神经网络加速器架构设计中的算力与带宽优化权衡
摘要:本文探讨神经网络加速器中算力与带宽的协同优化问题。算力(TOPS/TFLOPS)反映计算能力,带宽(GB/s)决定数据传输速率。重点分析卷积层的协同设计:1)输入带宽优化中,推导特征图传输时间、权重加载时间和运算时间的计算公式,提出带宽-算力比(BoC)指标评估匹配程度;2)输出带宽设计中,建立Conv模块与下游模块的吞吐量匹配模型,推导标准卷积、分组卷积和深度可分离卷积的吞吐量公式。通过量
目录
算力与带宽是决定神经网络加速器性能上限的核心要素,其协同匹配程度直接关乎架构设计的成败。在神经网络加速器的研发过程中,算力与带宽的动态平衡始终是设计决策的核心。
算力:通常以TOPS(每秒万亿次操作)或TFLOPS(每秒万亿次浮点运算)衡量,反映计算单元的并行处理能力。
带宽:以GB/s或TB/s为单位,衡量内存或网络的数据传输速率,决定数据供给的快慢。
1.算力与输入带宽的协同优化
算力需求涵盖卷积运算、池化处理、激活函数计算、归一化操作等多个神经网络核心计算环节;而带宽需求则涉及权重数据、输入特征图、输出特征图的传输,同时包含中间计算结果流转及子模块间数据交互等场景。尽管精准量化算力与带宽存在复杂性,但通过合理简化模型,可为架构设计提供关键参考依据。以下重点分析卷积层的算力与带宽计算方法。定义输入特征图的传输时间 TB ,其表达式为:
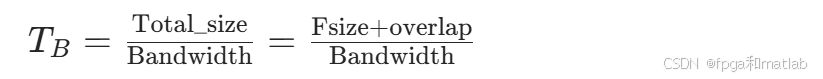
其中,Fsize代表输入特征图的存储容量,overlap为卷积操作中重复读取数据的存储开销,Bandwidth表示读取操作的带宽。
在实际应用中,输入特征图通常尺寸较大(例如1920×1080分辨率),此时可通过分片技术将卷积层拆解为多个子块并行处理,优化设计的加速器能够避免整幅特征图的重复读取。考虑到overlap通常远小于Fsize,可对公式进一步简化:
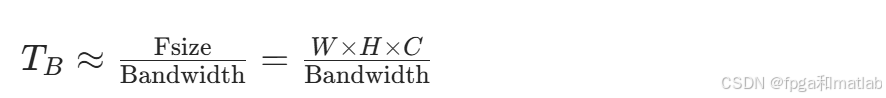
式中,W、H分别为输入特征图的宽度和高度,C为输入特征图的通道数。
定义权重加载时间 TW,表达式如下:

其中,S为卷积核宽度,R为卷积核高度,K为输出特征图的通道数。
卷积层的运算时间TC定义为:

式中,Total_MAC为卷积层所需的总乘加运算次数,MAC_num_instanced为硬件实现的乘加器数量,utilization为乘加器的利用率,W′、H′分别为输出特征图的宽度和高度。
为量化带宽与算力的匹配程度,定义带宽-算力比(Bandwidth over Compute, BoC):

举例说明:
假设卷积核尺寸5×5,步长1,输出通道数128,乘加器数量512,内部缓存带宽32B/cycle。
BoC= 512/(32×128×5×5)≈0.005
此时带宽资源充足。
假设卷积核尺寸3×3,步长1,输出通道数2,乘加器数量1024,内部缓存带宽32B/cycle。
BoC= 1024/(32×2×3×3)≈1.778
此时带宽资源不足。
2. 算力与输出带宽的协同设计
通过BoC指标完成带宽与卷积运算单元数量的权衡后,需进一步匹配卷积(Conv)模块与下游激活(Activation)模块的带宽和算力。子模块间的数据通路带宽通常仅需与两端接口匹配,无显著面积限制,设计难度较低;而Activation模块的算力需与Conv模块的吞吐量严格匹配,是架构优化的关键环节。定义Conv模块的吞吐量(ThroughPut),即单位时间内输出的数据量:
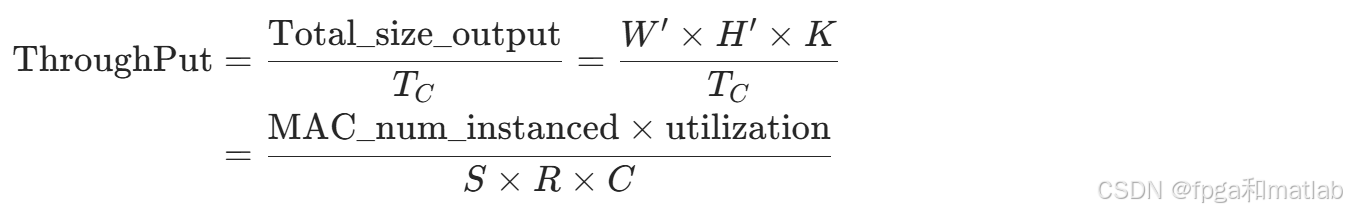
对于分组卷积:吞吐量公式调整为:

对于深度可分离卷积:由于输入通道数与分组数相等(C=Group_num),吞吐量公式简化为:
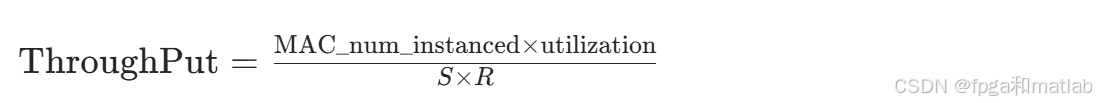

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐

 19
19 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)