【论文阅读(四)】Q-Instruct: Improving Low-level Visual Abilities for Multi-modality Foundation Models
为了收集对人类低级视觉方面感知的更丰富、更细致的理解,Q-Pathway选择收集一种新的注释格式,称为pathway反馈,对低级视觉属性(如噪声、亮度、清晰度)进行详尽的自然语言描述,然后得出一般结论。格式如下:(1)首先,这些描述可以更完整、更准确地保留人类的感知。例如,如果图像既有暗区也有亮区,如图3(a)所示,亮度分数可能无法正确记录这种情况:位置上下文无法保留,而且将其分数标记为“暗”或“
Q-Instruct: Improving Low-level Visual Abilities for Multi-modality Foundation Models
S-Lab for Advanced Intelligence;Nanyang Technological University;Shanghai Jiao Tong University CVPR 2024
概述:1. 构建Q-Pathway数据集: 人工对图像的low-eve|视觉属性(例如噪声、亮度、清晰度)进行详尽的自然语言描述。包含18973图像、58K标注数据(39名受试者); 2. 构建Q-Instruct数据集: 由GPT根据Q-Pathway构建200K的指令问答对; 3.采用mixed或after的方式对MLLMs进行指令调优。
一、动机
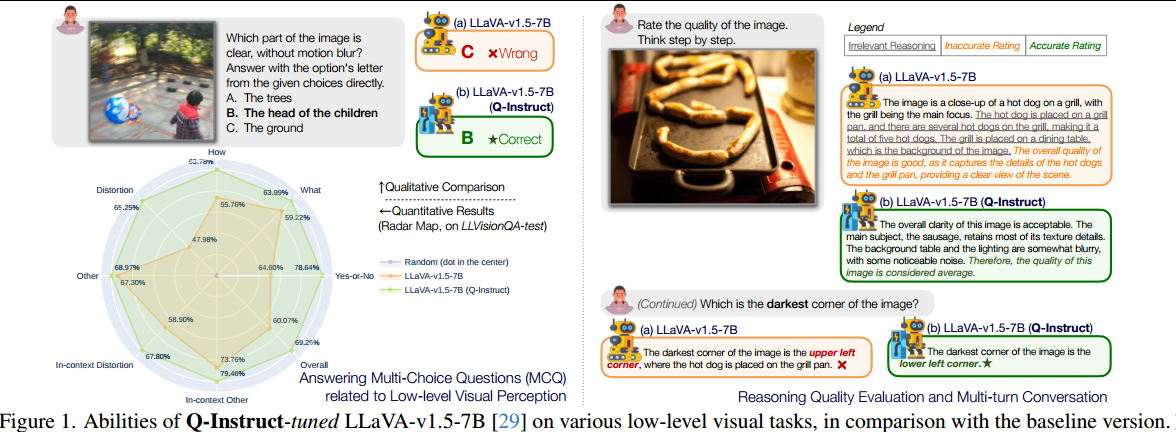
不同任务中相关的人类认知是高度关联的,作者渴望有一个统一的基础模型来建立这些任务的通用能力,使得模型可以对低级视觉方面的开放式人类查询做出稳健的响应。
然而,尽管现有的MLLM基本上可以回答有关低级视觉方面的人类查询,但其响应的准确性仍然不令人满意(图1(a))。主要问题是在训练MLLM期间缺乏低级视觉(图像外观的所有方面,可以被人类感知并唤起不同的人类感受)数据集,其中公开可用的数据集通常只关注高级视觉能力。

为此,作者通过以下两个步骤构建了Q-Instruct,这是第一个大规模的低级视觉指令调优数据集:
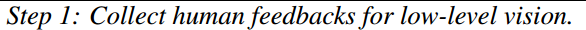
邀请人类受试者就他们对各种图像的低级感知和理解提供直接反馈(图2(b))。具体而言,每个反馈应包括两部分:
1)主要是对元素低级属性(如模糊、噪声、清晰度、颜色、亮度)的详尽描述。此类描述还应包括与低级属性相关的内容或位置上下文(例如,图像的鸭子/左侧部分曝光不足)。
2)基于对属性的描述,对图像质量进行总体总结。
通过这两个部分反馈(称为pathway反馈),不仅记录了人类基本的低级感知,还反映了人类在评估视觉质量方面的推理过程。
由此构建的Q-Pathway数据集(图2(b))包含18973张多源图像上的58K条pathway反馈,每张图像至少有三条反馈(平均每条反馈46.4个单词)。

虽然这些pathway反馈本身构成了低级视觉指令调优的重要子集,但完整的指令调优数据集应该被设计为激活更多功能。
首先,它还应该包括一个低级视觉问答(VQA)子集。为此,作者参考了COCO-VQA如何从图像标题中导出的设置,并使用GPT将pathway反馈转换为以形容词(例如 good/ fair/ poor)或名词(例如噪声/运动模糊)作为答案的问答对。同样,作者还根据反馈中的信息(回答为是)或与反馈的信息对比(回答为否)收集一个平衡的是非问题答案集;还创建了一些与上下文相关的问答对,以更好地理解低级属性。
VQA子集中的所有问答对都包括多项选择(A/ B/ C/ D)和直接回答设置。此外,除了VQA子集外,在GPT的帮助下,作者还收集了与低级问题相关的长对话子集(例如,为什么会发生失真,如何提高图像质量)。
这些子集组成了Q-Instruct数据集(图2(c)),其中包含200K个指令-响应对,旨在增强MLLM在各种低级视觉能力上的表现。
总之,本文有以下三个贡献:
(1)收集了Q-Pathway,这是一个用于低级视觉感知和质量评估的多模态数据集,其中包括对低级视觉方面的直接人类反馈(带推理)。
(2)基于Q-Pathway,构建了Q-Instruct,这是第一个专注于与低级视觉相关的人类查询的指令调优数据集。
(3)对低级视觉指令调优的丰富实验(图2(d))验证了Q-Instruct提高了MLLM的各种低级能力(图1)
二、方法
2.1 Q-Pathway
2.1.1 图像准备
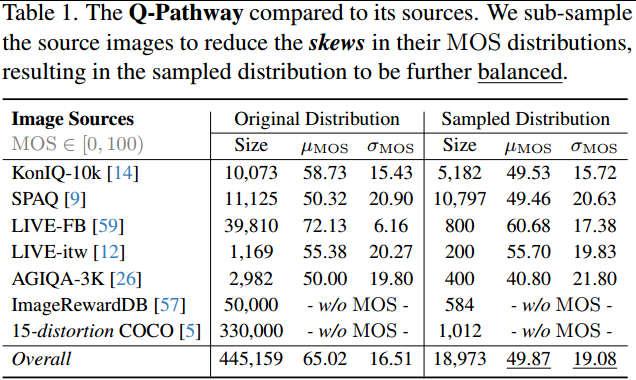
Q-Pathway中的图像是从各种来源采样的,包括四个野生IQA数据集,以及两个具有AI生成图像的数据集。
具体而言,如表1所示,仔细构建了子采样图像群体,以在Q-Pathway中引入更多样化的低级外观,在高质量和低质量图像之间取得平衡。此外,为了进一步使收集到的图像的低级外观多样化,设计了一种自定义的图像损坏变体,以随机损坏COCO数据集中的1012张原始原始图像,其中每15张人为失真1张。
组装的子采样数据集由18973张图像组成,这些图像被进一步馈送给人类受试者以提供Pathway反馈。
2.1.2 任务定义:pathway反馈
为了收集对人类低级视觉方面感知的更丰富、更细致的理解,Q-Pathway选择收集一种新的注释格式,称为pathway反馈,对低级视觉属性(如噪声、亮度、清晰度)进行详尽的自然语言描述,然后得出一般结论。
格式如下:
(1)首先,这些描述可以更完整、更准确地保留人类的感知。例如,如果图像既有暗区也有亮区,如图3(a)所示,亮度分数可能无法正确记录这种情况:位置上下文无法保留,而且将其分数标记为“暗”或“亮”都不准确。
(2)此外,与自由形式的文本反馈不同,pathway反馈中两部分的顺序通常与人类的推理过程相一致。(先给出描述,并根据描述直观的推理出一个结论)
这种推理将有助于MLLM更好地模拟与低级视觉相关的人类感知和理解。
2.1.3 主观学习过程
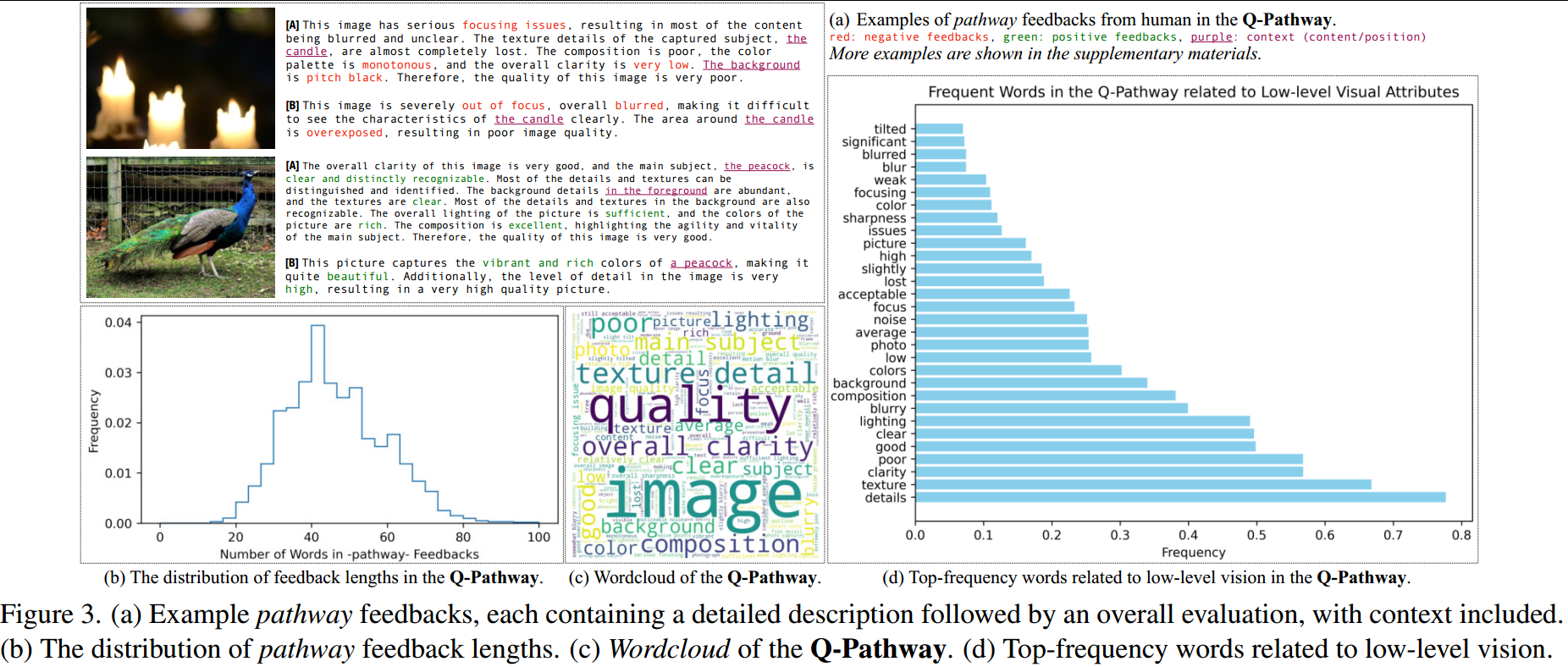
邀请了39名受过训练的人类受试者根据任务定义,并提供图像的MOSs得分辅助质量理解,共收集了58K个pathway反馈,如图3(a)所示。
2.1.4 分析
在主观研究之后,我们简要分析了收集到的反馈。从定性上讲(图3(a)),pathway反馈通常可以保留与低级属性相关的相应上下文。此外,来自不同人类受试者对同一图像的反馈(如[A]和[B]中对每幅图像的示例)显示出良好的一致性(没有有争议的信息),并且彼此略有互补。
据统计,反馈的长度通常在20到100个单词之间,平均为46.4个单词,是普通高级图像标题的4倍(图3(b))。
作者还将单词云(图3c)和与低级视觉相关的高频单词的条形图可视化(图3d),证明收集到的Q-Pathway涵盖了广泛的低级属性,并包括类似比例的正反馈和负反馈。
2.2 Q-Instruct
Q-Pathway中的长而多样的反馈为用于低级视觉指令调优的指令响应对的自动生成过程提供了足够的参考。虽然pathway反馈本身可以教会MLLM推理低级方面并预测质量(2.2.1),但作者进一步设计了更多的指令类型,使MLLM能够响应各种人类查询,包括一个视觉问答子集(2.2.2),用于更准确的低级感知能力,以及一个扩展的对话子集(2.2.3),允许MLLM与人类无缝地讨论与低级视觉方面相关的主题。

2.2.1 基于pathway反馈的低级推理
如图3所示,pathway反馈是直接和整体的人类反应,通常描述低级视觉外观。此外,这些反馈提供了从低级属性(亮度、清晰度)到整体质量评级(good/ poor)的推理,这可以激活MLLM在IQA上的潜在推理能力。此后,以每条pathway反馈为响应,以一般提示为指令,将58K通路推理(图4(a))作为Q-Instruct数据集的主要部分。
2.2.2 视觉问答(VQA)子集
作者要求GPT从pathway反馈中生成与低级视觉相关的各种风格的问题,并用尽可能少的单词提供答案。
如图4(b)所示,将反馈转换为76K个What和How问题,包括如何用与意见相关的形容词(如good/ poor、high/low)回答问题,或者用与属性相关的名词(blur/noise/focus)或与上下文相关的名词回答问题。进一步转换了57K个,Yes与No问题比例为1:1的Yes-or-No 问题。
对于答案格式,有直接的答案,也有多选题(MCQ)格式(图4(b)中的粉红色框)。
2.2.3 扩展对话子集
该子集侧重于提高与人类讨论输入图像低级视觉方面的能力。
这些讨论包括五个主要范围:
1)检查低级视觉模式的原因;
2)提供摄影改进建议;
3)提供恢复、增强或编辑图像的工具;
4)向各自的消费者推荐图像;
5)在pathway反馈中提供的低级视觉描述下可能发生的其他对话。
扩展对话子集也由GPT生成,为Q-Instruct收集了总共12K个对话。
2.2.4 低级可视化指令调优
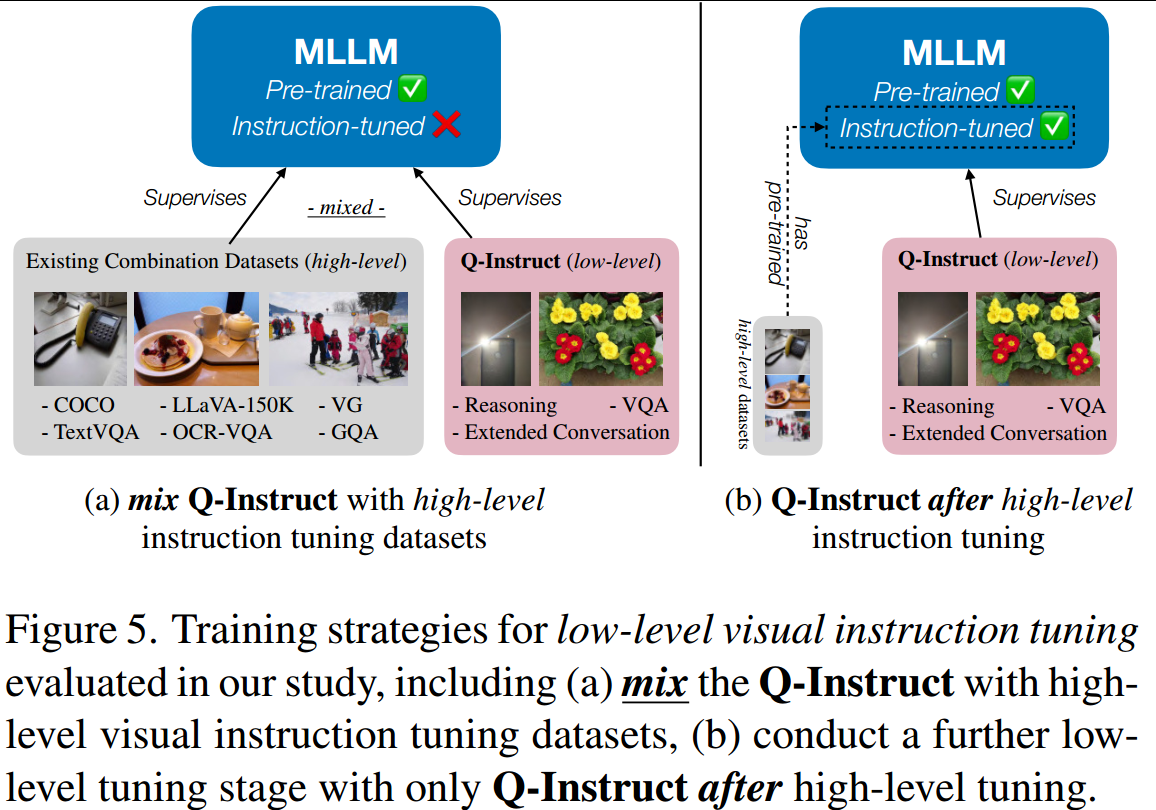
该节论了低级视觉指令调优的标准训练策略,即在MLLM训练过程中何时涉及Q-Instruct数据集。
一般来说,开源MLLM的训练包括两个阶段:
第一,将视觉骨干和LLM的表示空间与百万级网络数据对齐。
其次,结合人类标记的数据集进行视觉指令调整。
考虑到Q-Instruct的规模,一般策略是在第二阶段将其指令-响应对与高级数据集混合,以便在一般高级意识中理想地建立其低级视觉能力,如图5(a)所示。
另一种更快、更方便的策略(不需要再次训练高级数据集)是在原始高级调优后,仅使用Q-Instruct的第三阶段(图5(b))。
三、实验
3.1 实验设置
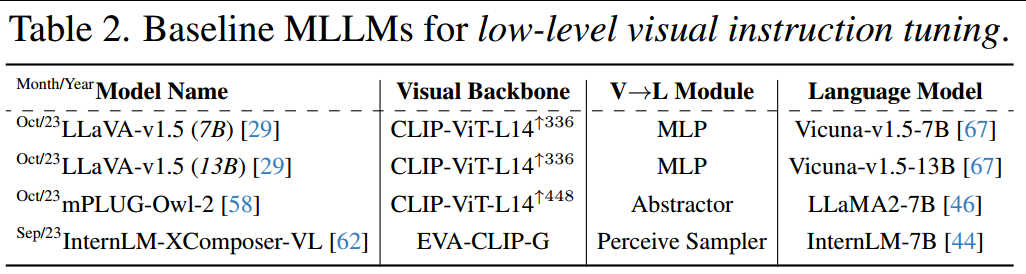
基线模型。我们在不同的元结构(表2)中选择了三种最先进的MLLM的四种变体作为基线模型,以评估他们在Q-Instruct训练前后的低级视觉能力。如图5所示,在高级数据集的原始组合不变的情况下,根据两种策略对每个模型进行评估
3.2 评估任务
在低级视觉指令调整后,MLLM的低级视觉能力在Q-Bench(参考上一篇博客)中定义的三个任务中进行了定量评估:
(A1)感知。感知任务检查MLLM是否正确回答了低级属性(如清晰度、亮度)的问题。使用LLVisionQA数据集作为评估集,其中包含2990个关于低级视觉的多项选择题(MCQ),并平均分为两个子集(dev/test),每个子集有1495个MCQ。
(A2)描述。描述任务评估MLLM是否能够精确地描述给定图像的低级外观。采用LLDescribe数据集作为评估集,包含499幅图像。此任务使用GPT在精度、完成度和相关性方面比较MLLM输出和GT描述,每个输出的评分范围为[0,2]。
(A3)质量评估。质量评估任务检查MLLM(没有直接训练得分)是否能够准确预测整个视觉质量
3.3 实验结果
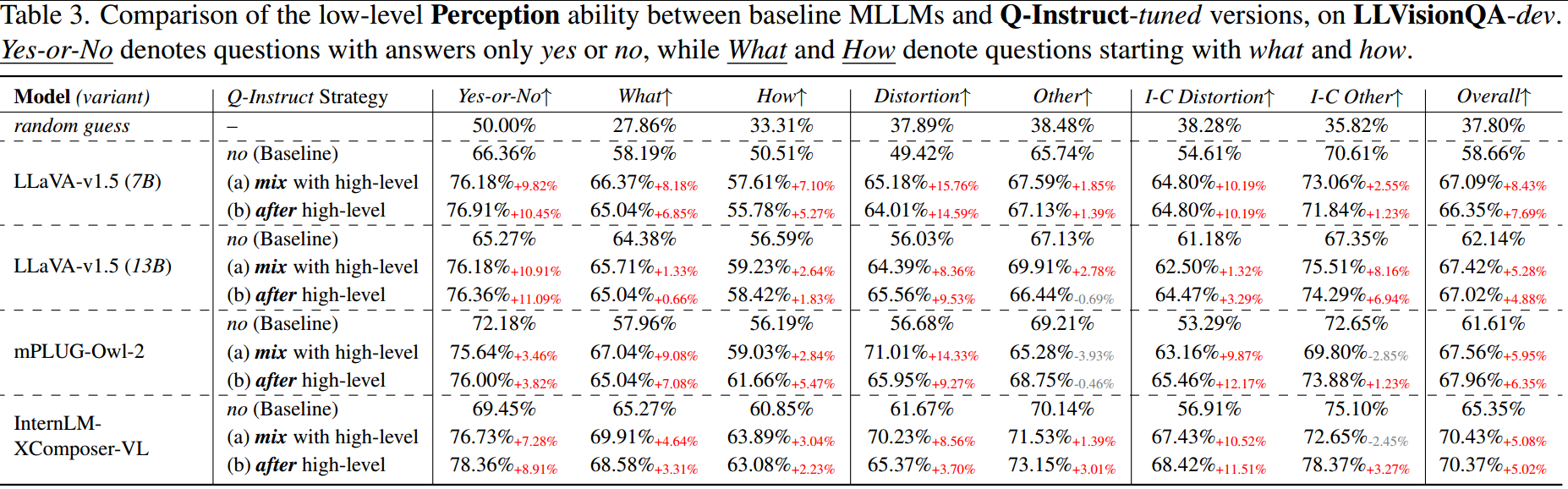

(A1)感知(MCQ)。从表3和表4中,可以观察到将Q-Instruct纳入MLLM训练的任何一种策略都可以显著提高他们的低水平感知能力。结果表明,所提出的管道pipeline能够通过GPT从pathway反馈中自动生成VQA子集(包括MCQ),这有望扩展到其他查询类型。具体来说,在所有维度中,“是”或“否”问题类型的准确性提高得最为显著(平均超过10%)。此外,对失真的改善比其他低级属性(美学、摄影技术)更为显著,这表明人类在Q-Pathway中提出的主要问题仍然与失真有关。
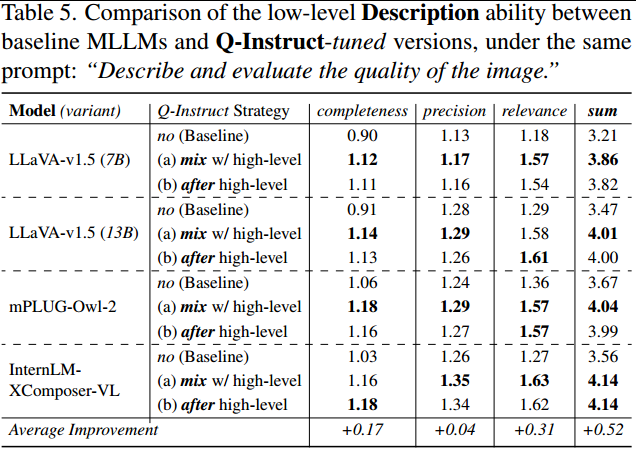
(A2)描述。如表5所示,Q-Instruct调优还显著提高了MLLM的低级描述能力,特别是在相关性(+0.31)方面,所有调优变体的平均得分均超过1.5/2。相比之下,完整性(+0.17)和精度(+0.04)的改进并不显著。
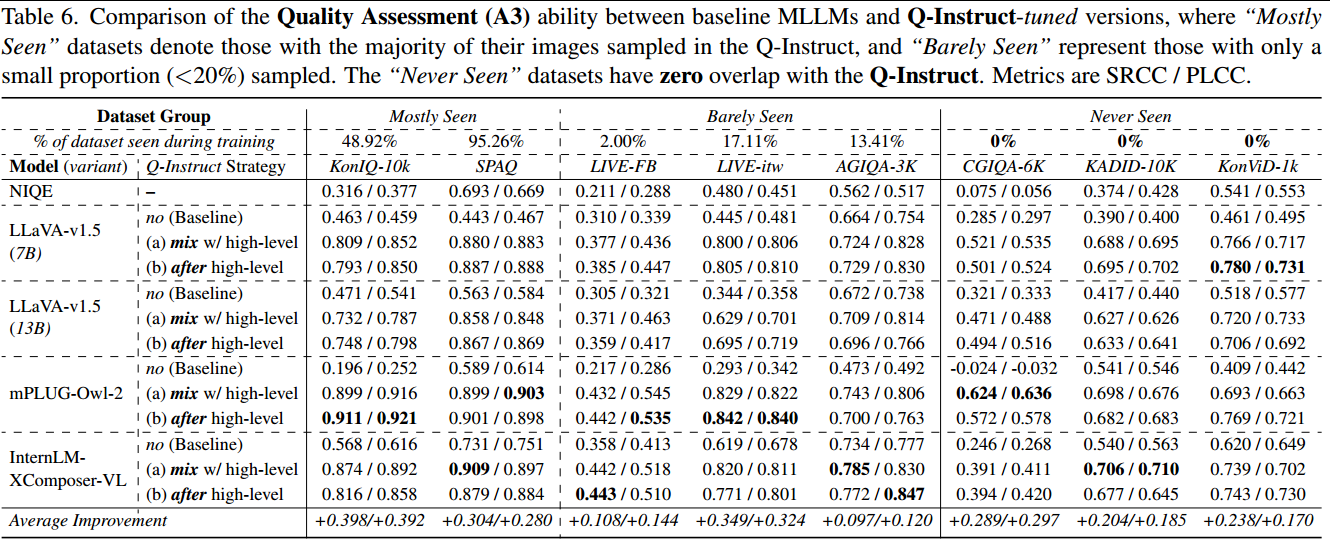
(A3)图像质量评估(IQA)。此处仍遵循softmax池化策略(Q-Bench)从MLLM中提取质量分数并评估其IQA能力,如表6所示。首先,可以发现所提方法在两个最常见的数据集上表现出色。所提方法在训练过程中不直接使用任何MOS值,这表明Q-Instruct调优可以教MLLM在没有任何数值监督的情况下有效地学习评分。
更令人兴奋的结果是,对ªbarely seenº (Q-Instruct中采样了一小部分图像)甚至ªnever seenº (交叉集)数据集的巨大改进,表明低级指令调整可以广泛提高MLLM的低级感知能力。
3.4 消融实验
比较了LLaVA-v1.5(7B)调优过程中的几个数据变化。
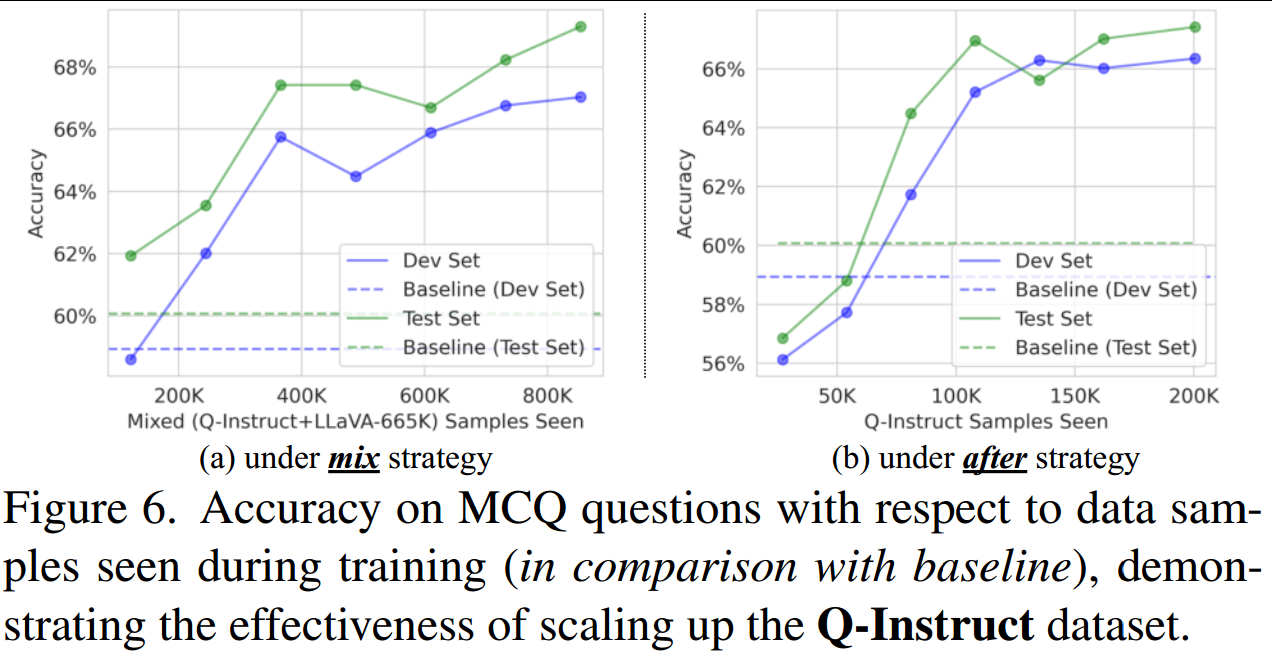
1、按比例扩大Q-Instuct的影响。如图6所示,在混合或后策略下,扩大Q-Instruct在训练过程中的比例可以不断提高低级感知精度。(仍未饱和)
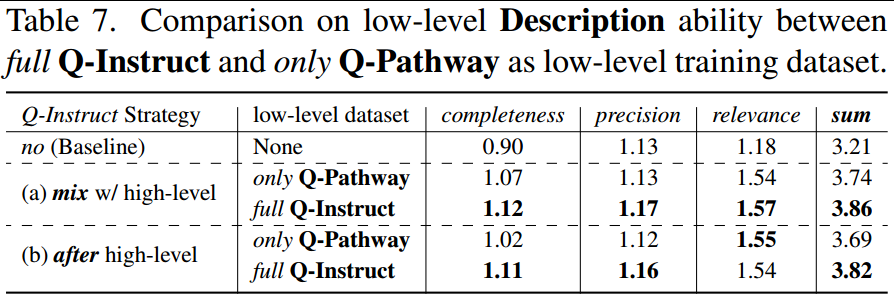
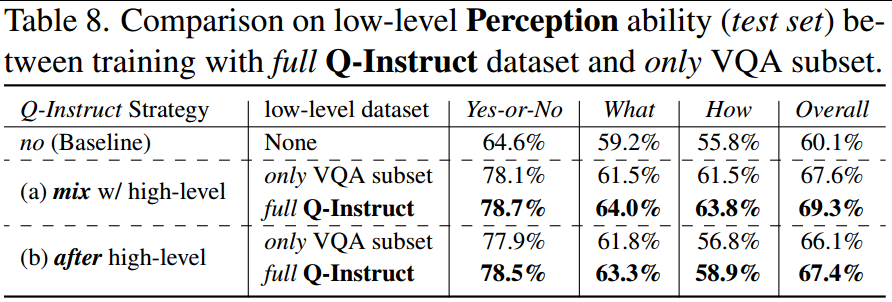
2、联合训练的效果。在低级视觉指令调优中,作者将不同的子集组合在一起,并在一个统一的模型下对它们进行联合训练。为了验证其有效性,作者将这种方法与传统的任务分离调优进行了比较,包括低级描述(表7)和问答(表8)功能。结果显示还是全部使用效果最好。
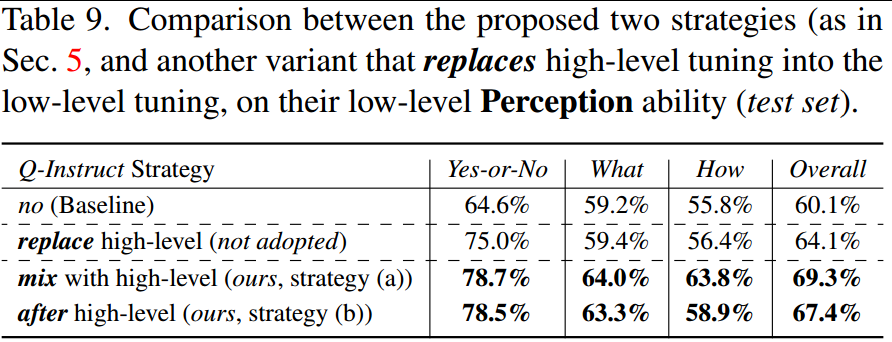
3、高级意识的影响。上述结果注意到混合策略和后策略之间的能力大致相当,但如果将第二阶段数据集替换为Q-Instruct,而在训练过程中不涉及高级指令调优数据集,将进一步研究性能。如表9所示,替换策略明显不如本文提的两种策略,这表明基本的高级意识对于MLLM的一般低级视觉识别很重要。
四、结论
本文提出了第一个关于低级视觉方面的多模态数据集,包括具有58K人类文本反馈的Q-Pathway和具有200K指令响应对的派生Q-Instruct,以促进MLLM的低级视觉指令调优。
它们的IQA性能揭示了一个有趣的现象,即纯文本驱动的指令调优可以使MLLM与数字质量分数充分对齐,并对未见过的视觉输入类型有令人印象深刻的泛化能力。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)