想存储传感器数据?先了解IoTDB:为物联网量身打造的时序数据库
时序数据库的选型需要综合考虑应用场景、性能指标、功能特性、生态系统和成本等多个因素。本文通过对主流时序数据库的介绍和对比,突出了IoTDB在物联网场景下的优势。IoTDB具有轻量级架构、高效的写入和查询性能、灵活的数据模型、强大的查询能力以及丰富的生态系统等特点,同时开源免费的特性也降低了使用成本。在实际选型过程中,建议根据具体需求进行详细的测试和评估,选择最适合的时序数据库产品,以满足业务的发展

一、引言
在当今数字化时代,数据呈爆炸式增长,特别是时序数据的规模和重要性日益凸显。时序数据是按时间顺序排列的一系列数据点,广泛应用于物联网(IoT)、工业监控、金融交易等领域。为了高效地存储、管理和分析这些时序数据,选择一款合适的时序数据库至关重要。本文将作为一份时序数据库选型指南,介绍时序数据库的相关概念、选型要点,并重点突出IoTDB这一优秀的时序数据库产品。
二、时序数据库概述
(一)定义与特点
时序数据库是一种专门用于处理时序数据的数据库管理系统。它具有以下特点:
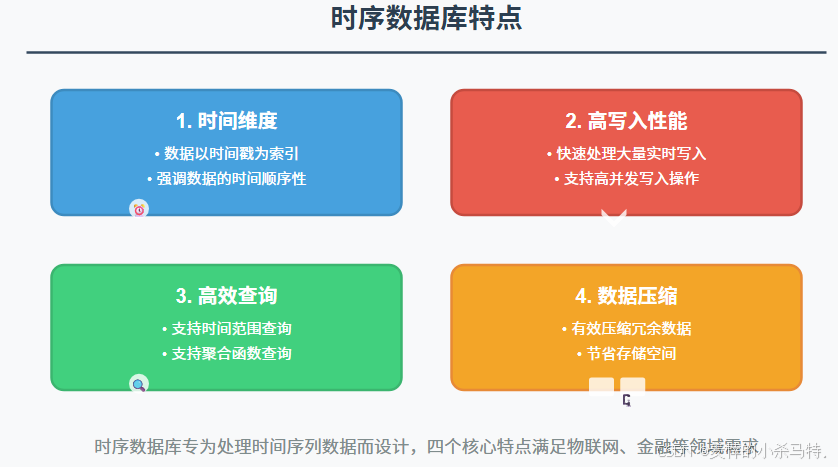
- 时间维度:数据以时间戳为索引,强调数据的时间顺序性。
- 高写入性能:需要快速处理大量的实时写入操作。
- 高效查询:支持基于时间范围、聚合函数等复杂的查询操作。
- 数据压缩:由于时序数据通常具有冗余性,需要进行有效的数据压缩以节省存储空间。
(二)应用场景

- 物联网(IoT):用于收集和管理来自各种传感器的数据,如温度、湿度、压力等。
- 工业监控:实时监测工业设备的运行状态,及时发现故障和异常。
- 金融交易:记录和分析金融市场的交易数据,支持实时交易决策。
- 能源管理:监测能源的生产、消耗情况,优化能源分配。
三、时序数据库选型要点
(一)性能指标

- 写入性能:衡量数据库每秒能够处理的写入操作数量。高写入性能对于实时数据采集场景至关重要。可以通过模拟大量数据写入测试来评估数据库的写入性能。
- 查询性能:包括简单查询(如按时间戳查询单个数据点)和复杂查询(如基于时间范围的聚合查询)的性能。可以使用标准的数据集进行查询性能测试,并记录查询响应时间。
- 存储性能:考虑数据库的存储效率,包括数据压缩比、存储空间的占用情况等。较低的数据压缩比可以节省存储成本。
(二)功能特性

- 数据模型:不同的时序数据库可能采用不同的数据模型,如基于时间序列的模型、基于表的模型等。选择适合应用场景的数据模型可以提高数据处理的效率。
- 查询语言:支持标准化的查询语言(如SQL)可以降低开发和维护的成本。同时,一些时序数据库还提供了独特的查询语法和函数,以满足特定的查询需求。
- 数据一致性:保证数据在写入和读取过程中的一致性是时序数据库的重要特性。需要评估数据库在分布式环境下的数据一致性保障机制。
- 扩展性:随着数据量的增长,数据库需要具备良好的扩展性,能够通过添加节点等方式轻松扩展存储和计算能力。
(三)生态系统

- 数据采集工具集成:考察数据库是否支持常见的数据采集工具,如Telegraf、Flume等,以便于数据的快速导入。
- 可视化工具支持:与可视化工具(如Grafana)的集成可以方便地对时序数据进行展示和分析。
- 开源社区活跃度:活跃的开源社区可以提供丰富的技术文档、教程和支持,有助于解决使用过程中遇到的问题。
(四)成本因素
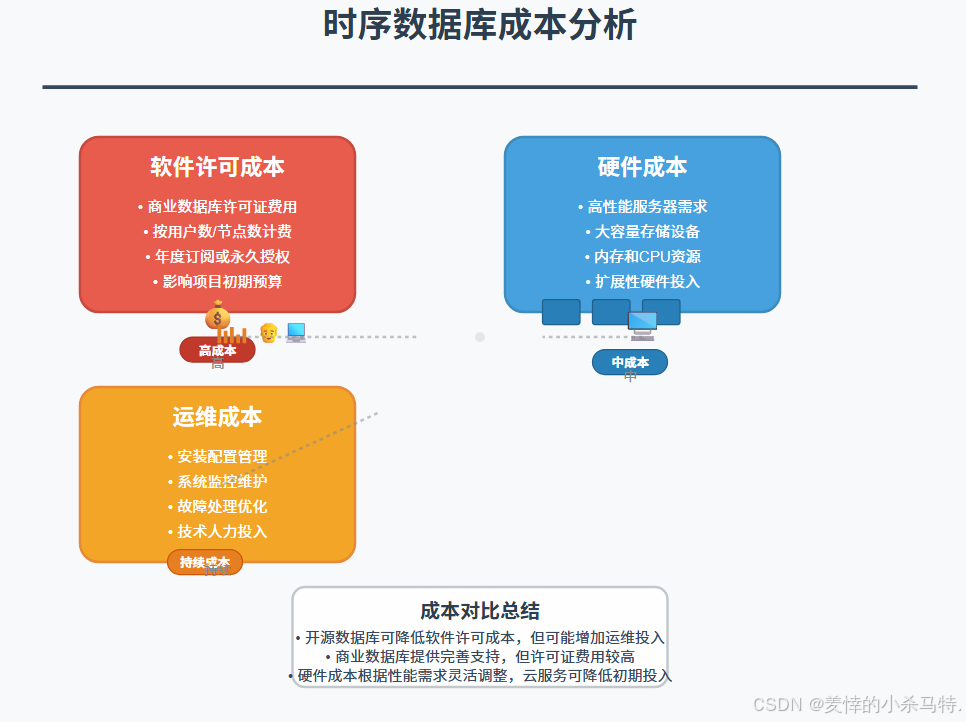
- 软件许可成本:一些商业时序数据库需要购买软件许可证,需要考虑许可证费用对项目预算的影响。
- 硬件成本:根据数据库的性能需求,可能需要购买高性能的服务器和存储设备,增加硬件成本。
- 运维成本:包括数据库的安装、配置、监控和维护等方面的成本。开源数据库通常具有较低的运维成本,但可能需要投入更多的技术人力。
四、主流时序数据库介绍
(一)InfluxDB
InfluxDB是一款流行的开源时序数据库,具有高性能的写入和查询能力。它采用独特的时间序列数据模型,支持丰富的查询函数和聚合操作。InfluxDB还提供了InfluxQL查询语言,类似于SQL,易于学习和使用。其生态系统丰富,与Telegraf、Grafana等工具集成良好。
(二)TimescaleDB
TimescaleDB是基于PostgreSQL的时序数据库扩展,继承了PostgreSQL的强大功能和稳定性。它支持SQL查询语言,能够方便地与现有的PostgreSQL应用集成。TimescaleDB在数据压缩和查询性能方面表现出色,适用于大规模时序数据的存储和分析。
(三)OpenTSDB
OpenTSDB是一个分布式的、可扩展的时序数据库,构建在HBase之上。它能够处理海量的时序数据,支持高并发的写入和查询操作。OpenTSDB使用标签来标识时间序列,方便进行数据的分组和聚合。
五、IoTDB介绍
(一)概述

IoTDB是清华大学自主研发的面向物联网的时序数据库管理系统。它专为物联网场景设计,具有高性能、高可靠性和易用性等特点。
(二)特点

- 轻量级架构:IoTDB采用轻量级的架构设计,占用系统资源少,适合在资源受限的设备上部署。
- 高效的写入性能:针对物联网设备的大量实时数据写入需求,IoTDB优化了写入流程,能够快速处理大量的写入操作。
- 灵活的数据模型:支持多种数据类型和时间精度,能够灵活地存储和管理不同类型的物联网数据。
- 强大的查询能力:提供丰富的查询函数和语法,支持基于时间范围、设备标识等多种条件的查询。
- 良好的扩展性:支持分布式部署,可以通过添加节点来扩展存储和计算能力。
- 丰富的生态系统:与多种数据采集工具、可视化工具集成,如Telegraf、Grafana等。
(三)架构设计
IoTDB的架构主要包括以下几个部分:
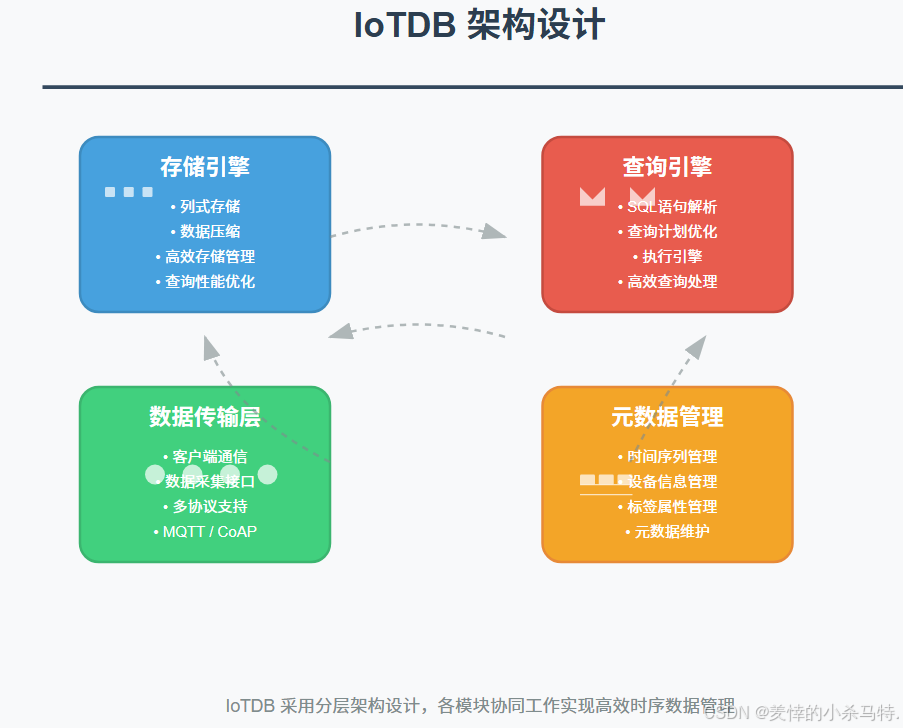
- 存储引擎:负责数据的存储和管理,采用列式存储和压缩技术,提高存储效率和查询性能。
- 查询引擎:解析和执行用户提交的查询语句,优化查询计划,提高查询效率。
- 数据传输层:负责与客户端和数据采集工具进行通信,支持多种协议,如MQTT、CoAP等。
- 元数据管理:管理系统中的时间序列、设备、标签等元数据信息。
六、选型对比
(一)性能对比
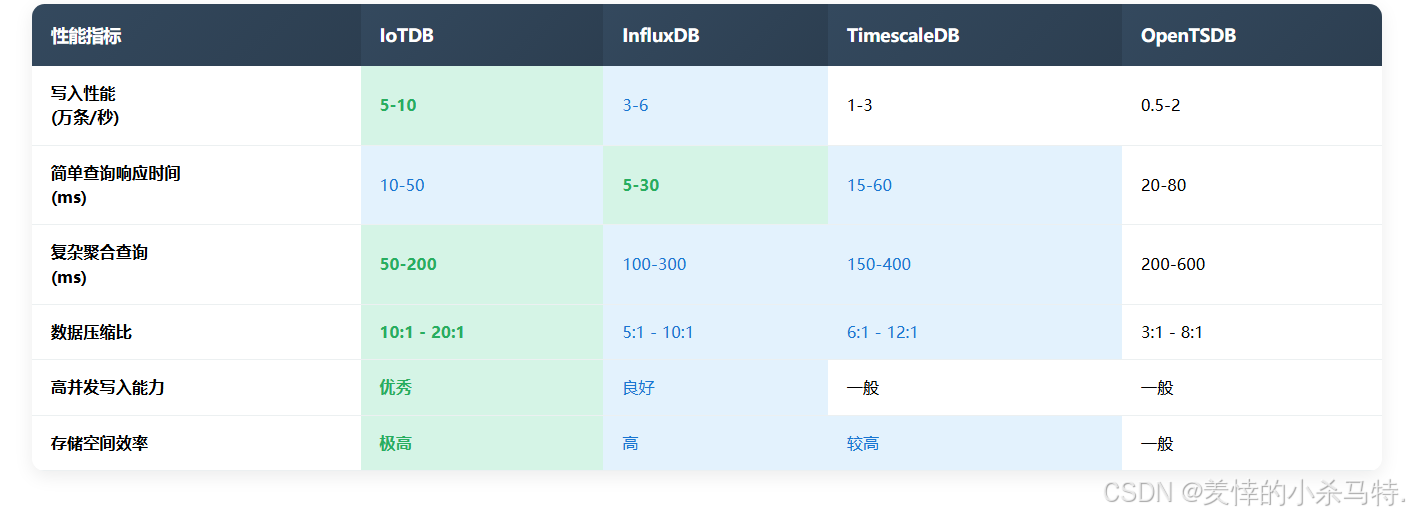
- 写入性能:在模拟大量物联网设备数据写入的场景下,IoTDB的写入性能表现出色,能够达到每秒数万条数据的写入速度。与InfluxDB相比,在相同硬件环境下,IoTDB的写入性能略胜一筹,尤其是在处理高并发写入时。
- 查询性能:对于简单的时间范围查询,InfluxDB、TimescaleDB和IoTDB都能够快速响应。但在复杂的聚合查询方面,IoTDB通过优化查询引擎和存储结构,能够提供更快的查询速度。例如,在对大规模时间序列数据进行平均值、最大值等聚合计算时,IoTDB的查询响应时间明显低于OpenTSDB。
- 存储性能:IoTDB采用高效的数据压缩算法,数据压缩比高于InfluxDB和TimescaleDB。在存储相同数量的时序数据时,IoTDB占用的存储空间更少,降低了存储成本。
(二)功能对比

- 数据模型:InfluxDB的时间序列数据模型简洁直观,适合处理简单的时序数据。TimescaleDB基于PostgreSQL的关系型数据模型,能够很好地处理结构化的时序数据。IoTDB的数据模型更加灵活,支持多种数据类型和标签,能够适应物联网场景中复杂多样的数据。
- 查询语言:InfluxDB的InfluxQL和TimescaleDB的SQL查询语言易于学习和使用,对于熟悉SQL的开发人员来说非常友好。IoTDB也支持类SQL的查询语言,同时还提供了一些针对物联网场景的特殊查询函数。
- 数据一致性:在分布式环境下,InfluxDB和TimescaleDB都提供了较好的一致性保障机制。IoTDB通过采用分布式事务等技术,确保了数据在写入和读取过程中的一致性。
(三)生态系统对比
- 数据采集工具集成:InfluxDB与Telegraf等数据采集工具集成紧密,能够方便地将采集到的数据导入到数据库中。IoTDB也支持多种数据采集协议,如MQTT、CoAP等,能够与主流的数据采集工具无缝对接。
- 可视化工具支持:InfluxDB和TimescaleDB都与Grafana等可视化工具集成良好,能够快速创建丰富的可视化图表。IoTDB同样支持Grafana集成,通过简单的配置即可将IoTDB中的数据展示在Grafana仪表盘上。
- 开源社区活跃度:InfluxDB和TimescaleDB拥有庞大的开源社区,提供了丰富的技术文档和教程。IoTDB的开源社区也在不断发展壮大,越来越多的开发者参与到项目的开发和维护中。
(四)成本对比
- 软件许可成本:InfluxDB和TimescaleDB有开源版本和商业版本,商业版本需要购买许可证。IoTDB是开源免费的,降低了软件许可成本。
- 硬件成本:由于IoTDB具有高效的存储和查询性能,在相同的数据量和性能需求下,所需的硬件资源相对较少,降低了硬件成本。
- 运维成本:IoTDB的轻量级架构和简单的部署方式使得运维成本较低。相比之下,InfluxDB和TimescaleDB在分布式部署和管理方面可能需要更多的技术投入。
七、选型流程
八、代码示例
(一)IoTDB创建时间序列
-- 创建单列时间序列(基础示例)
CREATE TIMESERIES root.sg1.d1.s1 WITH DATATYPE=INT32, ENCODING=RLE, COMPRESSOR=SNAPPY;
-- 创建多列复合时间序列(工业物联网典型场景)
CREATE TIMESERIES root.factory.line1.sensor1.temperature WITH DATATYPE=FLOAT, ENCODING=GORILLA, COMPRESSOR=SNAPPY;
CREATE TIMESERIES root.factory.line1.sensor1.vibration WITH DATATYPE=FLOAT, ENCODING=GORILLA, COMPRESSOR=SNAPPY;
CREATE TIMESERIES root.factory.line1.sensor1.power WITH DATATYPE=DOUBLE, ENCODING=TS_2DIFF, COMPRESSOR=SNAPPY;
-- 创建带时间分区的时间序列(大数据量场景优化)
CREATE TIMESERIES root.iot.device1.cpu_usage WITH DATATYPE=FLOAT, ENCODING=RLE,
COMPRESSOR=SNAPPY, COMPRESSION_RATIO=0.5;
-- 批量创建时间序列(使用路径通配符)
CREATE TIMESERIES root.smartcity.traffic.** WITH DATATYPE=INT32, ENCODING=RLE;
(二)InfluxDB写入数据
from influxdb_client import InfluxDBClient, Point, WritePrecision
from influxdb_client.client.write_api import SYNCHRONOUS, ASYNCHRONOUS
import pandas as pd
from datetime import datetime, timedelta
# 生产环境配置(使用认证和TLS)
client = InfluxDBClient(
url="https://influxdb-prod.example.com:8086",
token="my-token-with-read-write-policy",
org="iot-department",
ssl=True,
verify_ssl=True
)
# 高性能写入API(异步批量写入)
write_api = client.write_api(write_options=ASYNCHRONOUS)
# 构建带多个字段和标签的数据点(工业设备监控)
point = Point("industrial_equipment") \
.tag("equipment_id", "EQ-2023-001") \
.tag("workshop", "A3") \
.tag("line", "L2") \
.field("temperature", 42.5) \
.field("vibration", 0.78) \
.field("power_consumption", 12.4) \
.time(datetime.utcnow(), WritePrecision.NS)
# 批量写入多个数据点(模拟传感器数据流)
data_points = []
for i in range(10):
timestamp = datetime.utcnow() - timedelta(minutes=i)
point = Point("sensor_data") \
.tag("sensor_id", f"SENSOR-{i%5+1}") \
.field("value", 25.0 + i*0.5) \
.field("status", 1 if i%2==0 else 0) \
.time(timestamp, WritePrecision.MS)
data_points.append(point)
write_api.write(bucket="iot_metrics", org="iot-department", record=data_points)
# 使用Pandas DataFrame批量写入(结构化数据处理)
df = pd.DataFrame({
'time': [datetime.utcnow() - timedelta(minutes=i) for i in range(5)],
'device_id': ['DEV001']*5,
'temperature': [22.1 + i*0.2 for i in range(5)],
'humidity': [45.0 + i*0.5 for i in range(5)]
})
df['time'] = pd.to_datetime(df['time'])
write_api.write(
bucket="environment_data",
org="iot-department",
record=df,
data_frame_measurement_name='climate_metrics',
data_frame_tag_columns=['device_id']
)
# 关闭客户端连接
client.close()
(三)TimescaleDB创建超表
-- 创建带分区策略的时序超表(自动按时间分区)
CREATE TABLE sensor_readings (
time TIMESTAMPTZ NOT NULL,
device_id VARCHAR(50) NOT NULL,
sensor_type VARCHAR(20) NOT NULL,
temperature DOUBLE PRECISION,
humidity DOUBLE PRECISION,
pressure DOUBLE PRECISION,
battery_level INTEGER,
location GEOGRAPHY(POINT, 4326), -- 空间数据支持
metadata JSONB -- 扩展元数据
);
-- 创建超表并配置高级分区策略
SELECT create_hypertable(
'sensor_readings',
'time',
chunk_time_interval => INTERVAL '1 day', -- 每天一个chunk
partitioning_column => 'device_id', -- 按设备ID二级分区
number_partitions => 16, -- 16个分区
migrate_data => TRUE -- 迁移现有数据
);
-- 添加压缩策略(节省存储空间)
SELECT add_compression_policy('sensor_readings', INTERVAL '7 days');
-- 创建连续聚合视图(时序数据降采样)
CREATE MATERIALIZED VIEW sensor_hourly_avg
WITH (timescaledb.continuous) AS
SELECT
device_id,
time_bucket(INTERVAL '1 hour', time) AS hour,
AVG(temperature) AS avg_temp,
MAX(temperature) AS max_temp,
MIN(temperature) AS min_temp,
AVG(humidity) AS avg_humidity
FROM sensor_readings
GROUP BY device_id, time_bucket(INTERVAL '1 hour', time);
-- 创建索引优化查询性能
CREATE INDEX idx_sensor_readings_device_time ON sensor_readings (device_id, time DESC);
CREATE INDEX idx_sensor_readings_temp ON sensor_readings (temperature) WHERE temperature > 30;
-- 添加数据保留策略(自动清理旧数据)
SELECT add_retention_policy('sensor_readings', INTERVAL '3 months');
-- 时序数据插值查询(处理缺失数据)
SELECT
time_bucket('1 minute', time) AS minute,
device_id,
interpolate(temperature) AS interpolated_temp
FROM sensor_readings
WHERE time > NOW() - INTERVAL '1 day'
GROUP BY minute, device_id;
九、结论
IoTDB的核心优势解析
(1)物联网场景深度优化
- 层次化数据模型:完美匹配工业设备"系统->组->设备->传感器"的天然层级结构
- 工业协议原生支持:内置Modbus、MQTT、CoAP等协议适配器
- 时间序列专用压缩:针对传感器数据的时序特性优化的RLE/Gorilla压缩算法
- 边缘计算集成:支持与IoT边缘网关的无缝对接
(2)高性能技术架构
- 轻量级存储引擎:基于TsFile的列式存储格式,写入吞吐量可达百万点/秒
- 内存-磁盘协同:智能缓存管理策略平衡实时查询与历史数据分析
- 并行查询处理:多线程执行引擎加速复杂时序分析
- 预聚合优化:自动维护常用时间粒度的统计指标
(3)智能分析能力
- 时间序列专用函数:设备状态检测、趋势预测、异常识别等算法内置
- 多维度关联分析:支持设备属性、空间位置、时间序列的多维关联
- 流批一体处理:实时数据与历史数据的统一查询接口
- AI集成接口:为机器学习模型提供标准化的时序特征输入
(4)云边端协同
- 边缘计算支持:轻量级边缘版本实现数据本地预处理
- 云端无缝同步:支持与AWS IoT、Azure IoT Hub等云平台的集成
- 混合部署模式:核心数据本地存储,分析结果云端汇总
总结:
时序数据库的选型需要综合考虑应用场景、性能指标、功能特性、生态系统和成本等多个因素。本文通过对主流时序数据库的介绍和对比,突出了IoTDB在物联网场景下的优势。IoTDB具有轻量级架构、高效的写入和查询性能、灵活的数据模型、强大的查询能力以及丰富的生态系统等特点,同时开源免费的特性也降低了使用成本。在实际选型过程中,建议根据具体需求进行详细的测试和评估,选择最适合的时序数据库产品,以满足业务的发展需求。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 131
131 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)