基于OpenCV的银行卡号识别系统:从原理到实现
本文介绍了一个基于Python和OpenCV的银行卡号识别系统。系统采用计算机视觉技术处理银行卡图像,通过灰度转换、二值化、轮廓提取和排序等预处理步骤,结合自定义工具函数优化处理流程。核心技术包括:1)模板处理,建立数字特征库;2)图像形态学处理增强数字特征;3)三重循环实现数字区域定位和模板匹配。该系统能准确识别卡号并判断卡类型,展现了传统CV技术在金融科技中的实用价值,具有扩展到其他卡证识别场
引言
在现代金融科技应用中,银行卡号的自动识别是一项重要技术。本文将详细介绍如何使用Python和OpenCV库构建一个完整的银行卡号识别系统。该系统能够从银行卡图像中提取卡号信息,并根据卡号首数字判断银行卡类型。
技术栈
- OpenCV: 计算机视觉库,用于图像处理和特征提取
- NumPy: 科学计算库,用于数组操作和数值计算
- argparse: 命令行参数解析库
- 自定义工具函数: 用于轮廓处理和图像调整
创造函数
这里为了优化主函数的简洁性,我们另写了一个py文件,然后在主函数内导入。
这里写了一个排序函数,是我们对我们在图像中得到的轮廓进行从左到右排。
import cv2
def sort_contours(cnts, method="left-to-right"):
reverse = False
i=0
if method == "right-to-left" or method == "bottom-to-top":
reverse = True
if method == "top-to-bottom" or method == "bottom-to-top":
i=1
boundingBoxes = [cv2.boundingRect(c) for c in cnts]
(cnts, boundingBoxes) = zip(*sorted(zip(cnts, boundingBoxes),
key=lambda b: b[1][i],reverse=reverse))
return cnts, boundingBoxes
还一个resize函数,这个和最初的resize不一样,这个变大变小是等比变化的。
def resize(image,width=None,height=None,inter=cv2.INTER_AREA):
dim = None
(h, w) = image.shape[:2]
if width is None and height is None:
return image
if width is None:
r = height / float(h)
dim = (int(w * r), height)
else:
r = width / float(w)
dim = (width, int(h * r))
resized = cv2.resize(image, dim, interpolation=inter)
return resized系统架构
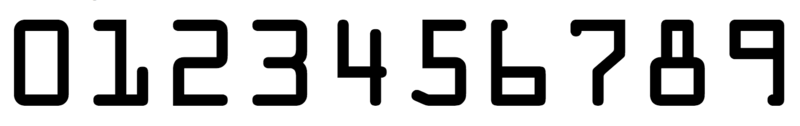

主要思路:
先对模板图像(包含数字的图像)进行灰度图处理,二值化。然后找出全部轮廓(这里轮廓是乱序的,我们用我们写的函数,对顺序进行整理),找出轮廓的的外接矩形。然后对轮廓进行裁剪,然后把用字典把图像和对应数字保存下来。
再对我们要检测的图像进行处理。灰度图,二值化,然后进行图像形态学处理(把我们的数字变的更明显,然后把背景给去除),找出我们的所在位置。然后裁剪出来,然后对每一个图像再进行每一个数字的定位。然后再对比,找出最大值的对应的索引,然后再保存就ok了。
代码详解
1 模板处理
image=cv2.imread(args["template"])
cv_show("image", image)
ref=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
cv_show("ref", ref)先进行二值化处理,不过我们的的图像原本就是二值化的,所以没啥区别
这里进行了一次图像转化,因为轮廓检测对白色检测。原本是黑色的。
ref=cv2.threshold(ref,127,255,cv2.THRESH_BINARY_INV)[1]
cv_show("ref", ref)
refCount,_=cv2.findContours(ref,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(image,refCount,-1,(0,255,0),3)
cv_show("ref", image)
refCnts=myfun.sort_contours(refCount,method='left-to-right')[0]把每个轮廓画出,并进行排序。

digits={}
for (i, cnt) in enumerate(refCnts):
(x, y, w, h) = cv2.boundingRect(cnt)
roi = ref[y:y+h, x:x+w]
roi=cv2.resize(roi,(57,88))
cv2.imshow("ROI", roi)
digits[i] = roi
print(digits)然后把每个数字的轮廓找外界矩形,然后保存下来
裁剪成这样 ,然后再保存下来。
,然后再保存下来。
2 图片处理
传入图片进行展示

进行二值化处理
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
cv_show("gray", gray)
定义核
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT,(9,3))
squareKernel = cv2.getStructuringElement(cv2.MORPH_RECT,(5,5))这里比较大,效果好。
进行顶帽处理
顶帽操作是原图像与开运算之间的差。开运算是先腐蚀后膨胀,顶帽操作用于突出比周围亮的区域,常用于增强图像中的细小亮细节或去除不均匀光照。如下图,我们用原图减去我们进行开运算的图,就可以看到我们数字的地方消失了,只剩背景了,减去之后就刚好只剩数字了。

tophat=cv2.morphologyEx(gray,cv2.MORPH_TOPHAT,rectKernel)
cv_show("tophat", tophat)
进行腐蚀
closeX=cv2.morphologyEx(gray,cv2.MORPH_CLOSE,rectKernel)
cv_show("closeX", closeX)这样我们的数字就更好选取一点了,然后这里四个一组可以直接选取了,注意这里我们要观察数字的特征,以便于我们对轮廓更好选取。

进行二值处理
thresh=cv2.threshold(closeX,0,255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv_show("thresh", thresh)
画出轮廓
threshCnts,h=cv2.findContours(thresh.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
cnts=threshCnts
cur_img=img.copy()
cv2.drawContours(cur_img,cnts,-1,(0,255,0),3)
对数字部分排序
cv_show("cur_img", cur_img)
locs=[]
for (i, cnt) in enumerate(cnts):
(x, y, w, h) = cv2.boundingRect(cnt)
ar=w/float(h)
if ar>2.5 and ar<4.0:
if (w>40 and h<55) and (h>10 and h<20):
locs.append((x,y,w,h))
locs=sorted(locs,key=lambda x : x[0])进行三重循环
第一层 对四块数字进行循环
第二层 对每块数字进行操作,然后找出每一个数字。

第三层 对上面每一个数字进行模板匹配
output = []
# 遍历每一个轮廓中的数字
for (i, (gX, gY, gW, gH)) in enumerate(locs):
groupOutput = []
group = gray[gY - 5:gY + gH + 5, gX - 5:gX + gW + 5] # 适当加一点边界
cv_show('group', group)
# 预处理
group = cv2.threshold(group, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv_show('group', group)
# 计算每一组的轮廓
digitCnts, hierarchy = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
digitCnts = myfun.sort_contours(digitCnts, method="left-to-right")[0]
# 计算每一组中的每一个数值
for c in digitCnts:
# 找到当前数值的轮廓, resize成合适的大小
(x, y, w, h) = cv2.boundingRect(c)
roi = group[y:y + h, x:x + w]
roi = cv2.resize(roi, (57, 88))
cv_show('roi', roi)
# 使用模板匹配,计算匹配得分
scores = []
# 在模板中计算每一个得分
for (digit, digitROI) in digits.items():
# 模板匹配
result = cv2.matchTemplate(roi, digitROI, cv2.TM_CCOEFF)
(_, score, _, _) = cv2.minMaxLoc(result)
scores.append(score)
# 得到最合适的数字
groupOutput.append(str(np.argmax(scores)))
# 画出来
cv2.rectangle(img, (gX - 5, gY - 5), (gX + gW + 5, gY + gH + 5), (0, 0, 255), 1)
cv2.putText(img, "".join(groupOutput), (gX, gY - 15), cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0, 0, 255), 2)
output.extend(groupOutput) # 得到结果,将一个列表的元素添加到另一个列表的末尾。结果展示

结论
本文介绍的银行卡号识别系统展示了传统计算机视觉技术在金融科技中的应用。通过合理的图像预处理、特征提取和模板匹配,实现了较高的识别准确率。这种技术不仅适用于银行卡识别,还可推广到其他卡证识别场景,具有广泛的应用前景。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)