【序列晋升】42 Spring Data Apache Cassandra 简化分布式NoSQL数据库的Spring应用开发
Apache Cassandra是一种高性能的分布式NoSQL数据库,而Spring Data for Apache Cassandra则是Spring Data家族的重要成员,旨在为Java开发者提供简化Cassandra操作的抽象层。它通过熟悉的Spring概念(如模板类和仓库接口)降低学习曲线,使开发者能够专注于业务逻辑而非底层数据库细节。
目录
1. 什么是Spring Data for Apache Cassandra?
6.1 Spring Data MongoDB vs Spring Data Cassandra
Apache Cassandra是一种高性能的分布式NoSQL数据库,而Spring Data for Apache Cassandra则是Spring Data家族的重要成员,旨在为Java开发者提供简化Cassandra操作的抽象层。它通过熟悉的Spring概念(如模板类和仓库接口)降低学习曲线,使开发者能够专注于业务逻辑而非底层数据库细节。本文将从概念、架构、核心特性、使用场景到配置步骤,全面解析Spring Data for Apache Cassandra的技术价值与实践应用。

1. 什么是Spring Data for Apache Cassandra?
Spring Data for Apache Cassandra是Spring Data框架的一部分,专门用于简化Java应用与Apache Cassandra数据库之间的交互。它通过提供高级抽象,如CassandraTemplate和ReactiveCassandraTemplate操作类,以及基于接口的CassandraRepository仓库抽象,将Cassandra的CQL(Cassandra Query Language)操作封装为更符合Java开发者习惯的API。这种设计使得开发者无需深入理解Cassandra的底层机制,即可高效地进行数据操作。
在传统Cassandra开发中,开发者需要直接使用DataStax Java驱动编写CQL语句并处理结果集,这不仅增加了开发复杂度,还容易引入错误。Spring Data for Apache Cassandra通过对象关系映射(ORM)机制,将Java对象自动映射到Cassandra表,同时提供类型安全的查询构建器和异常转换功能,显著提升了开发效率和代码可维护性。
2. 诞生背景
Spring Data for Apache Cassandra的诞生源于两个关键背景:
首先,NoSQL数据库的兴起与普及。随着互联网应用规模的扩大,传统关系型数据库在处理海量数据和高并发场景时面临性能瓶颈。Apache Cassandra作为一种分布式NoSQL数据库,以其高可用性、可扩展性和高性能特点,成为处理大规模数据的理想选择。然而,Cassandra的学习曲线较陡峭,特别是对于习惯于关系型数据库开发的Java开发者来说,需要掌握CQL语言和分布式数据模型的概念。
其次,Spring生态系统的成熟与扩展需求。Spring框架已成为Java开发的事实标准,其数据访问层抽象(如JPA、JDBC)大大简化了与关系型数据库的交互。随着NoSQL数据库的普及,Spring Data项目应运而生,旨在为不同类型的数据库提供一致的编程模型。Apache Cassandra作为重要的NoSQL数据库,自然成为Spring Data支持的目标。
Spring Data for Apache Cassandra的初始版本约发布于2012年,与Cassandra 1.x版本对应。随着时间推移,Cassandra不断演进,Spring Data也持续更新,以支持最新的Cassandra特性和Spring生态系统的集成。目前最新稳定版本为2.2.0 GA,而Spring Data 2025.0.0 GA版本则支持Cassandra 5的新特性,如向量类型和附加索引。
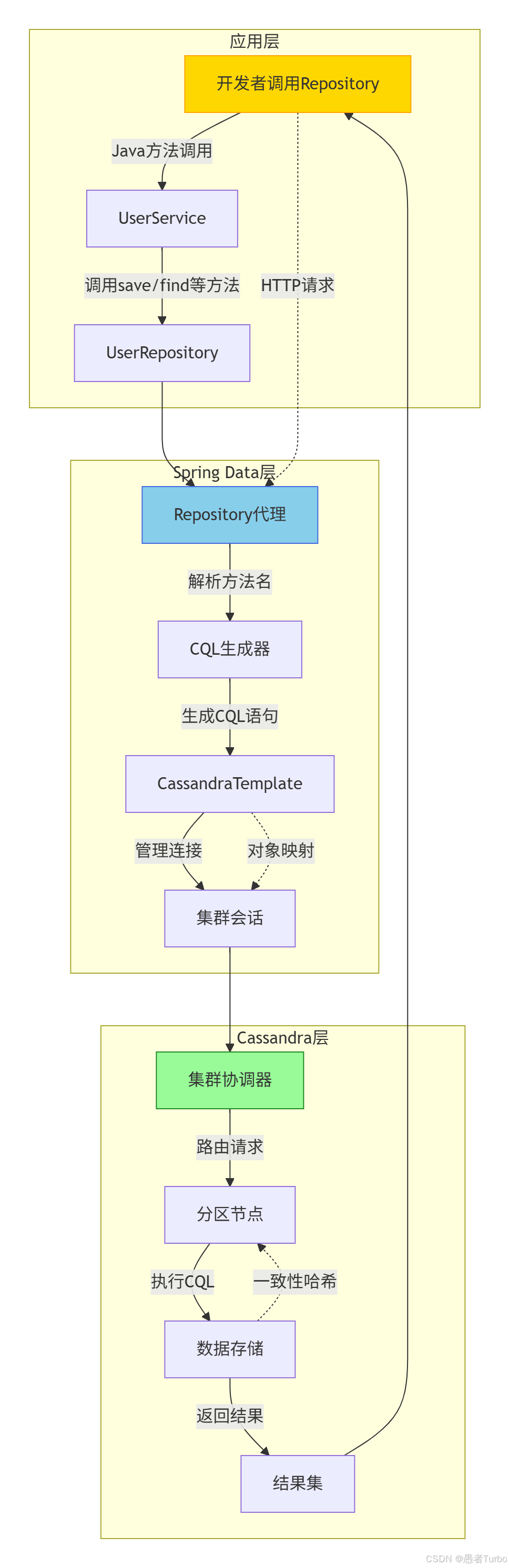
3. 架构设计
Spring Data for Apache Cassandra采用分层架构设计,将复杂的数据访问操作封装为简洁的API。其架构可分为以下几个层次:
3.1 应用层
应用层是开发者直接交互的部分,包含业务逻辑和服务类。开发者通过注入CassandraRepository或ReactiveCassandraRepository接口来执行数据操作,这些接口提供了基本的CRUD方法,如save()、findById()、findAll()等。
3.2 抽象层
抽象层是Spring Data的核心,包含以下几个关键组件:
-
CassandraTemplate/ReactiveCassandraTemplate:封装了Cassandra驱动API,提供类型安全的数据操作方法。
CassandraTemplate用于同步操作,而ReactiveCassandraTemplate则支持响应式非阻塞操作。 -
CassandraRepository/ReactiveCassandraRepository:基于Spring Data的仓库抽象,自动实现CRUD方法,并支持自定义查询方法。
-
CassandraMappingContext/CassandraConverter:负责实体类与Cassandra表之间的映射关系解析和数据转换。通过反射机制和注解处理,将Java对象属性映射到Cassandra表的列。
3.3 驱动层
驱动层直接依赖DataStax CQL Java驱动(版本4.x+),负责底层网络通信和会话管理。Spring Data for Apache Cassandra完全采用DataStax驱动,确保与Cassandra数据库的良好兼容性。
3.4 配置层
配置层负责管理Cassandra连接参数和驱动配置。支持XML配置和JavaConfig两种方式,通过CassandraCluster定义集群连接点,通过CassandraSession管理会话,并通过CassandraMapping和CassandraConverter配置实体映射。
4. 解决的问题
Spring Data for Apache Cassandra主要解决了以下几个问题:
4.1 降低Cassandra原生API的学习曲线
Cassandra的CQL语言和分布式数据模型与传统关系型数据库有很大不同,需要开发者掌握新的概念和语法。Spring Data通过以下方式简化了学习过程:
- 提供基于注解的实体映射,无需手动编写CQL语句
- 提供类型安全的查询构建器,减少CQL语法错误
- 自动转换Cassandra异常为Spring通用异常,便于统一处理
4.2 提供与Spring生态的无缝集成
Spring Data for Apache Cassandra深度集成Spring生态系统,支持以下功能:
- 与Spring Boot Starter自动配置集成,简化项目初始化
- 支持Spring Data的通用仓库抽象,提供一致的编程模型
- 与Spring事务管理器集成,支持事务控制
- 与Spring Security集成,支持安全认证
4.3 支持多种数据操作模式
Spring Data for Apache Cassandra支持同步、异步和响应式三种数据操作模式,满足不同应用场景的需求:
| 操作模式 | 核心类 | 返回类型 | 适用场景 |
|---|---|---|---|
| 同步 | CassandraTemplate |
void、List、Optional |
简单查询、更新操作 |
| 异步 | AsyncCassandraTemplate |
ListenableFuture |
非阻塞、高并发场景 |
| 响应式 | ReactiveCassandraTemplate |
Flux、Mono |
流式处理、微服务架构 |
4.4 简化对象映射和类型转换
Cassandra支持多种数据类型(如时间戳、UUID、集合、用户定义类型等),而Java对象与Cassandra数据类型的映射可能比较复杂。Spring Data通过以下方式简化了这一过程:
- 提供基于注解的实体映射机制
- 支持自定义转换器(
Converter),处理特殊类型转换 - 提供
@ReadingConverter和@WritingConverter注解,明确转换方向 - 内置JSR-310时间类型转换器,简化日期处理
5. 关键特性
Spring Data for Apache Cassandra提供了丰富的功能特性,使其成为Java开发者访问Cassandra的理想选择:
5.1 基于注解的实体映射
Spring Data for Apache Cassandra通过注解将Java实体类映射到Cassandra表:
@Table:标注在实体类上,指定对应的Cassandra表名@PrimaryKey:标注在主键字段或主键类上,标识主键@PrimaryKeyColumn:用于复合主键,指定分区键和聚类键@Column:指定属性与表列的映射关系,可自定义列名和数据类型@SecondaryIndex:在实体属性上创建二级索引,提高查询效率
5.2 查询构建器(QueryBuilders)
Spring Data提供了QueryBuilders和 Criteria API,允许开发者以类型安全的方式构建Cassandra查询:
// 创建查询条件
Query query = Query.query(Criteria.where("age").greaterThan(30));
// 执行查询
List<User> users = cassandraTemplate.query(query, User.class);5.3 自动实现的仓库接口
开发者只需定义继承自CassandraRepository的接口,Spring Data会自动实现其中的方法:
public interface UserRepository extends CassandraRepository<User, Long> {
List<User> findByAge GreaterThan(int age);
}5.4 异常转换
将Cassandra驱动的异常转换为Spring通用的DataAccessException层次结构,便于统一处理:
try {
cassandraTemplate.insert(user);
} catch (DataAccessException e) {
// 统一处理异常
log.error("Insert failed", e);
}5.5 响应式编程支持
通过ReactiveCassandraTemplate和ReactiveCassandraRepository提供非阻塞、响应式数据访问:
// 响应式插入
Mono<User> mono = reactiveCassandraTemplate.insert(user);
// 响应式查询
Flux<User> flux = reactiveCassandraTemplate.query(User.class)
.where("age").greaterThan(30)
.all();5.6 与云服务集成
Spring Data for Apache Cassandra支持与云服务(如Azure Cosmos DB for Apache Cassandra API)的集成,提供云环境下的特殊配置和优化。
6. 与同类产品对比
6.1 Spring Data MongoDB vs Spring Data Cassandra
| 特性 | Spring Data MongoDB | Spring Data Cassandra |
|---|---|---|
| 数据模型 | 文档模型 | 宽列模型 |
| 查询语言 | MongoDB查询语言 | CQL(类SQL) |
| 扩展性 | 垂直扩展为主 | 水平扩展为主 |
| 一致性模型 | 可选强一致性 | 最终一致性 |
| 适用场景 | 复杂结构数据、文档存储 | 高吞吐量写入、时间序列数据、水平扩展 |
Spring Data Cassandra的优势在于其分布式架构和高吞吐量写入能力,适合处理大规模数据和高并发场景。而Spring Data MongoDB则在文档模型和查询灵活性方面更具优势。
6.2 与原生Cassandra驱动对比
| 特性 | 原生Cassandra驱动 | Spring Data Cassandra |
|---|---|---|
| 学习曲线 | 较陡峭,需掌握CQL和驱动API | 较平缓,提供类型安全的API |
| 代码量 | 较大,需手动处理连接和结果集 | 较小,通过仓库接口自动生成实现 |
| 异常处理 | 需手动处理驱动异常 | 自动转换为Spring通用异常 |
| 对象映射 | 需手动实现 | 自动映射,支持注解配置 |
Spring Data Cassandra的核心优势在于其抽象层和与Spring生态的深度集成,显著降低了开发复杂度,提高了代码可维护性。
7. 使用方法
7.1 项目搭建
7.1.1 创建Spring Boot项目
使用Spring Initializr创建新项目,添加以下依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-cassandra</artifactId>
</dependency>7.1.2 配置Cassandra连接
在application.properties中配置Cassandra连接参数:
spring.data.cassandra接触点=127.0.0.1
spring.data.cassandra.port=9042
spring.data.cassandra.keyspace-name=my_keyspace
spring.data.cassandra当地数据中心=datacenter1
spring.data.cassandra username=cassandra
spring.data.cassandra password=cassandra
spring.data.cassandra schema-action(create-if-not-exists)=create-if-not-exists对于AzureCosmosDB,配置如下:
spring.data.cassandra接触点=wingtiptoyscassandra.cassandra.cosmos azure.com
spring.data.cassandra.port=10350
spring.data.cassandra username=wingtiptoyscassandra
spring.data.cassandra password=********7.1.3 定义实体类
使用注解定义与Cassandra表对应的实体类 :
@Table("users")
public class User {
@PrimaryKey
private String id;
@Column("first_name")
private StringfirstName;
@Column("last_name")
private String lastName;
@Column
private int age;
// Getters and Setters
}对于复合主键,需定义主键类:
@PrimaryKeyClass
public class PersonKey {
@PrimaryKeyColumn(name = "id", ordinal = 0, type = PrimaryKeyType.PARTITIONED)
private String id;
@PrimaryKeyColumn(name = "name", ordinal = 1, type = PrimaryKeyType CLUSTERED)
private String name;
// Getters and Setters
}
@Table("person")
public class Person {
@PrimaryKey
private PersonKey key;
@Column
private int age;
// Getters and Setters
}7.1.4 创建仓库接口
定义继承自CassandraRepository的接口:
public interface UserRepository extends CassandraRepository<User, String> {
List<User> findByAge GreaterThan(int age);
Optional<User> findByFirstName(StringfirstName);
}7.2 数据操作
7.2.1 同步操作
使用CassandraTemplate进行同步数据操作:
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public User saveUser(User user) {
return userRepository.save(user);
}
public User getUserById(String id) {
return userRepository.findById(id).orElse(null);
}
public List<User> getUsersByAge(int age) {
return userRepository.findByAge GreaterThan(age);
}
}7.2.2 响应式操作
使用ReactiveCassandraRepository进行响应式数据操作:
@Service
public class ReactiveUserService {
@Autowired
private ReactiveUserRepository reactiveUserRepository;
public Mono<User> saveUserReactive(User user) {
return reactiveUserRepository.save(user);
}
public Mono<User> getUserByIdReactive(String id) {
return reactiveUserRepository.findById(id);
}
public Flux<User>榜次getUsersByAgeReactive(int age) {
return reactiveUserRepository.findByAge GreaterThan(age);
}
}7.3 查询构建
使用QueryBuilders构建复杂查询:
// 创建查询条件
Query query = Query.query(Criteria.where("age").greaterThan(30))
.withPageable(Pageable.ofSize(10));
// 执行查询
List<User> users = cassandraTemplate.query(query, User.class);7.4 异常处理
Spring Data自动将Cassandra驱动异常转换为Spring通用异常:
try {
cassandraTemplate.insert(user);
} catch (DataAccessException e) {
// 处理异常
log.error("Insert failed", e);
}8. 最佳实践
8.1 数据建模优化
Cassandra的数据模型与传统关系型数据库有很大不同,应遵循以下最佳实践:
- 合理设计分区键:确保分区键能够均匀分布数据,避免热点问题
- 避免二级索引滥用:仅在低基数字段上使用二级索引,优先通过设计合理的分区键和聚类键进行查询
- 使用时间戳分片:对于时间序列数据,使用时间戳作为分区键或聚类键,便于数据分片和查询优化
8.2 性能优化
为提高应用性能,应考虑以下优化策略:
- 连接池配置:根据应用负载配置合适的连接池大小和超时时间
- 一致性级别设置:根据业务需求选择适当的一致性级别,平衡性能和数据一致性
- 批处理操作:使用批处理API提高写入性能
- 预编译语句缓存:优化预编译语句缓存策略,减少重复编译开销
8.3 云环境配置
在云环境(如AzureCosmosDB)中使用Spring Data Cassandra时,应注意以下配置:
- 使用云特定端口:如AzureCosmosDB的Cassandra API使用端口10350
- 认证信息配置:配置云服务提供的用户名和密码
- 多数据中心策略:根据业务需求配置多数据中心策略,提高数据可用性和容错性
- 自动创建密钥空间和表:通过
schema-action(create-if-not-exists)参数自动创建密钥空间和表
9. 应用场景
9.1 高并发日志存储
Cassandra的高吞吐量写入特性使其成为日志存储的理想选择。Spring Data简化了数据建模和写入操作,使开发者能够专注于日志分析和查询。
9.2 实时分析系统
对于需要实时分析大规模数据的场景,Cassandra的列式存储和分区机制提供了高效的数据访问。Spring Data的响应式支持使应用能够处理流式数据,提高实时分析性能。
9.3 多数据中心应用
对于需要跨地域部署的应用,Cassandra的分布式架构提供了天然的优势。Spring Data的云集成配置使应用能够轻松连接到不同地域的Cassandra集群,实现数据同步和读写分离。
9.4 时序数据存储
Cassandra的时间戳分片机制使其成为时序数据存储的理想选择 。Spring Data简化了时间序列数据的建模和查询,使开发者能够专注于数据分析和可视化。
10. 未来发展趋势
10.1 云原生支持增强
随着云服务的普及,Spring Data for Apache Cassandra将增强对云原生特性的支持,如自动扩缩容、多区域写入优化等。
10.2 向量搜索与AI集成
Cassandra 5引入了向量类型和向量搜索功能,Spring Data将提供对这些新特性的支持,使应用能够轻松集成机器学习和推荐系统。
10.3 响应式与协程优化
随着响应式编程和协程的普及,Spring Data将进一步优化响应式操作,提供更高效的非阻塞数据访问。
10.4 生态扩展与统一抽象
Spring Data可能引入更多NoSQL数据库的统一抽象,或增强与Spring Cloud组件的协作,使分布式应用开发更加便捷。
11. 总结
Spring Data for Apache Cassandra是Java开发者访问Cassandra数据库的理想选择,它通过熟悉的Spring概念降低了学习曲线,提供了与Spring生态的深度集成,支持多种数据操作模式,并简化了对象映射和类型转换。
在实际应用中,Spring Data for Apache Cassandra特别适合高并发写入、时序数据存储和水平扩展需求的场景。通过合理设计数据模型、优化查询和配置参数,可以充分发挥Cassandra的性能优势。
随着云原生技术的发展和响应式编程的普及,Spring Data for Apache Cassandra将继续演进,提供更强大的功能和更便捷的使用体验,帮助开发者构建高性能、可扩展的分布式应用。
参考资料:
本博客专注于分享开源技术、微服务架构、职场晋升以及个人生活随笔,这里有:
📌 技术决策深度文(从选型到落地的全链路分析)
💭 开发者成长思考(职业规划/团队管理/认知升级)
🎯 行业趋势观察(AI对开发的影响/云原生下一站)
关注我,每周日与你聊“技术内外的那些事”,让你的代码之外,更有“技术眼光”。
日更专刊:
🥇 《Thinking in Java》 🌀 java、spring、微服务的序列晋升之路!
🏆 《Technology and Architecture》 🌀 大数据相关技术原理与架构,帮你构建完整知识体系!

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐
 50
50 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)