Transformer实战(23)——使用SBERT进行文本聚类与语义搜索
本文介绍了如何利用 SBERT 模型进行文本聚类和语义搜索,以实现少样本或单样本学习,展示了文本表示在语义任务中的实用价值。。在文本聚类部分,使用 paraphrase-distilroberta 模型对 Amazon 评论数据进行编码,应用 K-means 聚类并可视化结果,通过质心附近的代表句解释聚类主题。在语义搜索部分,采用 quora-distilbert 模型对 FAQ 问题进行编码,通
Transformer实战(23)——使用SBERT进行文本聚类与语义搜索
0. 前言
我们已经学习了如何利用在 NLI (Natural Language Inference) 数据集上微调模型进行零样本学习。接下来,将学习如何通过语义文本聚类 (Text Clustering) 和语义搜索 (Semantic Search) 进行少样本或单样本学习。
1. 使用 SBERT 进行文本聚类
对于聚类算法,我们需要一个适合文本相似性的模型。本节将使用 paraphrase-distilroberta-base-v1 模型。首先加载 Amazon Polarity 数据集,用于文本聚类。该数据集包含从亚马逊网站上收集的超过 3500 万条评论,其中包括包括产品信息、用户信息、用户评分和用户评价。
1.1 文本聚类
(1) 首先,随机打乱数据,从中选择 10000 条评论:
import pandas as pd, numpy as np
import torch, os
from datasets import load_dataset
dataset = load_dataset("amazon_polarity",split="train")
corpus=dataset.shuffle()[:10000]['content']
pd.Series([len(e.split()) for e in corpus]).hist()
(2) 语料库准备完毕后进行聚类。使用预训练的 paraphrase-distilroberta-base-v1 模型实例化一个 SentenceTransformer 对象:
from sentence_transformers import SentenceTransformer
model_path="paraphrase-distilroberta-base-v1"
#paraphrase-distilroberta-base-v1 - Trained on large scale paraphrase data.
model = SentenceTransformer(model_path)
(3) 对整个语料库进行编码,模型将句子列表映射为嵌入向量列表:
corpus_embeddings = model.encode(corpus)
corpus_embeddings.shape
# (10000, 768)
其中,向量大小为 768,这是 BERT 基础模型的默认嵌入大小。
(4) 接下来,我们将使用传统的聚类方法,选择 k-means 聚类算法,因为它是一种快速且广泛使用的聚类算法。将聚类数 (k) 设置为 5,这个数字可能并不是最优的。有多种技术可以确定最佳聚类数,例如肘部法或轮廓法,但并非本节讨论的重点:
from sklearn.cluster import KMeans
K=5
kmeans = KMeans(n_clusters=5).fit(corpus_embeddings)
import pandas as pd
cls_dist=pd.Series(kmeans.labels_).value_counts()
cls_dist
输出结果如下所示:
2 2735
1 2111
4 1955
0 1743
3 1456
Name: count, dtype: int64
从输出中可以看到,聚类分布相对均匀。另一个问题是,我们需要理解这些聚类的含义。我们可以对每个聚类应用主题分析,或者检查基于聚类的 TF-IDF (词频-逆文档频率)来理解内容。接下来,我们使用基于聚类中心的方法,k-means 算法会计算出聚类中心(称为质心),质心保存在 kmeans.cluster_centers_ 属性中。聚类中心是每个聚类中向量的平均值,因此它们都是虚拟点,而不是实际存在的数据点。我们假设,最接近聚类中心的句子是对应聚类中最具代表性的数据点。
(5) 找到距离每个聚类中心最近的一个真实句子嵌入,我们也可以选择多个句子:
import scipy
distances = scipy.spatial.distance.cdist(kmeans.cluster_centers_ , corpus_embeddings)
centers={}
print("Cluster", "Size", "Center-idx", "Center-Example", sep="\t\t")
for i,d in enumerate(distances):
ind = np.argsort(d, axis=0)[0]
centers[i]=ind
print(i,cls_dist[i], ind, corpus[ind] ,sep="\t\t")
输出结果如下所示:

通过这些具有代表性的句子,我们可以推测出聚类的含义,k-means 算法将评论分成了五个不同的类别:电子产品、音频 CD /音乐、DVD /电影、书籍,以及家具/家居用品。
1.2 降维
接下来,在二维空间中可视化句子样本和聚类中心。使用 UMAP (Uniform Manifold Approximation and Projection) 库进行降维。在自然语言处理中,其他常用的降维技术包括 t-SNE (t-distributed Stochastic Neighbor Embedding) 和主成分分析 (Principal Component Analysis, PCA)。
(1) 首先使用 pip 命令安装 UMAP 库:
pip install umap-learn
(2) 将所有嵌入向量降维并映射到二维空间中:
import matplotlib.pyplot as plt
import umap
X = umap.UMAP(n_components=2, min_dist=0.0).fit_transform(corpus_embeddings)
labels= kmeans.labels_
fig, ax = plt.subplots(figsize=(12, 8))
plt.scatter(X[:,0], X[:,1], c=labels, s=1, cmap='Paired')
for c in centers:
plt.text(X[centers[c],0], X[centers[c], 1], "CLS-"+ str(c), fontsize=24)
plt.colorbar()
输出结果如下所示:
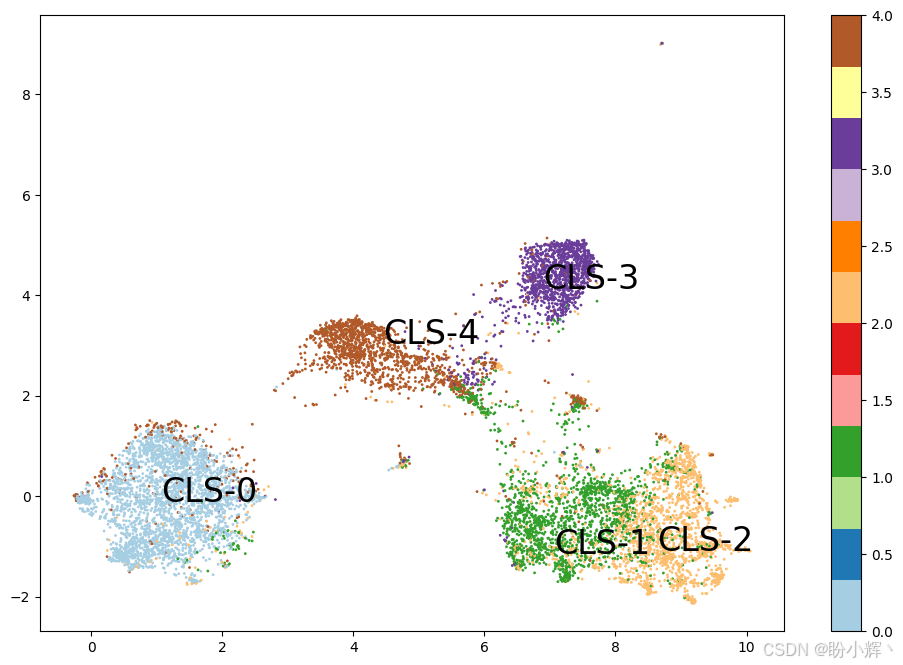
可以看到,数据点根据其聚类成员身份和质心进行了着色,从结果来看,我们选择的聚类数量是合适的。为了捕捉主题并解释聚类,我们找到了每个聚类中心附近的一个句子。
2. 使用 SBERT 进行语义搜索
在基于关键词的搜索(布尔模型)中,给定一个关键词或模式,我们可以检索与该模式匹配的结果。另一种方法是使用正则表达式,通过正则表达式我们可以定义高级模式,比如词法-句法模式。但这些传统方法无法处理同义词(例如,car 和 automobile 含义相同)或词义问题(例如,bank 既可以指河岸,也可以指金融机构)。同义词问题会导致低召回率,因为会遗漏一些不应该遗漏的文档;而第二个问题则会导致低精确率,因为会捕捉到一些不相关的文档。
我们将利用常见问题解答 (Frequently Asked Questions, FAQ) 来进行语义搜索,使用来自世界自然基金会 (World Wide Fund for Nature, WWF)的 FAQ 作为数据集。
使用语义模型进行语义搜索类似于单样本学习问题,其中我们只有一个类别的单个样本(即单个示例),我们希望根据该样本重新排序其余的数据(句子)。可以将问题重新定义为搜索与给定样本语义接近的样本,或根据样本进行二元分类。模型可以提供一个相似性度量,接着根据这个度量重新排序其他样本。最终的排序列表即为搜索结果,它根据语义表示和相似性度量进行了重新排序。WWF 网页上有 18 个常见问题和答案。将它们定义为一个 Python 列表对象 wf_faq:
import pandas as pd
import sklearn
import numpy as np
wwf_faq=["I haven’t received my adoption pack. What should I do?",
"How quickly will I receive my adoption pack?",
"How can I renew my adoption?",
"How do I change my address or other contact details?",
"Can I adopt an animal if I don’t live in the UK?",
"If I adopt an animal, will I be the only person who adopts that animal?",
"My pack doesn't contain a certicate",
"My adoption is a gift but won’t arrive on time. What can I do?",
"Can I pay for an adoption with a one-off payment?",
"Can I change the delivery address for my adoption pack after I’ve placed my order?",
"How long will my adoption last for?",
"How often will I receive updates about my adopted animal?",
"What animals do you have for adoption?",
"How can I nd out more information about my adopted animal?",
"How is my adoption money spent?",
"What is your refund policy?",
"An error has been made with my Direct Debit payment, can I receive a refund?",
"How do I change how you contact me?"]
用户可以自由提出任何问题。我们需要评估 FAQ 中哪个问题与用户的问题最相似,这就是 quora-distilbert-base 模型的目标。
在 SBERT Hub 中有两个选项,一个是英语版本,另一个是多语言版本:
quora-distilbert-base:经过微调,专门用于Quora重复问题检测和检索quora-distilbert-multilingual:quora-distilbert-base的多语言版本,经过50多种语言的并行数据微调
接下来,从零开始构建语义搜索模型。
(1) 实例化 SBERT 模型:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("quora-distilbert-base")
(2) 接下来,编码 FAQ:
faq_embeddings = model.encode(wwf_faq)
(3) 准备五个问题,使其分别与 FAQ 中的前五个问题相似;即第一个测试问题应与 FAQ 中的第一个问题相似,第二个测试问题与 FAQ 中的第二个问题相似,依此类推,以便我们可以轻松跟踪结果。将测试问题定义在 test_questions 列表对象中,并进行编码:
test_questions=["What should be done, if the adoption pack did not reach to me?",
" How fast is my adoption pack delivered to me?",
"What should I do to renew my adoption?",
"What should be done to change adress and contact details ?",
"I live outside of the UK, Can I still adopt an animal?"]
test_q_emb= model.encode(test_questions)
(4) 计算每个测试问题与 FAQ 中每个问题的相似度,并进行排序:
from scipy.spatial.distance import cdist
for q, qe in zip(test_questions, test_q_emb):
distances = cdist([qe], faq_embeddings, "cosine")[0]
ind = np.argsort(distances, axis=0)[:3]
print("\n Test Question: \n "+q)
for i,(dis,text) in enumerate(zip(distances[ind], [wwf_faq[i] for i in ind])):
print(dis,ind[i],text, sep="\t")
输出结果如下:

可以看到,顺序为 0、1、2、3、4 的索引,这意味着模型成功地找到了与预期相似的问题。
(5) 定义 getBest() 函数,接受一个问题并返回 FAQ 中与其最相似的 K 个问题:
def get_best(query, K=3):
query_embedding = model.encode([query])
distances = cdist(query_embedding, faq_embeddings, "cosine")[0]
ind = np.argsort(distances, axis=0)
print("\n"+query)
for c,i in list(zip(distances[ind], ind))[:K]:
print(c,wwf_faq[i], sep="\t")
(6) 调用 getBest() 函数:
get_best("How do I change my contact info?",3)
输出结果如下:

(7) 接下来,测试输入的问题与 FAQ 中的问题并无相似的情况:
get_best("How do I get my plane ticket if I bought it online?")
输出结果如下:

最小的相似度距离为 0.35,距离越大表明相似度越低。因此,我们需要定义一个阈值,例如 0.3,以便模型忽略那些高于该阈值的问题,并返回“未找到相似答案”。
除了基于问题与问题之间的对称相似度搜索外,还可以利用 SBERT 的问答不对称搜索模型,例如 msmarco-distilbert-base-v3,该模型基于约 50 万个 Bing 搜索查询数据集进行训练,也称为 Passage Ranking。该模型帮助我们评估问题和上下文的相关性,并检查问题的答案是否出现在文本段落中。
小结
在本节中,我们探讨了文本表示的一些有用的应用场景,如语义搜索、语义聚类和主题建模。学习了如何可视化聚类结果,并理解了质心在此类问题中的重要性。
系列链接
Transformer实战(1)——词嵌入技术详解
Transformer实战(2)——循环神经网络详解
Transformer实战(3)——从词袋模型到Transformer:NLP技术演进
Transformer实战(4)——从零开始构建Transformer
Transformer实战(5)——Hugging Face环境配置与应用详解
Transformer实战(6)——Transformer模型性能评估
Transformer实战(7)——datasets库核心功能解析
Transformer实战(8)——BERT模型详解与实现
Transformer实战(9)——Transformer分词算法详解
Transformer实战(10)——生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)——从零开始构建GPT模型
Transformer实战(12)——基于Transformer的文本到文本模型
Transformer实战(13)——从零开始训练GPT-2语言模型
Transformer实战(14)——微调Transformer语言模型用于文本分类
Transformer实战(15)——使用PyTorch微调Transformer语言模型
Transformer实战(16)——微调Transformer语言模型用于多类别文本分类
Transformer实战(17)——微调Transformer语言模型进行多标签文本分类
Transformer实战(18)——微调Transformer语言模型进行回归分析
Transformer实战(19)——微调Transformer语言模型进行词元分类
Transformer实战(20)——微调Transformer语言模型进行问答任务
Transformer实战(21)——文本表示(Text Representation)
Transformer实战(22)——使用FLAIR进行语义相似性评估

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 53
53 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)