QMT 之用 KMeans 聚类寻找股票支撑位 / 压力位(下)- 实战代码实现
本文介绍了利用KMeans聚类算法自动识别股票支撑位和压力位的Python实现方法。通过QMT的xtquant库获取股票历史数据,使用scikit-learn的KMeans算法对收盘价进行5类聚类,将聚类中心作为潜在的支撑/压力位。代码包含数据获取、聚类分析和可视化三个核心步骤,并对结果进行解读:聚类中心代表股价密集成交区,低位中心为支撑位,高位中心为压力位。该方法可为交易决策提供量化参考,如确定
前言
在上一篇内容中,我们介绍了利用 KMeans 聚类算法寻找股票支撑位和压力位的核心原理,本篇将聚焦实战落地,通过 Python 结合 QMT 的 xtquant 库实现完整的 KMeans 聚类找支撑 / 压力位的代码,小白也能直接照着运行,同时讲解如何将聚类结果应用到实际交易中。
一、核心思路回顾
股票的支撑位和压力位本质是价格密集成交区,股价在这些位置容易出现反弹或遇阻。KMeans 聚类能自动识别股价序列中的价格中枢,这些聚类中心就是潜在的支撑 / 压力位,我们通过 5 类聚类划分出股价的关键运行区间,为交易提供参考。
二、环境准备
实现本次实战需要安装以下 Python 库,直接通过 pip 安装即可:
pip install xtquant pandas numpy matplotlib mplfinance scikit-learn
- xtquant:QMT 的量化交易库,用于获取股票历史行情数据;
- pandas/numpy:数据处理与数值计算;
- matplotlib/mplfinance:行情与聚类结果可视化;
- scikit-learn:机器学习库,提供 KMeans 聚类算法。
三、完整代码实现
3.1 代码整体实现
以下是最简版可直接运行的代码,包含行情获取、KMeans 聚类、结果可视化三大核心步骤,代码中做了详细注释:
# 导入所需库
from xtquant import xtdata
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 关闭plt的警告信息(可选)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
plt.rcParams['axes.unicode_minus'] = False # 显示负号
xtdata.enable_hello = False # 关闭xtdata的欢迎信息
def get_hq(code, start_date='19900101', period='1d', dividend_type='front_ratio', count=-1):
"""
从QMT的xtquant获取股票历史行情数据
:param code: 股票代码,如000001.sz
:param start_date: 开始日期,格式YYYYMMDD
:param period: 周期,1d(日)、1w(周)、1mon(月)
:param dividend_type: 除权方式,front_ratio等比前复权(推荐)
:param count: 获取数据条数,-1为获取全部
:return: 整理后的DataFrame行情数据
"""
# 下载历史数据
xtdata.download_history_data(stock_code=code, period=period, incrementally=True)
# 获取行情数据(开盘、最高、最低、收盘、成交量、成交额、前收盘价)
history_data = xtdata.get_market_data_ex(['open', 'high', 'low', 'close', 'volume', 'amount', 'preClose'], code, start_date=start_date, count=count)
df = history_data[code]
# 处理索引为日期格式
df.index = pd.to_datetime(df.index.astype(str), format='%Y%m%d')
df['date'] = df.index
return df
# 1. 获取行情数据:以深发展A(000001.sz)2024年至今的日K为例
df = get_hq('000001.sz', start_date='20240101', period='1d', dividend_type='front_ratio', count=-1)
# 提取收盘价作为聚类特征,reshape满足KMeans输入要求
prices = df['close'].values.reshape(-1, 1)
# 2. KMeans聚类:设置5个聚类中心(可根据需求调整n_clusters)
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=5, random_state=42).fit(prices)
# 获取聚类中心并排序,便于后续分析支撑/压力位
centers = sorted(kmeans.cluster_centers_.flatten())
# 3. 结果可视化:绘制收盘价曲线+聚类中心(支撑/压力位)水平线
plt.figure(figsize=(10, 6))
plt.plot(df.index, df['close'], label="收盘价", color="blue", linewidth=1.5)
# 绘制每个聚类中心的红色水平线
for c in centers:
plt.axhline(c, color="red", linestyle="-", alpha=0.6, label=f"价格中枢{round(c,2)}" if c == centers[0] else "")
plt.title('KMeans聚类寻找支撑/压力位 - 000001.sz', fontsize=14)
plt.xlabel('日期', fontsize=12)
plt.ylabel('收盘价(元)', fontsize=12)
plt.legend(loc='best')
plt.grid(alpha=0.3)
plt.show()
# 打印聚类中心(潜在的支撑/压力位)
print("聚类中心(可能的支撑/压力位):", [round(x, 2) for x in centers])
3.2 代码关键说明
- 行情获取函数
get_hq:封装了 xtquant 的行情下载与数据整理,默认使用等比前复权,复权后的数据能更真实反映股价的实际走势,避免除权除息对价格的干扰; - KMeans 参数设置:
n_clusters=5表示划分 5 个价格中枢,random_state=42保证聚类结果可复现; - 聚类中心排序:对聚类中心进行升序排序,方便后续从低到高判断支撑、压力位;
- 可视化优化:添加了中文显示、网格、图例等,让结果更易读。
四、运行结果解读
代码运行后,会输出聚类中心数值和行情可视化图:
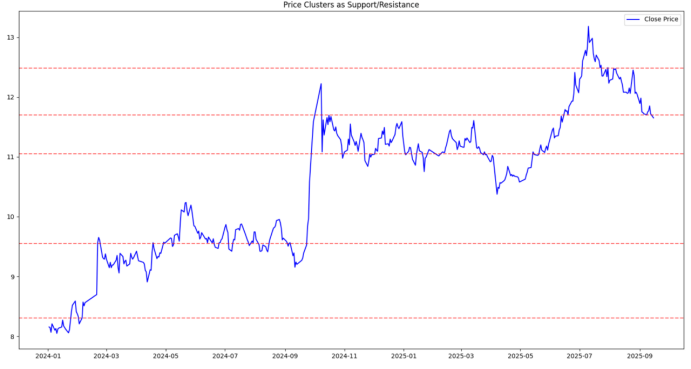
- 数值结果:会打印出 5 个排序后的价格中枢,例如
[148.50, 152.70, 160.30, 165.80, 172.10],这些数值是股价的关键密集成交区; - 图形结果:蓝色曲线为股票收盘价走势,红色水平线为聚类中心,每条红线都是股价的关键位置。
这些红色水平线对应的价格,就是我们通过算法识别出的潜在支撑位和压力位,可以把它们理解为股价运行的 “楼层”,股价在不同 “楼层” 会出现不同的市场行为。
五、聚类结果在交易中的实际应用
KMeans 聚类得到的价格中枢并非绝对的支撑 / 压力位,但能为交易提供高参考价值的量化依据,核心应用场景分为两大方向:
5.1 判断支撑位与压力位
通过聚类中心的高低位置,直接划分支撑和压力区间:
- 支撑位:股价下跌到中低位置的聚类中心(如上述示例的 152.70)附近时,市场存在大量成交承接盘,股价大概率出现反弹,是低吸的潜在位置;
- 压力位:股价上涨到中高位置的聚类中心(如上述示例的 165.80、172.10)附近时,市场存在大量抛压盘,股价突破难度大,是高抛的潜在位置。
注意:低位的聚类中心支撑性更强,高位的聚类中心压力性更强,中间位置的聚类中心为股价的震荡中枢。
5.2 作为止损与止盈的参考依据
支撑 / 压力位不仅是进出场信号,更是风险管理的核心工具,能让止损、止盈设置更具量化性,避免主观臆断:
- 止损设置:若在支撑位附近(如 152.70)买入,当股价有效跌破该支撑位时,说明市场情绪弱于预期,原有上涨逻辑被破坏,应果断止损,避免更大亏损;
- 止盈设置:若在低位(如 150.00)买入,当股价上涨到压力位附近(如 165.80)时,可进行部分止盈,落袋为安;若股价突破压力位,可持有观望,看向上一个更高的聚类中心。
六、拓展与优化建议
本次实现的是最简版代码,在实际量化交易中,可从以下方面优化,让结果更精准:
- 调整聚类数量:
n_clusters可根据股票的波动特性调整,波动小的股票可设置 3-4 类,波动大的股票可设置 6-7 类; - 加入更多特征:除了收盘价,可结合开盘价、最高价、最低价的均值进行聚类,更全面反映成交价格;
- 结合成交量:在价格中枢附近,若成交量放大,说明该位置的支撑 / 压力有效性更强,可加入成交量筛选;
- 动态更新聚类:通过定时任务更新行情数据,重新聚类,适应股价的动态变化;
- 结合其他指标:将 KMeans 聚类结果与 MA、MACD、RSI 等技术指标结合,形成多因子交易策略,提高胜率。
七、总结
本文通过 Python+QMT+KMeans 实现了量化寻找股票支撑 / 压力位的完整流程,核心是利用聚类算法识别股价的密集成交区,摆脱了传统技术分析中主观画趋势线的弊端,为交易提供了量化依据。
该方法的优势是自动化、可复现、适应性强,适用于不同周期(日 K、周 K、月 K)和不同标的(股票、期货、ETF);需要注意的是,量化分析只是交易的辅助工具,实际操作中还需结合市场情绪、基本面等因素综合判断。
快去用自己关注的股票代码试试吧,看看 KMeans 能为你挖掘出哪些关键的支撑 / 压力位!
原创不易,欢迎点赞、收藏、关注! 后续会继续分享 QMT 量化交易和机器学习在金融中的实战应用,敬请期待~

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)