MapReduce工作流程:从MapTask到Yarn机制深度解析
摘要 MapReduce作为Hadoop核心计算框架,通过"分而治之"思想将大数据任务分解为并行子任务。本文系统解析MapReduce三大核心机制: MapTask执行机制:从数据分片(InputSplit)到RecordReader读取,通过Map函数处理生成中间键值对,经Combiner本地聚合后按Partitioner分区。关键优化包括减少对象创建、批量处理和合理使用Co
MapReduce工作流程:从MapTask到Yarn机制深度解析
🌟 你好,我是 励志成为糕手 !
🌌 在代码的宇宙中,我是那个追逐优雅与性能的星际旅人。
✨ 每一行代码都是我种下的星光,在逻辑的土壤里生长成璀璨的银河;
🛠️ 每一个算法都是我绘制的星图,指引着数据流动的最短路径;
🔍 每一次调试都是星际对话,用耐心和智慧解开宇宙的谜题。
🚀 准备好开始我们的星际编码之旅了吗?
目录
摘要
MapReduce作为Hadoop生态系统的核心计算框架,自诞生以来就彻底改变了大数据处理的方式。它基于"分而治之"的思想,将复杂的大数据处理任务分解为可并行执行的子任务,极大地提高了数据处理的效率和可扩展性。在当今数据量呈爆炸式增长的时代,MapReduce仍然是理解分布式计算原理和构建高效数据处理系统的基础。
本文将从三个核心维度深度解析MapReduce的工作流程:首先,详细探讨MapTask的执行机制,包括数据分片、映射处理、本地排序等关键环节,揭示Map阶段如何将原始数据转换为中间键值对;其次,深入分析ReduceTask的工作原理,涵盖数据拉取、归并排序、规约计算等步骤,阐述Reduce阶段如何将中间结果聚合为最终输出;最后,全面讲解Yarn的工作机制,特别是作业提交的完整流程,包括ResourceManager与NodeManager的协作、容器分配、任务调度等核心内容,揭示MapReduce如何在Yarn的管理下高效运行。
通过对这三个方面的系统讲解,读者将能够深入理解MapReduce的内部工作原理,掌握分布式计算的核心思想,并能够在实际项目中更好地应用和优化MapReduce作业。无论是大数据初学者还是有一定经验的数据工程师,本文都将为您提供有价值的参考和指导,帮助您在大数据处理的道路上更进一步。
一、MapTask执行机制深度解析
1.1 MapTask概述
MapTask是MapReduce框架中负责执行Map阶段任务的核心组件。每个MapTask处理一个特定的数据分片(InputSplit),将原始数据转换为中间键值对(Intermediate Key-Value Pairs)。MapTask的执行效率直接影响整个MapReduce作业的性能,因此深入理解其工作原理对于优化MapReduce作业至关重要。
对应的,我们可以把MapTask分为五个阶段,对应的是Read,Map,Collect,spill,merge。以下是更为详细的阐述。
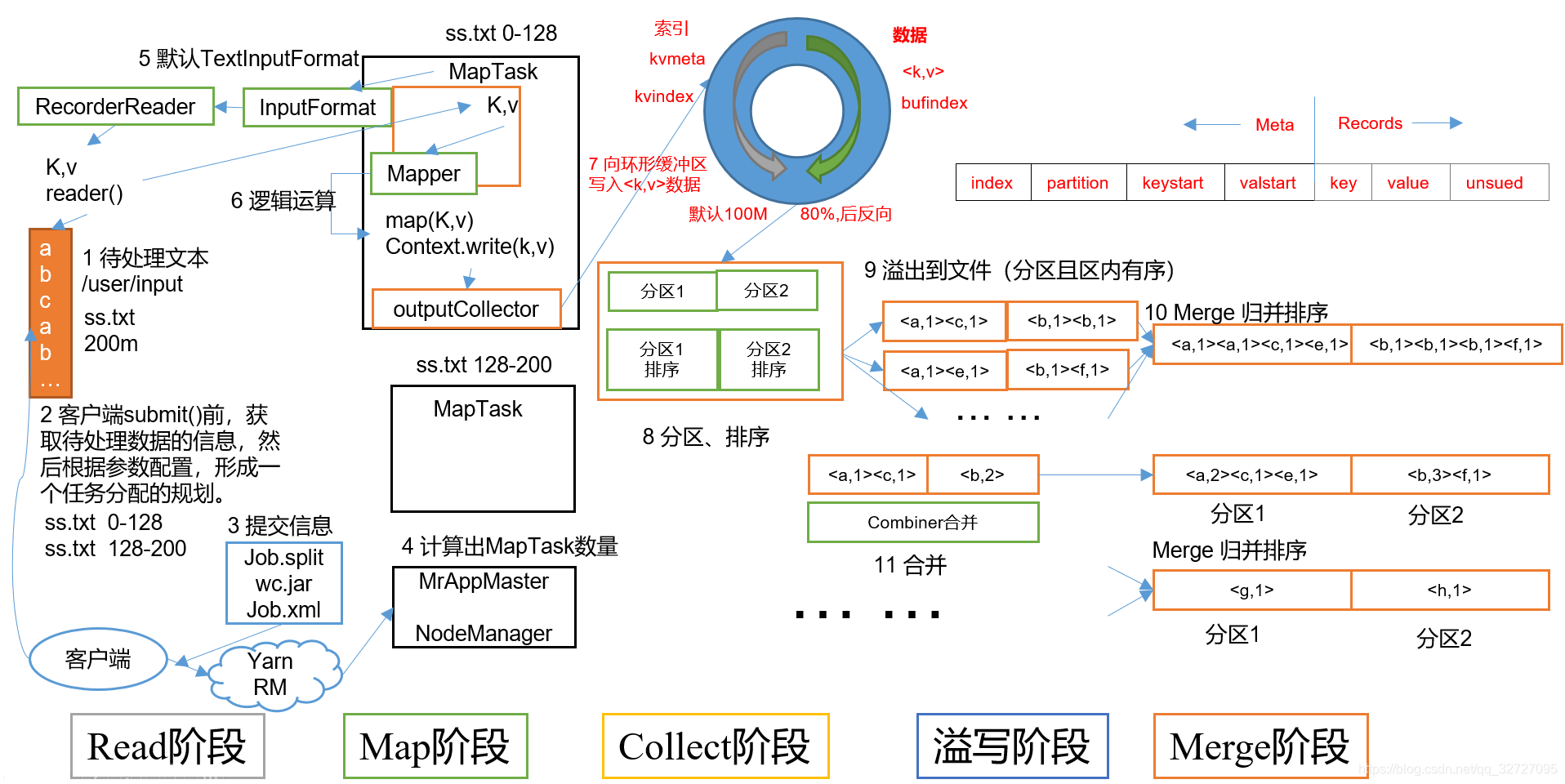
1.2 数据分片与InputFormat
在Map阶段开始之前,Hadoop会将输入数据划分为多个数据分片(InputSplit)。每个InputSplit对应一个MapTask,因此数据分片的大小和数量直接决定了MapTask的数量。
InputFormat是Hadoop中用于描述输入数据格式的接口,它负责:
- 计算输入数据的分片信息
- 提供RecordReader用于读取分片数据
- 验证输入数据的格式
常用的InputFormat实现包括:
| 实现类 | 适用场景 | 数据分割方式 | 键类型 | 值类型 |
|---|---|---|---|---|
| TextInputFormat | 文本文件处理 | 按行分割,每行作为一个记录 | LongWritable(行偏移量) | Text(行内容) |
| SequenceFileInputFormat | 二进制数据处理 | 保持SequenceFile的记录边界 | 自定义 | 自定义 |
| KeyValueTextInputFormat | 键值对数据处理 | 按行分割,每行按分隔符拆分为键值对 | Text(分隔符前的内容) | Text(分隔符后的内容) |
| NLineInputFormat | 需要控制记录数量的场景 | 按指定行数(N)分割 | LongWritable(行偏移量) | Text(N行内容) |
| CombineFileInputFormat | 小文件处理优化 | 将多个小文件合并为一个InputSplit | 自定义 | 自定义 |
1.3 RecordReader与数据读取
RecordReader是实际负责读取数据的组件,它将InputSplit转换为Map函数可以处理的键值对。对于TextInputFormat,RecordReader会将每行数据转换为一个键值对,其中键是该行数据在文件中的偏移量,值是该行的内容。
RecordReader的工作流程
- 初始化:在MapTask开始时创建RecordReader实例,并初始化相关资源
- 数据读取:通过
nextKeyValue()方法逐行读取数据,每次调用返回一个键值对 - 键值获取:通过
getCurrentKey()和getCurrentValue()方法获取当前读取的键值对 - 资源释放:在数据读取完成后,通过
close()方法释放相关资源
TextInputFormat的RecordReader实现
对于默认的TextInputFormat,其对应的RecordReader是LineRecordReader。LineRecordReader会将每行数据转换为一个键值对:
- 键:LongWritable类型,表示该行数据在文件中的字节偏移量
- 值:Text类型,表示该行的实际内容(不包括换行符)
这种设计使得Map函数可以精确定位每条记录的位置,同时获取完整的记录内容。 以上我们可以把这个过程称为Read阶段。核心是把数据以K-V键值对的形式读取进来,以完成、方便后续操作。
1.4 Map函数执行
Map函数是用户定义的核心处理逻辑,它接收RecordReader提供的键值对,经过处理后输出中间键值对。Map函数的执行是并行的,每个MapTask独立执行自己的Map函数。
Map函数的生命周期
- 初始化:调用
setup()方法进行初始化操作,如加载配置、创建临时对象等 - 数据处理:调用
map()方法处理每个输入键值对,输出中间键值对 - 清理资源:调用
cleanup()方法释放资源,如关闭文件句柄、数据库连接等
下面是一个简单的WordCount示例中的Map函数实现:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
// 定义输出值为1的IntWritable对象,避免重复创建
private final static IntWritable one = new IntWritable(1);
// 定义输出键Text对象
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将输入值转换为字符串
String line = value.toString();
// 按空格分割行内容
String[] words = line.split(" ");
// 遍历每个单词
for (String str : words) {
// 设置输出键
word.set(str);
// 输出键值对<单词, 1>
context.write(word, one);
}
}
}
关键行点评:
map方法:Map函数的核心处理逻辑,接收输入键值对并输出中间键值对line.split(" "):将行内容按空格分割为单词数组context.write(word, one):将处理结果写入上下文,供后续阶段使用
Map函数的并行执行模型
Map函数的并行执行是Hadoop扩展性的关键。每个MapTask在独立的Java虚拟机(JVM)中运行,处理分配给它的InputSplit。Hadoop会根据集群的计算资源(CPU、内存)自动调整同时运行的MapTask数量。
为了提高Map函数的执行效率,用户可以考虑以下优化策略:
- 减少对象创建:如WordCount示例中所示,复用对象减少GC压力
- 批量处理:对于可以批量处理的场景,减少
context.write()的调用次数 - 本地化计算:尽量在Map阶段完成更多计算,减少数据传输
- 计数器使用:利用Hadoop的计数器功能进行统计,避免额外的输出
1.5 本地聚合(Combiner)
Combiner是MapReduce中的一个可选优化组件,它在MapTask本地对中间键值对进行聚合,减少数据传输量。Combiner的实现通常与Reducer相同,但它仅在本地执行,不会影响最终结果。
-
Combiner的工作原理
(1). 触发条件:当Map函数输出的中间键值对达到一定阈值时触发Combiner
(2). 聚合逻辑:对相同键的中间值进行合并(如求和、计数等)
(3). 输出结果:将聚合后的键值对写入本地磁盘 -
Combiner的优势
(1). 减少网络传输:通过本地聚合减少发送到Reducer的数据量
(2). 降低Reducer负载:减少Reducer需要处理的数据量
(3). 提高作业效率:缩短作业的整体执行时间 -
Combiner的使用注意事项
虽然Combiner可以显著提高性能,但并非所有场景都适用:
适合的操作:求和、计数、最大值、最小值等幂等操作
不适合的操作:平均值等非幂等操作(可能导致结果错误)
执行次数:Hadoop不保证Combiner的执行次数,因此Combiner的逻辑必须是幂等的
1.6 分区(Partitioning)
分区是将中间键值对分配给不同ReduceTask的过程。默认情况下,Hadoop使用HashPartitioner,它基于键的哈希值将键值对分配到不同的分区。用户也可以自定义Partitioner来实现特定的分区逻辑。
以下是默认的HashPartitioner的核心逻辑:
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
该实现确保了相同键的键值对会被分配到同一个分区,不同键的键值对可能被分配到不同分区(取决于哈希值)。
至此,我们把combine和partition这两部分用于合并K-V键值对的过程称为collect阶段,可以理解为是按照不同的键去合并、分区等。
1.7 溢写(Spill)到磁盘
Map函数输出的中间键值对首先存储在内存缓冲区中,这个缓冲区由mapreduce.task.io.sort.mb参数控制,默认大小为100MB。为了防止缓冲区溢出,当缓冲区使用率达到一定阈值(由mapreduce.map.sort.spill.percent参数控制,默认80%)时,会触发溢写(Spill)操作,将数据写入到本地磁盘。
溢写前的准备工作
在溢写开始之前,系统会对缓冲区中的中间键值对执行以下关键操作:
-
内存排序(In-memory Sort):
- 使用快速排序算法(QuickSort)对缓冲区中的键值对按键进行排序
- 排序确保相同键的键值对聚集在一起,为后续的聚合操作奠定基础
- 排序的时间复杂度为O(n log n),其中n是缓冲区中的键值对数量
-
再次分区(Repartitioning):
- 对排序后的键值对再次执行分区操作
- 确保每个键值对被分配到正确的分区,以便后续ReduceTask能够准确拉取
- 分区结果决定了键值对在溢写文件中的存储位置
-
可选的Combiner操作:
- 如果用户定义了Combiner,并且当前溢写的数据量达到一定阈值,会再次执行Combiner
- 本地聚合进一步减少数据量,降低磁盘I/O和网络传输开销
- Combiner的执行需要保证聚合操作的幂等性,避免影响最终结果
溢写文件的结构
溢写生成的文件具有特定的结构,主要包括:
- 索引区:存储键的偏移量信息,便于快速定位特定键的位置
- 数据区:存储实际的键值对数据
- 元数据区:存储文件的基本信息,如分区数量、记录数量等
每个溢写文件都被划分为多个分区段,每个分区段对应一个ReduceTask。这种结构使得ReduceTask能够高效地拉取属于自己的分区数据,无需扫描整个文件。
溢写相关的配置参数
mapreduce.task.io.sort.mb:内存缓冲区大小,默认100MBmapreduce.map.sort.spill.percent:溢写触发阈值,默认0.8(80%)mapreduce.map.sort.spill.compression.enabled:是否启用溢写数据压缩,默认falsemapreduce.map.sort.spill.compression.codec:溢写数据压缩编解码器,默认org.apache.hadoop.io.compress.DefaultCodec
1.8 本地合并(Merge)
当MapTask处理完所有输入数据后,通常会生成多个溢写文件。为了提高后续ReduceTask的拉取效率,MapTask会将所有溢写文件合并成一个最终的中间文件。合并过程是MapTask执行的最后一个关键步骤,对作业的整体性能有重要影响。
合并的触发条件
合并操作在以下情况下触发:
- 所有Map函数执行完成,不再有新的数据输出到缓冲区
- 内存缓冲区中的数据已经全部溢写到磁盘
- 当前存在多个溢写文件需要合并
合并策略与过程
MapTask采用多轮合并策略,具体过程如下:
-
合并轮次计算:
- 系统会根据溢写文件的数量和
mapreduce.task.io.sort.factor参数(默认10)计算合并轮次 - 每轮合并最多处理
mapreduce.task.io.sort.factor个文件 - 例如,如果有25个溢写文件,
sort.factor=10,则需要进行3轮合并(10→10→5)
- 系统会根据溢写文件的数量和
-
多轮归并排序:
- 每轮合并都执行归并排序(Merge Sort),保持键的有序性
- 合并过程中,系统会同时打开多个溢写文件,按键的顺序逐个读取键值对
- 相同键的键值对会被聚集在一起,为可选的Combiner操作提供条件
-
可选的Combiner优化:
- 在合并过程中,如果用户定义了Combiner,系统会对相同键的键值对执行Combiner操作
- 这是Map阶段最后一次使用Combiner减少数据量的机会
- 合理使用Combiner可以显著减少最终中间文件的大小
-
最终中间文件生成:
- 经过多轮合并后,所有溢写文件被合并成一个最终的中间文件
- 最终文件保持分区结构和键的有序性
- 系统会生成一个索引文件,记录每个分区在最终文件中的偏移量信息
1.9 MapTask执行流程图
图1:MapTask执行流程图 - 展示了MapTask从数据读取到生成最终中间文件的完整流程,包括数据分片、Map函数处理、本地聚合、分区、溢写和合并等关键环节。
1.10 MapTask性能优化要点
MapTask性能优化是提高整个MapReduce作业效率的关键环节,需要从数据处理的各个层面进行综合考虑。输入数据局部性是优化的首要原则,Hadoop调度器会优先将MapTask分配到数据所在的节点执行(本地性任务),如果本地节点资源不足,会尝试分配到同一机架的其他节点(机架局部性任务),最后才考虑跨机架分配,通过合理的数据块大小设置(默认128MB)和机架感知配置,可以最大化本地性任务的比例,显著减少数据传输开销。缓冲区大小调整是另一个重要优化点,通过mapreduce.task.io.sort.mb参数可以调整内存缓冲区大小,适当增加缓冲区(如调整到200-300MB)可以减少溢写次数,降低磁盘I/O开销,但需要根据节点内存情况合理设置,避免内存不足导致的性能下降。
Combiner的合理使用是减少数据传输量的有效手段,它在MapTask本地对中间键值对进行聚合处理,相当于本地的Reducer,能够显著减少溢写和网络传输的数据量,但使用时需要确保聚合操作的幂等性,避免重复聚合影响最终结果,比如求和、计数等操作适合使用Combiner,而求平均值等操作则不适合。数据压缩策略可以在多个层面优化性能,对溢写数据和最终中间文件进行压缩(通过mapreduce.map.output.compress等参数启用),可以减少磁盘I/O和网络传输量,常用的压缩编解码器包括Snappy、LZO和Gzip,其中Snappy压缩速度快,适合对性能要求高的场景,而Gzip压缩率高,适合存储空间受限的场景。
并行度调整是MapTask优化的关键策略,MapTask的数量由输入数据的分片数决定,默认情况下一个分片对应一个MapTask,通过调整mapreduce.input.fileinputformat.split.minsize和mapreduce.input.fileinputformat.split.maxsize参数可以控制分片大小,进而调整MapTask数量,一般来说,MapTask数量应该设置为集群节点数的1-3倍,每个MapTask处理的数据量在128-256MB之间,这样可以充分利用集群资源,避免任务过多导致的调度开销或任务过少导致的资源浪费。通过对MapTask执行机制的深入理解和这些优化策略的综合应用,我们可以显著提升Map阶段的性能,从而提高整个MapReduce作业的执行效率。
二、ReduceTask执行机制深度解析
2.1 ReduceTask概述
ReduceTask是MapReduce框架中负责执行Reduce阶段任务的核心组件,它是MapReduce作业的最终计算单元。ReduceTask接收所有MapTask输出的中间键值对,通过数据拉取、归并排序和聚合计算等步骤,生成最终的输出结果。ReduceTask的执行效率对整个MapReduce作业的性能有着决定性影响,特别是在数据传输量巨大和聚合计算复杂的场景下,Reduce阶段往往成为作业的性能瓶颈。
ReduceTask的核心职责包括:从各个MapTask节点拉取属于自己分区的中间键值对;对拉取的数据进行归并排序,确保相同键的键值对连续排列;执行用户定义的Reduce函数,对相同键的所有值进行聚合计算;将计算结果输出到指定的文件系统中。理解ReduceTask的工作原理和执行流程,是进行MapReduce性能优化的关键。
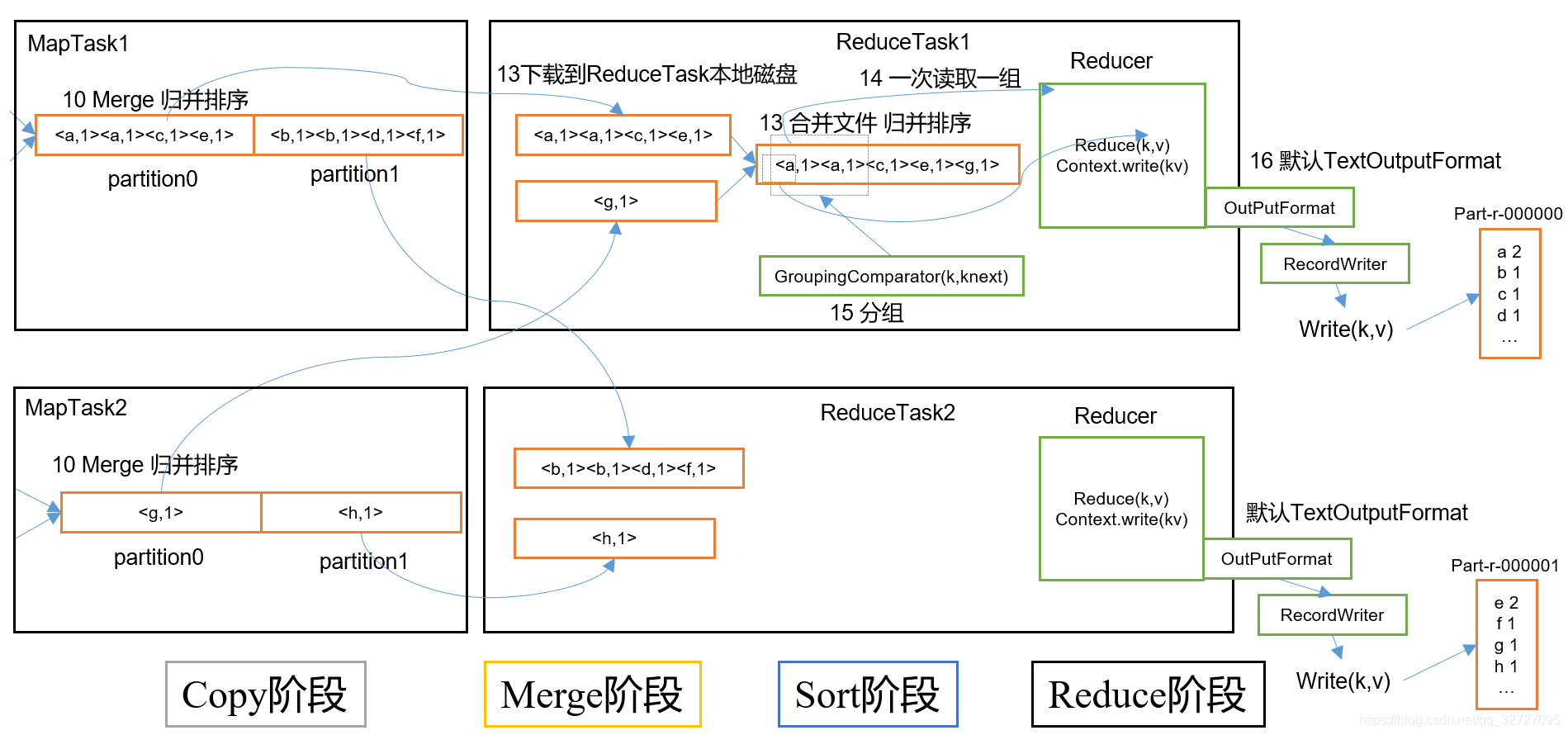
2.2 Shuffle阶段:数据拉取
Shuffle阶段是MapReduce中连接Map阶段和Reduce阶段的桥梁,它负责将所有MapTask输出的中间键值对拉取到ReduceTask节点进行处理。Shuffle阶段的性能直接影响整个作业的执行效率,因此是MapReduce优化的重点之一。
Shuffle阶段主要包括以下几个关键步骤:
-
数据拉取(Fetch):当MapTask完成执行后,会向ApplicationMaster注册其完成状态和中间文件位置信息。ReduceTask通过ApplicationMaster获取所有MapTask的完成信息和中间文件位置,然后通过HTTP协议从各个MapTask节点拉取属于自己分区的中间键值对。每个ReduceTask只拉取与自己分区相关的数据,避免了不必要的数据传输。
-
数据缓存与过滤:拉取的数据首先存储在ReduceTask节点的内存缓冲区中,缓冲区的大小由
mapreduce.reduce.shuffle.input.buffer.percent参数控制(默认值为0.7,即堆内存的70%)。在缓存过程中,系统会对数据进行基本的完整性检查和过滤,确保只有有效的键值对被存储和处理。 -
内存合并与溢写:当内存缓冲区达到一定阈值(由
mapreduce.reduce.shuffle.merge.percent参数控制,默认值为0.66)时,会触发溢写操作,将内存中的数据写入到磁盘临时文件中。在溢写之前,系统会对内存中的数据进行排序和合并操作,确保数据的有序性,减少后续处理的开销。 -
磁盘文件合并:随着拉取数据的增加,磁盘上会生成多个溢写文件。系统会定期对这些溢写文件进行合并操作,减少文件数量,提高后续归并排序的效率。合并过程中会保持数据的有序性,相同键的键值对会被聚集在一起。
2.3 归并排序(Merge Sort)
在ReduceTask节点上,所有拉取的中间键值对会进行最终的归并排序,这是Reduce阶段的关键步骤之一。归并排序的目的是确保相同键的键值对连续排列,以便Reduce函数能够高效地遍历和处理相同键的所有值。
归并排序的过程通常包括以下几个阶段:
-
内存归并:内存缓冲区中的数据会定期进行排序和合并,形成有序的内存数据块。内存归并的效率较高,但受限于内存容量。
-
磁盘归并:当内存缓冲区的数据溢写到磁盘后,会生成多个有序的临时文件。系统会对这些临时文件进行多轮归并排序,每轮归并的文件数量由
mapreduce.reduce.merge.inmem.threshold参数控制(默认值为10)。磁盘归并的效率相对较低,但可以处理大量数据。 -
最终归并:当所有MapTask的数据都被拉取完成后,系统会将内存中的数据和磁盘上的归并结果进行最终的归并排序,形成一个完整的有序数据集。最终归并的结果是一个按键排序的键值对序列,相同键的键值对连续排列。
归并排序是Reduce阶段的核心操作之一,其效率直接影响Reduce函数的执行效率。优化归并排序的参数(如mapreduce.reduce.merge.inmem.threshold和mapreduce.task.io.sort.factor)可以显著提高归并排序的性能。
2.4 Reduce函数执行
Reduce函数是用户定义的核心聚合逻辑,它接收归并排序后的键值对迭代器,对相同键的所有值进行聚合计算,然后输出最终的键值对。
下面是WordCount示例中的Reduce函数实现:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// 定义输出值IntWritable对象
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 定义计数器
int sum = 0;
// 遍历相同键的所有值
for (IntWritable val : values) {
// 累加计数
sum += val.get();
}
// 设置输出值
result.set(sum);
// 输出最终结果
context.write(key, result);
}
}
关键行点评:
reduce方法:Reduce函数的核心处理逻辑,接收归并后的键值对迭代器并输出最终结果for (IntWritable val : values):遍历相同键的所有值sum += val.get():对相同键的所有值进行累加计数context.write(key, result):输出最终的键值对结果
2.5 输出结果
Reduce函数处理完成后,会将最终的键值对输出到指定的输出目录中。OutputFormat负责将Reduce函数的输出结果写入到文件系统中,常用的OutputFormat实现包括:
- TextOutputFormat:默认的输出格式,将结果按行写入文本文件
- SequenceFileOutputFormat:将结果写入SequenceFile格式的文件
- MapFileOutputFormat:将结果写入MapFile格式的文件
2.6 ReduceTask执行流程图
图2:ReduceTask执行流程图 - 展示了ReduceTask从拉取MapTask输出数据到生成最终结果的完整流程,包括数据拉取、缓存、溢写、归并排序、Reduce函数执行和结果输出等关键环节。
这里附上一段完整的MapReduce运行代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* 完整的MapReduce WordCount示例
* 功能:统计文本文件中每个单词出现的次数
*/
public class WordCount {
/**
* Mapper类:负责将输入文本拆分为单词并生成<单词, 1>的键值对
*/
public static class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> {
// 定义输出键类型为Text(单词)
private final static IntWritable one = new IntWritable(1);
// 定义输出值类型为IntWritable(计数)
private Text word = new Text();
/**
* map方法:处理输入的每一行文本
* @param key 输入键(通常是偏移量,这里不使用)
* @param value 输入值(文本行)
* @param context 上下文对象,用于输出结果
* @throws IOException
* @throws InterruptedException
*/
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 使用StringTokenizer分割文本行为单词
StringTokenizer itr = new StringTokenizer(value.toString());
// 遍历所有单词
while (itr.hasMoreTokens()) {
// 设置当前单词为输出键
word.set(itr.nextToken());
// 输出<单词, 1>键值对
context.write(word, one);
}
}
}
/**
* Reducer类:负责汇总相同单词的计数
*/
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// 定义输出值类型为IntWritable(总计数)
private IntWritable result = new IntWritable();
/**
* reduce方法:处理相同键(单词)的所有值(计数)
* @param key 输入键(单词)
* @param values 输入值迭代器(该单词的所有计数)
* @param context 上下文对象,用于输出结果
* @throws IOException
* @throws InterruptedException
*/
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 初始化计数器
int sum = 0;
// 遍历所有计数并累加
for (IntWritable val : values) {
sum += val.get();
}
// 设置总计数为输出值
result.set(sum);
// 输出<单词, 总计数>键值对
context.write(key, result);
}
}
/**
* Driver类:负责配置和提交MapReduce作业
* @param args 命令行参数,包括输入路径和输出路径
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 解析命令行参数
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: WordCount <input path> <output path>");
System.exit(2);
}
// 创建作业对象
Job job = Job.getInstance(conf, "word count");
// 设置作业的主类
job.setJarByClass(WordCount.class);
// 设置Mapper类
job.setMapperClass(WordCountMapper.class);
// 设置Combiner类(可选,用于本地聚合,减少网络传输)
job.setCombinerClass(WordCountReducer.class);
// 设置Reducer类
job.setReducerClass(WordCountReducer.class);
// 设置输出键类型
job.setOutputKeyClass(Text.class);
// 设置输出值类型
job.setOutputValueClass(IntWritable.class);
// 设置输入路径
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
// 设置输出路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
// 提交作业并等待完成,完成后退出程序
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
/*
运行说明:
1. 编译代码:
javac -classpath $(hadoop classpath) WordCount.java
2. 打包为JAR文件:
jar cf wc.jar WordCount*.class
3. 执行MapReduce作业:
hadoop jar wc.jar WordCount <输入文件路径> <输出目录路径>
例如:
hadoop jar wc.jar WordCount /user/input/text.txt /user/output/wordcount
4. 查看结果:
hadoop fs -cat /user/output/wordcount/part-r-00000
注意事项:
- 确保Hadoop集群已启动并正常运行
- 输入文件路径必须存在于HDFS中
- 输出目录必须不存在,否则作业会失败
- 可以根据需要修改作业配置参数
*/
2.7 ReduceTask性能优化要点
ReduceTask作为MapReduce作业的最后一个阶段,其执行效率直接影响作业的完成时间。通过对ReduceTask工作原理的深入理解和性能优化,可以显著提高MapReduce作业的整体性能。以下是一些关键的ReduceTask性能优化要点:
-
ReduceTask数量调整:ReduceTask的数量需要根据数据量和集群规模合理设置。一般来说,ReduceTask的数量应该设置为集群节点数的1-2倍,每个ReduceTask处理的数据量在1-2GB之间。过多的ReduceTask会导致任务调度开销增加,过少的ReduceTask会导致资源利用率降低。ReduceTask的数量可以通过
mapreduce.job.reduces参数设置。 -
数据压缩策略:对Map输出和Reduce输出进行压缩,可以显著减少网络传输和磁盘I/O开销。对于Map输出,可以使用Snappy或LZO等快速压缩算法,减少网络传输时间;对于Reduce输出,可以根据后续使用需求选择合适的压缩算法,如需要长期存储可以使用Gzip等压缩率高的算法。压缩相关的参数包括
mapreduce.map.output.compress、mapreduce.map.output.compress.codec、mapreduce.output.fileoutputformat.compress等。 -
内存与缓存优化:调整ReduceTask的内存分配和缓存策略,可以提高Shuffle阶段的性能。例如,增加
mapreduce.reduce.shuffle.input.buffer.percent参数的值,可以扩大内存缓冲区的大小,减少溢写次数;调整mapreduce.reduce.shuffle.merge.percent参数的值,可以优化内存合并的时机。此外,开启JVM重用(通过mapreduce.job.jvm.numtasks参数设置)可以减少JVM启动和关闭的开销,提高任务执行效率。 -
数据本地化与网络优化:尽量使ReduceTask在数据所在的节点或机架上执行,可以减少网络传输开销。Hadoop调度器会尽量将ReduceTask分配到数据所在的节点,但由于ReduceTask需要拉取多个MapTask的输出,完全的数据本地化往往难以实现。在这种情况下,可以通过优化网络拓扑和增加网络带宽来提高数据传输效率。
-
Reduce函数优化:优化Reduce函数的实现,可以提高聚合计算的效率。例如,避免在循环中创建大量临时对象、使用更高效的聚合算法、减少不必要的计算等。此外,合理使用Combiner可以减少传输到ReduceTask的数据量,间接提高Reduce阶段的性能。
-
输出格式与存储优化:选择合适的OutputFormat实现和存储策略,可以提高输出结果的处理效率。例如,对于需要后续分析的数据,可以选择Parquet等列式存储格式;对于需要长期存储的数据,可以选择高压缩率的存储格式。此外,合理设置输出文件的块大小和复制因子,可以优化存储和读取性能。
通过综合应用这些优化策略,可以显著提高ReduceTask的执行效率,从而缩短整个MapReduce作业的完成时间。在实际应用中,需要根据具体的业务场景和数据特点,选择合适的优化策略,并进行充分的测试和调优。
ReduceTask作为MapReduce作业的核心组件之一,其执行效率对整个作业的性能有着重要影响。通过对ReduceTask工作原理的深入理解和性能优化,我们可以充分发挥MapReduce框架的优势,高效处理大规模数据。
三、Yarn工作机制与作业提交过程
3.1 Yarn概述
Yarn(Yet Another Resource Negotiator)是Hadoop 2.0引入的资源管理系统,它负责集群资源的管理和作业的调度。Yarn的引入使得Hadoop能够支持多种计算框架,如MapReduce、Spark、Storm等,实现了计算框架与资源管理的解耦。
3.2 Yarn基本架构
Yarn的核心架构由三个主要组件组成:
- ResourceManager(RM):集群资源的中央管理器,负责资源分配和作业调度
- NodeManager(NM):单个节点的资源管理器,负责节点上资源的管理和任务的执行
- ApplicationMaster(AM):每个应用程序的管理器,负责与ResourceManager协商资源并管理应用程序的执行
3.3 Yarn核心组件职责
ResourceManager主要职责:
- 接收客户端提交的作业请求
- 管理和分配集群资源(CPU、内存等)
- 调度作业并为作业分配ApplicationMaster
- 监控ApplicationMaster的运行状态
NodeManager主要职责:
- 管理节点上的资源(CPU、内存等)
- 接收ResourceManager的资源分配命令
- 创建和管理容器(Container)
- 监控容器的运行状态
- 向ResourceManager汇报节点状态
ApplicationMaster主要职责:
- 与ResourceManager协商资源
- 向NodeManager请求创建容器
- 管理应用程序的任务执行
- 监控任务的运行状态
- 处理任务失败和重试
3.4 Yarn架构图
图3:Yarn架构图 - 展示了Yarn的核心组件及其交互关系,包括客户端、ResourceManager、NodeManager和容器等层次结构。
3.5 MapReduce作业提交到Yarn的流程
MapReduce作业提交到Yarn的完整流程包括以下几个关键步骤:
- 作业提交:客户端向ResourceManager提交作业,包括作业配置、Jar包、分片信息等
- 作业初始化:ResourceManager为作业创建ApplicationMaster容器,并启动ApplicationMaster
- 资源申请:ApplicationMaster向ResourceManager申请执行MapTask和ReduceTask所需的资源
- 任务调度:ResourceManager根据调度策略为ApplicationMaster分配资源
- 容器启动:ApplicationMaster向NodeManager请求创建容器,并在容器中启动MapTask和ReduceTask
- 任务执行:MapTask和ReduceTask在容器中执行,处理数据
- 进度汇报:任务向ApplicationMaster汇报执行进度和状态
- 作业完成:所有任务执行完成后,ApplicationMaster向ResourceManager汇报作业完成,并清理资源
3.6 作业提交详细流程
下面是MapReduce作业提交到Yarn的详细流程:
- 客户端调用Job.submit()方法:开始作业提交过程
- 创建内部JobSubmitter:客户端创建JobSubmitter对象,负责作业的实际提交
- 检查作业配置:JobSubmitter检查作业的配置信息,确保必要的参数已设置
- 计算输入分片:JobSubmitter使用InputFormat计算输入数据的分片信息
- 复制资源到HDFS:客户端将作业的Jar包、配置文件、分片信息等资源复制到HDFS的临时目录
- 向ResourceManager提交作业:客户端向ResourceManager发送作业提交请求
- ResourceManager创建Application:ResourceManager为作业创建一个Application,并分配Application ID
- ResourceManager分配AM容器:ResourceManager的Scheduler为ApplicationMaster分配一个容器
- NodeManager启动AM:ResourceManager通知相应的NodeManager启动ApplicationMaster
- AM初始化作业:ApplicationMaster初始化作业,创建任务列表
- AM申请资源:ApplicationMaster根据任务列表向ResourceManager申请资源
- ResourceManager分配资源:Scheduler根据资源需求和调度策略分配资源
- AM启动任务:ApplicationMaster向NodeManager请求创建容器,并在容器中启动MapTask和ReduceTask
- 任务执行:MapTask和ReduceTask在容器中执行,读取数据、处理数据、输出结果
- 任务状态汇报:任务定期向ApplicationMaster汇报执行状态和进度
- 处理任务失败:ApplicationMaster处理任务失败,根据需要重试任务
- 作业完成:所有任务执行完成后,ApplicationMaster向ResourceManager汇报作业完成
- 清理资源:ApplicationMaster清理作业资源,释放容器
- 客户端获取结果:客户端从HDFS读取作业的输出结果
3.7 Yarn作业提交流程图
图4:Yarn作业提交流程图 - 展示了MapReduce作业从客户端提交到Yarn,经过资源分配、任务执行,最终完成的完整流程。
3.8 Yarn作业执行时间分布饼图
图5:Yarn作业执行时间分布饼图 - 展示了MapReduce作业在Yarn上执行时各阶段的时间分布比例,其中Map阶段和Shuffle阶段占据了大部分时间。
3.9 Yarn性能优化要点
- 资源配置优化:根据集群规模和作业特点合理配置CPU和内存资源
- 调度策略选择:根据作业类型选择合适的调度策略(FIFO、Capacity、Fair等)
- 容器复用:开启容器复用,减少容器创建和销毁的开销
- 数据本地化:优化数据存储位置,提高数据本地化率
- 任务并行度调整:根据数据量和集群资源调整MapTask和ReduceTask的数量
- JVM参数调优:优化JVM参数,提高Java应用程序的性能
通过对Yarn工作机制的深入理解和性能优化,我们可以更好地利用集群资源,提高MapReduce作业的执行效率和集群的整体吞吐量。
四、MapTask与ReduceTask对比分析
为了更好地理解MapTask和ReduceTask的区别和联系,我们可以通过以下表格进行对比分析:
| 特性 | MapTask | ReduceTask |
|---|---|---|
| 输入数据 | 原始数据分片 | MapTask输出的中间键值对 |
| 输出数据 | 中间键值对 | 最终结果 |
| 并行度 | 由输入分片数量决定 | 由用户配置的reduce数量决定 |
| 数据处理 | 局部处理,无依赖 | 全局聚合,依赖所有MapTask输出 |
| 网络传输 | 无(除了输出到HDFS) | 需要拉取所有MapTask的输出数据 |
| 计算复杂度 | 相对简单,主要是数据转换 | 相对复杂,主要是数据聚合 |
| 故障影响 | 影响局部数据处理 | 影响全局结果聚合 |
| 优化重点 | 数据本地化、Map函数效率 | Shuffle阶段、Reduce函数效率 |
通过对比分析可以看出,MapTask和ReduceTask在数据处理方式、并行度、网络传输等方面存在明显的区别,因此在实际应用中需要针对不同的任务类型和特点进行优化。
五、MapReduce与Yarn的协同工作
MapReduce和Yarn的协同工作是Hadoop分布式计算的核心。MapReduce提供了数据处理的框架和API,而Yarn提供了资源管理和作业调度的能力。它们的协同工作使得Hadoop能够高效地处理大规模数据集。
“MapReduce是处理大数据的锤子,而Yarn是握住锤子的手。” —— 大数据领域谚语
这句谚语形象地说明了MapReduce和Yarn的关系:MapReduce是处理大数据的工具,而Yarn是管理和调度这个工具的平台。只有两者协同工作,才能发挥Hadoop的最大威力。
六、总结
本文从三个核心维度深度解析了MapReduce的工作流程:MapTask执行机制、ReduceTask执行机制以及Yarn工作机制和作业提交过程。
首先,我们详细探讨了MapTask的执行流程,包括数据分片、映射处理、本地聚合、分区、溢写和合并等关键环节。MapTask作为MapReduce的第一个阶段,负责将原始数据转换为中间键值对,为后续的Reduce阶段做准备。
其次,我们深入分析了ReduceTask的工作原理,涵盖了Shuffle阶段的数据拉取、归并排序、Reduce函数执行等步骤。ReduceTask作为MapReduce的第二个阶段,负责将中间键值对聚合为最终的输出结果。
最后,我们全面讲解了Yarn的工作机制和作业提交过程,包括Yarn的基本架构、核心组件、资源管理和作业调度等内容。Yarn作为Hadoop 2.0引入的资源管理系统,实现了计算框架与资源管理的解耦,使得Hadoop能够支持多种计算框架。
通过对这三个方面的系统讲解,我们可以看出MapReduce的工作流程是一个复杂而精妙的分布式计算过程,它充分利用了"分而治之"的思想,将大规模的数据处理任务分解为可并行执行的子任务,极大地提高了数据处理的效率和可扩展性。
在实际应用中,我们需要根据具体的业务需求和数据特点,合理配置MapReduce和Yarn的参数,优化作业的执行效率。同时,我们也需要关注作业的监控和调优,及时发现和解决作业执行过程中的问题。
随着大数据技术的不断发展,MapReduce虽然面临着Spark等新兴计算框架的挑战,但它仍然是理解分布式计算原理和构建高效数据处理系统的基础。掌握MapReduce的工作原理和优化方法,对于大数据工程师来说是非常重要的。
参考链接
关键词标签
#MapReduce #Yarn #大数据处理 #分布式计算 #Hadoop

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 88
88 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)