MapReduce 的执行原理
本文系统介绍了MapReduce分布式计算模型的执行原理。MapReduce采用"分而治之"思想,将任务分解为Map和Reduce两个阶段:Map阶段并行处理数据分片并生成中间键值对;Shuffle阶段对中间结果进行分区、排序和聚合;Reduce阶段完成最终计算。该模型具有编程简单、并行度高、容错性强等优点,但也存在磁盘I/O依赖、迭代计算效率低等局限。虽然新兴计算框架不断涌现
一、前言
随着大数据的快速发展,如何高效处理海量数据成为关键问题。Google 提出的 MapReduce 编程模型,以及 Hadoop 对它的开源实现,为分布式大规模数据处理提供了统一的解决方案。
本文将带你深入理解 MapReduce 的执行原理,从 整体流程 到 各阶段细节,让你对它有一个系统的认识。
二、MapReduce 的核心思想
MapReduce 将一个复杂任务分解为两个阶段:
-
Map(映射阶段):把大任务拆分成多个小任务,在不同节点并行处理,生成中间结果(key-value 对)。
-
Reduce(归约阶段):对中间结果按 key 分组,再进行聚合、统计、计算,得到最终结果。
一句话总结:分而治之 + 并行计算。
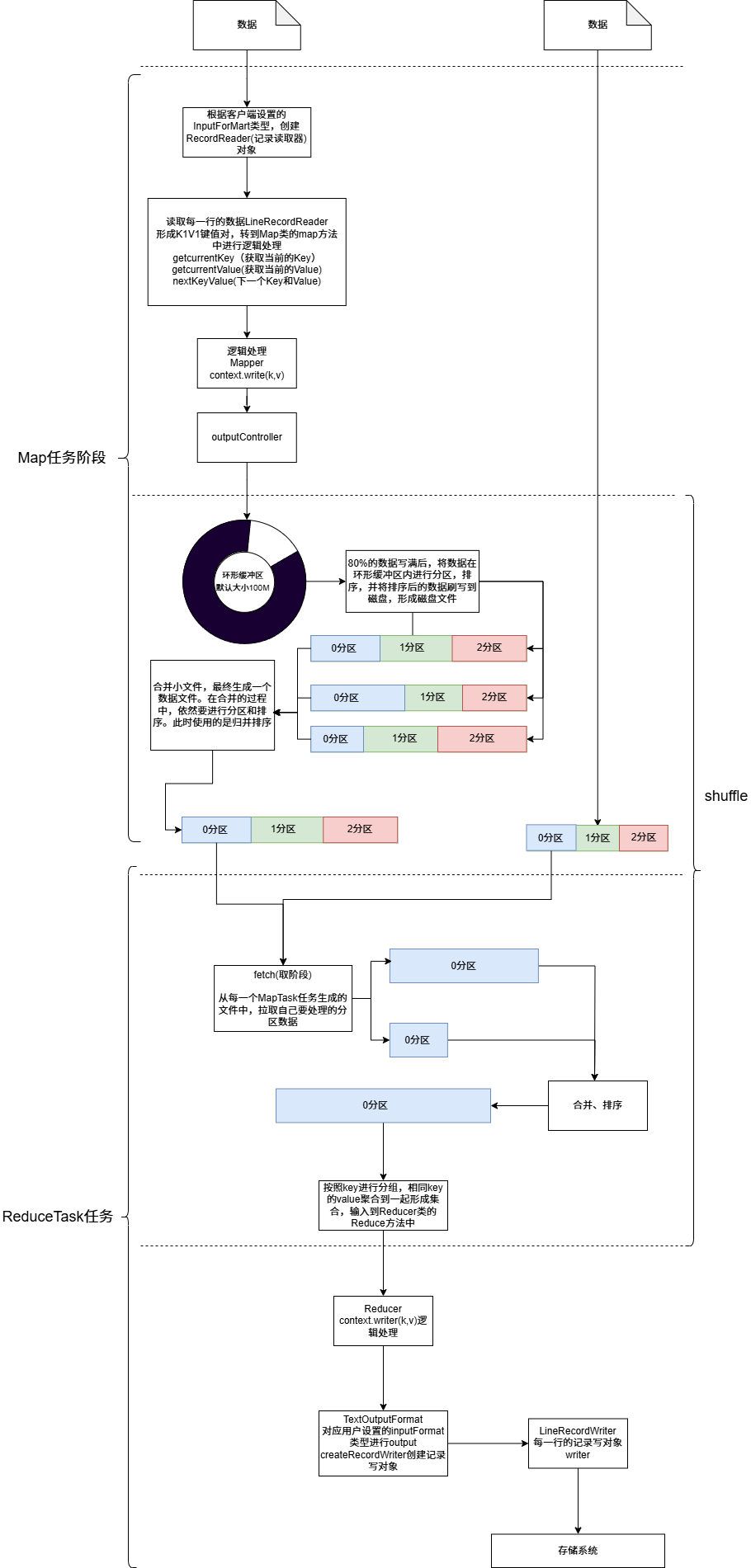
三、MapReduce 的执行流程
整个执行过程可以分为以下 6 个阶段:
-
输入分片(Input Splits)
-
Hadoop 会把大文件切分成若干个逻辑分片(默认大小 128MB)。
-
每个分片会交给一个 Map Task 处理。
-
-
Map 阶段
-
Map Task 从分片中读取数据,解析成
<key, value>对。 -
执行用户自定义的
map()方法,输出新的中间<key, value>对。
-
-
Shuffle 阶段(核心)
Shuffle 是 MapReduce 的灵魂,分为三个小过程:-
Partition(分区):决定某个 key 属于哪个 Reduce Task。
-
Sort(排序):在每个分区内部,按 key 排序。
-
Combine(可选):在 Map 端先做一次本地聚合,减少网络传输量。
-
-
数据传输
-
Map 输出的数据通过网络传输给对应的 Reduce Task。
-
-
Reduce 阶段
-
Reduce Task 接收来自不同 Map 的数据,并对相同 key 的 value 集合执行用户自定义的
reduce()方法。
-
-
输出结果
-
Reduce 的结果写入 HDFS,形成最终的计算结果。
-
四、MapReduce 执行过程示意图
输入数据 → 分片 → Map → Shuffle → Reduce → 输出结果
可以用一个词频统计(WordCount)的例子来理解:
-
Map 阶段:将每个单词映射为
<word, 1>。 -
Shuffle 阶段:把相同单词聚合到一起,如
<hello, [1,1,1]>。 -
Reduce 阶段:累加得到
<hello, 3>。
五、MapReduce 的特点
-
优点
-
编程模型简单,屏蔽了分布式计算的复杂性。
-
天然适合大规模并行计算。
-
与 HDFS 紧密结合,具有高容错性。
-
-
缺点
-
计算过程中依赖磁盘 I/O,效率较低。
-
迭代计算(如机器学习算法)不够高效。
-
调度和资源利用率有限。
-
六、总结
MapReduce 的执行原理可以概括为:输入 → Map → Shuffle → Reduce → 输出。
它通过“分而治之”的思想,把复杂任务拆分成多个并行子任务,在分布式环境下高效处理大规模数据。虽然在如今 Spark、Flink 等新框架兴起后,MapReduce 的使用场景有所减少,但作为大数据处理的基石,理解它的执行原理仍然非常重要。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)