(四十七)深度解析领域特定语言(DSL)第八章——语法分析器组合子:案例实现(Part3)
本文介绍了基于组合子模式实现的语法分析器设计。通过代码示例展示了如何构建BindingParser、BindingBlockParser和StartParser等子分析器,说明了如何通过对象组合方式实现复杂语法解析。重点分析了StartParser作为顶级分析器的组装过程,以及通过OrderRuleParser外观类封装解析细节的设计考量。文章还探讨了子分析器命名规范、组合子与语言构造的对应关系,
续接上文。
代码8-22中,笔者通过调用parsers[i].setupCallback()方法为对应的子分析器设定回调函数,其中i表示构造函数中的第i个子分析器,其值分别为0和2。不过,这种将变量名写死的方式是笔者非常不喜欢的,读者了解其意即可,实践中应该使用其它更优雅的方式。两个回调方法的实现如代码8-23所示:
代码8-23
void acceptServiceType(List<Token> tokens) {
this.serviceType = tokens.get(0);
}
void acceptAliases(List<Token> tokens) {
this.aliases = tokens;
}acceptServiceType()方法用于获取受理类型信息,acceptAliases()方法用于获取别名列表信息。这两个方法的参数由BindingParser类内的子分析器进行赋值,执行过程当中再将该值赋予类内定义的字段。以脚本“upgrade {ResNotF, ResNotE};”为例,第一个方法执行后,类内字段serviceType的值为“upgrade”;第二个方法执行后,aliases字段的值则为“ResNotF”和“ResNotE”。
BindingParser类剩余的代码如代码8-24所示:
代码8-24
@Override
void parse(ParseContext context) {
super.parse(context);
if (!context.isPreviousMatched()) {
return;
}
this.constructBindingModel(context);
}
void constructBindingModel(ParseContext context) {
String serviceType = null;
if (this.serviceType != null) {
serviceType = this.serviceType.lexeme;
}
List<String> aliases = null;
if (this.aliases != null) {
aliases = this.aliases.stream()
.map(e -> e.lexeme)
.collect(Collectors.toList());;
}
context.bindingConfig.addBindingItem(serviceType, aliases);
}constructBindingModel()用于构建语义模型,逻辑比较简单,笔者不做过多赘述。接下来要展示的是规则绑定代码块子分析器的实现,对应于非终结符BINDING_BLOCK,如代码8-25所示:
代码8-25
class BindingBlockParser extends SequenceParser {
BindingBlockParser(String targetNode) {
super(targetNode,
new TerminalParser(TokenType.BIND_RULES),
new ListParser(new BindingParser("BINDING"), TokenType.END),
new TerminalParser(TokenType.END));
}
@Override
void parse(ParseContext context) {
super.parse(context);
}
}至此为止,我们已经将规则名称代码块、受理类型代码块和规则绑定代码块所对应的子分析器,及其内部嵌套的子分析器代码进行了展示和说明。接下来,需要将三个顶层分析器组装在一起形成一个更大的语法分析器,使其能够对完整的DSL语言进行分析并构建出BindingConfig类型的实例,该对象是语法分析器要构建的最终结果。StartParser类完成了本次组装的任务,对应于非终结符START,如代码8-26所示:
代码8-26
class StartParser extends SequenceParser {
StartParser(String targetNode) {
super(targetNode,
new RuleBlockParser("RULE_BLOCK"),
new ServiceTypeBlockParser("SERVICE_TYPE_BLOCK"),
new BindingBlockParser("BINDING_BLOCK"),
new TerminalParser(TokenType.EOF));
}
@Override
void parse(ParseContext context) {
super.parse(context);
if (!context.isPreviousMatched()) {
throw new ParseException(context.getError());
}
}
}StartParser类的构造函数中,笔者不仅将三个顶级子分析器进行了组装,还特意加了一个用于对EOF类型的词法单元进行解析的分析器,这样的话,bind_rules代码块所对应的end关键字之后将不再允许添加任何其他的脚本,否则将无法通过解析。另外,笔者在前文中也曾对三个代码块的顺序进行过阐述,必须按代码8-1所示的顺序才可以。这一点,通过StartParser的实现也能看到。其继承自顺序结构分析器SequenceParser,运行时会按子分析器的配置顺序对DSL代码进行解析。
另外,虽然StartParser子分析器是最顶级的分析器,但我们不应该让用户直接使用它。具体原因如下:
- 定义于中抽象类Parser中的parse()无返回值。由代码可知,构建好的语义模型被放到了参数context对象中,虽然也可以让用户直接从该对象中获取最终结果,但这样的做法不太符合常见的编程习惯。正常情况下,应通过返回值的形式来为客户提供所需的结果。
- 保持ParseContext类型的不可见。parse()方法使用了ParseContext类型的对象作为参数,不过该对象内部需要初始化的信息比较多,将这些细节暴露给客户端的话很容易导致混乱。此外,对于设计良好的应用或者框架而言,无论是对象的初始化还是方法调用,都应尽量简化,参数越少越好,除非需要的信息必须通过外部传入进去。对于当前案例而言,既然ParseContext的使用仅仅是内部工作机制所需,就没必要再让其对用户可见了。
综上所述,笔者引入了一个外观类OrderRuleParser,该类将StartParser对象和ParseContext对象的初始化过程进行了封装,如代码8-27所示:
代码8-27
class OrderRuleParser {
private ParseContext context = new ParseContext();
OrderRuleParser(TokenBuffer tokenBuffer) {
context.tokenBuffer = tokenBuffer;
context.nameContainer = new NameContainer();
context.serviceTypeContainer = new ServiceTypeContainer();
context.bindingConfig = new BindingConfig(context.nameContainer,
context.serviceTypeContainer);
}
BindingConfig parse() {
StartParser start = new StartParser("START");
start.parse(context);
return context.bindingConfig;
}
}代码比较简单,笔者不做过多的解释。唯一值得注意的是ParseContext对象的初始化过程,笔者将其放到了构造函数OrderRuleParser()当中,更值得推荐的方式是由ParseContext类来承担这一责任,也就是所谓的“信息专家模式(Information Expert Pattern)”,有兴趣的读者可找一些专门的资料进行学习。
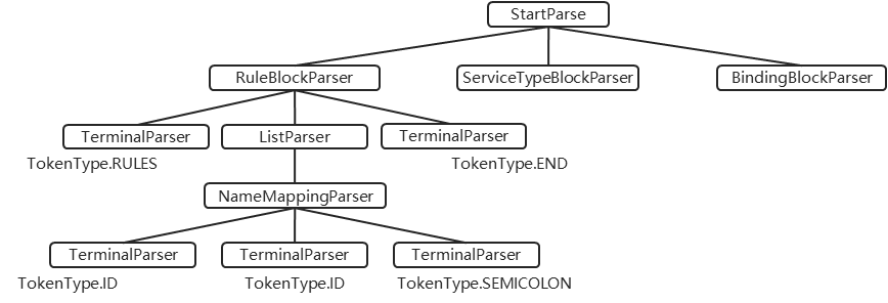
关于基于组合子模式实现语法分析器的完整代码已全部展示。建议读者回顾前文代码,从宏观视角观察完整语法分析器的结构,不难发现其将面向对象编程的思想体现得淋漓尽致。当实例化StartParser对象时,其运行时结构如图 8.7所示(为简化展示,笔者只对rules代码块所对应的子语法分析器进行了分解。请读者将图示结构与示例代码对照,尝试推断其他代码块(如服务类型块等)对应的子分析器结构,深入理解组合子模式通过对象组合构建复杂解析逻辑的核心机制。
在结束本章之前,笔者需要对一些要点内容进行总结:
- 子分析器的命名模式。按照笔者个人的习惯,比较喜欢让子分析器与文法符号使用相同的名称,前面的代码也对此进行了体现。不过为了提升代码的可阅读性,笔者还为每一个子分析器增加了Parser后缀。由于使用组合子模式会产生非常多的分析器类型,保持分析器与文法符号名称的一致对于程序的可维护性来说是有利的。
- 组合子与程序构造的关系。正常情况下,我们需要为DSL中的每一个构造都给出一个对应的子分析器,比如前文案例中的rules、service_types以及这些构造所包含的子构造。除此之外,我们还需要为一些隐式的构造进行建模,这些构造通常会作为子分析器的父类,如顺序结构、选择结构、循环结构等,前面案例中SequenceParser和ListParser便属于这类隐式语言构造分析器。
上一章 下一章

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 26
26 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)