【序列晋升】44 Spring Data Couchbase:云原生架构中的文档数据库集成新思路
Spring Data Couchbase是Spring生态系统中专为Couchbase NoSQL文档数据库设计的抽象层,它通过统一的编程模型和简化API,显著降低了分布式文档数据库的集成难度。
目录
6.1 Spring Data MongoDB vs Spring Data Couchbase
6.2 Spring Data Redis vs Spring Data Couchbase
Spring Data Couchbase是Spring生态系统中专为Couchbase NoSQL文档数据库设计的抽象层,它通过统一的编程模型和简化API,显著降低了分布式文档数据库的集成难度。 本文将深入剖析这一技术的背景、架构、核心特性和实际应用场景,帮助Java开发者全面掌握如何利用Spring Data简化Couchbase的使用。

1. 什么是Spring Data Couchbase?
Spring Data Couchbase是Spring Data项目的一个子模块,旨在为Java开发者提供与Couchbase NoSQL文档数据库交互的便捷方式。它位于Spring框架和Couchbase数据库之间,通过提供基于Spring的编程模型,使开发者能够以熟悉的Spring风格操作Couchbase,而无需深入理解底层SDK的细节。
Spring Data的核心理念是"声明式数据访问",即开发者只需声明需要的方法,而无需编写实现。 如,只需定义一个名为"findByEmail"的方法,Spring Data会自动生成实现该查询的代码,而无需手动编写N1QL查询语句或处理SDK的复杂API。
在传统NoSQL开发中,开发者需要直接使用Couchbase SDK,处理vBucket分片、集群路由、查询构建等复杂任务。而Spring Data简化了这一过程,提供了更高级别的抽象,使开发者能够专注于业务逻辑而非数据访问细节。
2. 诞生背景
2.1 NoSQL的兴起与挑战
随着互联网应用的快速发展,传统关系型数据库在处理非结构化数据和高并发场景时遇到了瓶颈。NoSQL数据库因其灵活性、可扩展性和高性能而受到欢迎,但不同的NoSQL数据库(如MongoDB、Redis、Cassandra等)提供了不同的数据模型和查询方式,这增加了开发复杂度。
Couchbase作为一种高性能、可扩展的NoSQL文档数据库,结合了键值存储的速度和文档数据库的灵活性,但其SDK的使用仍然需要开发者掌握特定的API和查询语言(N1QL)。Spring Data的目标是为各种数据存储提供统一的编程模型,降低开发门槛,提高开发效率。
2.2 Spring Data的演进
Spring Data项目始于2010年,最初是为了简化JPA(Java Persistence API)的使用。随着NoSQL数据库的普及,Spring Data扩展了对多种NoSQL数据库的支持,包括MongoDB、Redis、Cassandra等。Spring Data通过提供统一的Repository接口、查询方法解析和对象映射机制,使开发者能够以一致的方式操作不同的数据存储。
Couchbase作为NoSQL领域的领先产品,其与Spring Data的整合成为自然选择。Spring Data Couchbase于2011年首次发布,旨在为Java开发者提供更简洁的Couchbase集成方式。 随着Couchbase功能的不断丰富(如N1QL查询语言、ACID事务支持),Spring Data也在持续更新,以更好地支持这些新特性。
3. 架构设计
3.1 核心组件
Spring Data Couchbase的架构主要包含以下组件:
| 组件 | 描述 | 作用 |
|---|---|---|
CouchbaseTemplate |
底层操作类,封装了Couchbase SDK的功能 | 提供基本的文档操作(如存取、查询),支持对象与JSON文档的映射 |
CouchbaseRepository |
基于Spring Data Repository模式的接口 | 提供声明式查询方法,支持命名规则查询和自定义N1QL查询 |
Document注解 |
标记Java类为Couchbase文档 | 定义文档的结构、ID和字段映射 |
@Query注解 |
定义自定义N1QL查询 | 支持复杂查询,如JOIN、子查询等 |
PagingAndSortingRepository |
支持分页和排序的接口 | 提供分页查询功能,结合Pageable参数使用 |
3.2 架构分层
Spring Data Couchbase采用典型的分层架构设计:
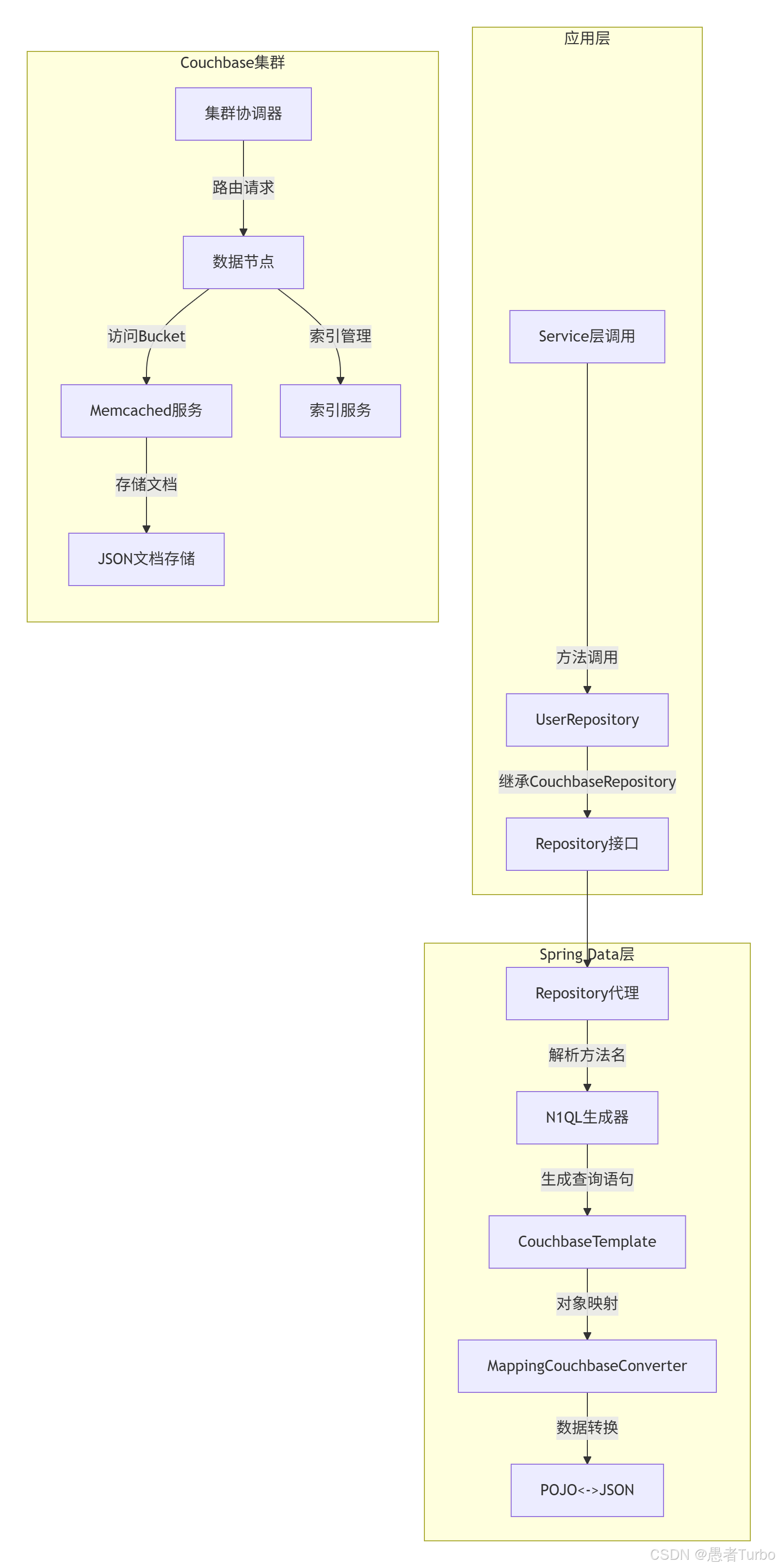
这种分层设计使得开发者能够专注于业务逻辑,而无需关心底层SDK的实现细节。 应用层通过@Service调用@Repository接口,Repository接口由Spring Data自动实现,Spring Data通过Couchbase SDK与Couchbase Server交互。
3.3 查询执行流程
当开发者调用一个查询方法时,Spring Data会执行以下流程:
- 方法解析:解析方法名或
@Query注解中的N1QL语句 - 参数绑定:将方法参数绑定到查询语句
- 查询生成:生成完整的N1QL查询
- SDK调用:通过Couchbase SDK执行查询
- 结果映射:将查询结果映射为Java对象
Spring Data自动处理了vBucket分片路由和集群拓扑变化,开发者无需手动维护这些复杂的分布式细节。
4. 解决的问题
4.1 降低SDK使用复杂度
直接使用Couchbase SDK需要处理vBucket分片、集群路由、查询构建等复杂任务。Spring Data通过Repository接口和CouchbaseTemplate封装了这些细节,使开发者能够以声明式方式编写查询,大大简化了开发流程。
直接使用SDK查询文档需要编写:
Bucket bucket = cluster.openBucket("my_bucket");
JsonDocument doc = bucket.get("user_1001");而使用Spring Data只需:
User user = userRepository.findById("user_1001").orElse(null);4.2 简化查询构建
Couchbase的N1QL查询语言虽然强大,但构建复杂查询(如JOIN、子查询)需要编写大量SQL-like语句。Spring Data提供了基于方法名的查询解析机制,使开发者能够通过命名约定自动生成查询,无需手动编写N1QL。
以下方法会自动生成N1QL查询:
List<User> findByEmailAndAgeLessThan(String email, int maxAge);4.3 提供统一的编程模型
Spring Data为各种数据存储提供了统一的编程模型,使开发者能够在不同数据存储之间无缝切换。通过继承CouchbaseRepository接口,开发者可以使用与Spring Data JPA或MongoDB相似的API,降低了学习成本。
4.4 支持事务管理
Couchbase 7.0+引入了ACID事务支持,Spring Data通过@Transactional注解简化了事务管理,使开发者能够像使用关系型数据库一样处理事务。
5. 关键特性
5.1 声明式Repository
Spring Data的核心特性是声明式Repository模式,开发者只需声明需要的方法,而无需编写实现。
public interface UserRepository extends CouchbaseRepository<User, String> {
User findByEmail(String email);
}Spring Data会自动生成实现类,执行相应的N1QL查询。
5.2 自动查询方法解析
Spring Data能够解析方法名并生成相应的N1QL查询。
List<User> findByNameStartingWithAndAgeLessThan(String namePrefix, int maxAge);会解析为:
SELECT * FROM `my_bucket` WHERE name LIKE 'namePrefix%' AND age < maxAge;5.3 N1QL查询支持
Spring Data支持通过@Query注解直接编写N1QL查询,使开发者能够利用Couchbase强大的查询能力:
public interface UserRepository extends CouchbaseRepository<User, String> {
@Query("SELECT * FROM `my_bucket` WHERE type = 'user' AND country = $1")
List<User> findByCountry(String country);
}5.4 分页与排序
Spring Data提供了PagingAndSortingRepository接口,支持分页和排序:
public interface UserRepository extendsouchbasePagingAndSortingRepository<User, String> {
}
// 使用
Pageable pageable = PageRequest.of(0, 10);
Page<User> users = userRepository.findAll(pageable);5.5 事务支持
Spring Data支持ACID事务,通过@Transactional注解实现:
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
@Transactional
public User updateUserEmail(String userId, String newEmail) {
User user = userRepository.findById(userId).orElse(null);
if (user != null) {
usergetEmail() = newEmail;
userRepository.save(user);
}
return user;
}
}5.6 缓存集成
Spring Data可以与Spring Cache集成,通过@Cacheable注解缓存查询结果:
@Service
@EnableCaching
public class UserService {
@Autowired
private UserRepository userRepository;
@Cacheable(value = "users", key = "#email")
public User getUserbyEmail(String email) {
return userRepository.findByEmail(email);
}
}6. 与同类产品对比
6.1 Spring Data MongoDB vs Spring Data Couchbase
| 特性 | Spring Data MongoDB | Spring Data Couchbase | 优势 |
|---|---|---|---|
| 数据模型 | 文档模型 | 文档+键值混合模型 | 提供更灵活的数据访问方式 |
| 查询语言 | MongoDB查询语言 | N1QL(SQL-like) | 更接近关系型数据库开发者习惯 |
| 性能 | 适合文档操作 | 内存优先,性能更高 | 提供更快的读写速度 |
| 分布式 | 需要手动处理分片 | 自动处理vBucket分片路由 | 更简单的分布式开发体验 |
| 事务支持 | 最终一致性 | ACID事务(7.0+) | 提供更强的数据一致性保证 |
6.2 Spring Data Redis vs Spring Data Couchbase
| 特性 | Spring Data Redis | Spring Data Couchbase | 优势 |
|---|---|---|---|
| 数据持久化 | 通常不持久化 | 内存+磁盘持久化 | 提供更好的数据可靠性 |
| 数据模型 | 键值对 | JSON文档 | 支持更复杂的数据结构 |
| 查询能力 | 有限的查询功能 | 强大的N1QL查询 | 提供更灵活的数据检索方式 |
| 缓存集成 | 内置缓存功能 | 可作为缓存后端使用 | 提供更统一的缓存管理 |
| 高可用性 | 需要额外配置 | 内置高可用性和自动故障转移 | 更简单的高可用性实现 |
7. 使用方法
7.1 基础配置
首先需要添加Spring Data Couchbase依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-couchbase</artifactId>
</dependency>然后配置连接信息:
spring.couchbase.bootstrap-hosts=localhost
spring.couchbase bucket.name=my_bucket
spring.couchbase bucket.password=
spring.couchbase envreplica-number=1
spring.couchbase envtimeouts connect=3000
spring.couchbase envtimeouts kv=20007.2 实体定义
使用@Document注解标记实体类:
@Document
public class User {
@Id
private String id;
private String name;
private String email;
private int age;
// getters and setters
}7.3 定义Repository接口
继承CouchbaseRepository接口,定义查询方法:
public interface UserRepository extendsouchbaseRepository<User, String> {
User ByEmail(String email);
List<User> findByNameStartingWith(String namePrefix);
@Query("SELECT * FROM `my_bucket` WHERE type = 'user' AND country = $1")
List<User> ByCountry(String country);
}7.4 使用Repository接口
在服务层注入并使用Repository:
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public User getUserById(String userId) {
return userRepository.findById(userId).orElse(null);
}
public List<User>用户的按国家查询(String country) {
return userRepository.findByCountry(country);
}
@Transactional
public User updateUserEmail(String userId, String newEmail) {
User user = userRepository.findById(userId).orElse(null);
if (user != null) {
user pdateEmail(newEmail);
userRepository.save(user);
}
return user;
}
}7.5 复杂查询示例
使用N1QL JOIN查询关联文档:
public interface OrderRepository extendsouchbaseRepository<Order, String> {
@Query("SELECT o.* FROM `my_bucket` o JOIN `my_bucket` u ON o userId = u.id WHERE u country = $1")
List<Order> findOrdersByUserCountry(String country);
}7.6 缓存集成示例
与Spring Cache集成,缓存查询结果:
@Service
@EnableCaching
public class UserService {
@Autowired
private UserRepository userRepository;
@Cacheable(value = "users", key = "#country")
public List<User> ByCountryWithCache(String country) {
return userRepository.findByCountry(country);
}
@CacheEvict(value = "users", key = "#user country")
public void evictUserCache(User user) {
// 清除缓存
}
}8. 最佳实践与架构建议
8.1 数据建模最佳实践
在Couchbase中,数据模型应尽量避免频繁的JOIN操作,因为JOIN虽然在N1QL中支持,但会降低查询性能。建议采用以下策略:
- 嵌入式文档:将频繁一起访问的数据嵌入到同一个文档中
- 反规范化设计:在读多写少的场景下,可以适当反规范化数据
- 文档类型标识:在文档中添加
type字段标识文档类型 - 使用视图或N1QL:根据查询需求选择合适的查询方式
8.2 查询优化策略
有效的查询优化是提高Couchbase性能的关键,建议采取以下策略:
- 创建合适的索引:为频繁查询的字段创建二级索引
- 使用覆盖索引:在索引中包含查询所需的所有字段,避免访问文档
- 限制查询结果:使用
LIMIT和OFFSET限制返回结果数量 - 使用参数化查询:避免SQL注入,提高查询性能
- 避免全表扫描:使用索引优化查询,减少全表扫描
8.3 集群配置建议
合理的集群配置可以充分发挥Couchbase的性能优势,建议:
- 根据数据量选择合适的vBucket数量:默认1024,大型集群可增加到4096
- 设置合适的副本数量:根据可用性和性能需求选择1-3个副本
- 分配足够的内存配额:确保文档能够存入内存,提高读写性能
- 使用合适的存储类型:根据数据持久化需求选择
couchbase或ephemeral存储类型 - 启用SSL加密:保护数据传输安全
8.4 微服务架构中的使用
在微服务架构中,Couchbase可以作为共享数据库或每个服务使用独立集群。 建议:
- 服务专属集群:在大型分布式系统中,为每个服务配置独立的Couchbase集群
- 使用连接池优化:配置连接池参数,提高资源利用率
- 异步操作:在高并发场景下,使用Reactive API进行异步操作
- 分布式事务:使用XDCR实现跨集群数据同步
- 监控与告警:配置监控指标,及时发现性能问题
8.5 异常处理与重试机制
Couchbase在分布式环境下可能出现各种异常,建议:
- 统一异常处理:使用Spring的异常处理机制统一处理Couchbase异常
- 重试机制:实现重试逻辑,处理临时性错误
- 版本控制:使用CAS值实现乐观锁,避免并发冲突
- 错误码处理:根据错误码采取不同的处理策略
- 日志记录:详细记录查询和错误信息,便于排查问题
9. 总结与展望
Spring Data Couchbase通过提供统一的编程模型和简化API,显著降低了分布式文档数据库的集成难度。 它不仅简化了数据访问层的开发,还支持事务管理、缓存集成等高级功能,使Java开发者能够充分利用Couchbase的性能和可扩展性优势。
随着微服务架构和云原生应用的普及,Couchbase的分布式特性与Spring生态的结合将变得更加重要。 未来,Spring Data可能会进一步增强对Couchbase新特性的支持,如事件驱动架构、向量搜索等,为Java开发者提供更强大的工具。
对于Java开发者来说,掌握Spring Data Couchbase不仅能提高开发效率,还能构建高性能、可扩展的应用系统。在选择数据存储方案时,Couchbase的混合模型(文档+键值)和内存优先特性使其成为许多场景的理想选择,而Spring Data则为这一选择提供了最佳实践的实现方式。
最终,Spring Data和Couchbase的结合代表了Java NoSQL开发的未来方向——通过统一的抽象层简化复杂的数据存储集成,同时保留特定数据库的独特优势和功能。
参考资料:
本博客专注于分享开源技术、微服务架构、职场晋升以及个人生活随笔,这里有:
📌 技术决策深度文(从选型到落地的全链路分析)
💭 开发者成长思考(职业规划/团队管理/认知升级)
🎯 行业趋势观察(AI对开发的影响/云原生下一站)
关注我,每周日与你聊“技术内外的那些事”,让你的代码之外,更有“技术眼光”。
日更专刊:
🥇 《Thinking in Java》 🌀 java、spring、微服务的序列晋升之路!
🏆 《Technology and Architecture》 🌀 大数据相关技术原理与架构,帮你构建完整知识体系!

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐
 33
33 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)