合合信息大模型加速器2.0:知识库智能化与文档图表解析能力实测
大模型AI在处理专业文档时常因"AI幻觉"引发争议。核心问题在于训练数据集质量。合合信息推出的大模型加速器2.0版本优化了文档处理能力,通过精准解析复杂文档和强大图表逆向还原能力,提供高质量语料。其文档解析技术具有泛化能力和解析精度,图表逆向还原技术能精准识别图表数据。此外,知识库构建和智能交互能力助力大模型输出可靠性提升。此技术路径通过提升信息处理质量增强AI可靠性,标志着AI应用向"可信"转变
合合信息大模型加速器2.0:知识库智能化与文档图表解析能力实测

1. 大模型AI幻觉问题的技术突破
大模型落地应用时常因"AI幻觉"(输出看似合理实则错误的结果)引发争议,特别是在处理医疗报告、法律合同等专业文档时,复杂的排版和图表识别问题容易导致理解偏差。这一问题的核心在于训练数据集的质量——正如人类需要优质教材学习,AI同样依赖精准的结构化信息。当文档中的关键数据(如医疗表格)被错误解析时,模型就会产生错误推理。因此,如何从海量文档中准确提取有效信息,成为解决AI幻觉问题的关键突破口。
近期,合合信息推出的大模型加速器2.0版本,将升级重点放在了文档处理能力的优化上,为模型训练和知识库构建提供“提纯”后的高质量语料。其核心升级功能主要体现在复杂文档的精准解析和专业图表的强大逆向还原能力两方面。
大模型加速器2.0版本基于文档解析技术打造了知识库产品组件,支持PDF、Word、图片等十余种格式秒级处理,通过自动溯源和精准定位文档关键数据,赋能企业及个人开发者快速构建定制化行业知识库,不仅能提供智能问答、多轮对话交互、文档深度摘要等核心功能,助力企业和个人开发者打造专业化AI助手,提升大模型输出的可靠性与行业应用效率。
2. 精准的复杂文档解析能力
**大模型加速器 2.0”版本对于复杂版面的理解、多种表格(含图表)的处理能力均有大幅突破。**例如处理金融财报中的密集表格和段落、国家标准文件中的复杂公式等行业难题,从专业文档中提取知识语料,赋能下游各类大语言模型任务。登录通用文档解析工作台:https://www.textin.com/user/login?redirect=%2F&from=0320xpkx-pr-kol即可体验。
文档解析技术具有极强的泛化能力和优秀的解析精度,能帮助大模型能够按照人类正常的阅读顺序扫描文档结构。如下所示这一页PPT有2个图表,每个图表在其顶部和底部都绑定了对应的信息。从右侧的解析结果可以看到是符合预期的,没有出现顺序杂乱的问题。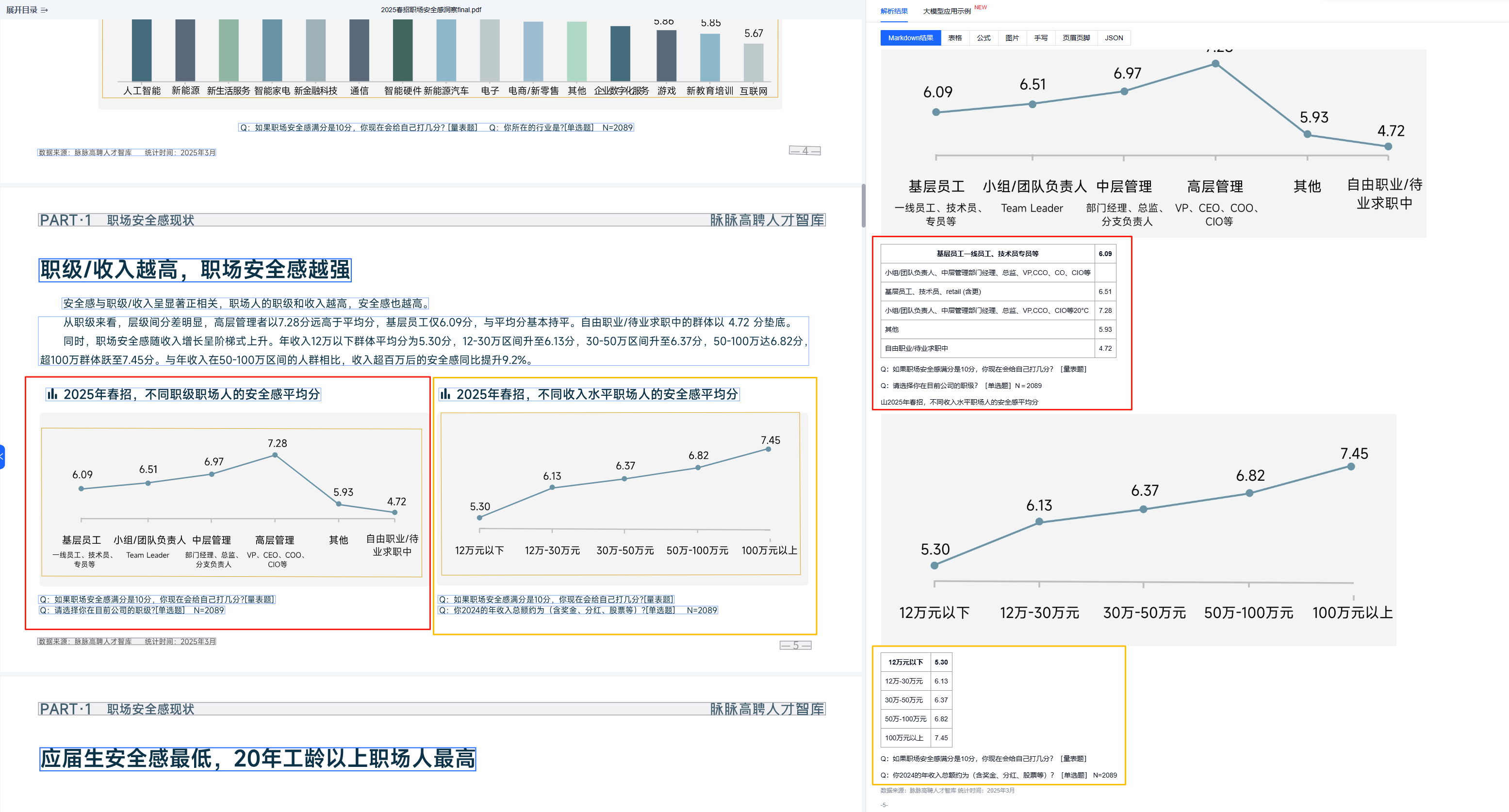
文档解析能力对数学公式、符号等的精准识别和提取也都不在话下。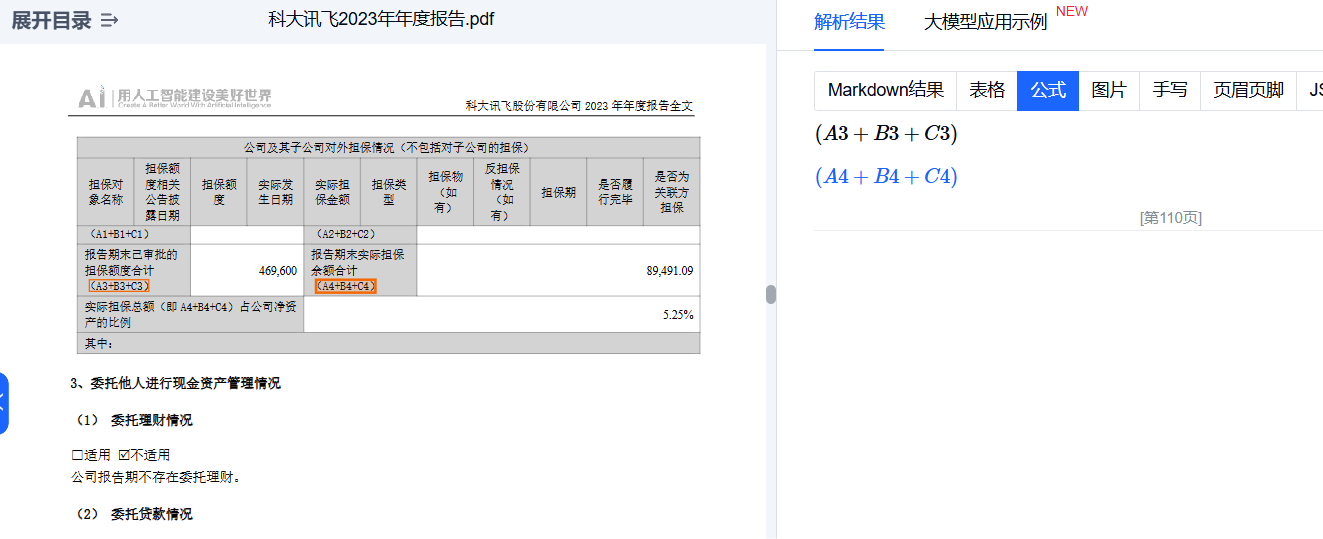
此外,文档解析能力对密集表格和合并单元格的识别解析也非常擅长。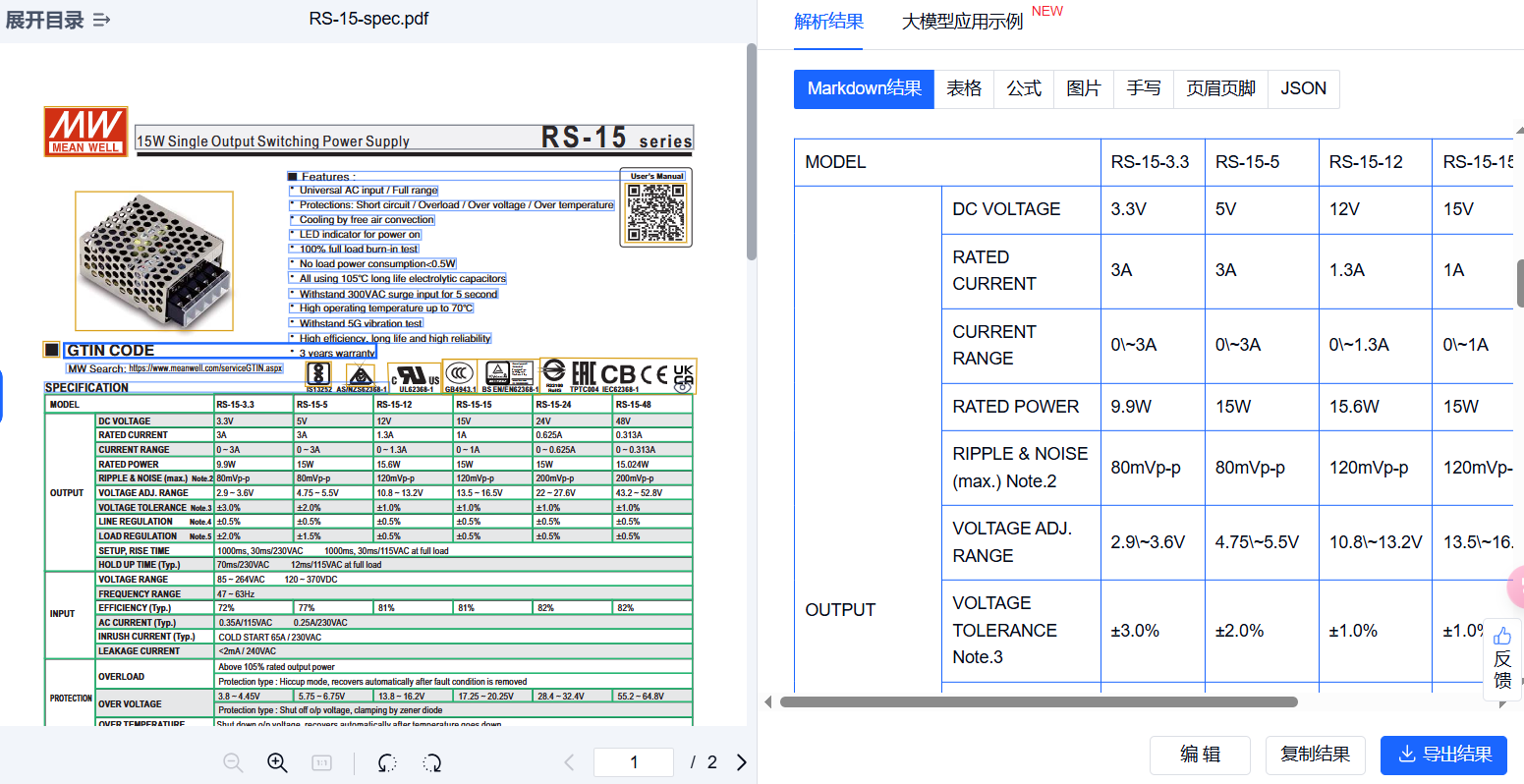
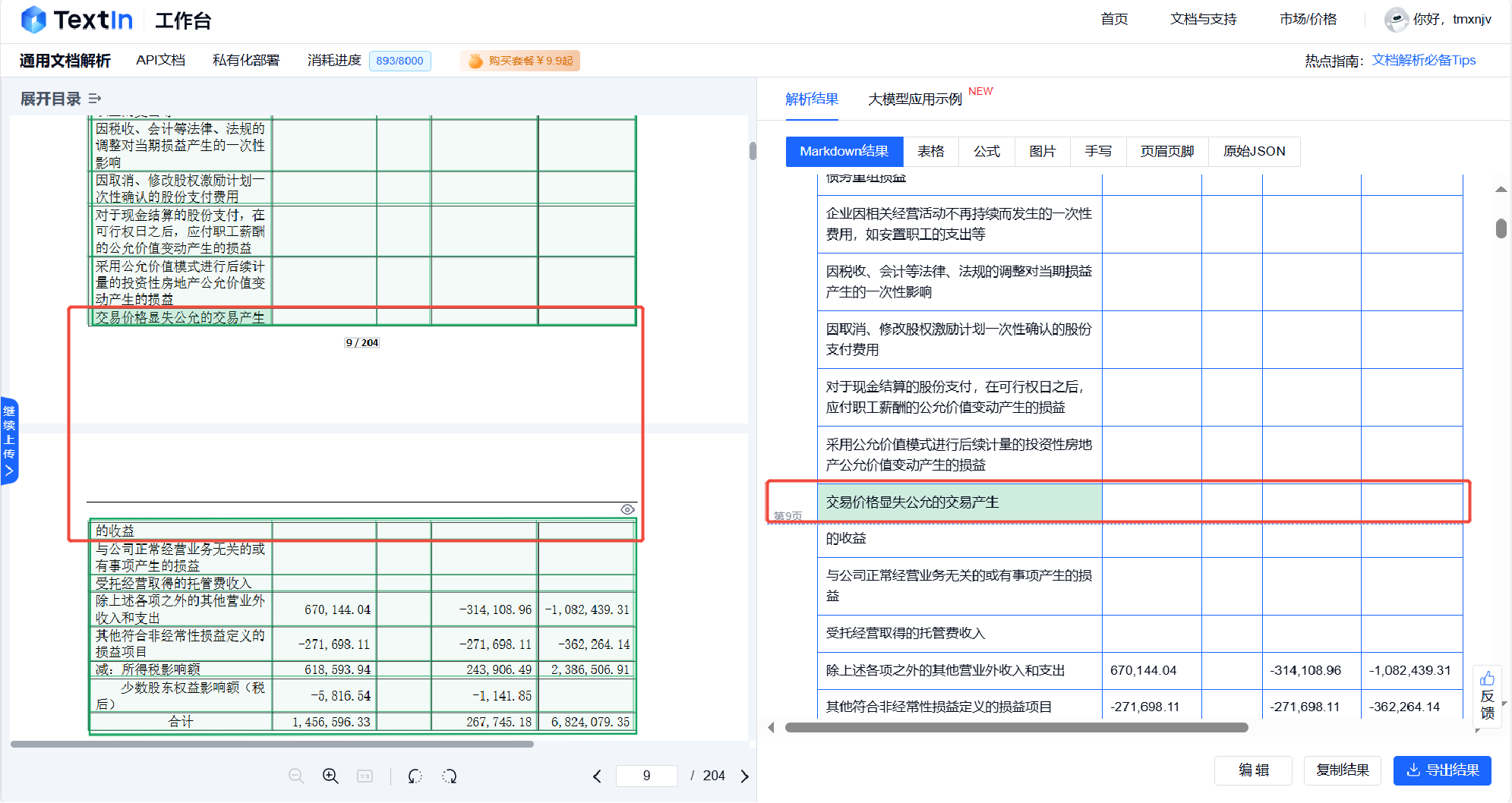
在复杂场景中,文档解析引擎还支持自动合并跨多页表格,帮助大模型理解表头和跨页数据的对应关系,减少AI幻觉的产生。
3. 强大的图表逆向还原能力
在“大模型加速器2.0”版本中,文档解析-图表解析模块优化上新,基于大规模预训练的基座模型,通过生成式学习的方法,对图表的布局、线条、颜色、标记等多维度特征进行深度建模,提取图表中的关键数据点、坐标轴信息、图例说明等,可精准识别柱状图、折线图、饼图等十余种专业图表类型,并转化为大模型能够“读懂”的Markdown格式,助力大模型获取图表数据全貌。此外,解析模块能够将复合式图表如“柱形图+折线图”还原为完整的Excel表格数据,展现其对不同图表类型及数据特性的强大解析能力。在文档解析模块左侧的参数配置中打开图表识别功能并对文件进行重新识别。
4. 知识库构建和智能交互能力
合合信息“大模型加速器2.0”基于智能文档解析技术推出开源组件快速搭建框架,支持企业按需定制行业知识库。无论是上市公司千页年报、学术论文等复杂文档,系统均可实现全自动结构化处理,通过智能标注(如关键指标标红、章节语义关联)将杂乱数据转化为可检索、可分析的数字化知识资产,大幅降低知识库建设门槛与时间成本。知识库提供智能问答、文档摘要与精准检索功能,目前已在金融、教育、医疗等专业领域实现规模化应用。登录https://www.textin.com/user/login?redirect=%2F&from=0320xpkx-pr-kol即可体验。
4.1 千页文档秒级解析
用户可任意上传1000份500M以内的个人文档,支持PDF、Doc、PNG等格式。知识库文档支持多文件夹管理,单个文件夹最多50份资料。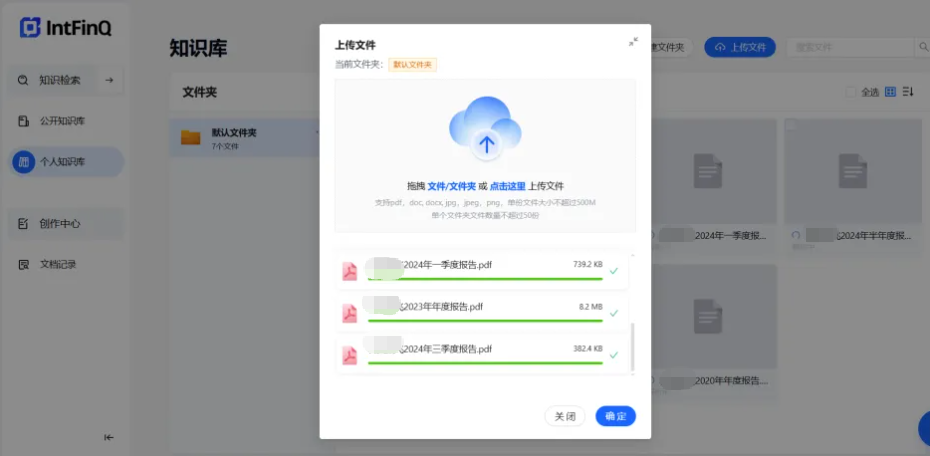
文档上传完之后,知识库只需要几秒钟就可以完成文档的阅读理解。之后就可以针对文档进行提问了。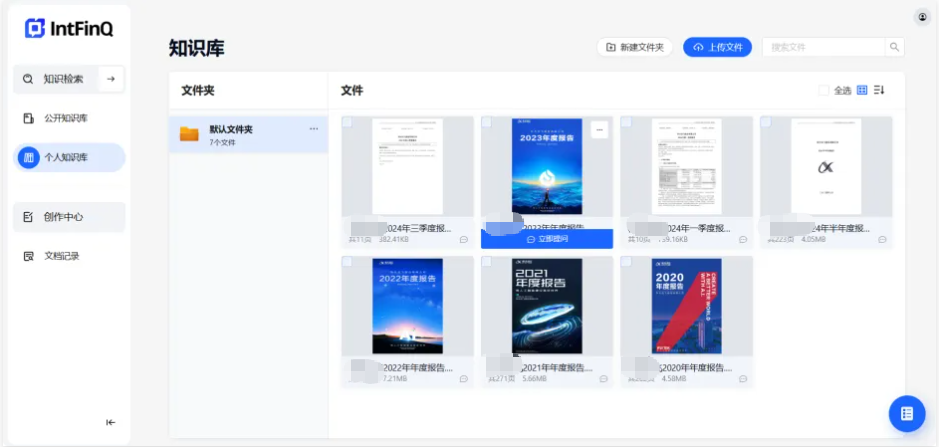
4.2 智能问答与溯源功能
上一节中,我将某公司最近5年的财报上传到了个人知识库,接下来我们进行知识库检索提问。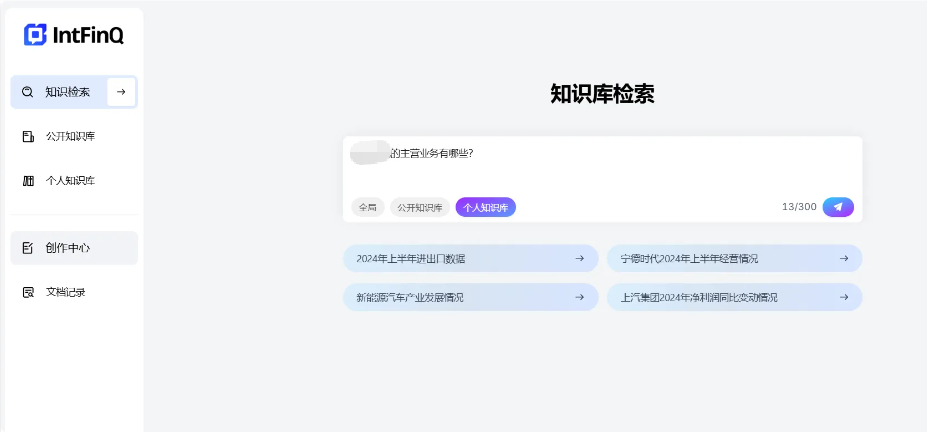
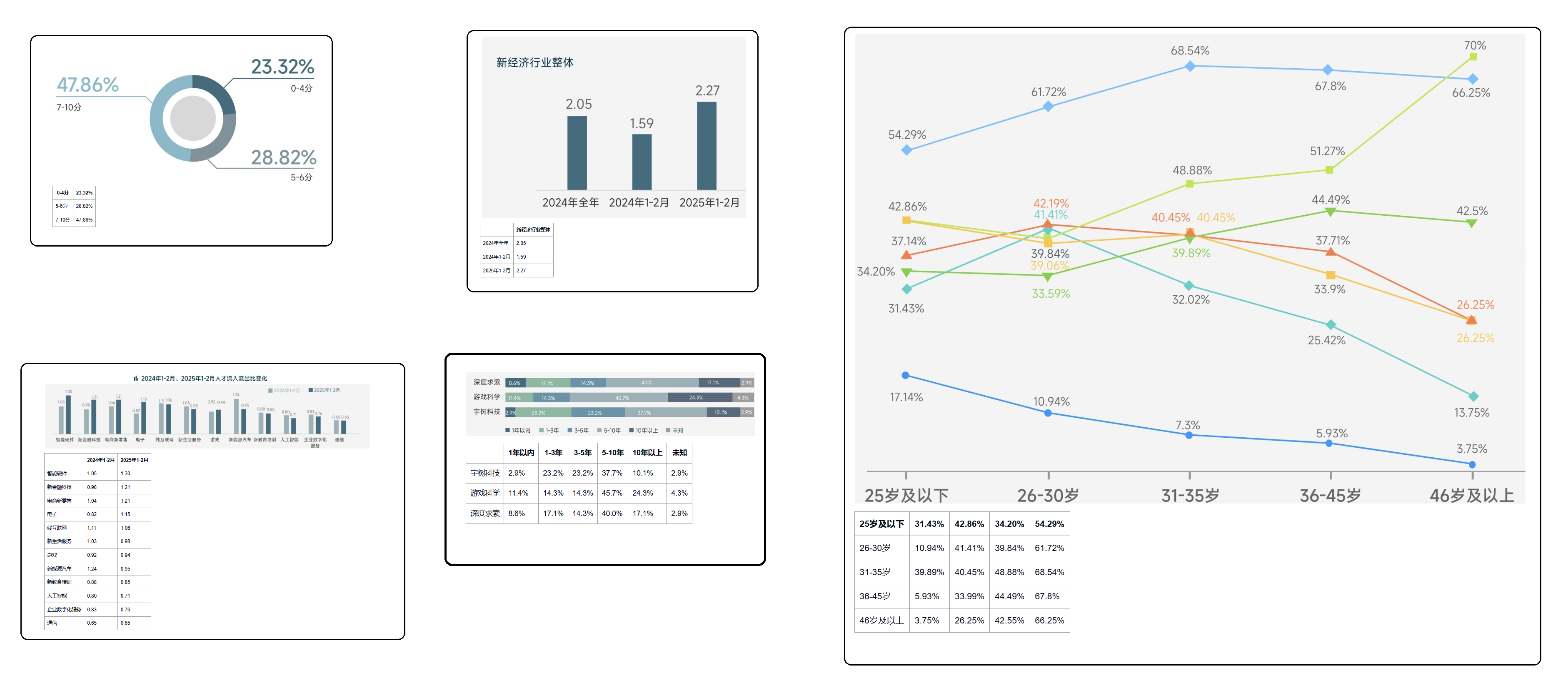
第一个问题:某公司的主营业务有哪些。如下图所示,大模型自动查询知识库,从某公司2023年财报中找到了主营业务信息,并整理回复给了我们。并且每一条信息都有对应的溯源,我们可以核查原文,确保大模型的结果是真正从我们的知识库而来,有据可依,避免大模型”胡说八道“。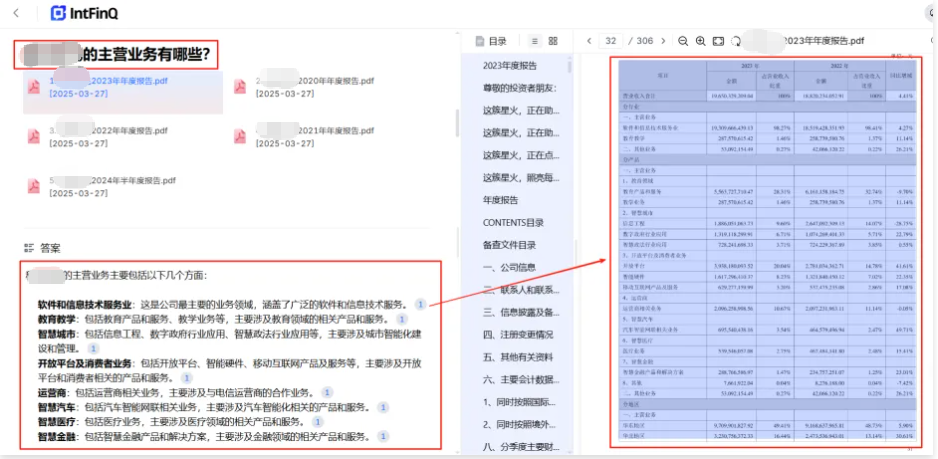
接下来,我们继续问第二个问题:某公司主营产品收入情况。如下图可以看到,知识库横跨了多个文档,对最近5年财报中主营产品营业收入和同比增减等数据所在表格进行了精准溯源,最终汇总整理返回了给了我们。仔细一点,还可以发现智能硬件、汽车智能网联相关业务、医疗业务等几个业务在2020年财报中是没有相关数据的,也就是说这几个业务都是从2021年才开展的新业务,大模型对于这些变化的信息都能很好的识别和理解。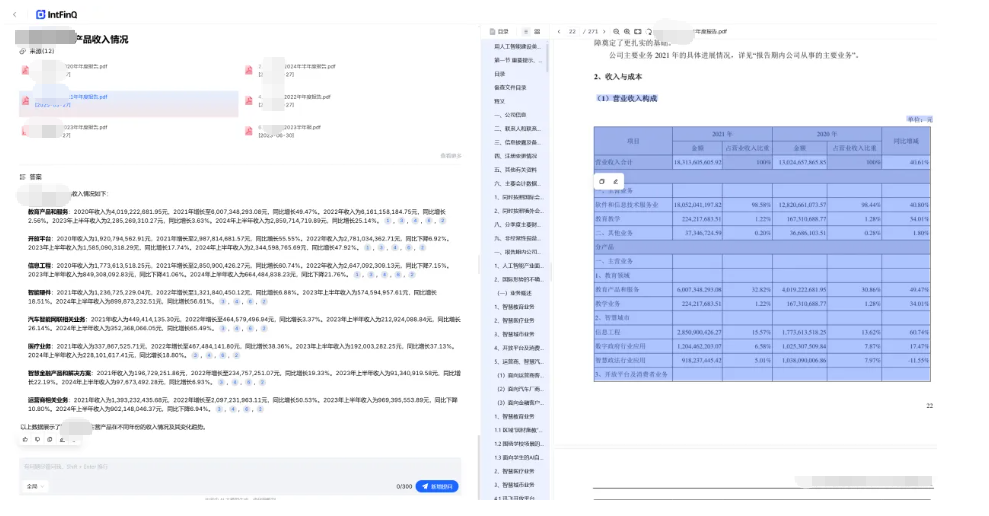
4.3 多维数据分析与对比
在强大的知识检索能力和DeepSeek AI大模型的加持下,知识库支持在同行业多公司间进行横向对比,并结合行业信息将海量数据转化为商业洞察。我向知识库提问:从近三年财务数据看,某公司与公司A、公司B、公司C等AI企业的营收增长率、毛利率、研发费用率有何差异?哪些指标反映其行业地位?。知识库对几家竞对企业的财报进行了分析和横向对比,然后结合DeepSeek大模型的强大推理能力,给出了结论:某公司在AI行业领域的领先地位。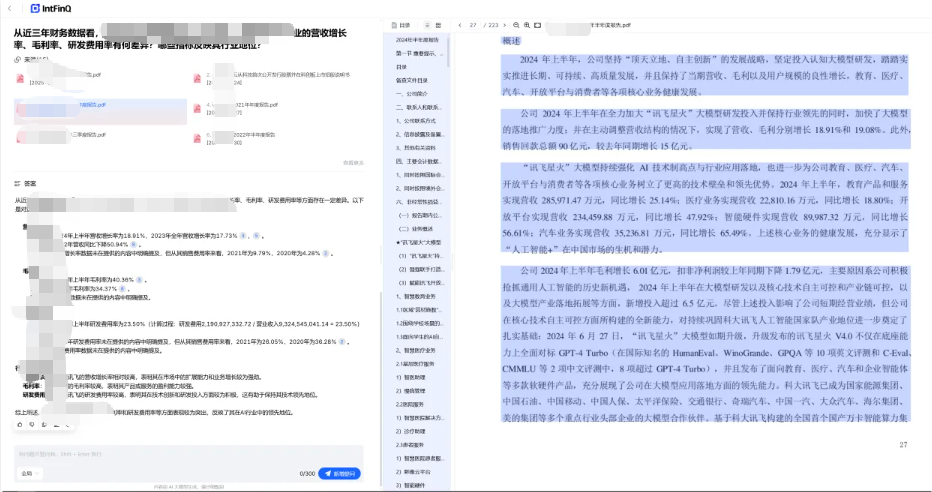
4.4 跨页表格的合并理解
除了文档的智能解析之外,依托大模型加速器2.0强大的图表逆向还原能力,可以为大模型的知识检索和内容理解提供准确的数据支持。如下图所示,大模型很好的识别了原文件中的跨页表格并自动进行合并理解,这就从根源上避免了出现AI幻觉问题。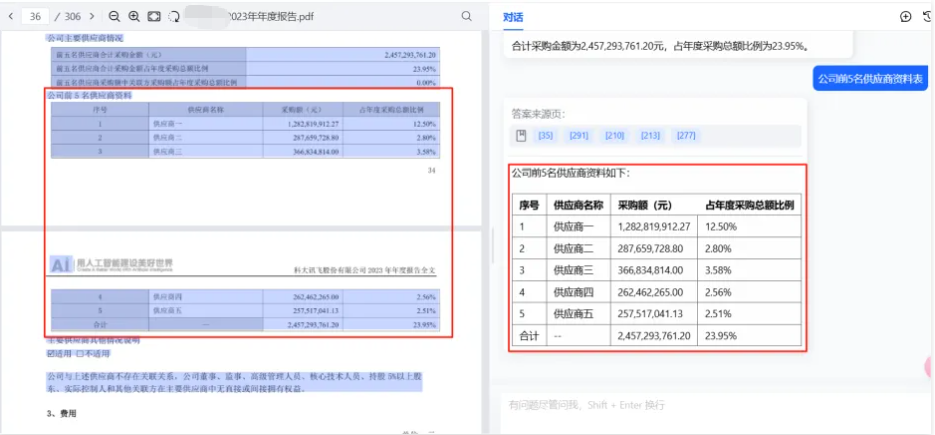
5. 总结
大模型AI幻觉问题的本质在于认知框架的缺陷,而合合信息大模型加速器2.0的创新恰恰击中了这一痛点。它通过三重技术革新构建了AI的"专业认知体系":
- 文档解析技术如同为AI配备了行业专家的"结构化思维",能精准解构财报、合同等专业文档的语义网络。
- 图表逆向还原技术则赋予AI"数据透视能力",可立体提取图表中的多维特征
- 知识库框架则建立了"事实校验机制",通过溯源功能确保输出结果的可验证性。
这种技术路径的价值在于,它没有陷入盲目追求模型规模的窠臼,而是回归AI认知的本质——通过提升信息处理的质量而非数量来增强可靠性。特别是在金融、医疗等专业领域,这种"精准认知"比"海量生成"更具实用价值,标志着AI应用从"能做"到"可信"的重要转变,为行业智能化落地提供了新的技术范式。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐
 49
49 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)