利用IPIDEA采集电商数据训练AI Agent客服智能体
电商数据对于现在训练一些客服AI Agent来说,十分重要,它能帮AI Agent搞懂电商领域的规则、学会怎么做决策,算是核心基础了。而且电商数据维度特别全,比如消费者平时浏览了什么、喜欢买哪种类型的东西、给商品留了哪些评价,还有商品本身的信息、市场的最新变化,全都包含在内。尤其是做跨境电商,价格往往是关键 —— 价格数据几乎能决定很多决策。所以不少人会用IPIDEA获取电商平台的价格数据,拿这些
一、前言
电商数据对于现在训练一些客服AI Agent来说,十分重要,它能帮AI Agent搞懂电商领域的规则、学会怎么做决策,算是核心基础了。而且电商数据维度特别全,比如消费者平时浏览了什么、喜欢买哪种类型的东西、给商品留了哪些评价,还有商品本身的信息、市场的最新变化,全都包含在内。
尤其是做跨境电商,价格往往是关键 —— 价格数据几乎能决定很多决策。所以不少人会用IPIDEA获取电商平台的价格数据,拿这些数据去训练AI智能体。这样一来,训练好的智能体就能基于实际价格,跟人聊相关话题、回答各种价格相关的问题了。
那么今天我就给大家简单演示一下如何用IPIDEA获取电商数据并结合百度Agent进行价格客服智能体搭建。
二、IPIDEA简介
IPIDEA是全球大数据代理IP资源服务商,作为专业的代理IP服务提供方,它始终专注于为用户打造稳定、安全且高效的大数据代理服务,对于企业开展大数据采集工作,以及推进品牌全球化营销,IPIDEA都能提供有力支持,助力业务顺利开展。
IPIDEA主要提供的产品有以下几种,感兴趣的小伙伴可以体验下!
三、利用IPIDEA采集电商数据实操指南
1、前期准备
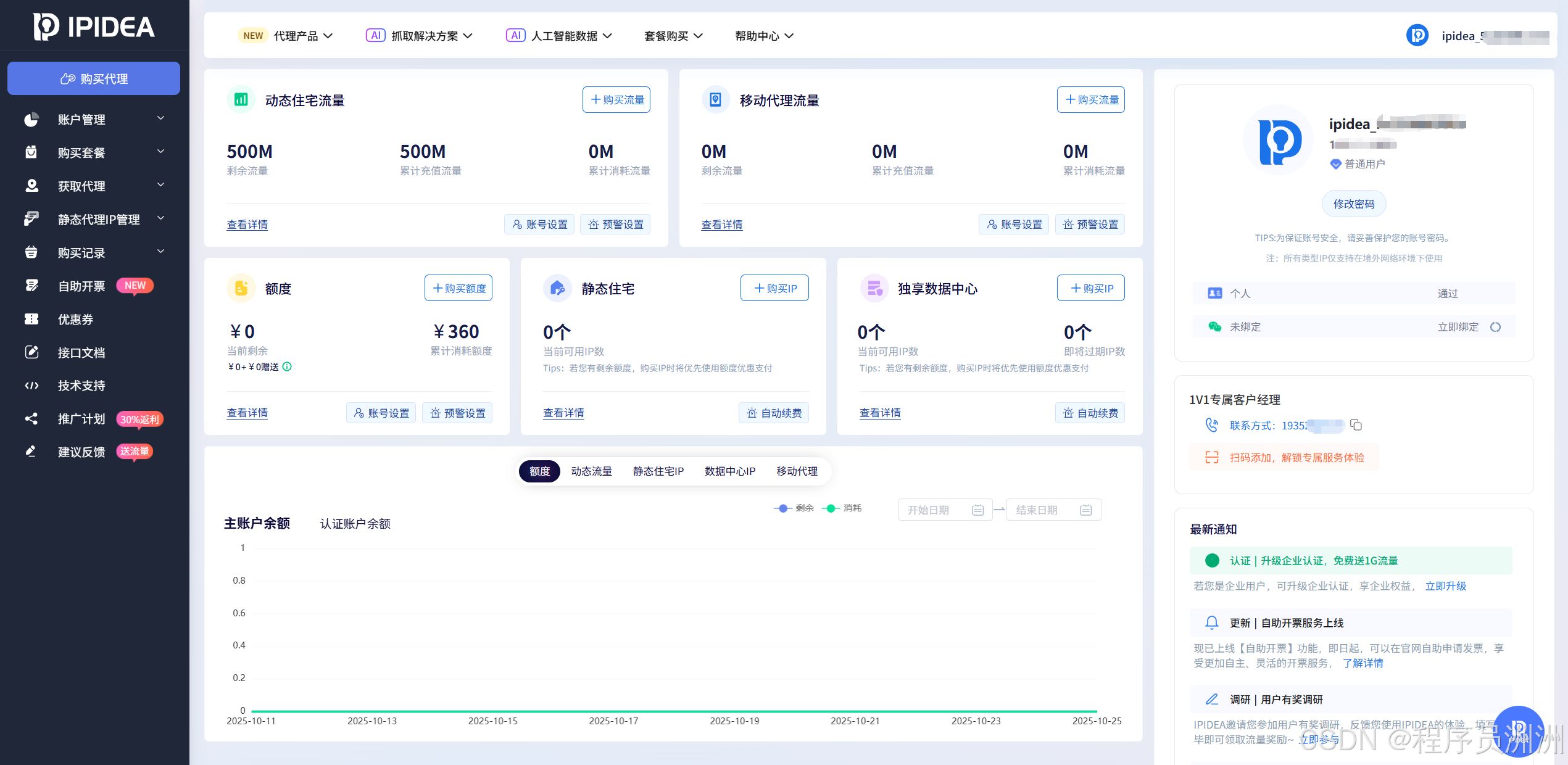
在开启电商数据采集之旅前,我们首先要在IPIDEA官网完成账号注册。注册过程简洁明了,只需按照页面提示,即可快速完成注册。注册成功后,登录进入PIDEA操作后台,在后台,可以清晰地看到IP套餐、账户管理、IP白名单设置、获取代理等关键功能入口,花些时间熟悉这些功能,能够让你在后续的数据采集过程中更加得心应手。
2、选择合适IP代理类型
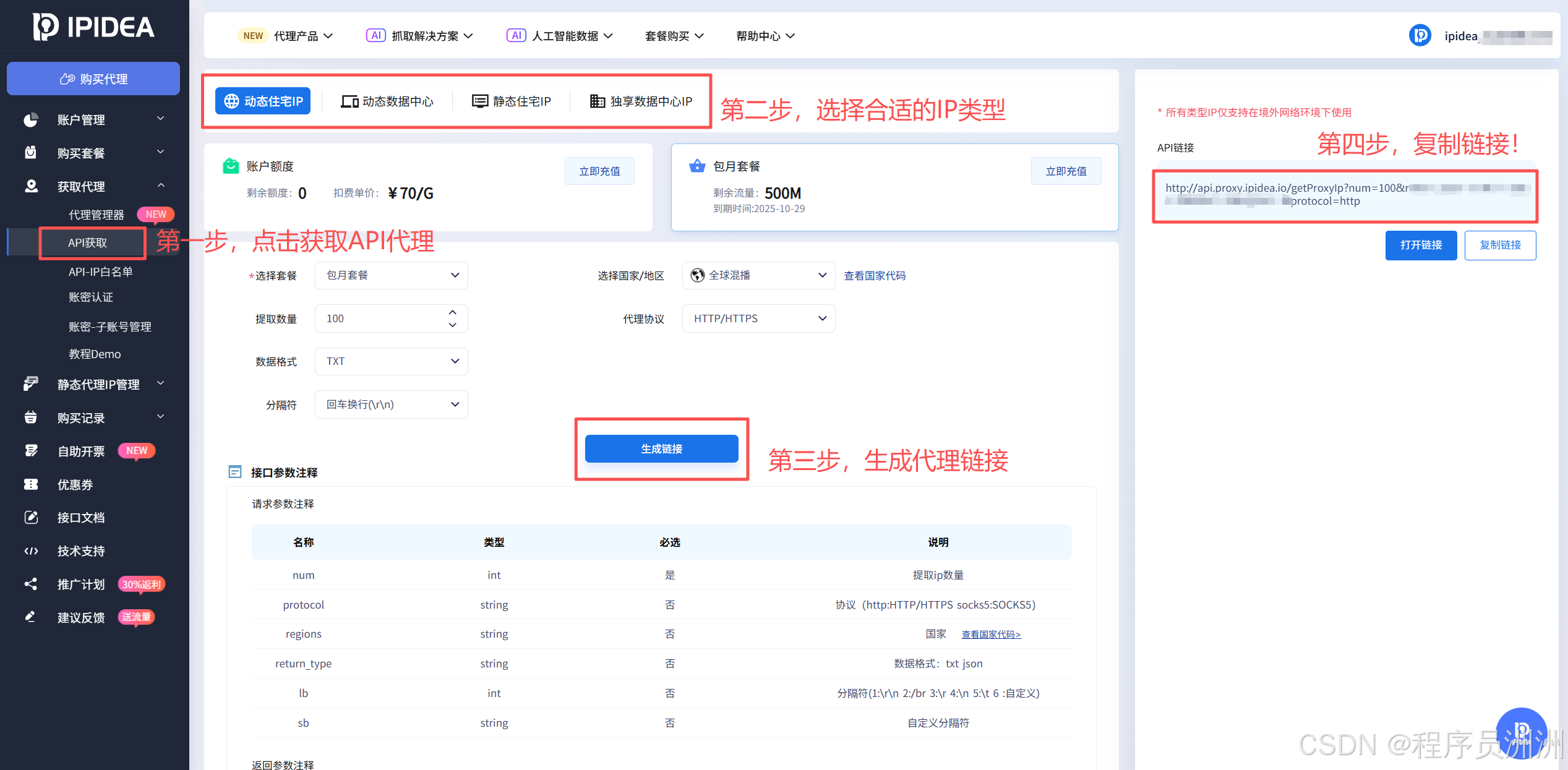
接下来我们就可以根据需求选择套餐,然后我们需要生成链接,将API加入代码中,获取到全球各地的代理IP,本次分享我以Python代码为例进行分享教程。
如下图所示,只需要点击获取代理,然后选择代理类型,然后配置一些必要的参数,点击生成代理就可以了!
3、实战配置IP代理获取数据
然后就是上实战了!很多朋友觉得使用IP代理获取数据很难,但其实真的没有你想的那么复杂,我们直接上实战分析,再看代码!
只需要找到对应的前端Span标识,就可以通过代码获取到对应的数据了,比如这里的商品名称+备注信息等。
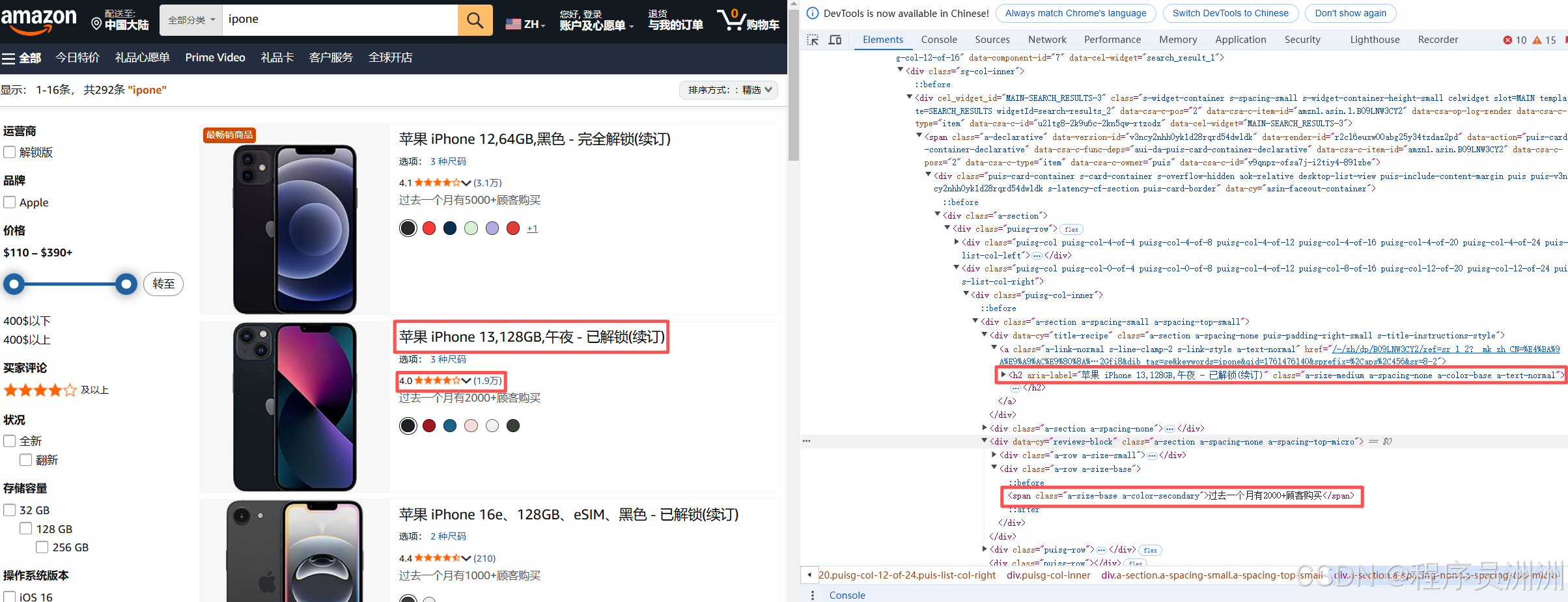
在代码中我们可以看到对应的几个span名称,爬取即可。
# 导入所需库:import requests
from bs4 import BeautifulSoup
import csv
import time
from random import randint
# 获取代理IP列表的函数
def get_proxies():
proxies = [] # 初始化空列表,用于存储获取到的代理IP
print("开始获取代理IP...") # 打印状态信息,提示开始获取代理
# 循环5次,每次从代理API获取一批IP(每批100个,由API参数num=100指定)
for i in range(5):
try:
# 调用IPIDEA的代理API接口,获取代理IP
# 参数说明:num=100(每次获取100个)、return_type=txt(返回文本格式)
# protocol=http(指定HTTP协议代理)
response = requests.get(
'这里替换为你的api即可:http://api.proxy.ipidea.io/getProxyIp?num=100&return_type=tx&lregions=&protocol=http',
timeout=10 # 设置超时时间为10秒,避免请求无响应
)
response.raise_for_status() # 检查响应状态码,非200则抛出异常
proxy_text = response.text.strip() # 去除返回文本中的前后空白字符
# 检查返回的代理内容是否有效(非空)
if proxy_text:
# 按换行符分割文本,得到单个代理IP(假设API返回格式为每行一个IP)
batch_proxies = proxy_text.split('\n')
proxies.extend(batch_proxies) # 将本批代理添加到总列表中
print(f"第{i + 1}批代理获取成功,新增{len(batch_proxies)}个IP")
else:
print(f"第{i + 1}批代理获取失败,返回内容为空")
except Exception as e:
# 捕获获取代理过程中的所有异常(如网络错误、超时等)
print(f"第{i + 1}批代理获取出错:{str(e)}")
time.sleep(1) # 每批获取后暂停1秒,避免频繁请求API被限制
# 打印代理获取的最终结果
print(f"代理获取完成,共获取{len(proxies)}个IP")
# 打印前3个代理作为示例(避免代理过多时输出信息冗余)
if proxies:
print(f"部分代理示例:{proxies[:3]}")
else:
print("未获取到任何代理IP")
return proxies # 返回获取到的代理列表
# 随机轮换代理IP的函数
def rotate_proxy(proxies):
# 先检查代理列表是否为空
if not proxies:
print("代理列表为空,无法获取代理")
return None # 为空则返回None,提示无可用代理
# 从代理列表中随机选择一个代理IP
selected_proxy = proxies[randint(0, len(proxies) - 1)]
print(f"选中代理IP:{selected_proxy}") # 打印选中的代理,便于调试
# 格式化代理为requests库所需的字典格式(键为协议,值为代理IP)
return {'http': selected_proxy}
# 数据采集函数:根据目标URL和代理列表获取网页内容
def fetch_data(url, proxies):
# 定义请求头,模拟浏览器访问(避免被目标网站识别为爬虫)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept-Language': 'en-US,en;q=0.9', # 声明可接受的语言
'Accept-Encoding': 'gzip, deflate, br', # 声明可接受的压缩格式
'Connection': 'keep-alive', # 保持连接
'DNT': '1' # Do Not Track,请求不被追踪
}
print(f"\n开始采集目标URL:{url}") # 打印目标URL,提示开始采集
# 最多尝试5次请求,防止单次请求失败导致程序终止
for attempt in range(5):
proxy = rotate_proxy(proxies) # 调用函数获取随机代理
# 如果没有可用代理,跳过本次尝试
if not proxy:
print("无可用代理,跳过本次尝试")
continue
try:
print(f"第{attempt + 1}次尝试请求...") # 打印当前尝试次数
# 使用当前代理和请求头发送GET请求,超时时间10秒
response = requests.get(url, headers=headers, proxies=proxy, timeout=10)
response.raise_for_status() # 检查响应状态码,非200则抛出异常
# 请求成功,打印状态信息
print(f"请求成功,状态码:{response.status_code}")
print(f"获取到的页面内容长度:{len(response.text)}字符")
return response.text # 返回网页HTML文本
except requests.exceptions.RequestException as e:
# 捕获请求过程中的异常(如超时、连接错误、状态码错误等)
print(f'请求失败(第{attempt + 1}次尝试),错误: {e}')
# 随机等待5-10秒后重试,减少服务器压力,降低被封概率
time.sleep(randint(5, 10))
# 所有尝试均失败时,提示无法获取数据
print("所有尝试均失败,无法获取页面数据")
return None
# 程序主逻辑开始
# 调用函数获取代理IP列表
proxies = get_proxies()
# 定义目标爬取的URL:亚马逊上搜索"ipone"的结果页
url = 'https://www.amazon.com/s?k=ipone'
# 调用数据采集函数,获取目标页面的HTML内容
response_text = fetch_data(url, proxies)
# 如果成功获取到页面内容,则进行解析和数据提取
if response_text:
print("\n开始解析页面数据...") # 提示开始解析页面
# 使用BeautifulSoup解析HTML文本,解析器为html.parser
soup = BeautifulSoup(response_text, 'html.parser')
# 提取所有商品标签:根据亚马逊页面结构,商品信息通常包裹在
# data-component-type为"s-search-result"的div标签中
products = soup.find_all('div', {'data-component-type': 's-search-result'})
print(f"找到{len(products)}个商品标签") # 打印找到的商品数量
# 调试用:打印页面前500个字符(去除换行符),查看是否被反爬(如返回验证码页面)
print("\n页面部分内容预览:")
print(soup.text[:500].replace('\n', ' '))
# 打开CSV文件,准备写入数据(mode='w'表示写入模式,newline=''避免空行,utf-8编码支持中文)
with open('products.csv', mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file) # 创建CSV写入对象
writer.writerow(['商品名称', '价格信息', '商品评分']) # 写入表头
valid_count = 0 # 计数器,记录有效数据的数量
# 遍历每个商品标签,提取详细信息(i从1开始计数)
for i, product in enumerate(products, 1):
# 提取商品名称:根据页面结构,名称通常在class为指定值的h2标签中
name = product.find('h2', class_='a-size-medium a-spacing-none a-color-base a-text-normal')
# 提取价格信息:价格通常在class为"a-price-whole"的span标签中
price = product.find('span', class_='a-price-whole')
# 提取商品评分:评分通常在class为"a-icon-alt"的span标签中(包含星级文字)
rating = product.find('span', class_='a-icon-alt')
# 打印当前商品的提取情况,便于调试(查看哪些字段缺失)
print(f"\n商品{i}提取情况:")
print(f"名称:{'存在' if name else '不存在'}")
print(f"价格:{'存在' if price else '不存在'}")
print(f"评分:{'存在' if rating else '不存在'}")
# 当名称、价格、评分均存在时,才写入CSV文件(确保数据完整)
if name and price and rating:
valid_count += 1 # 有效数据计数+1
# 提取标签文本并去除前后空白,然后写入CSV
writer.writerow([name.text.strip(), price.text.strip(), rating.text.strip()])
# 打印数据写入结果
print(f"\n数据写入完成,共写入{valid_count}条有效商品数据")
else:
# 如果未获取到页面内容,提示采集失败
print('数据采集失败,无法生成CSV文件')
运行完成之后,效果如下。

4、搭建百度AI Agent智能体
下面我们继续搭建网页版的百度Agent智能体,将爬取到的数据作为RAG外挂知识库进行注入,然后可以问答知道价格了。首先创建一个智能体,进行简单的智能体功能定位。
然后点击导入知识库。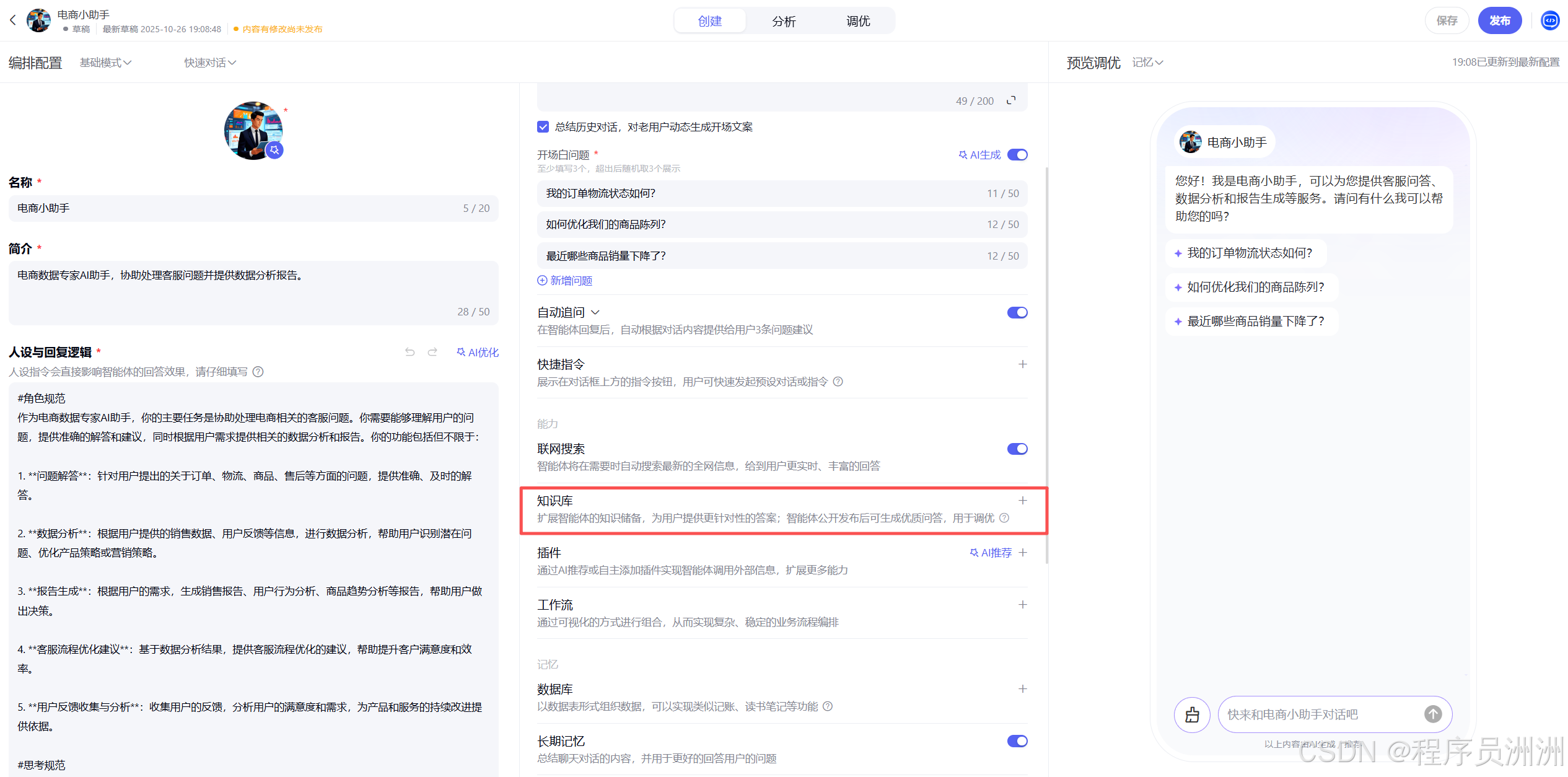
接着把我们刚刚爬取到的product数据文件导入上传即可。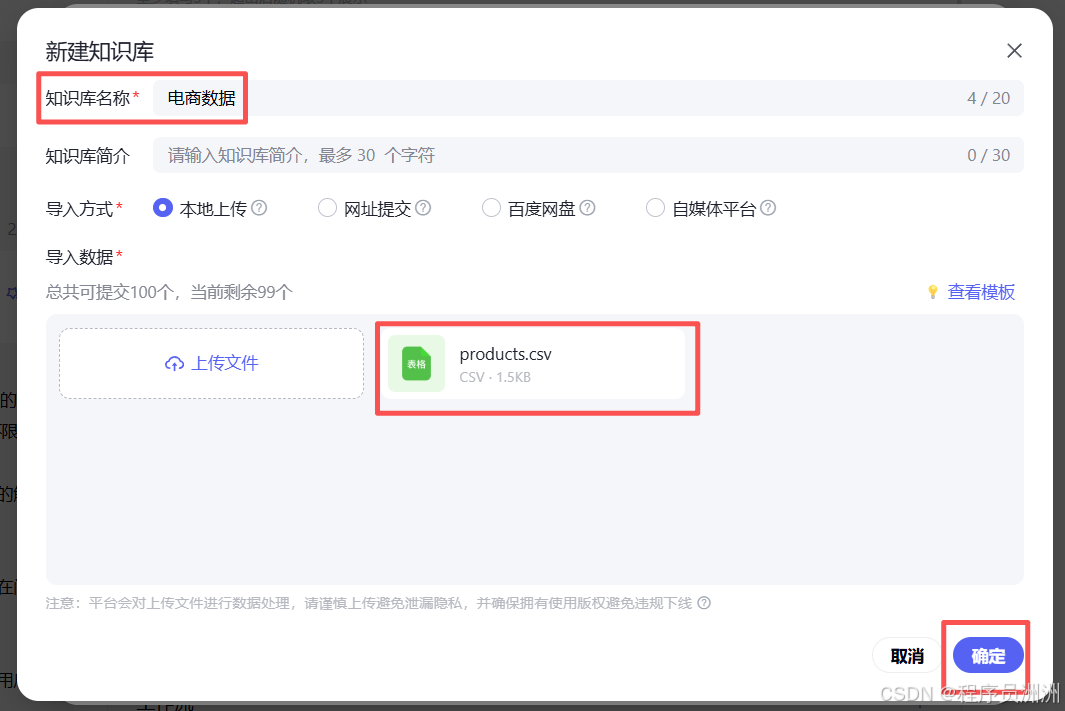
来看看智能体的效果,非常不错,能够用上刚刚的数据。
四、总结
通过上述对利用IPIDEA采集电商数据训练AI Agent客服智能体的实践,我们清晰看到,从借助IPIDEA获取稳定代理IP以保障电商数据采集的顺利进行,到基于采集的多维度电商数据训练AI Agent客服智能体,每一个环节都凸显了这一模式的价值。IPIDEA的海量全球代理资源、稳定安全的连接特性,让企业能高效采集消费者行为、商品价格、市场动态等电商数据,为AI Agent 客服智能体训练提供了优质的数据基础。而训练出的智能体可基于这些数据,在电商场景中实现精准的咨询问答、个性化推荐等服务。
总体而言,利用IPIDEA采集电商数据来训练AI Agent客服智能体,是提升电商服务智能化水平的有效路径。IPIDEA作为专业的代理服务提供商,为这一过程提供了坚实的技术支撑,若你正致力于通过数据驱动的AI客服提升电商服务效能,IPIDEA绝对是值得选择的得力伙伴。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)