(四十一)深度解析领域特定语言(DSL)第七章——语法制导翻译——参数验证DSL语法分析器实现:构建语义模型
本文介绍了语义模型构建的核心流程,通过ModelBuilder类实现。重点内容包括:1) 使用栈结构存储模型组件,通过后序遍历语法树节点;2) 构建比较表达式和逻辑表达式模型的方法实现;3) 分析了模型复用问题,提出基于结构特征的缓存策略;4) 以"(#e>=0 and #e<=8) or (#e>=50 and #e<=100)"为例,展示了模型构建过
接续上文。笔者将构建语义模型的任务交由ModelBuilder类进行处理,该类位于“model”包中,结构信息和入口方法如代码7-22所示:
代码7-22
class ModelBuilder {
private Stack<Validatable> stack = new Stack<>();
public Validatable build(AST tree, Comparable elementValue) {
List<Node> nodes = tree.traversal(); //代码1
for (Node node : nodes) { //代码2
buildCompareExpression(node, elementValue);
buildLogical(node);
}
return stack.pop();
}
}栈类型的字段stack用于保存已经构建好的语义模型,至于为什么要使用堆栈笔者会在后文中进行解释。build()方法是构建语义模型的核心,分为如下两部分逻辑:
- 代码1 处,调用AST对象的traversal()对语法树进行遍历,获取所有有意义的结点对象数据。
- 代码2处,执行语义模型构建逻辑并返回最终的结果。
接下来,让我们以DSL脚本“(#e >= 0 and #e <= 8) or (#e >= 50 and #e <= 100)”为例,对语义模型的构建流程进行说明。首先,请看一下该脚本所对应的语义模型结构,如图 7.17所示。build()方法所返回的,就是根节点Or。请读者务必注意,笔者在前面的内容中也展示了一些类似的图,如图 7.13、图 7.14等,它们所代表的是抽象语法树的结构,是语法分析环节的结果;而图 7.17展示的则是语义模型对象的运行时结构,是语义模型构建环节的结果,请读者注意二者间的区别。
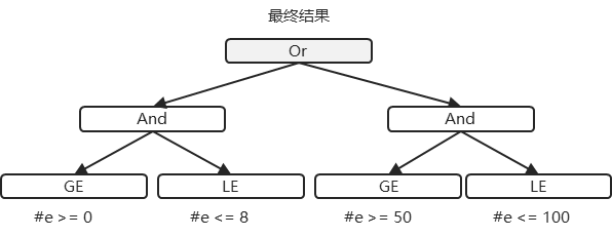
图 7.17 DSL 脚本(#e >= 0 and #e <= 8) or (#e >= 50 and #e <= 100)所对应的语义模型对象运行时结构
对语法树节点进行遍历的代码位于AST类(即代码7-17)中,如代码7-23所示:
代码7-23
List<Node> traversal() {
List<Node> nodes = new ArrayList<>();
if (root.child == null) {
return nodes;
}
traversal(nodes, root.child);
return nodes;
}
void traversal(List<Node> allNodes, Node root) {
if (!(root instanceof BinaryNode)) {
return;
}
BinaryNode binaryNode = (BinaryNode)root;
if (binaryNode.left != null) {
traversal(allNodes, binaryNode.left);
}
if (binaryNode.right != null) {
traversal(allNodes, binaryNode.right);
}
allNodes.add(binaryNode);
}无参方法traversal()是遍历语法树节点的入口,其会将所有的节点对象存储于列表之中作为最终输出。此处的逻辑刻意使用了后序遍历的方式对语法树的节点进行访问,这就意味着输出的结果是有序的,这一点还请读者注意。图 7.18以图 7.14为参考,展示了语法树遍历的结果(注:其中存储的是语法树节点对象),后续环节会以此列表中的数据为依据进行语义模型的构建工作。
接续代码7-22的学习。ModelBuilder.build()方法的第二部分逻辑为构建语义模型,代码7-24展示了构建关系运算语义模型的实现:
代码7-24
void buildCompareExpression(Node node, Comparable elementValue) {
if (!(node instanceof CompareNode)) {
return;
}
CompareNode compareNode = (CompareNode)node;
String operator = compareNode.operator.lexeme;
ElementTuple tuple = this.buildTuple(elementValue, compareNode);
Validatable result = null;
if (Objects.equals(operator, TokenType.EQ.getName())) {
result = new Equal(tuple.left, tuple.right);
}
if (Objects.equals(operator, TokenType.GREATER_THAN.getName())) {
result = new GreaterThan(tuple.left, tuple.right);
}
if (Objects.equals(operator, TokenType.LESS_THAN.getName())) {
result = new LessThan(tuple.left, tuple.right);
}
if (result != null) {
stack.push(result);
}
}
ElementTuple buildTuple(Comparable elementValue, CompareNode compareNode) {
BigDecimal left, right;
if (compareNode.left != null) {
left = new BigDecimal(compareNode.left.lexeme);
right = new BigDecimal(elementValue.toString());
return new ElementTuple(left, right);
}
left = new BigDecimal(elementValue.toString());
right = new BigDecimal(compareNode.right.lexeme);
return new ElementTuple(left, right);
}
class ElementTuple {
Comparable left;
Comparable right;
}由buildCompareExpression()方法可知,笔者只实现了等于、大于、小于三个运算符的语义模型构建逻辑,而我们的案例却会使用到小于等于和大于等于两类运算。扩展起来也很简单,只需要将对应的代码加到该方法中即可。另外就是关于参数elementValue的作用,它所代表的是被验证对象的实际值,会作为语义模型的一部分而存在,即关系表达式的左元或右元。那么为什么它的位置不是固定的呢?这与DSL脚本的编写方式有关。用户可以将比较表达式写成如下两种等价的形式:
- #e > 20。
- 20 < #e。
#e是一个占位符,其所代表的是被验证对象的实际值(即elementValue),可以出现在表达式的任意一侧。在将#e替换成真实值的时候,必须要保持其位置不发生变化,否则就会影响到语义模型的正确性。
在buildCompareExpression()方法的末尾,会将语义模型实例压入堆栈以便后续环节使用。在继续学习之前,有必要分析当前设计存在的不足。当前设计选择在构建语义模型时,将被验证对象的实际值和目标值作为成员变量传入语义模型。按照这种方式,每次触发验证时都需要执行一次语言编译操作来重新构建语义模型。其原因在于,这两个值会不断变化,必须通过创建新实例才能保证数据有效性。可以预见,频繁的验证操作将导致语义模型被频繁创建,由此带来的性能损耗不容忽视。
显然,解决上述问题的最优方案是复用语义模型,但在当前案例中实现复用并非易事。由于DSL结构的差异,语义模型的结构也会不同。以DSL脚本“#e >= 0 and #e <= 8”和“#e >= 0 or #e <= 8”为例,其对应的语义模型分别如图 7.19-a、图 7.19-b所示。若要实现复用,需为每类DSL结构构建对应的语义模型实例并缓存。尽管理论上DSL脚本结构可能无限,导致语义模型实例数量不可控,但在实际项目中,可使用的DSL结构通常是有限枚举的,因此无需过度担忧对象爆炸问题。此外,还可通过设置缓存容量上限的方式,进一步限制语义模型实例的数量。
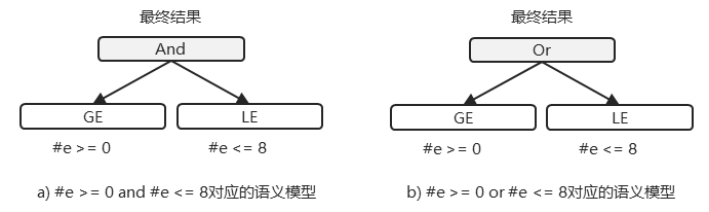
除缓存语义模型实例之外,实现对象复用还需要考虑如下两个问题:
- 如何查询被缓存的实例。针对这一问题,可考虑从DSL脚本的结构出发,将其结构特征转换成字符串来做为缓存的键。所为“结构特征”,其实就是去除脚本中变量部分(占位符、目标值)之后所得到的值。以脚本“#e >= 0 and #e <= 8”为例,其结构特征字符串为“>=_and_<=”(为方便识别,笔者在每一元素之间加上了下划线作为分隔符)。类似地,脚本“(#e > 0 and #e < 20) or (#e > 30 and #e < 50)”所对应的结构特征字符串为“(_>_and_<_)_or_(_>_and_<_)”。查找缓存实例时,可首先将DSL表达式转换为结构特征字符串。
- 如何触发验证。触发验证时,首先根据DSL脚本定位到被缓存的语义模型实例(没有的话则构建一个新的),之后再调用validate()方法来执行验证逻辑。值得注意的是,我们应该在执行验证时将目标值和被验证对象的实际值做为validate()方法的参数传入进去,而不是像当前方案一样将它们作为对象的字段。
笔者以有限篇幅探讨了实践中语义模型的构建与使用。实际开发中,需考量的因素更为复杂,例如触发验证的时机、语义模型实例的构建时机(服务启动阶段或验证执行阶段)等,均需读者进行全面权衡。但作为教学案例,需简化处理——当前学习重点聚焦于语法分析与语义模型构建。
让我们再回到代码7-22中。build()方法还会调用buildLogical()方法来构建逻辑表达式语义模型。如代码7-25所示:
代码7-25
void buildLogical(Node node) {
if (!(node instanceof LogicalNode)) {
return;
}
LogicalNode logicalNode = (LogicalNode)node;
String operator = logicalNode.logicalOperator.lexeme;
Validatable result = null;
if (Objects.equals(operator, TokenType.AND.getName())) {
Validatable x = stack.pop();
Validatable y = stack.pop();
result = new And(x, y);
}
if (Objects.equals(operator, TokenType.OR.getName())) {
Validatable x = stack.pop();
Validatable y = stack.pop();
result = new Or(x, y);
}
if (result != null) {
stack.push(result);
}
}buildLogical()方法的核心逻辑可概括为如下两点:
- 当语法树节点类型为逻辑表达式的时候,从栈对象中弹出两个元素(均为语义模型实例,类型为关系运算或逻辑运算)并使用它们作为构造函数的参数来构建逻辑表达式语义模型。之所以要从栈中弹出两个对象,是因为逻辑表达式是二元的,必须有两个子元素才可以。另外,由于我们使用的是自底向上的后序遍历方式,所以栈中必然已经存在至少两个语义模型的实例。
- 将构建好的语义模型再次放入到栈中,因为它可能是另一个语义模型的子元素。
按照以上原则,当对图 7.18所示的语法树节点列表进行遍历处理时,栈对象stack中的元素将会按图 7.20所指示的趋势发生变化。而当列表遍历完成时,栈中所余下的唯一元素便是我们需要的最终结果。

至此,语义模型构建工作已完成。该过程主要包含两个步骤:遍历语法树和构建语义模型。第一步通过后续遍历方式访问节点并按序输出所有节点;第二步利用第一步的输出结果执行语义模型构建逻辑。那么,能否将这两个步骤合并,即在语法树遍历过程中同步创建语义模型?笔者认为,至少从当前案例的复杂度来看,这种处理方式完全可行。但若DSL脚本较为复杂,分步处理则更为适宜。
最后建议读者抽时间巩固面向对象、设计模式和数据结构相关知识。尽管案例已尽可能简化,仍大量涉及这些知识。实际业务场景通常更为复杂,涉及的知识领域也更广泛,而扎实的理论基础是构建优秀软件的根基。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 23
23 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)