Spark 核心角色深度剖析:Driver, Executor, Master, Worker 全解析
Spark 的世界就像一场大型协作演出:Driver 负责指挥全局,Cluster Manager 分配资源,Worker 和 Executor 则在后台默默干活。每个 RDD 分区都化身为并行 Task,在集群上同时运行。理解它们的分工与协作,你就能看懂 Spark 的“分布式魔法”是如何高效驱动数据计算的。
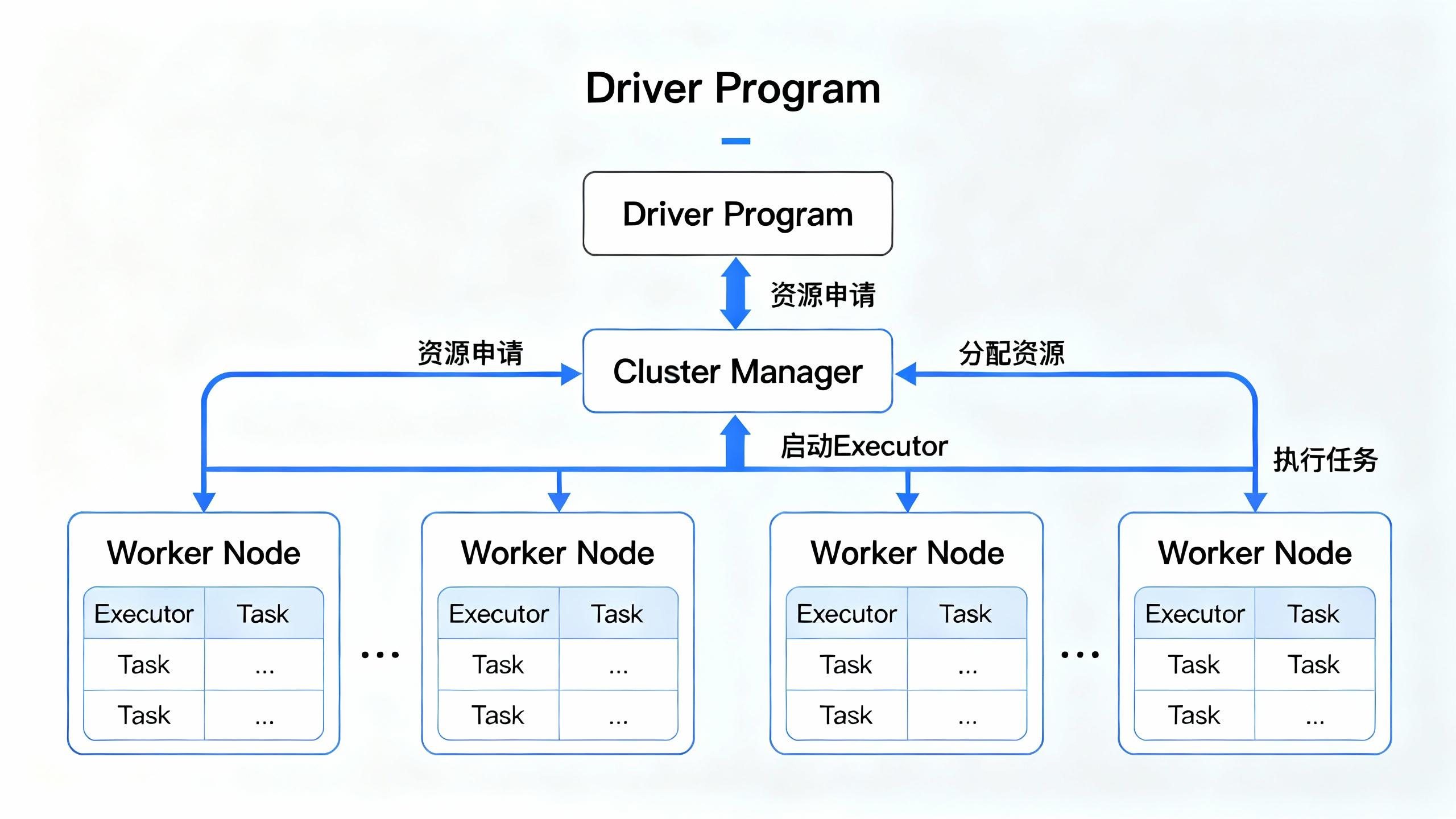
要真正理解 Spark 的运行机制,首先必须掌握其分布式架构中的关键角色。一个 Spark 应用程序 (Application) 的成功运行,离不开 Driver、Cluster Manager、Worker 和 Executor 等角色的协同工作。本节,我们将深入剖析这些核心角色的职责与相互关系。
一、Spark 应用程序的核心角色
一个完整的 Spark Application 主要由以下几个核心角色构成:
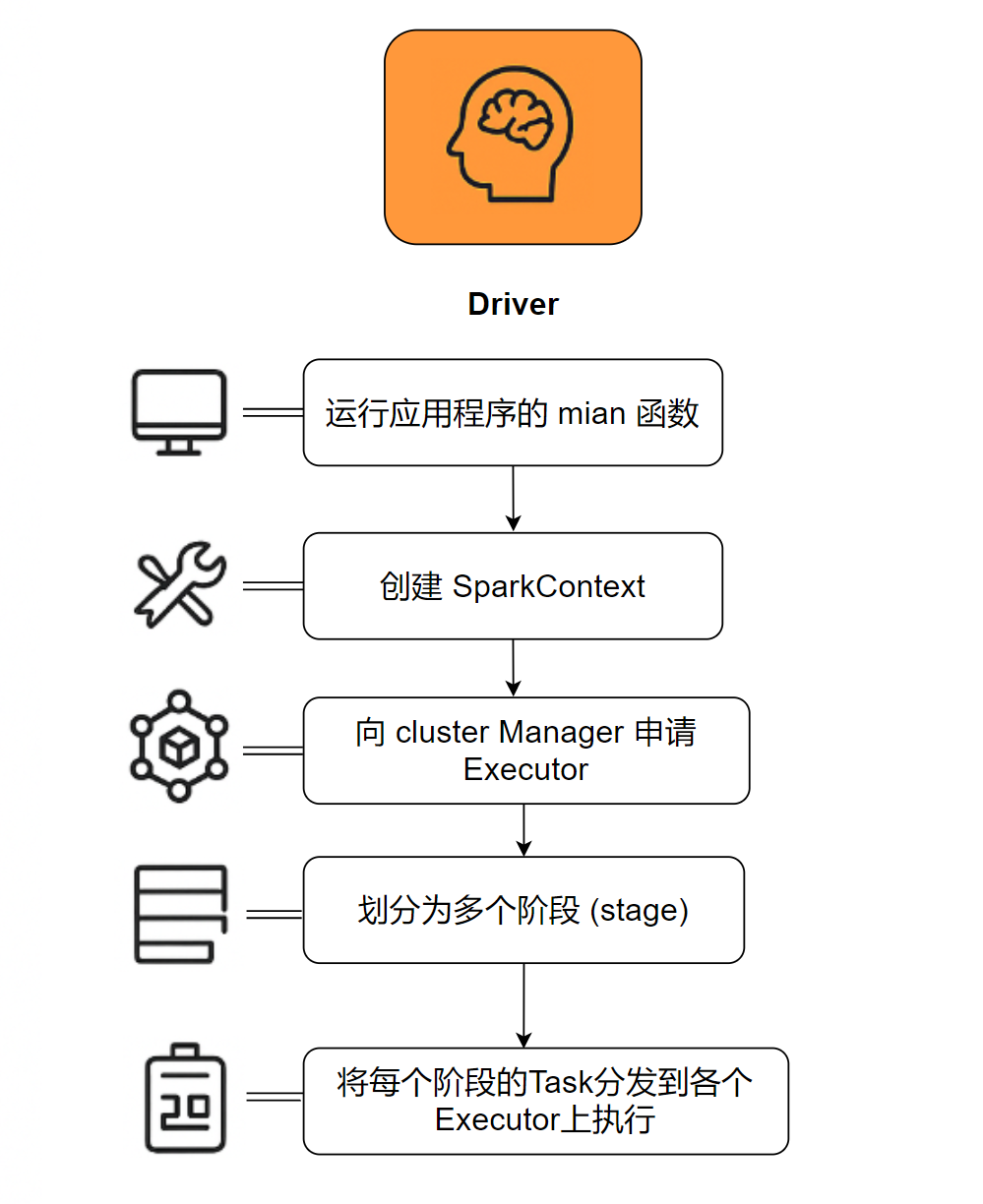
a. Driver (驱动程序)
核心职责: 应用程序的“大脑”。它是整个应用的入口和总指挥。
识别标志: 哪里创建了 SparkContext (或 SparkSession),哪里就是 Driver。
具体工作:
- 运行应用程序的
main函数- 创建
SparkContext,这是与集群交互的唯一通道- 向 Cluster Manager (如 Standalone Master, YARN ResourceManager) 申请计算资源 (Executor)
- 对作业 (Job) 进行分析,并将其划分为多个阶段 (Stage)
- 将每个阶段的任务 (Task) 分发到各个 Executor 上执行
- 收集任务的执行结果
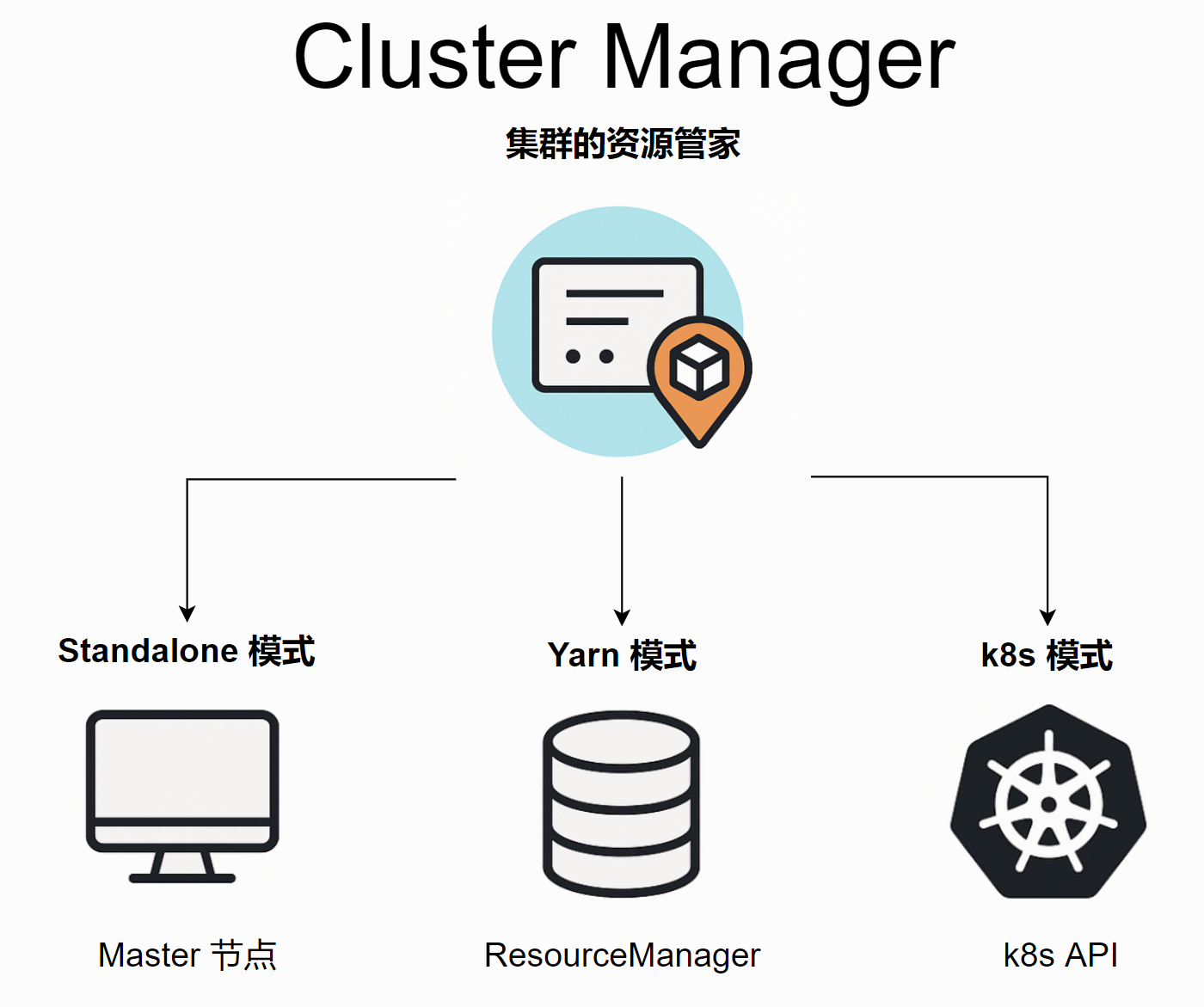
b. Cluster Manager (集群管理器)
核心职责: 集群的“资源管家”。负责管理和分配集群中的物理资源。
不同模式下的实现:
Standalone 模式: 角色是
Master节点
YARN 模式: 角色是ResourceManager
Kubernetes 模式: 角色是 Kubernetes Master (API Server)
c. Worker Node (工作节点)
核心职责: 集群中的“劳动力”。任何可以运行 Application 计算代码的物理或虚拟机器。
具体工作:
- 接收 Cluster Manager 的指令。
- 在其上启动和管理一个或多个
Executor进程。
d. Executor (执行器)
核心职责: 任务的“执行单元”。它是一个运行在 Worker Node 上的 JVM 进程 (或可视为一个线程池)。
具体工作:
- 接收 Driver 分发过来的任务 (Task)
- 在自己的线程中执行这些 Task,进行具体的计算
- 将计算结果返回给 Driver,或者写入外部存储 (如 HDFS)
- 缓存 RDD 分区数据
e. Task (任务)
核心职责: 工作的“最小单位”。一个 Task 是一个被发送到 Executor 的工作单元,通常在一个线程中执行。
具体工作: 对一个 RDD 的一个分区 (Partition) 执行一系列的计算操作 (如 map, filter)。
二、RDD 分区与 Task 的并行执行
要理解 Spark 如何实现并行计算,关键在于理解 RDD 分 和 Task 之间的关系。
RDD (弹性分布式数据集):是 Spark 中最基本的数据抽象。一个 RDD 逻辑上是一个完整的数据集,但物理上被切分成了多个分区,分布在集群的不同节点上。
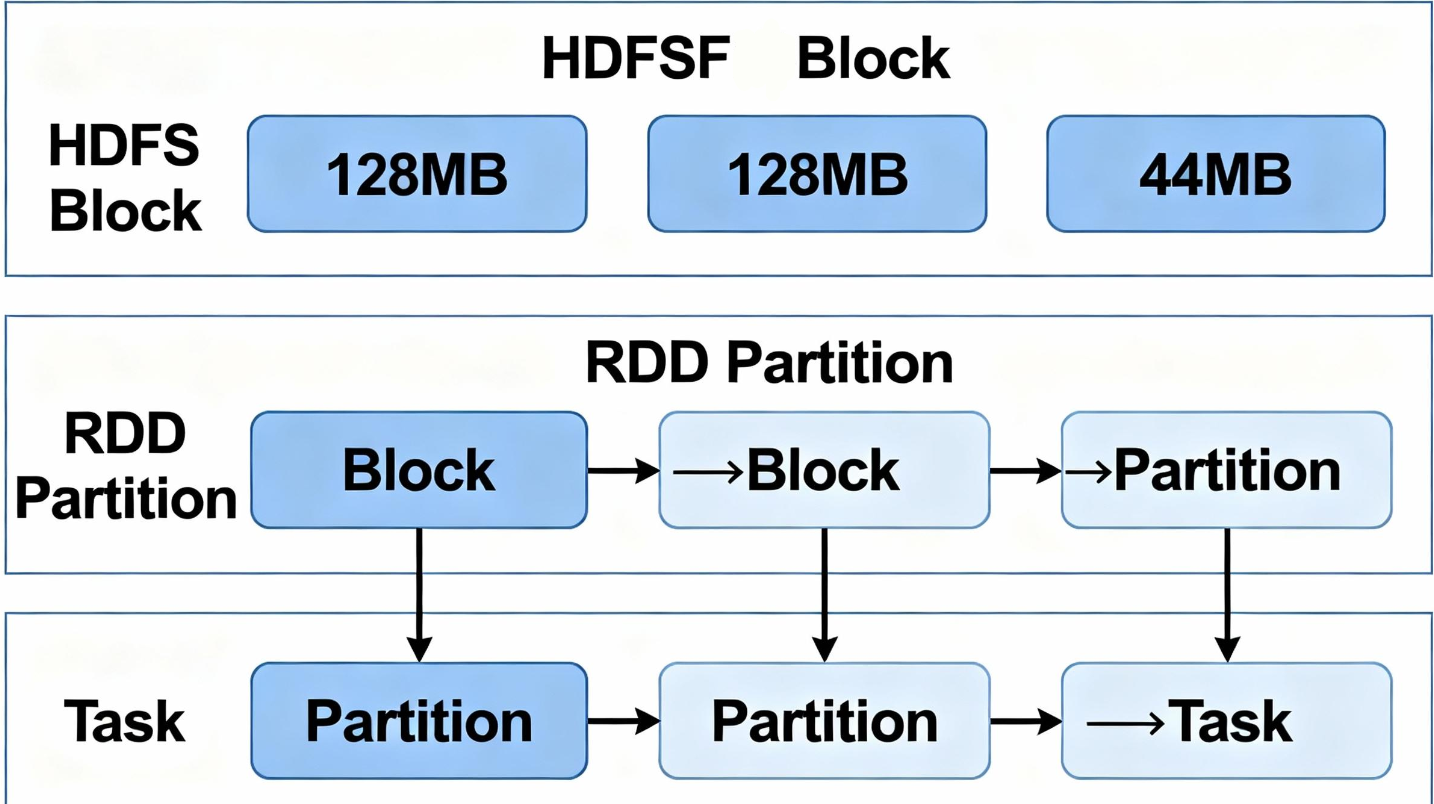
分区与 HDFS Block 的关系:当我们从 HDFS 读取文件创建 RDD 时,通常情况下,HDFS 中的一个 Block 会对应 RDD 的一个 Partition。例如,一个 300MB 的文件在 HDFS 中被存储为 128MB, 128MB, 44MB 三个 Block,那么通过 sc.textFile() 读取后,生成的 RDD 很可能也会有 3 个分区。
并行计算的核心:Spark 为 RDD 的每一个分区启动一个 Task 来进行计算。如果有 N 个分区,Spark 就可以并行地运行 N 个 Task,从而实现分布式并行计算。
代码执行流程解析:
当我们编写并提交如下代码时:
# ... SparkContext 已创建
textRDD = sc.textFile("hdfs://...")
flatmap_RDD = textRDD.flatMap(lambda line: line.split(" "))
mapRDD = flatmap_RDD.map(lambda word:(word,1))
resultRDD = mapRDD.reduceByKey(lambda a,b:a+b)
resultRDD.collect()
sc.textFile(...): 读取数据并创建 RDD,确定分区数。flatMap,map,reduceByKey: 这些是转换 (Transformation) 操作,它们并不会立即执行,只是记录了 RDD 之间的依赖关系,形成一个有向无环图 (DAG)。collect(): 这是一个行动 (Action) 操作。它的触发,会让 Driver 将整个 DAG 提交给集群执行。Driver 将计算任务分解为 Task,分发给 Executor。Executor 启动多个 Task 线程,每个线程负责处理一个分区上的数据,并依次执行flatMap,map,reduceByKey等一系列计算。
三、Driver 端与 Executor 端的代码执行划分
在一个 Spark Application 中,并非所有代码都在Executor 上执行。理解代码的执行位置对于调试和性能优化至关重要。
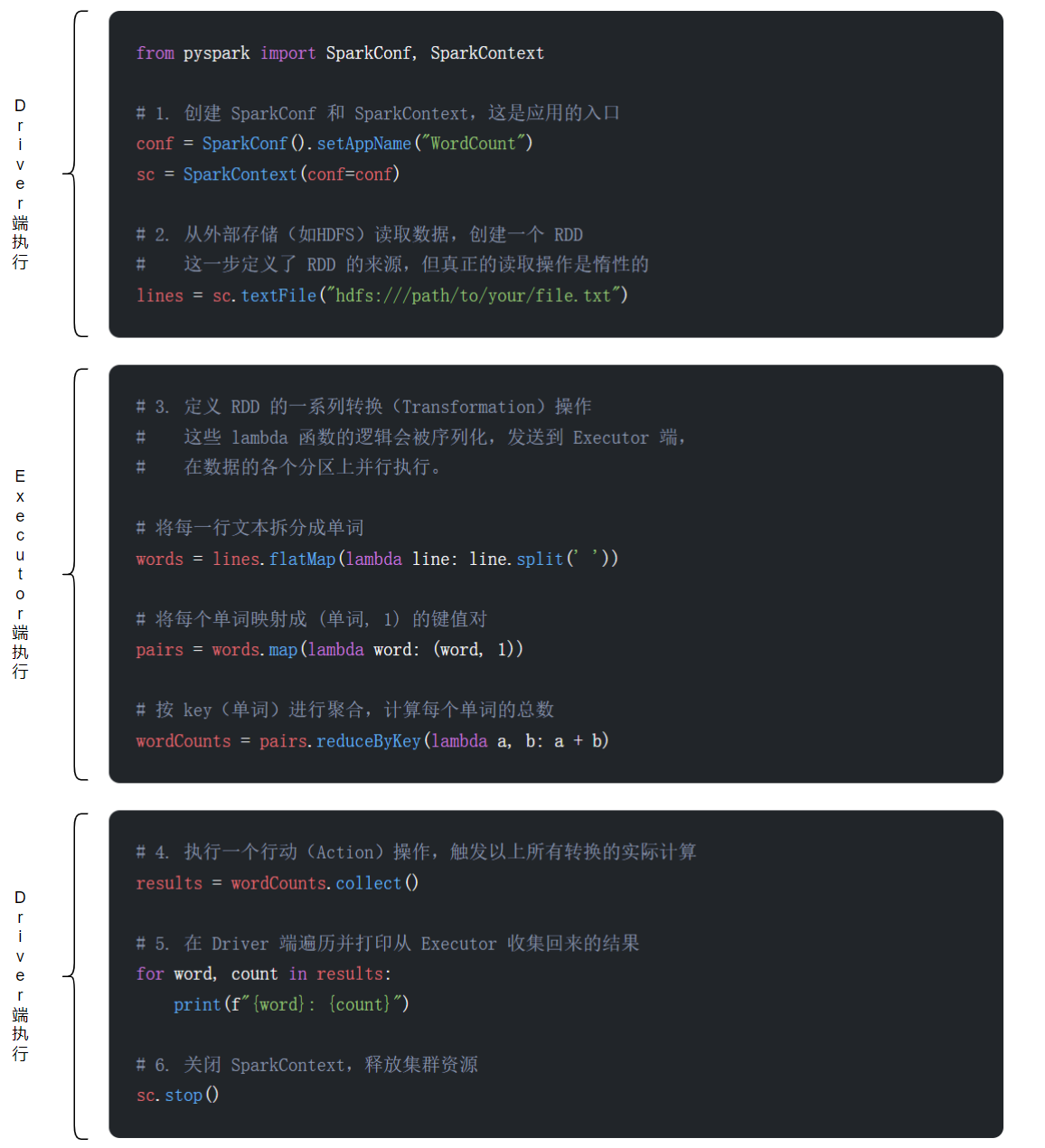
执行位置划分:
在 Driver 端执行的代码:
- 创建
SparkContext/SparkSession:sc = SparkContext(...)- 所有 RDD 转换操作的“定义”: 当你写
rdd.map(...)或rdd.filter(...)时,这些代码本身是在 Driver 端构建 DAG 的一部分,并不是在 Executor 上立即执行。- 触发 Action 的代码:
rdd.collect(),rdd.count()等。Action 本身是在 Driver 端调用的,它触发了在 Executor 上的计算。- 处理 Action 结果的代码:
collect()返回的结果列表是在 Driver 端的内存中的。所有对这个结果列表的操作 (如for循环打印) 都在 Driver 端执行。- 关闭
SparkContext:sc.stop()
在 Executor 端执行的代码:
- RDD 转换操作的“函数体”: 在
rdd.map(lambda x: x + 1)中,lambda x: x + 1这个函数本身会被序列化后发送到 Executor,并由 Task 线程在数据分区上实际执行。- 所有数据处理逻辑: 包括从数据源 (如 HDFS) 读取数据、中间的转换计算、Shuffle 数据的读写等,都是在 Executor 中完成的。
四、spark-shell, pyspark, spark-submit 的关系与参数
spark-shell (Scala) 和 pyspark (Python) 是交互式的 Shell 环境,非常适合探索性分析和快速原型开发。而 spark-submit 是用于提交已打包好的独立应用 (JARs or Python scripts) 到集群的通用工具。
核心关系:
spark-shell和pyspark的底层实际上也是调用spark-submit来启动一个 Spark 应用的。
因此,所有可以传递给spark-submit的配置参数,同样可以在启动spark-shell或pyspark时使用。
常用 spark-submit 参数解析 (YARN 模式下)
下表总结了一些在 YARN 模式下提交任务时最常用的参数:
| 参数 (Parameter) | 作用 | 默认值 | 示例 |
|---|---|---|---|
--master |
指定集群管理器。 | local[*] |
yarn |
--deploy-mode |
部署模式 (client 或 cluster)。 |
client |
cluster |
--driver-memory |
Driver进程的内存。 | 1g |
2g |
--driver-cores |
Driver进程的CPU核心数 (仅限cluster模式)。 | 1 |
2 |
--num-executors |
启动的Executor数量。 | 2 |
10 |
--executor-memory |
每个Executor的内存。 | 1g |
4g |
--executor-cores |
每个Executor的CPU核心数。 | 1 |
4 |
示例命令:提交一个配置丰富的 Spark 作业到 YARN
spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--driver-cores 1 \
--num-executors 10 \
--executor-memory 2g \
--executor-cores 2 \
--name "MyComplexApp" \
my_spark_app.py arg1 arg2
资源计算示例解析:
根据上面的命令,我们向 YARN 集群申请了多少资源?
Driver 资源: 1g 内存, 1 个 CPU core (运行在某个NodeManager上)。
Executor 总资源:
- 总Executor内存:
10(executors) *2g(memory/executor) =20g - 总Executor核心数:
10(executors) *2(cores/executor) =20cores
整个应用总共需要 1g + 20g = 21g 内存和 1 + 20 = 21 个CPU核心。在提交前,你需要确认 YARN 集群有足够的可用资源</-s>。

日期:2025年10月6日
专栏:Spark教程(PySpark)

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 68
68 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)