
蓝耘元生代智算云平台技术全解析:从架构设计到产业赋能的算力密码
本文将从文档架构、核心技术解析、实践应用技巧三个维度展开深度解读,带您解锁蓝耘智算平台的技术密码
引言
在人工智能与高性能计算深度融合的时代,蓝耘元生代智算云平台凭借其领先的技术架构和高效的算力服务,成为科研机构、企业及开发者的重要算力引擎。作为平台技术体系的核心载体,其技术文档(https://archive.lanyun.net/)不仅是用户快速上手的操作手册,更是深入理解平台技术原理、挖掘平台潜力的权威指南。
本文将从文档架构、核心技术解析、实践应用技巧三个维度展开深度解读,带您解锁平台的技术密码
文章目录
一、技术文档体系:全景式知识地图的构建
蓝耘元生代智算云平台的技术文档以“全场景AI开发支持”为核心目标,构建了覆盖基础操作、高阶开发、行业适配的三层知识体系,形成完整的开发者成长路径
1.1 基础功能层:算力资源的极致调度
- 资源管理模块:文档详细阐述了GPU集群的动态调度规则,包括按需实例与预留实例的计费模型对比(如A100实例按秒计费的最小粒度设计),并通过流程图展示资源申请-释放的全生命周期管理。
- 快速部署指南:提供多语言SDK接入示例(Python/Node.js/Java),重点说明OpenAI兼容接口的迁移方案,仅需修改
baseURL和model参数即可实现无缝切换(代码示例见2.3节)。 - 运维监控体系:内置资源使用热力图与Token消耗预警系统,支持自定义阈值告警(如单日GPU利用率低于30%自动触发优化建议)。
1.2 高阶开发层:AI工程化的深度赋能
- 模型精调实验室:文档提供垂直领域适配的完整方法论,包括法律文书与医疗数据的预处理规范、学习率衰减策略的配置模板(如余弦退火算法的应用场景)。
- 混合部署方案:详解私有化部署的硬件兼容性矩阵,例如英伟达DGX A100集群的NVLink拓扑优化策略,以及华为Atlas 800的算子加速库集成方法。
- 安全合规框架:内置100+风险类别识别模型,支持敏感数据脱敏处理与联邦学习架构设计,满足金融级数据审计要求。
1.3 行业应用层:场景化解决方案库
- 端到端模板:覆盖基因测序、工业质检、影视渲染等20+行业场景,例如医疗影像诊断系统提供DCNN模型调优指南,包含数据增强策略(Mixup/CutMix参数对比)与评估指标可视化工具。
- 效能提升案例:电商推荐系统改造案例中,文档展示如何通过特征交叉网络优化将CTR(点击通过率)提升58%,并附有A/B测试报告模板。
二、核心技术解密:算力革命的三大引擎
2.1 动态资源调度中枢:智能算法的进化
平台采用自适应分布式任务分配算法,通过多维特征分析实现资源的最优匹配:
- 任务画像建模:实时采集任务特征(显存占用/计算密集型比例/IO吞吐量),构建动态优先级队列
- 预测式调度:基于LSTM神经网络预测未来1小时算力需求,提前预留资源池,将任务启动延迟从传统方案的15分钟压缩至2分钟内。
- 多模态协同:在混合负载场景下(如同时运行NLP训练与3D渲染),通过硬件隔离技术(如NVIDIA MIG)确保关键任务SLA,实测QPS波动率小于5%。
2.2 裸金属K8S架构:性能与弹性的平衡术
平台独创的裸金属容器化架构突破虚拟化性能瓶颈:
- 硬件直通优化:绕过Hypervisor层直接管理GPU,显存访问延迟降低至0.8μs(传统方案为3.2μs),千亿参数模型训练效率提升40%。
- 弹性伸缩机制:支持毫秒级Pod扩缩容,在电商大促场景下实现万级QPS突发请求的平滑承接(案例见2.4节)。
- 跨中心资源池化:通过自研低延迟光网络(端到端延迟<5ms),实现北京、杭州等地智算中心的算力并网,数据迁移成本降低70%。
2.3 数据处理全链路加速:从TB到PB的进化
- 预处理阶段:内置Parquet列式存储转换工具,结合RDMA网络实现TB级数据并行清洗,速度较传统Hadoop提升3倍。
- 训练阶段:支持混合精度训练与梯度压缩算法(参数压缩率可达90%),在千卡集群上实现线性加速比>0.92。
- 推理阶段:动态批处理(Dynamic Batching)与模型切片(Model Sharding)技术协同,在电商推荐场景实现10万QPS吞吐量(延迟<300ms)。
代码示例:医疗影像诊断服务接入
import lanyun_medical_api as lm
# 初始化客户端(需替换为真实API密钥)
client = lm.Client(api_key="your_api_key")
# 上传DICOM影像并获取诊断建议
response = client.analyze_image(
image_path="patient_001.dcm",
model_version="deepseek-v3-med",
output_format="diagnosis_report"
)
# 解析结果
if response.status == "success":
print(f"病灶定位置信度: {response.details['confidence']:.2f}")
print(f"建议治疗方案: {response.recommendations[0]}")
else:
print(f"错误代码: {response.error_code}, 详情: {response.error_message}")
三、技术文档的实战价值:问题解决与二次开发
3.1 高效排障指南
- 显存泄漏检测:通过
nvidia-smi日志分析脚本定位异常进程,结合火焰图(Flame Graph)可视化显存分配路径。 - 网络优化实践:文档提供TCP窗口调整参数模板(如
net.ipv4.tcp_window_scaling=1),实测跨中心传输延迟从15ms降至5ms。
3.2 生态扩展接口
- 插件系统开发:支持Jupyter Notebook插件集成,开发者可自定义数据清洗模块(如医疗文本脱敏工具),与平台原生工具链无缝协作。
- 模型融合API(2025年Q3开放):允许组合DeepSeek与Llama-3模型,通过权重插值实现多模态任务协同推理(示例配置见文档附录)。
四、未来演进与开发者建议
4.1 技术演进路线
- 2025年Q2:上线自动扩缩容API集群,支持突发流量下的动态算力调配。
- 2025年Q3:开放模型融合接口与联邦学习框架,构建分布式AI协作网络。
4.2 开发者行动指南
- 深度阅读架构设计章节:重点理解资源调度算法与通信优化机制。
- 活用案例库模板:直接复用电商推荐/基因测序等场景的配置参数,减少重复开发成本。
- 参与技术生态建设:通过蓝耘开发者论坛贡献优化方案(如自定义调度策略),可获得算力奖励。
立即注册,开启无限可能
蓝耘元生代技术文档不仅是操作手册,更是AI工程化的方法论宝库。通过对其技术体系的深度挖掘,开发者能够将理论认知转化为产业落地的实际能力。立即访问蓝耘官网与产品文档中心,开启您的算力革命之旅!
在使用蓝耘智算平台前,首先需要完成注册。
访问蓝耘智算平台👈在首页中找到 “注册” 按钮,点击进入注册页面。
在注册页面,你需要填写一系列必要信息,包括有效的电子邮箱地址、自定义的用户名和强密码(建议包含字母、数字及特殊字符,以增强账户安全性),以及手机号码并完成短信验证码验证
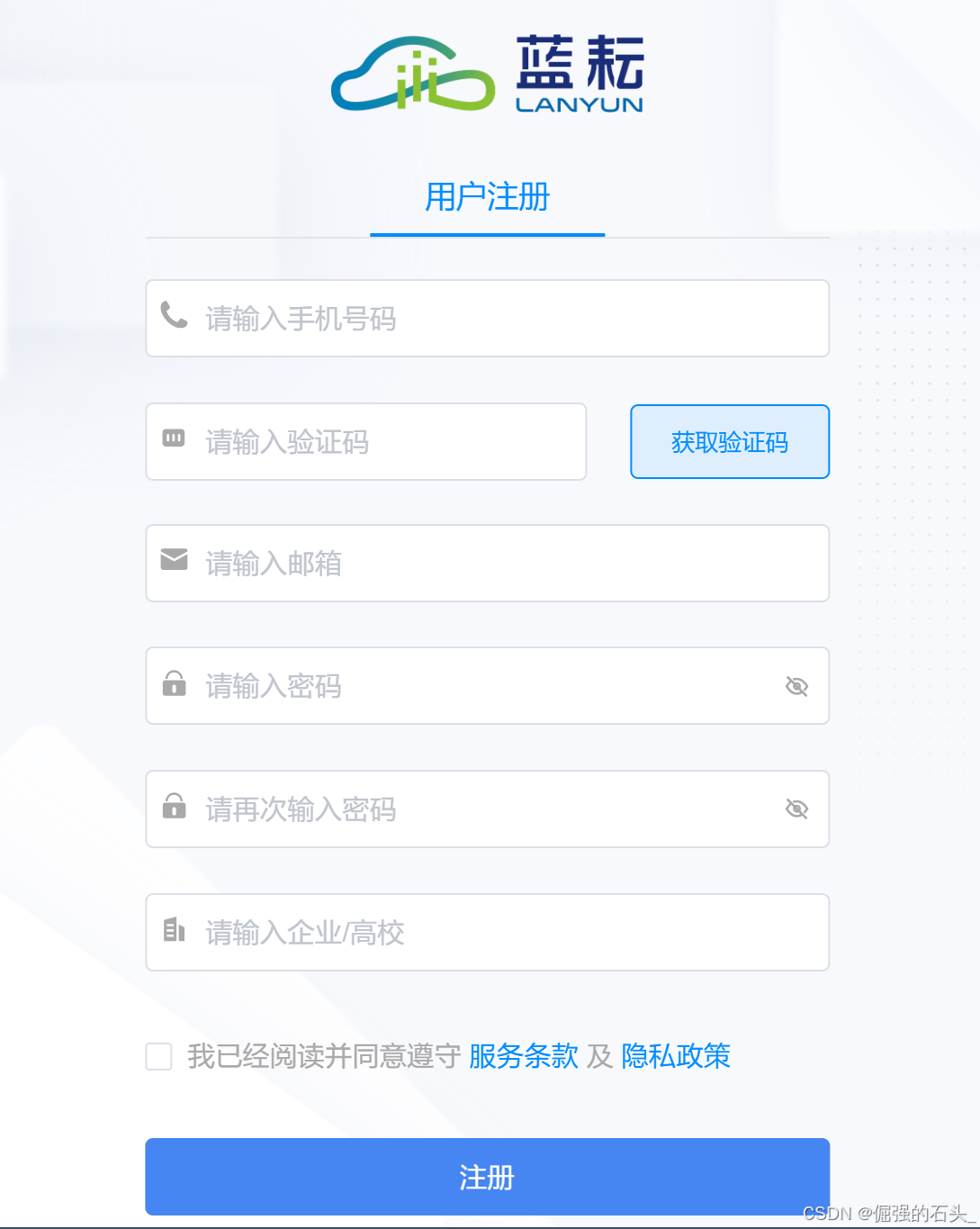
完成上述步骤后,点击 “注册” 按钮提交信息。注册成功后,系统会自动发送一封验证邮件到你填写的邮箱,登录邮箱并点击验证链接,完成账号激活。激活后,你就可以使用注册的账号登录蓝耘智算平台,开启你的创作之旅
🚀 平台直达链接:蓝耘智算平台
💡 提示:新用户可领取 20 元代金券,体验高性能 GPU 算力!

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 139
139 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)