步中执行,插值帧的质量和独特性可以通过后续的去噪步骤得到很好的保留
-
-
分层采样器: 将长视频分解为多个短片段,分别生成并保持整体一致性。
- 首先将长视频分割为多个短视频片段,并选择关键帧。
- 然后,使用全跨帧注意力预生成关键帧,以确保长距离一致性。
- 基于成对的关键帧,我们按顺序合成其对应的中间短视频片段,并保持全局一致性。
-
-
高效性:
- 使用 xFormers 实现和分层采样器,可在几分钟内生成短视频和长视频(使用一块 NVIDIA 2080Ti)。
2. 背景
2.1 Latent Diffusion Model
-
LDM 是扩散模型的高效变体,通过在潜在空间(而非图像空间)进行扩散过程来提升效率。
-
潜在空间是指高维数据(如图像、音频、文本等)经过编码后得到的低维表示空间。
- 在这个空间中,数据的复杂结构被压缩为更紧凑的表示形式,同时保留了数据的关键特征
-
包含两个主要组件:
- 编码器(Encoder):将图像压缩为潜在代码 z=E(x)
- 解码器(Decoder):从潜在代码重建图像 x≈D(z)**
-
在DDPM的框架下,学习图像潜在代码 z 0 z_0 z0∼ p d a t a p_{data} pdata( z 0 z_0 z0) 的分布
- 图像潜在代码
z
0
z_0
z0:
- z 0 z_0 z0是图像在潜在空间中的表示,通常通过编码器将图像压缩为低维潜在代码。
- **学习分布
p
d
a
t
a
p_{data}
pdata(
z
0
z_0
z0) **:
- 模型的目标是学习潜在代码 的 z 0 z_0 z0真实数据分布,从而能够在潜在空间中生成符合真实数据分布的样本。
- 避免生成结果过于单一或重复
- 图像潜在代码
z
0
z_0
z0:
-
DDPM框架
-
forward process:在每个时间步 t(也就是第t步) 逐步添加高斯噪声,得到 zt
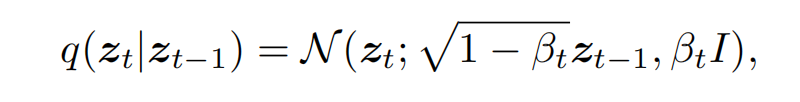
- 其中,$ {\beta_t}_{t=1}^T$是噪声的缩放系数,T 表示扩散过程的时间步数
-
backward process:通过去噪模型 ϵθ 预测噪声,逐步恢复潜在代码
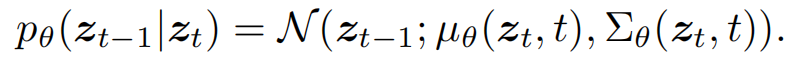
- 根据学习到的分布来预测 Z t − 1 Z_{t-1} Zt−1
- μ θ μ_θ μθ 和 Σ θ Σ_θ Σθ 通过一个具有可学习参数 θ 的去噪模型 ϵ θ ϵ_θ ϵθ 来实现,该模型通过以下简单的目标函数进行训练

-
-
生成新样本
- 从 z T z_T zT ∼N(0,1) 开始,逐步预测 z t − 1 z_{t-1} zt−1。
- 使用去噪模型 ϵ θ ϵ_θ ϵθ 和 DDIM 采样方法生成潜在代码。
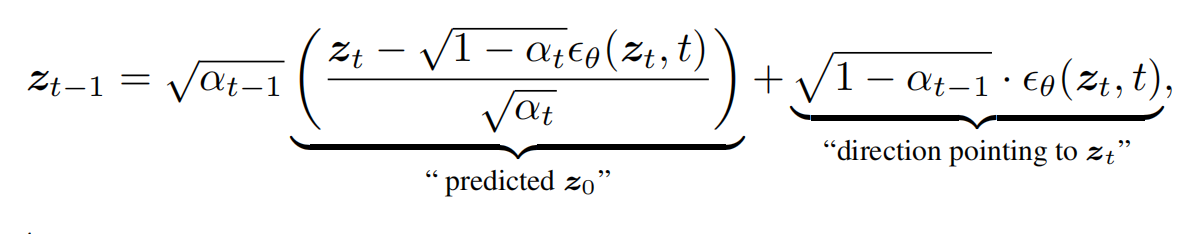
- 其中, α t = ∏ i = 1 t ( 1 − β i ) \alpha_t = \prod_{i=1}^t (1 - \beta_i) αt=∏i=1t(1−βi)。
- 为了简化,我们用
z
t
→
0
z_{t \to 0}
zt→0 表示时间步
t
t
t 的“predicted
z
0
z_0
z0”
- “predicted z0” 表示从当前噪声数据 zt 预测的原始数据 z0,基于预测的 z0,逐步去除噪声,恢复数据
- “direction pointing to zt” 表示从预测的 z0 指向当前噪声数据 zt 的方向,用于保留一定的噪声信息,确保生成结果的多样性和平滑性
- 需要注意的是,我们使用 Stable Diffusion (SD) 的 ϵ θ ( z t , t , τ ) \epsilon_\theta(z_t, t, \tau) ϵθ(zt,t,τ) 作为基础模型,它是基于数十亿图像-文本对预训练的文本引导潜在扩散模型(LDM)的一个实例。 τ \tau τ 表示文本提示。
- 最后根据预测的 z 0 z_0 z0,放入decoder中
-
2.2 ControlNet
-
扩展 Stable Diffusion (SD) 的能力:
ControlNet 使 SD 能够在文本到图像生成过程中支持更多的可控输入条件。 -
支持的输入条件:
例如深度图(depth maps)、姿态(poses)、边缘(edges)等。 -
ControlNet 的架构
-
与 SD 相同的 U-Net 架构:ControlNet 使用了与 SD 相同的 U-Net架构。
-
微调权重:通过微调 U-Net 的权重,ControlNet 能够支持任务特定的条件。
-
-
条件扩展
- 去噪模型的扩展:将 SD 的去噪模型
ϵ
θ
ϵ_θ
ϵθ(
z
t
z_t
zt,t,τ) 扩展为
ϵ
θ
ϵ_θ
ϵθ(
z
t
z_t
zt,t,c,τ)
- 参数说明:
- z t z_t zt:当前时间步的噪声数据。
- t:时间步。
- τ:文本提示。
- c:额外的输入条件(如深度图、姿态、边缘等)。
- 参数说明:
- 去噪模型的扩展:将 SD 的去噪模型
ϵ
θ
ϵ_θ
ϵθ(
z
t
z_t
zt,t,τ) 扩展为
ϵ
θ
ϵ_θ
ϵθ(
z
t
z_t
zt,t,c,τ)
-
主 U-Net 与辅助 U-Net
-
主 U-Net:SD 的原始 U-Net,负责文本到图像生成。
-
辅助 U-Net:ControlNet 的 U-Net,负责处理额外的输入条件。
-
3. ControlVideo
-
目标
- 生成视频:目标是生成长度为 N 的视频。
- 条件信息:
- 运动序列:$ c= {{c_i}}_{i=0}^{N−1} $ 。
- 文本提示:τ。
-
技术:
-
改编自ControlNet
-
完全跨帧交互:确保外观一致性,减少质量下降。
-
交错帧平滑器:减少视频闪烁,提升连贯性。
-
层次采样器:实现长视频合成,保持整体一致性。
-
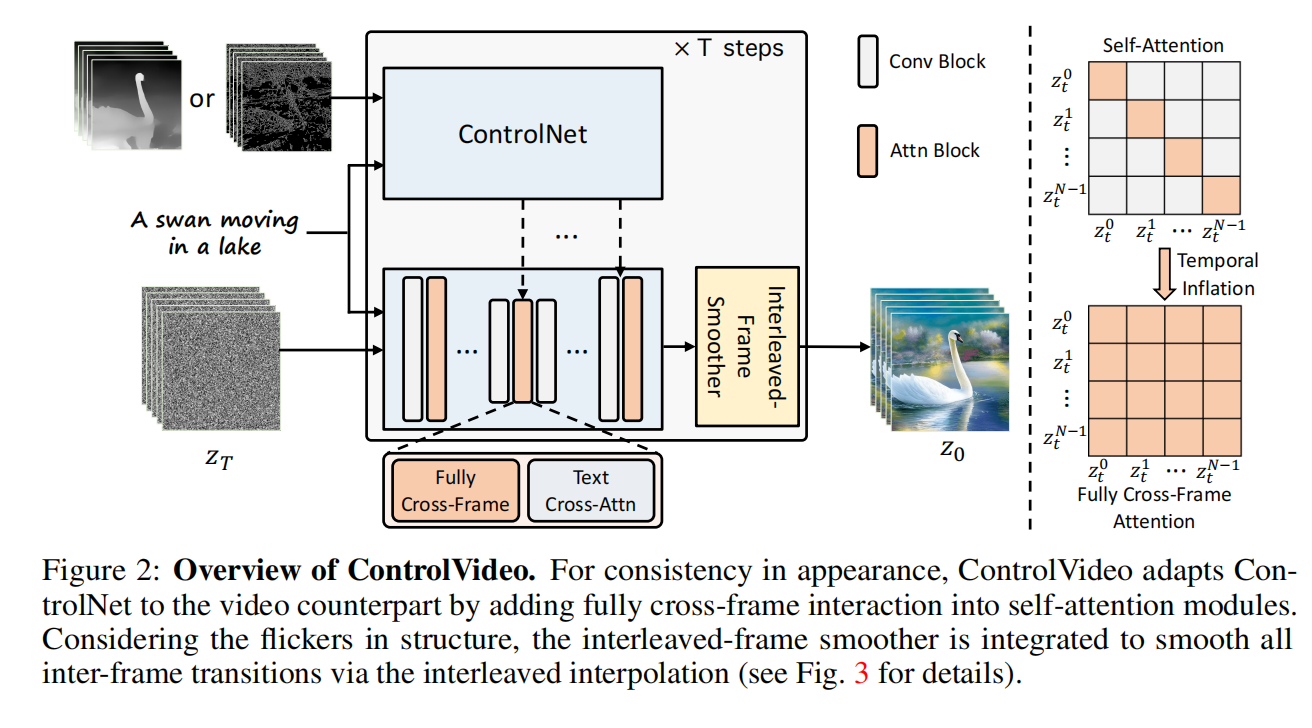
3.1 完全跨帧交互
- 目标:确保视频帧之间的时间一致性,避免生成过程中出现外观不一致的问题。
- 挑战:直接将文本到图像模型(如 ControlNet)应用于视频生成,会导致帧之间出现显著的外观不一致
- 解决方案:将所有视频帧连接成一个“大图像”,通过跨帧交互共享帧之间的内容。
3.1.1 技术实现
一、架构调整
- 主 U-Net:将 Stable Diffusion 的主 U-Net 沿时间轴扩展,使其支持视频生成。
- 辅助 U-Net:保留 ControlNet 的辅助 U-Net,用于处理额外的控制条件。
- 卷积层转换:将 2D 卷积层转换为 3D 卷积层,例如将 3x3 卷积核替换为 1x3x3 卷积核。
- 三维卷积:https://blog.csdn.net/YOULANSHENGMENG/article/details/121328554
二、注意力机制扩展
-
自注意力机制:扩展自注意力机制,增加跨帧交互,使所有帧之间能够相互关注–全局交叉帧注意力机制
-
公式
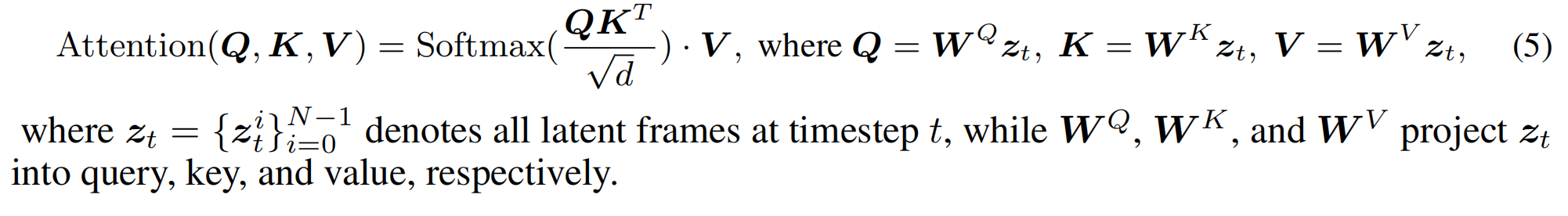
- $ z_t= {{z_i}}_{i=0}^{N−1} $表示在第t步的时的视频—包括了所有帧的潜在帧
- W Q W^Q WQ、 W K W^K WK、 W V W^V WV是可学习的权重矩阵
- 将$ z_t$通过上述三个矩阵投影成Q、K、V
三、交错帧平滑器
-
问题背景
-
完全跨帧交互的局限性:
尽管通过完全跨帧交互生成的视频在外观一致性上表现良好,但在结构上仍然存在明显的闪烁效应。 -
原因:
输入的运动序列仅能确保视频在粗粒度结构上的一致性,但不足以保持帧与帧之间的平滑过渡。
-

-
交错帧平滑器的原理
-
核心思想:
通过插值中间帧来平滑每三个帧的片段,从而减少视频中的结构闪烁。 -
具体操作:
- 选择帧片段: 在每个时间步长选择三个帧的片段(如 i−1, i , i+1)。
- 插值中间帧: 对中间帧(如第 i 帧)进行插值,生成平滑的过渡帧。
- 组合平滑片段: 将两个连续时间步长的平滑片段重叠在一起,减少整个视频的结构闪烁–连续两个时间步长后,所有帧都smooth了
-
实现
-
时间步长的操作:在每个时间步长 t,对预测的 RGB 帧进行平滑操作。
-
公式:在应用交错帧平滑器之前,首先根据$ z_t$ 预测干净的视频潜在变量 z t → 0 z_{t→0} zt→0:
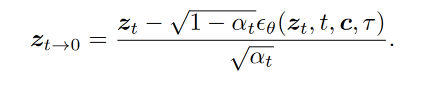
- z t z_t zt:当前时间步的噪声数据。
- ϵ θ ϵ_θ ϵθ( z t z_t zt,t,c,τ):去噪模型预测的噪声。
- α t α_t αt:噪声缩放系数。
-
投影为RGB视频:
- 将 z t → 0 z_{t→0} zt→0投影到RGB空间,得到对应的视频帧 $ x_{t→0} = D(z_{t→0}) $
-
使用交错帧平滑器:
- 使用交错帧平滑器将 RGB 视频 $ x_{t→0}$转换为更平滑的视频 $ \tilde{x}_{t→0}$
-
DDIM去噪:
- 用平滑后的$ \tilde{x}{t→0} 转换为潜在变量 转换为潜在变量 转换为潜在变量 \tilde{z}{t→0} ,再按照 D D I M 去噪公式计算 ,再按照DDIM去噪公式计算 ,再按照DDIM去噪公式计算 z_{t-1}$
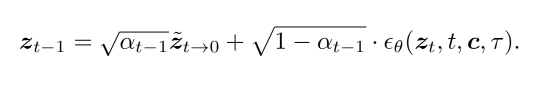
-
-
中间时间步长的选择
- 操作:
上述过程仅在选定的中间时间步长执行。 - 优点:
- 计算负担小:新增的计算负担可以忽略不计。
- 保留插值帧的质量:插值帧的独特性和质量通过后续的去噪步骤得到了很好的保留
- 操作:
-
四、分层采样器
-
目标
- 问题:
视频扩散模型需要保持帧间的时间一致性,通常需要大量的 GPU 内存和计算资源,尤其是在生成长视频时。 - 解决方案:
引入分层采样器,通过分片段生成的方式高效合成长视频。
- 问题:
-
具体实现方法
-
分割长视频:将长视频 z t = { z t i } i = 0 N − 1 z_t = {\{z^i_t}\}_{i=0}^{N-1} zt={zti}i=0N−1 分割成多个短视频片段。
- 选择关键帧 z t k e y = { z t k N c } k = 0 N N c z_t^{key} = {\{z^{kN_c}_t}\}_{k=0}^{\frac{N}{N_c}} ztkey={ztkNc}k=0NcN ,并通过全局交叉帧注意力预生成关键帧,确保长期一致性。
- 每段长为 N c − 1 N_c-1 Nc−1
- 第k个片段用 z ~ t = { z t i } j = k N c + 1 ( k + 1 ) N c − 1 \tilde{z}_t = {\{z_t^i}\}_{j=kN_c+1}^{(k+1)N_c-1} z~t={zti}j=kNc+1(k+1)Nc−1
-
预生成关键帧
- 全局交叉帧注意力:通过全局交叉帧注意力预生成关键帧,确保长期一致性。
- 关键帧矩阵的Q、K、V计算方式如下
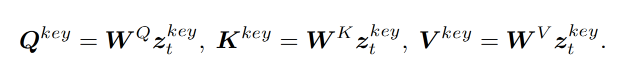
-
合成对应短视频片段
- 基于关键帧合成片段:基于每对关键帧,顺序合成对应的短视频片段,保持整体一致性。

-
4. 实验
-
重点总结
-
实验设置:ControlVideo 基于 ControlNet 实现,采用 DDIM 采样和交错帧平滑器,生成短视频和长视频的时间分别为 2 分钟和 10 分钟。
-
数据集:从 DAVIS 数据集中收集视频,使用 ChatGPT 生成编辑提示,形成 125 个视频-提示对作为评估数据集。
-
评估指标:使用帧一致性和提示一致性评估视频的时间一致性和语义一致性。
-
基线方法:与 Tune-A-Video、Text2Video-Zero 和 Follow-Your-Pose 进行对比。
-
实验结果:ControlVideo 在外观一致性、结构一致性和处理大运动输入方面均优于基线方法。
-
-
消融实验
为了验证完全跨帧交互的有效性,作者对比了以下四种机制:
- Individual(无交互):
- 所有帧之间没有交互。
- 结果:出现严重的时间不一致问题,例如彩色帧和黑白帧交替出现。
- First-only(仅第一帧交互):
- 所有帧仅与第一帧交互。
- 结果:减少了部分外观不一致问题,但仍存在结构不一致和可见伪影。
- Sparse-causal(稀疏因果交互):
- 每帧与第一帧及前一帧交互。
- 结果:与 First-only 类似,仍存在结构不一致和伪影问题。
- Fully(完全跨帧交互):
- 所有帧之间完全交互。
- 结果:外观一致性和视频质量最佳,尽管带来了额外的 1∼2 倍时间成本,但对高质量视频生成是可接受的
- Individual(无交互):

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 42
42 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)