为什么PostgreSQL不使用Oracle那样的UNDO机制?
在数据库的并发控制领域,Oracle和PostgreSQL选择了截然不同的技术路径
📢📢📢📣📣📣
作者:IT邦德
中国DBA联盟(ACDU)成员,15年DBA工作经验
Oracle、PostgreSQL ACE
CSDN博客专家及B站知名UP主,全网粉丝15万+
擅长主流Oracle、MySQL、PG、高斯及Greenplum备份恢复,
安装迁移,性能优化、故障应急处理
在数据库的并发控制领域,Oracle和PostgreSQL选择了截然不同的技术路径。对于习惯Oracle的DBA来说,初次接触PostgreSQL的MVCC实现时,最直观的疑问就是:为什么PostgreSQL不使用Oracle那样的UNDO机制?
1.根本差异
Oracle的UNDO机制本质上是一个集中式的回滚段系统。当数据被修改时,原始数据被复制到UNDO表空间,而数据块中只保留最新版本。这种设计通过专门的UNDO段来管理旧数据,实现了读一致性视图。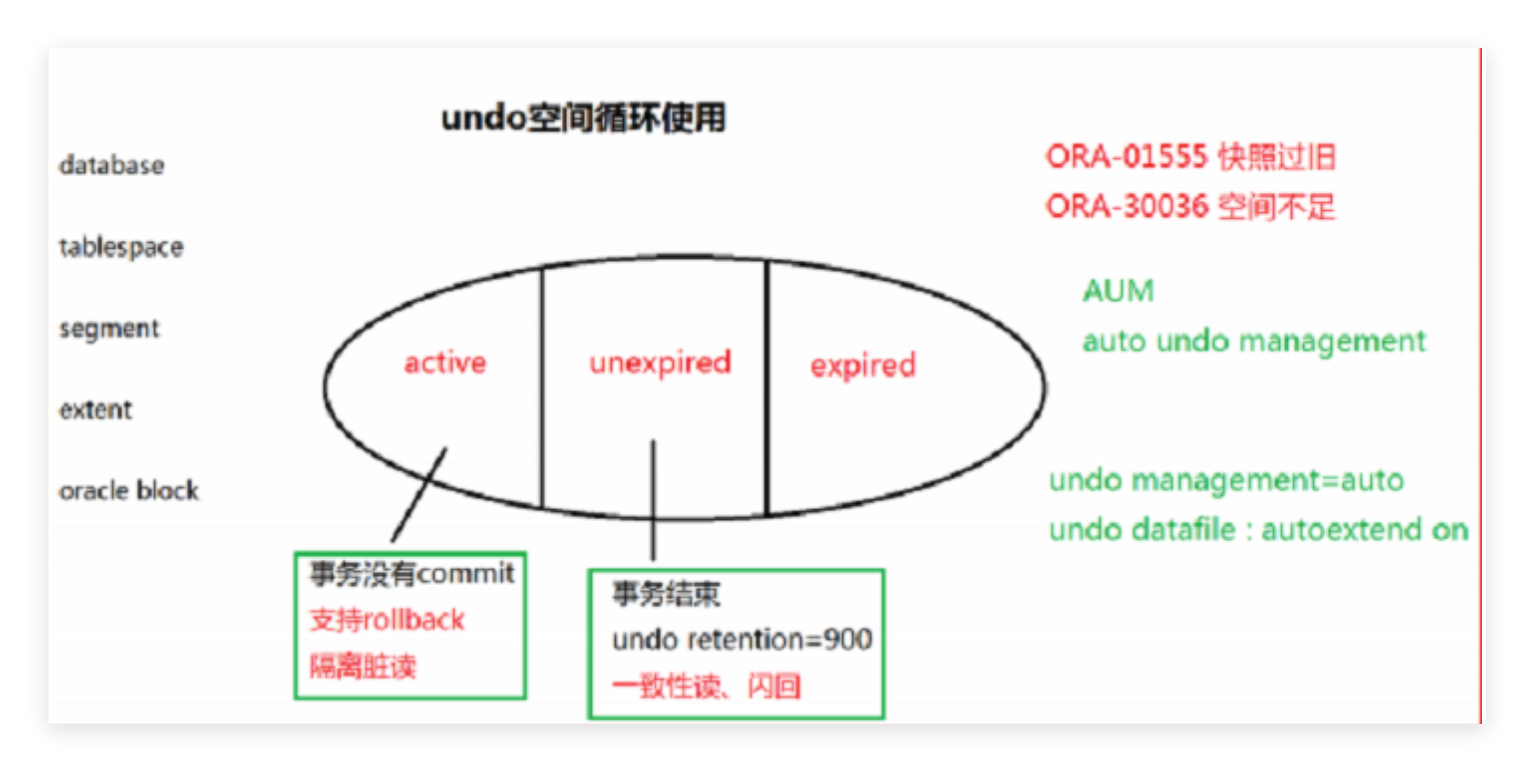
PostgreSQL则采用了基于元组的分散式版本控制。每个数据行(元组)的每次更新都会在表中生成一个新版本,旧版本依然保留在原表中,通过事务ID链式连接。这种“堆中多版本”的设计让每个表都隐含着数据的历史版本。

2.技术实现对比
2.1 Oracle UNDO架构:
使用专门的回滚段存储旧数据版本
数据块中只保留最新数据,通过指针链接到UNDO信息
需要复杂的UNDO表空间管理和保留策略
SELECT查询通过UNDO数据重建一致性视图
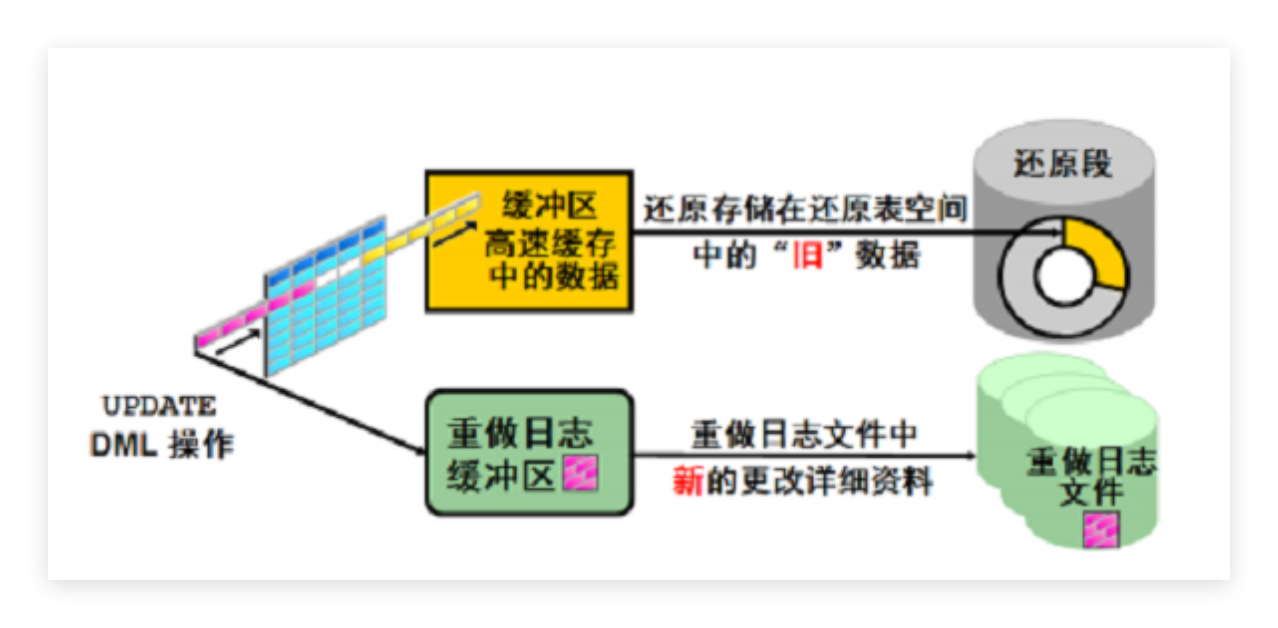
2.2 PostgreSQL元组版本链
所有数据版本都存储在表的堆文件中
每个元组头部包含xmin、xmax、ctid等事务信息
VACUUM机制负责清理过期版本
可见性判断通过事务快照和元组状态直接完成

t_xmin:代表插入此元组的事务xid;
t_xmax:代表更新或者删除此元组的事务xid,如果该元组插入后未进行更新或者删除,t_xmax=0;
3.优劣分析
PostgreSQL元组版本的优势:
简化读取路径:查询无需访问额外的UNDO段,所有可见性判断在堆内完成
避免UNDO争用:没有集中式的UNDO段竞争,减少了热点问题
更直观的空间管理:版本直接体现在表大小上,监控更直接
Oracle UNDO机制的优势:
主表更紧凑:表数据只保留最新版本,主表空间占用更稳定
专业的UNDO管理:UNDO保留时间、大小等参数可精细控制
更好的长查询支持:通过UNDO保留策略可以更好地支持长时间运行的查询
设计哲学的分歧
这两种选择背后是设计哲学的差异:Oracle追求的是高度优化和可控的集中式管理,而PostgreSQL选择了简单透明和分散化的设计思路。
PostgreSQL的元组版本链虽然会导致表膨胀问题(需要依赖VACUUM清理),但它的实现更加透明和一致。DBA可以直接在表中看到所有数据版本,调试和排查问题更加直观。
4.总结
PostgreSQL不使用Oracle式的UNDO机制,是基于其设计哲学的选择。PostgreSQL追求的是绝对的读一致性和简化的空间管理,愿意以定期VACUUM为代价换区这些优势。
而Oracle则更注重主表的存储效率和可预测的性能,但需要DBA投入更多精力管理UNDO空间。
作为DBA,理解这些底层机制差异,有助于我们根据具体应用场景做出更合理的技术选型和优化策略。无论是哪种方案,都没有绝对的优劣,只有适合与否的区别。
您对PostgreSQL的MVCC机制有什么经验或疑问?欢迎在评论区分享交流!

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 21
21 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)