深入掌握 Pandas:用 Pivot 与 Merge 构建灵活的数据分析流程
本文介绍了如何使用 Pandas 的 pivot_table() 与 merge() 方法对数据进行透视与合并。透视操作帮助我们在不同维度上汇总与重组数据,以揭示特征间的结构性关系;合并操作则通过类似 SQL 的连接机制,将多个数据源整合在一起,实现跨表对比与综合分析。通过掌握这些技巧,数据科学家能够灵活操纵数据结构,提炼更深层的洞察。
【精选优质专栏推荐】
- 《AI 技术前沿》 —— 紧跟 AI 最新趋势与应用
- 《网络安全新手快速入门(附漏洞挖掘案例)》 —— 零基础安全入门必看
- 《BurpSuite 入门教程(附实战图文)》 —— 渗透测试必备工具详解
- 《网安渗透工具使用教程(全)》 —— 一站式工具手册
- 《CTF 新手入门实战教程》 —— 从题目讲解到实战技巧
- 《前后端项目开发(新手必知必会)》 —— 实战驱动快速上手
每个专栏均配有案例与图文讲解,循序渐进,适合新手与进阶学习者,欢迎订阅。
文章目录

前言
在数据科学项目中,你收集到的数据往往不是你想要的格式。你常常需要创建派生特征、将数据子集聚合为汇总形式,或根据某些复杂逻辑选择部分数据。这并非假设情境,无论项目大小,你在第一步获得的数据都很可能远非理想。
作为数据科学家,你必须熟练地将数据整理成正确的形状,以便后续步骤更顺利。接下来,你将学习如何在 pandas 中对数据集进行分割与重组,使有用数据更突出,从而简化分析过程。
使用 Pandas 的数据编排
一个有趣的问题是:房产建造年份如何影响其价格?
为探究这一点,你可以按 “SalePrice” 将数据集划分为四个四分位区间——Low、Medium、High 和 Premium——并分析这些区间中的建造年份。这样的系统划分不仅有助于集中分析,也能揭示在整体审查中可能被掩盖的趋势。
分段策略:以 “SalePrice” 的四分位数为界
首先创建一个新列,将房价分类到定义的价格类别中:
# 导入 Pandas 库
import pandas as pd
# 读取数据集
Ames = pd.read_csv('Ames.csv')
# 定义四分位数
quantiles = Ames['SalePrice'].quantile([0.25, 0.5, 0.75])
# 定义分类函数
def categorize_by_price(row):
if row['SalePrice'] <= quantiles.iloc[0]:
return 'Low'
elif row['SalePrice'] <= quantiles.iloc[1]:
return 'Medium'
elif row['SalePrice'] <= quantiles.iloc[2]:
return 'High'
else:
return 'Premium'
# 应用函数创建新列
Ames['Price_Category'] = Ames.apply(categorize_by_price, axis=1)
print(Ames[['SalePrice','Price_Category']])
执行上述代码后,数据集中会新增一列 “Price_Category”。输出示例如下:
SalePrice Price_Category
0 126000 Low
1 139500 Medium
2 124900 Low
3 114000 Low
4 227000 Premium
... ... ...
2574 121000 Low
2575 139600 Medium
2576 145000 Medium
2577 217500 Premium
2578 215000 Premium
[2579 rows x 2 columns]
使用经验累积分布函数(ECDF)可视化趋势
现在可以将原始数据集拆分为四个 DataFrame,并可视化各价格区间中房屋建造年份的累积分布。这种可视化能让你一目了然地看到建筑年代与价格之间的历史趋势。
# 导入 Matplotlib 和 Seaborn
import matplotlib.pyplot as plt
import seaborn as sns
# 按价格类别拆分数据集
low_priced_homes = Ames.query('Price_Category == "Low"')
medium_priced_homes = Ames.query('Price_Category == "Medium"')
high_priced_homes = Ames.query('Price_Category == "High"')
premium_priced_homes = Ames.query('Price_Category == "Premium"')
# 设置样式
sns.set_style("whitegrid")
# 创建图形
plt.figure(figsize=(10, 6))
# 绘制各区间的 ECDF 曲线
sns.ecdfplot(data=low_priced_homes, x='YearBuilt', color='skyblue', label='Low')
sns.ecdfplot(data=medium_priced_homes, x='YearBuilt', color='orange', label='Medium')
sns.ecdfplot(data=high_priced_homes, x='YearBuilt', color='green', label='High')
sns.ecdfplot(data=premium_priced_homes, x='YearBuilt', color='red', label='Premium')
# 添加标题与标签
plt.title('ECDF of Year Built by Price Category', fontsize=16)
plt.xlabel('Year Built', fontsize=14)
plt.ylabel('ECDF', fontsize=14)
plt.legend(title='Price Category', title_fontsize=14, fontsize=14)
# 显示图形
plt.show()
下方的 ECDF 图展示了你所分类数据的总体概况。
ECDF(经验累积分布函数)是一种统计工具,用于描述数据集中各点的分布情况。它表示低于或等于某个值的数据点所占的比例或百分比。本质上,它能帮助你可视化数据的分布形态、离散程度和集中趋势。ECDF 图特别适用于不同数据集之间的比较。注意,每个价格类别的曲线共同描绘出历年房屋建设的趋势图景。
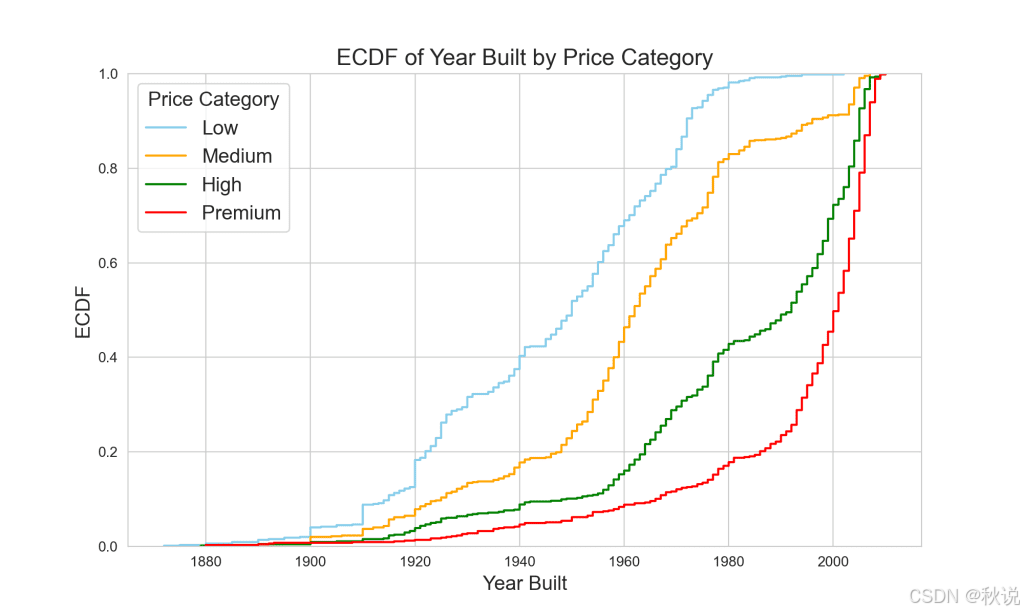
从图中可以明显看出,低价与中价房屋更多建于早期,而高价与高端房屋则倾向于近年建造。通过了解房龄在不同价格区间的显著差异,你有了使用 Pandas.concat() 的充分理由。
使用 Pandas.concat() 堆叠数据集
作为数据科学家,你经常需要堆叠数据集或其部分,以获取更深层次的洞察。
Pandas.concat() 是执行此类任务的瑞士军刀,它能以高精度和灵活性合并 DataFrame。该函数类似于 SQL 的 UNION 操作,可将不同数据集的行合并。
但 Pandas.concat() 更为灵活,它支持垂直与水平拼接,当你处理列名不匹配或需按公共列对齐的数据集时,这一特性尤为关键,大大拓宽了分析范围。
如下示例展示如何将分段后的 DataFrame 合并,用于比较“可负担房产”和“高端房产”两大市场类别:
# 将 Low 与 Medium 类别堆叠为 "affordable_homes"
affordable_homes = pd.concat([low_priced_homes, medium_priced_homes])
# 将 High 与 Premium 类别堆叠为 "luxury_homes"
luxury_homes = pd.concat([high_priced_homes, premium_priced_homes])
通过此操作,你可以并列分析两类房产的特征差异。
使用 Pandas 透视与合并
在将数据集划分为 “affordable” 与 “luxury” 房屋并分析其建造年份分布后,你可以转向另一个影响房价的维度——房屋设施,此处重点关注壁炉数量。
在进行数据合并(Pandas.merge(),类似 SQL 的 JOIN 操作)之前,先以更细致的方式审视数据。
透视表(Pivot Table)是汇总与分析特定数据点的优秀工具。它能对数据进行聚合并揭示模式,为后续合并操作提供依据。通过创建透视表,你可以获得按壁炉数量分类的平均居住面积与房屋数量的有序概览。
此分析不仅深化了你对市场分层的理解,也为展示更复杂的合并方法奠定了基础。
使用透视表创建有洞察力的汇总
下面构建 “affordable” 与 “luxury” 房屋类别的透视表。
透视表汇总了平均居住面积(GrLivArea)并统计各壁炉数量下的房屋数量。
该分析揭示了房屋吸引力与价值的关键因素——壁炉的存在与数量——及其在不同市场区间的差异。
# 创建透视表,计算平均居住面积与房屋数量
pivot_affordable = affordable_homes.pivot_table(index='Fireplaces',
aggfunc={'GrLivArea': 'mean', 'Fireplaces': 'count'})
pivot_luxury = luxury_homes.pivot_table(index='Fireplaces',
aggfunc={'GrLivArea': 'mean', 'Fireplaces': 'count'})
# 重命名列与索引
pivot_affordable.rename(columns={'GrLivArea': 'AvLivArea', 'Fireplaces': 'HmCount'}, inplace=True)
pivot_affordable.index.name = 'Fire'
pivot_luxury.rename(columns={'GrLivArea': 'AvLivArea', 'Fireplaces': 'HmCount'}, inplace=True)
pivot_luxury.index.name = 'Fire'
# 查看透视表
print(pivot_affordable)
print(pivot_luxury)
第一张透视表来自 “affordable” 房屋数据集,结果显示此类房产多数没有壁炉:
HmCount AvLivArea
Fire
0 931 1159.050483
1 323 1296.808050
2 38 1379.947368
第二张透视表来自 “luxury” 房屋数据集,显示该组房产的壁炉数量从 0 到 4 个不等,其中单壁炉最为常见:
HmCount AvLivArea
Fire
0 310 1560.987097
1 808 1805.243812
2 157 1998.248408
3 11 2088.090909
4 1 2646.000000
通过这些透视表,你已将数据提炼为适合下一步分析的形式——使用 Pandas.merge() 结合这些洞察,观察特征在更广市场中的交互关系。
进阶版透视表
上面的透视表属于最基础的类型。更高级的版本允许在参数中同时指定索引与列。
原理相同:选择两个字段,一个作为 index,另一个作为 columns,再按 aggfunc 指定的方式聚合成矩阵。
示例如下,结果与前述类似:
pivot = Ames.pivot_table(index="Fireplaces",
columns="Price_Category",
aggfunc={'GrLivArea':'mean', 'Fireplaces':'count'})
print(pivot)
输出结果:
Fireplaces GrLivArea
Price_Category High Low Medium Premium High Low Medium Premium
Fireplaces
0 228.0 520.0 411.0 82.0 1511.912281 1081.496154 1257.172749 1697.439024
1 357.0 116.0 207.0 451.0 1580.644258 1184.112069 1359.961353 1983.031042
2 52.0 9.0 29.0 105.0 1627.384615 1184.888889 1440.482759 2181.914286
3 5.0 NaN NaN 6.0 1834.600000 NaN NaN 2299.333333
4 NaN NaN NaN 1.0 NaN NaN NaN 2646.000000
你可以看到结果一致,例如零壁炉的低价与中价房数量分别为 520 与 411,总和为 931,与之前的结果相符。
第二层列标签为 Low、Medium、High、Premium,因为在 pivot_table() 中将 “Price_Category” 指定为列参数。
传入 aggfunc 的字典决定了最上层列的分组。
利用 Pandas.merge() 进行对比分析
在揭示了壁炉数量、房屋数量与居住面积之间的关系后,你可以更进一步。通过 Pandas.merge(),你可以叠加这些洞察,就像 SQL 的 JOIN 操作那样,根据公共列将两个或多个表的记录结合在一起。此技术允许基于共同属性合并分段数据,从而实现超越分类层面的比较分析。
外连接:全面视图
第一个操作使用外连接(outer join)来合并“affordable” 与 “luxury” 房屋数据集,确保不会丢失任何一类数据。这种方法尤其有助于展示房屋的完整分布,无论它们是否拥有相同数量的壁炉。
pivot_outer_join = pd.merge(pivot_affordable, pivot_luxury, on='Fire', how='outer', suffixes=('_aff', '_lux')).fillna(0)
print(pivot_outer_join)
输出结果:
HmCount_aff AvLivArea_aff HmCount_lux AvLivArea_lux
Fire
0 931.0 1159.050483 310 1560.987097
1 323.0 1296.808050 808 1805.243812
2 38.0 1379.947368 157 1998.248408
3 0.0 0.000000 11 2088.090909
4 0.0 0.000000 1 2646.000000
外连接的作用类似右连接,它捕获了两个市场中存在的所有壁炉类别。
可以注意到,在“affordable” 类别中没有 3 或 4 个壁炉的房屋。
由于两张表中都存在 “HmCount” 与 “AvLivArea” 列,因此需要通过 suffixes 参数为列名添加后缀。HmCount_aff 为 0 的行仅作为外连接的占位符,用于与 pivot_luxury 对齐。
内连接:聚焦交集
接着使用内连接(inner join),聚焦于“affordable” 与 “luxury” 房屋共享相同壁炉数量的交集部分。此方法突显两类市场的共性。
pivot_inner_join = pd.merge(pivot_affordable, pivot_luxury, on='Fire', how='inner', suffixes=('_aff', '_lux'))
print(pivot_inner_join)
输出结果:
HmCount_aff AvLivArea_aff HmCount_lux AvLivArea_lux
Fire
0 931 1159.050483 310 1560.987097
1 323 1296.808050 808 1805.243812
2 38 1379.947368 157 1998.248408
在此情境下,内连接的效果类似左连接,只保留两个数据集中共同存在的壁炉类别。
没有显示 3 和 4 个壁炉的行,因为在 pivot_affordable 中不存在这些记录。
交叉连接:全组合分析
最后,交叉连接(cross join)可以生成“affordable” 与 “luxury” 房屋特征的所有可能组合,即两张表行的笛卡尔积。这种方法有助于进行假设性分析或观察不同特征在整体市场中的潜在交互。
# 重置索引以便执行交叉连接
pivot_affordable.reset_index(inplace=True)
pivot_luxury.reset_index(inplace=True)
pivot_cross_join = pd.merge(pivot_affordable, pivot_luxury, how='cross', suffixes=('_aff', '_lux')).round(2)
print(pivot_cross_join)
结果如下,显示交叉连接的所有组合,但在此数据集中不提供新的洞察:
Fire_aff HmCount_aff AvLivArea_aff Fire_lux HmCount_lux AvLivArea_lux
0 0 931 1159.05 0 310 1560.99
1 0 931 1159.05 1 808 1805.24
2 0 931 1159.05 2 157 1998.25
3 0 931 1159.05 3 11 2088.09
4 0 931 1159.05 4 1 2646.00
5 1 323 1296.81 0 310 1560.99
6 1 323 1296.81 1 808 1805.24
7 1 323 1296.81 2 157 1998.25
8 1 323 1296.81 3 11 2088.09
9 1 323 1296.81 4 1 2646.00
10 2 38 1379.95 0 310 1560.99
11 2 38 1379.95 1 808 1805.24
12 2 38 1379.95 2 157 1998.25
13 2 38 1379.95 3 11 2088.09
14 2 38 1379.95 4 1 2646.00
从合并数据中提取洞察
三种连接操作揭示了住房市场的不同面向:
- 外连接:展现最全面的房屋分布,强调不同价位在壁炉等设施上的多样性。
- 内连接:聚焦两类房屋共享的特征,帮助发现市场的共同标准。
- 交叉连接:生成全组合结果,用于假设分析或探索市场潜在扩展空间。
观察结果
可负担型住房(affordable homes):
- 无壁炉房屋平均居住面积约为 1159 平方英尺,为最大类别。
- 当壁炉数量增至 1 个时,平均居住面积上升至 约 1296 平方英尺。
- 拥有 2 个壁炉的房屋虽数量较少,但平均面积增至 约 1379 平方英尺,表明更多设施与更大空间存在正相关。
高端住房(luxury homes):
- 无壁炉房屋起点面积为 1560 平方英尺,显著高于可负担房型。
- 单壁炉房屋平均面积约 1805 平方英尺。
- 双壁炉房屋面积进一步提升至 约 1998 平方英尺。
- 拥有三或四个壁炉的少数房屋面积最大,四壁炉房屋平均面积达 2646 平方英尺。
这些结果表明,壁炉等设施不仅提升房屋吸引力,也与更大的居住空间密切相关,尤其在从可负担市场迈向高端市场时这一趋势更加明显。
总结
本文系统探讨了使用 Python 与 Pandas 进行数据整合的关键技术。
从依据房价分类对数据进行分段、可视化建造年份趋势,到使用 Pandas.concat() 堆叠数据集,再到通过透视表汇总关键特征,最后借助 Pandas.merge() 执行外、内、交叉三种合并操作以比较市场特征,你掌握了多种核心数据处理与分析方法。
通过这些技术,数据科学家可高效整合复杂数据,发现潜在模式,并提取推动决策的有价值洞察。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)