动手学深度学习 - NLP 词嵌入全解析:从 Word2Vec/GloVe 到 FastText/BPE 与 BERT
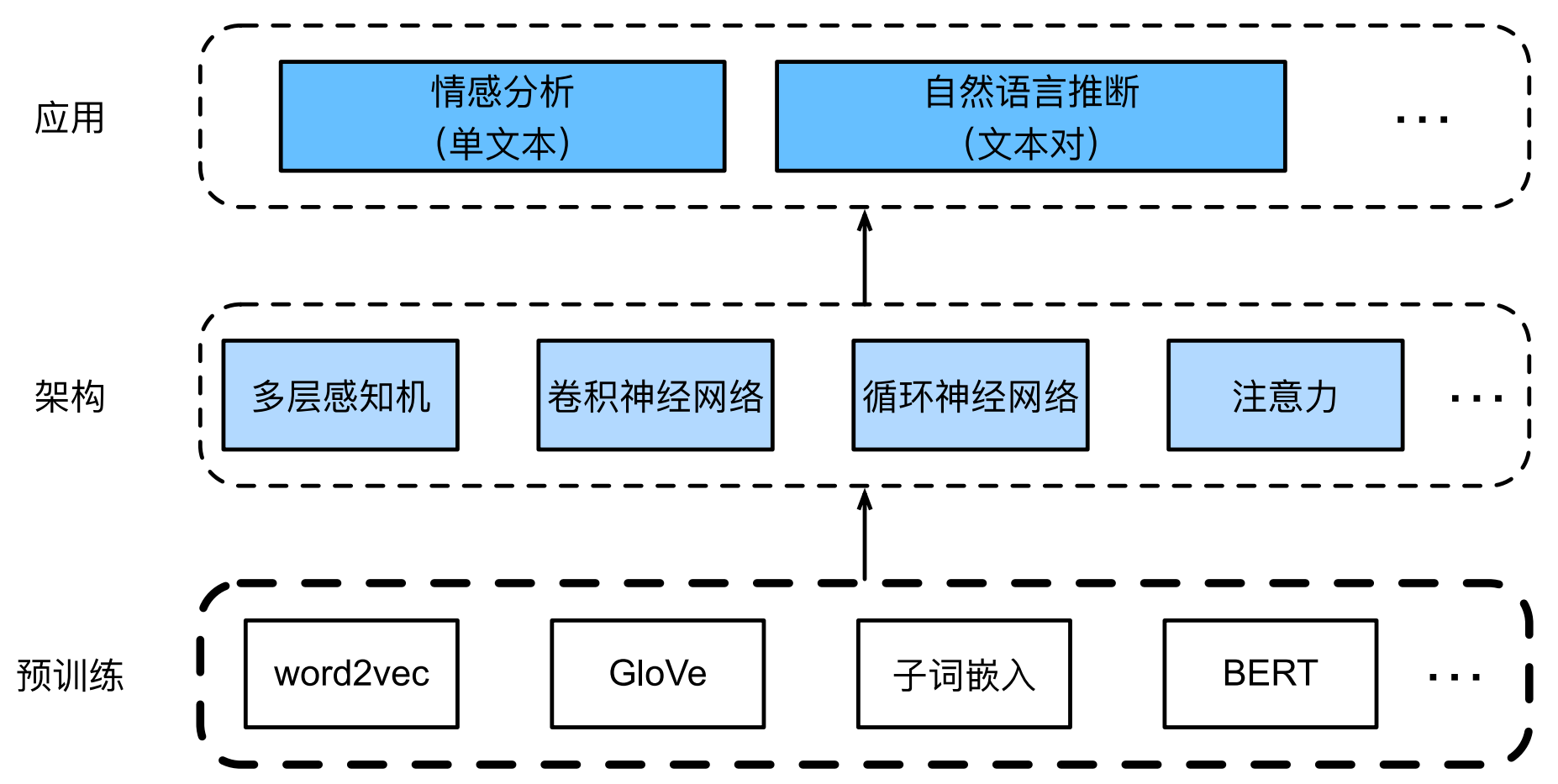
本文系统介绍了NLP中的词嵌入技术发展历程。首先讲解了Word2Vec的Skip-Gram和CBOW模型原理及其在中文文本的应用;然后介绍了融合全局统计的GloVe模型,并给出代码实践;针对传统词嵌入的缺陷,分析了FastText子词嵌入和BPE字节对编码的优势;最后重点阐述了上下文敏感的预训练模型BERT,包括其双向编码特性、输入表示方法以及中文分词器的具体使用方法。通过从静态词嵌入到动态上下文
本文系统梳理 NLP 核心的词嵌入技术全体系,从基础静态词嵌入到进阶动态上下文嵌入完整讲解。
首先详解 Word2Vec 的 Skip-Gram 与 CBOW 模型原理、近似训练策略及三国演义中文实战;
再介绍融合全局统计的 GloVe 模型核心思想与词相似、词类比实践;
针对传统词嵌入缺陷,讲解 FastText 子词嵌入与 BPE 字节对编码的优势;
最后阐述上下文敏感的核心需求,对比 ELMo、GPT、BERT 差异,
详解 BERT 双向编码特性与输入表示,并给出 bert-base-chinese 分词器的实操用法。
经过预训练,每个词元表示为一个向量。(词嵌入)
目录
5. GloVe 代码实践(加载 + knn + 相似词查找 + 词类比 analogy)
1. word2vec
1. Skip-Gram 跳元模型
中心词 -> 上下文词;条件概率用 softmax,分母为 w_c 对词表中所有词。
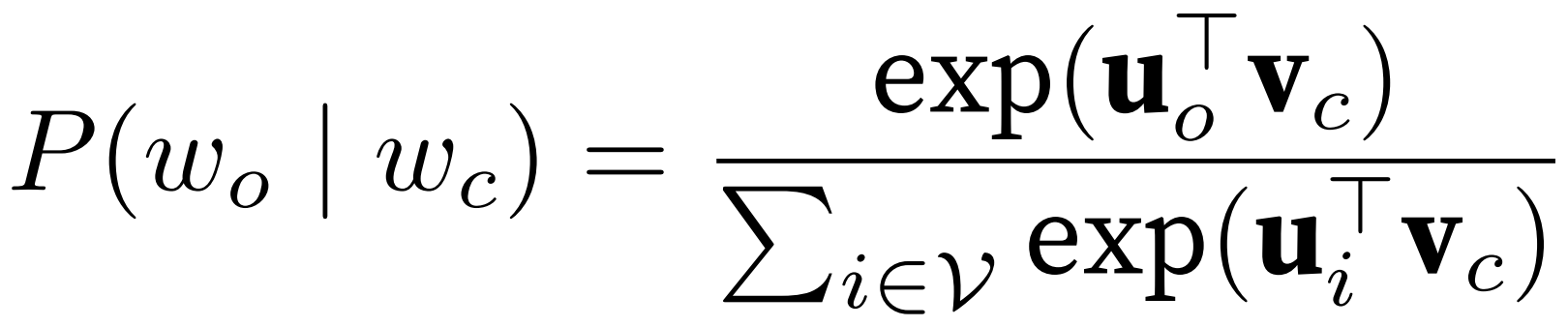
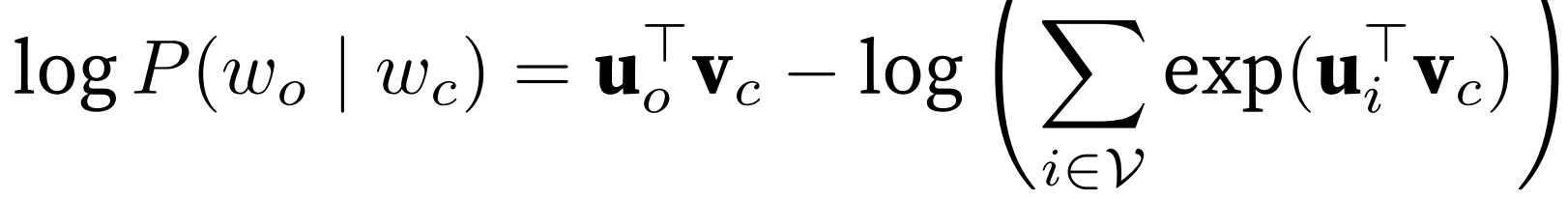
求偏导:
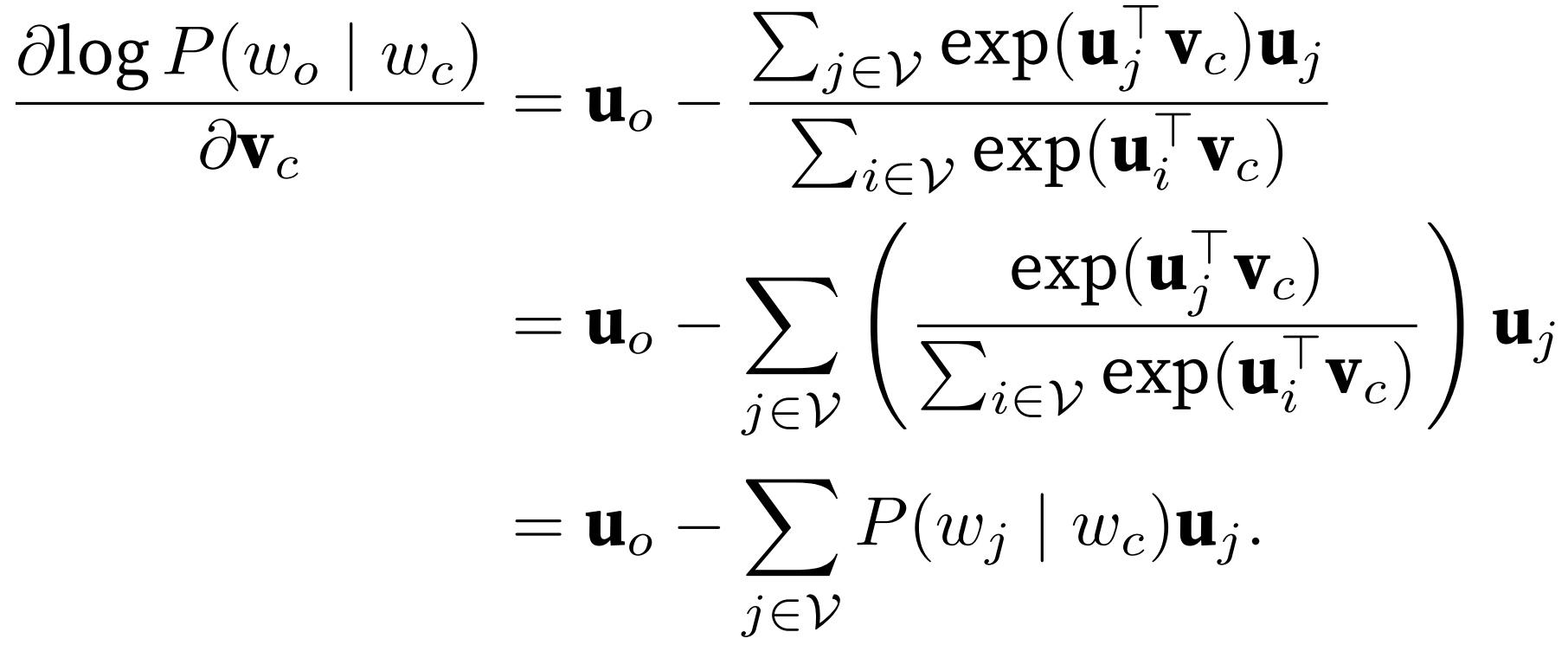
似然函数为长度为 T 的词序列,每个词 对m个上下文词的乘积。
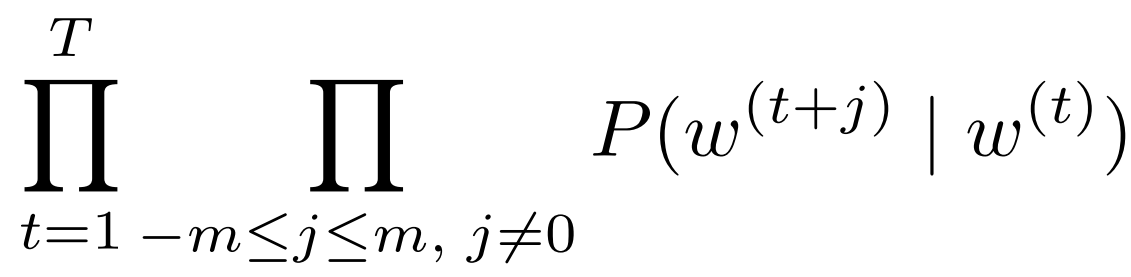
即最小化负对数,单项为 log-sum-exp函数
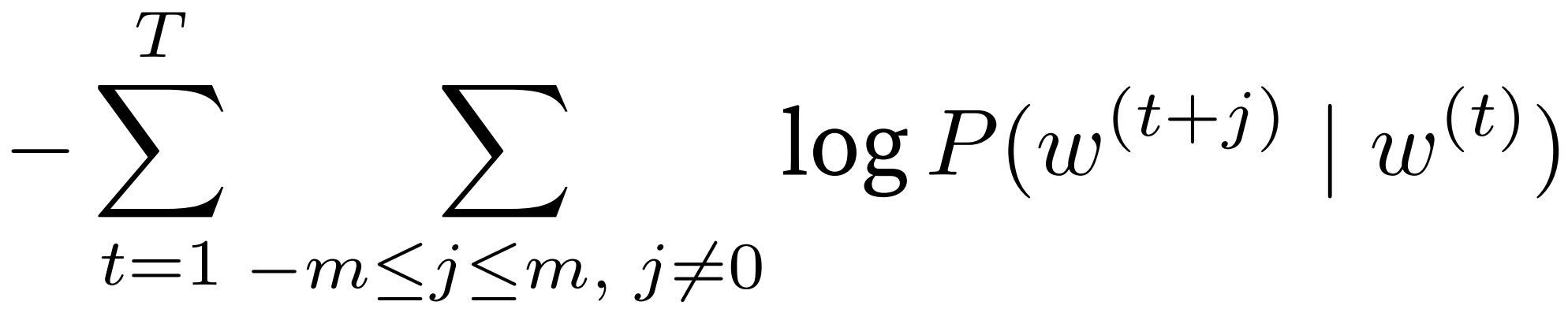
2. CBOW 连续词袋
w_o 上下文词 -> w_c 中心词
中心词取向量平均 ![]()
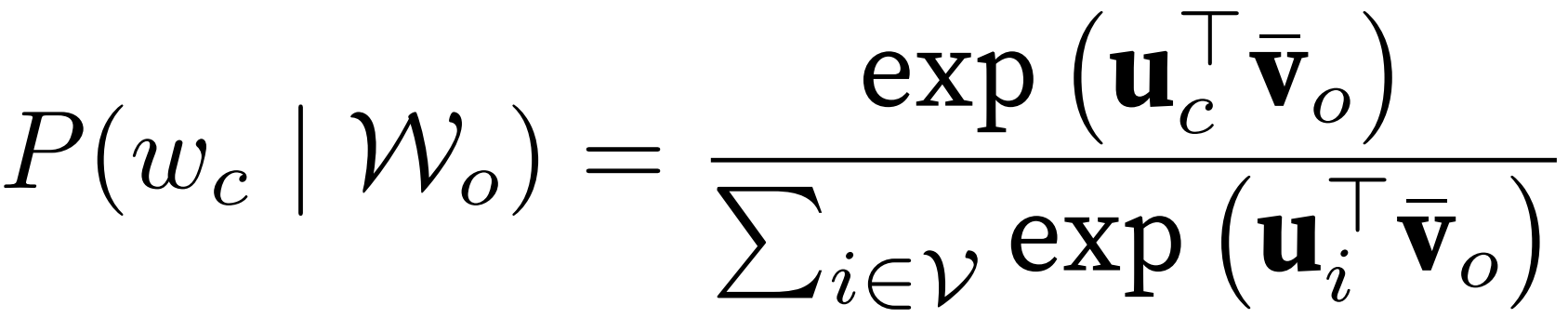
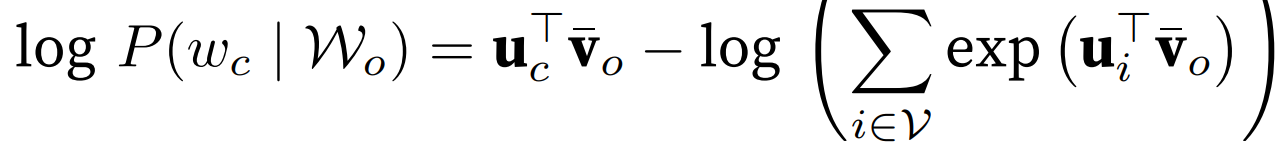
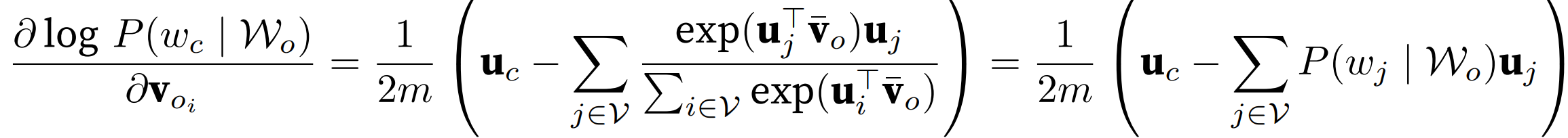
每个词由上下文推出:
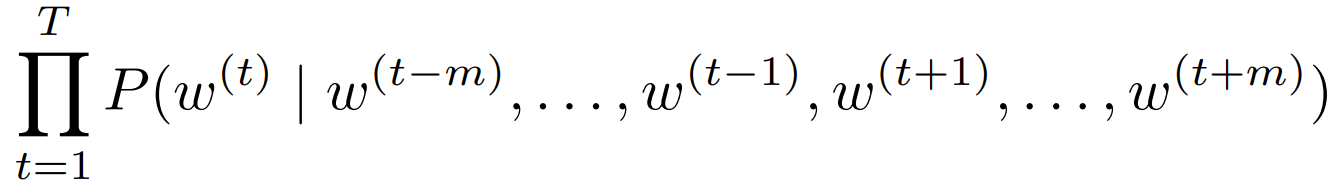
取负对数为:
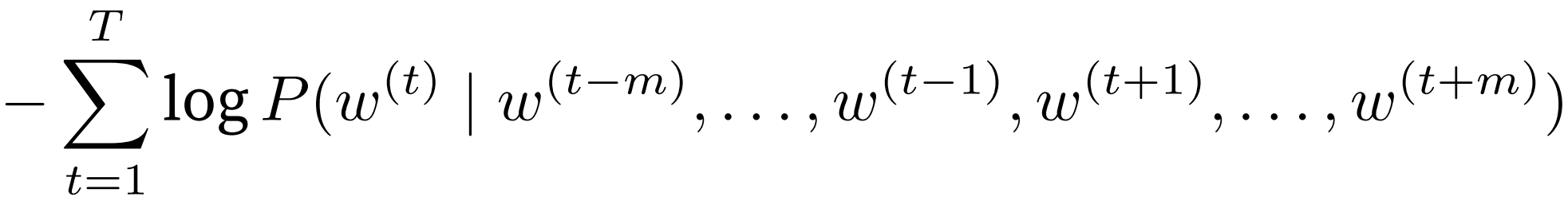
2. 近似训练(负采样 + 分层softmax)
目标函数对词表进行 softmax,但如果词表元素过多,计算成本太高。
正样本:真实上下文
负样本:词表里的所有其他词(太多了) -> 从预定义分布中采样的 “噪声词”
![]()
![]()
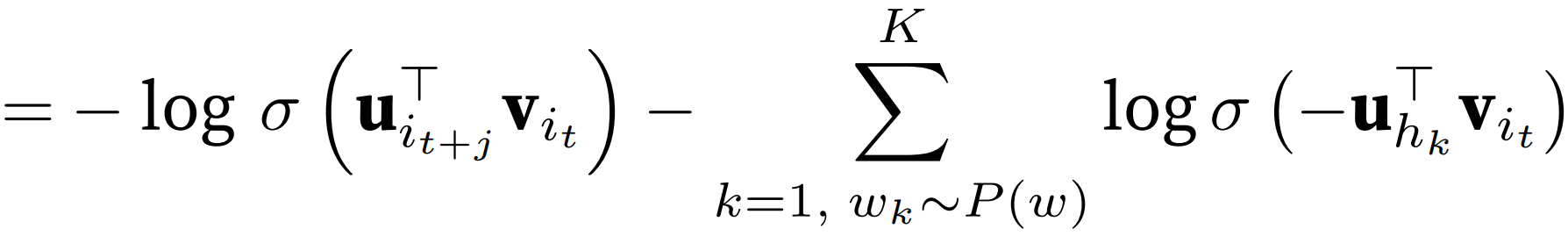
分层 softmax 将词表压缩为二叉树(叶子节点为每个词)路径长度压缩为 log 级别。
中心词决定向量 v_c;
目标上下文词 w_o 要看二叉树从根往下的路径;向左是 sigmoid(内积),向右是 sigmoid(-内积)
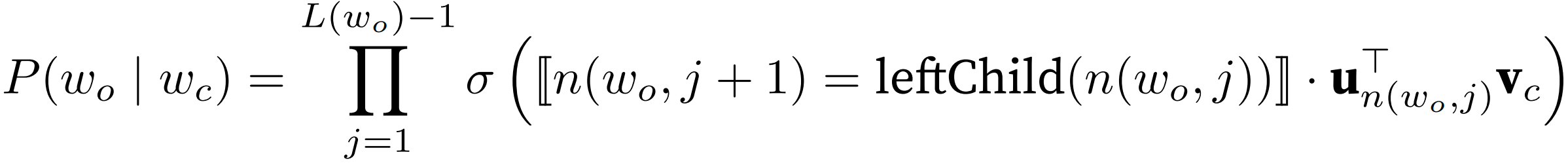
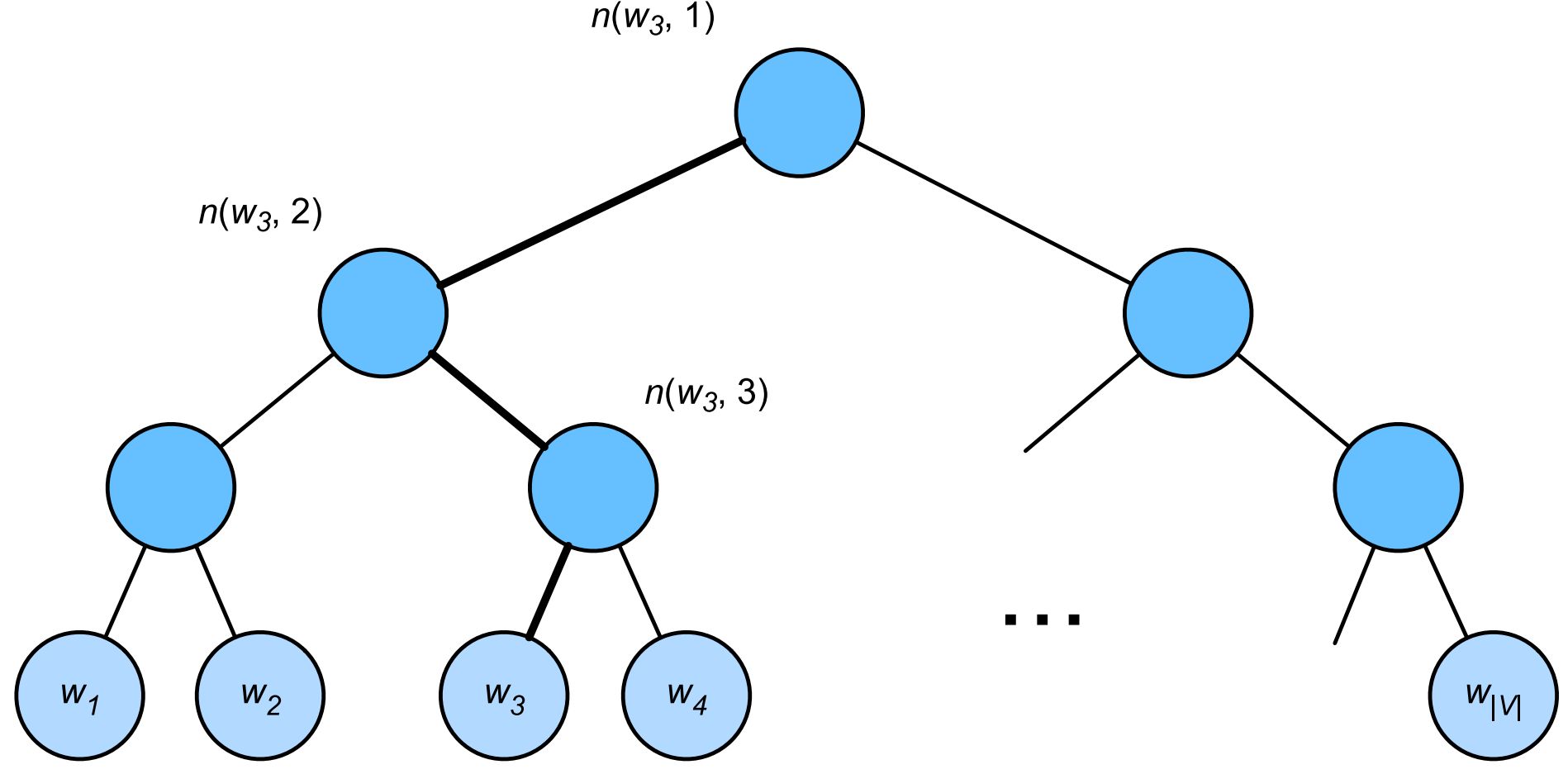
比如 根节点到 w3 是 左右左,条件概率式子则为:
![]()
因为每个非叶子节点 向左向右概率之和为 σ(x) + σ(-x) = 1;
所以与所有叶子节点内积之和还是 1 (和 Softmax 一样)但是计算次数变为 log 级别。
3. skip-gram 训练流程
1. 构建词表Vocab,过滤出现频次低的稀有单词
2. 下采样被丢弃的概率;频率 > t 时有可能被丢弃,频率越高概率越高。
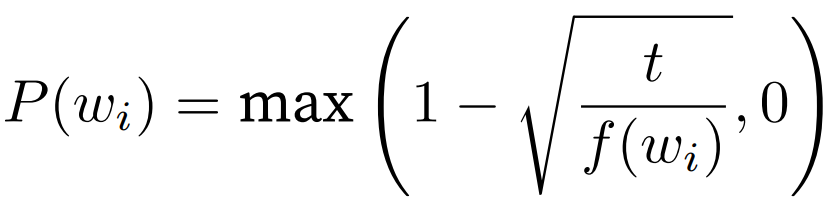
3. 所有单词映射为数字索引
4. 遍历数字语料库的每一句话 每个词依次作为中心词 (窗口大小内为)上下文词
5. 按「词频的 0.75 次方」构建采样权重 生成噪声词(负样本)
6. 统一不同中心词的(上下文词 + 噪声词) 数量
labels = 1/0 代表正负样本;mask = 1/0 代表有效 / 为了统一长度而填充
7. DataLoader 构建批量迭代器
8. 双嵌入:embed_v(中心词嵌入层 最后的结果)embed_u(上下文嵌入层 辅助)
学嵌入 相当于学神经网络的权重。
还用一个专门算上下文的辅助嵌入,(区分中心词和上下文)比中心词和上下文用同一个嵌入算效果更好。
9. 0-1 二分类交叉熵损失:sigmoid(向量内积) ground truth 为 label,权重为 mask。
4. 三国演义 + word2vec 例
导入txt文档;每段 jieba 分词,过滤标点。
import jieba
import re
f = open("sanguo.txt", 'r',encoding='utf-8') #读入文本
lines = []
for line in f: # 分别对每段分词
temp = jieba.lcut(line) # 结巴分词 精确模式
words = []
for i in temp:
#过滤掉所有的标点符号
i = re.sub("[\s+\.\!\/_,$%^*(+\"\'””《》]+|[+——!,。?、~@#¥%……&*():;‘]+", "", i)
if len(i) > 0:
words.append(i)
if len(words) > 0:
lines.append(words)
print(lines[:5]) # 前5行分词结果word2vec 训练这段文本(超参数设置)
from gensim.models import Word2Vec
model = Word2Vec(lines, vector_size = 20, window = 2, min_count = 3, epochs=7, negative=10, sg=1)结果:某词对应的词向量 + 与某词最高相似度的词 + 词类比
# 孔明的词向量
model.wv.get_vector('孔明')
# 和孔明相关性最高的前20个词语
model.wv.most_similar('孔明', topn = 20)
# 玄德-孔明=?-曹操
words = model.wv.most_similar(positive=['玄德', '曹操'], negative=['孔明'])
# 曹操-魏=?-蜀
words = model.wv.most_similar(positive=['曹操', '蜀'], negative=['魏'])4. 全局向量的词嵌入(GloVe)论文 + 实践
https://nlp.stanford.edu/projects/glove/ 参数权重
https://nlp.stanford.edu/pubs/glove.pdf 论文
相关工作:
1. LSA 等话题模型 矩阵分解的方法 全局统计信息 但不擅长词语类比。
2. word2vec 仅局限于词语局部上下文窗口 local context window;需要扫描整个语料库中的上下文窗口,无法直接利用语料库的共现统计信息。

GloVe 直接捕捉整个语料库的全局统计特征。

Co-occurrence probabilities 共现比例;不同中心词对上下文:
ice 和 固体相关性大,比例 > 1;steam 和 气体相关性大比例<1;
都比较有关 or 都比较无关 比例约为1.
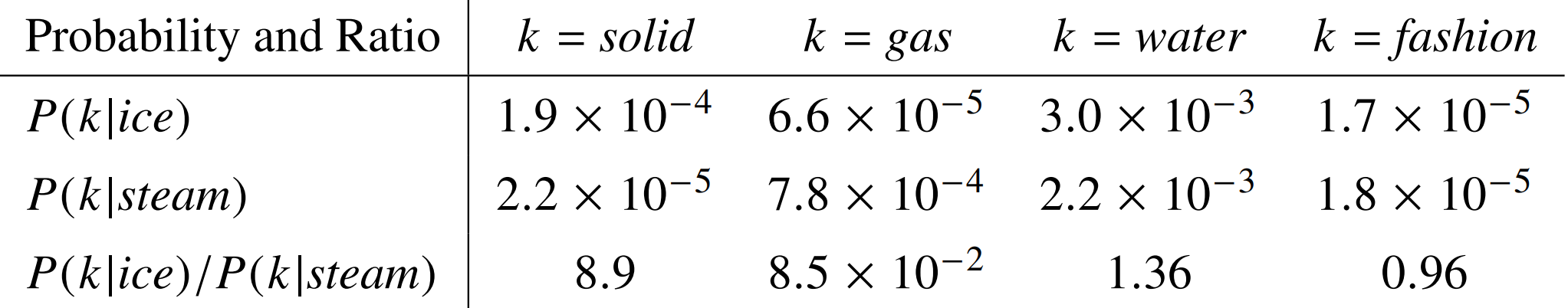
单词向量学习的合理出发点应该是共现概率的比值,而非概率本身。
中心词 w_i 和 w_j 对同一个上下文词 w_k 的比值:
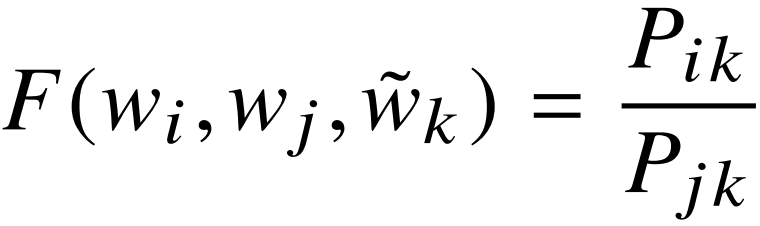
如何选取函数 F?向量减法 -> 比例;左右都是标量 -> 内积
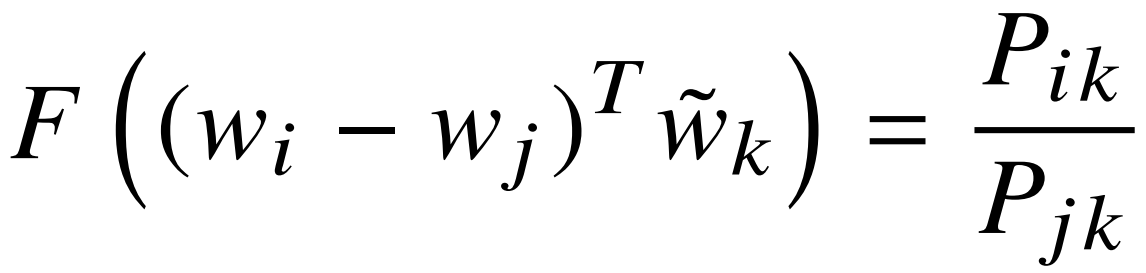
对称性:加法群和乘法群的同态映射
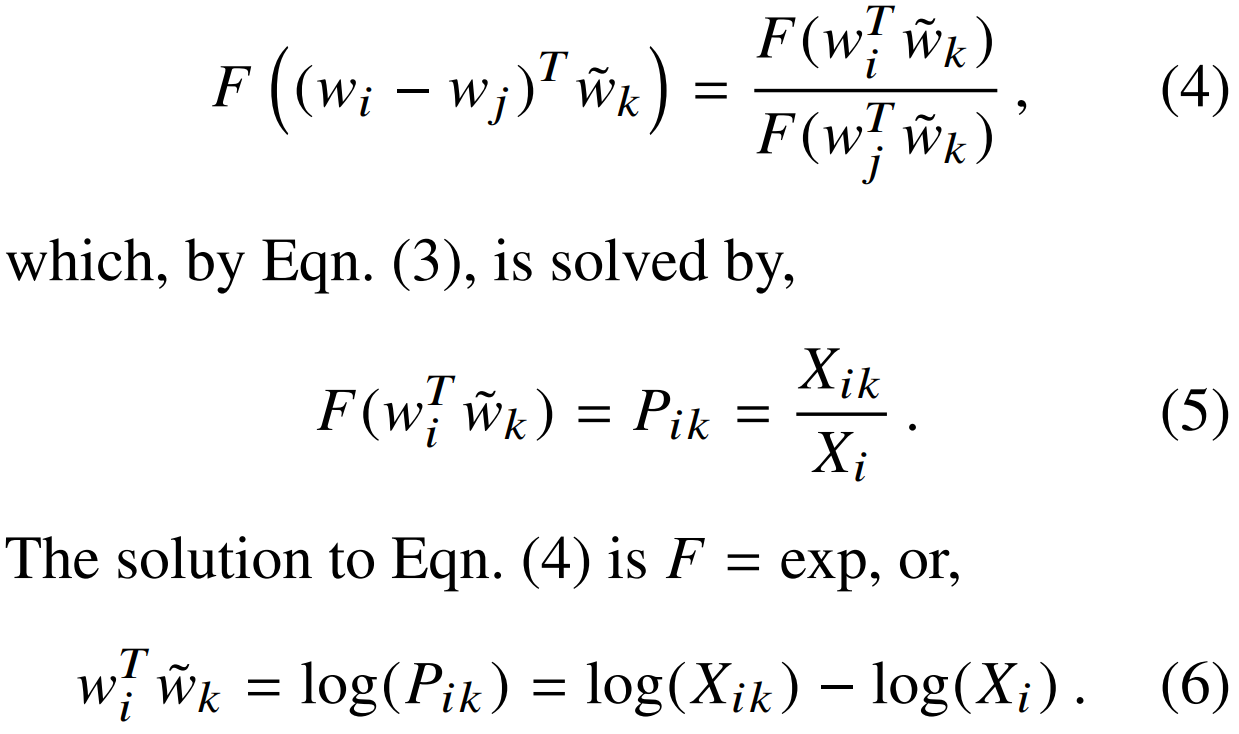
为了 i,k 的交换对称性,等式右边的 X_i (单项自己)需要被吸收,于是加入 b_i 和 b_k 的单项偏置。
![]()
最终损失函数写成 最小二乘形式:
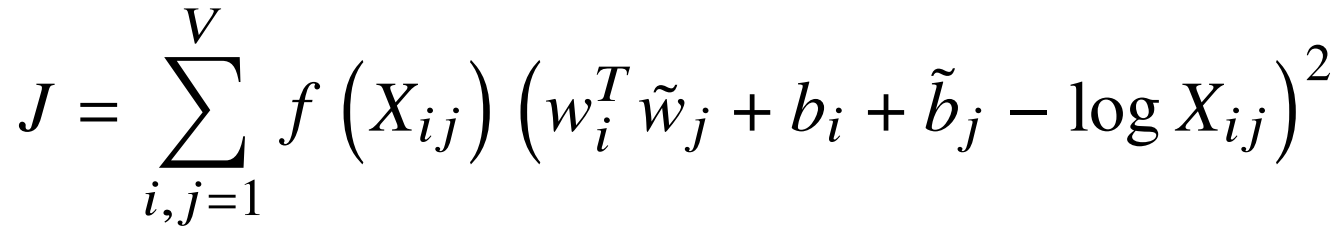
权重函数 f 需要满足一些性质(0处迅速衰减;非递减)最终选取如下 α = 0.75 的幂次形式
词嵌入的 benchmark:
Word analogy 单词类比、Word similarity 余弦相似度、Named entity recognition 命名实体识别
5. GloVe 代码实践(加载 + knn + 相似词查找 + 词类比 analogy)
建立 token - idx - vec 之间的映射;方便后续查询
依次读入得到 idx -> token 和 idx -> vec;并且txt文件的每一行都是 第一个词为 token 后面为 vec
import torch
# ===================== 1. 核心类:加载并解析GloVe预训练词向量 =====================
class TokenEmbedding:
def __init__(self, glove_file_path):
# 初始化:未知词的索引固定为0
self.unknown_idx = 0
# 加载词向量,返回:[词列表, 向量矩阵]
self.idx_to_token, self.idx_to_vec = self._load_glove_embedding(glove_file_path)
# 构建 单词->索引 的映射字典
self.token_to_idx = {token: idx for idx, token in enumerate(self.idx_to_token)}
def _load_glove_embedding(self, glove_file_path):
"""解析GloVe的txt文件,核心解析逻辑"""
idx_to_token = ['<unk>'] # 0 -> 未知词
idx_to_vec = []
# 第一步:先读取第一行,获取词向量维度(适配50/100/300维)
with open(glove_file_path, 'r', encoding='utf-8') as f:
first_line = f.readline().strip().split()
vec_dim = len(first_line) - 1 # 减1是因为第一个元素是单词
# 未知词的向量初始化为全0,维度和预训练向量一致
idx_to_vec.append([0.0] * vec_dim)
# 第二步:逐行读取并解析单词和向量 每行第一个为单词,后面为对应的词向量
with open(glove_file_path, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
if not line:
continue
elems = line.split()
token = elems[0] # 取出单词
vec = [float(x) for x in elems[1:]] # 取出对应的词向量
idx_to_token.append(token)
idx_to_vec.append(vec)
# 转为torch张量,方便后续计算
idx_to_vec = torch.tensor(idx_to_vec, dtype=torch.float32)
return idx_to_token, idx_to_vec
def __getitem__(self, tokens):
"""批量查询单词,输入:单词列表,输出:对应vector矩阵"""
if isinstance(tokens, str): # 兼容单个单词输入
tokens = [tokens]
# 查找每个单词的索引,找不到则返回未知词的索引0
indices = [self.token_to_idx.get(token, self.unknown_idx) for token in tokens]
indices = torch.tensor(indices, dtype=torch.long)
vecs = self.idx_to_vec[indices] # token -> idx -> vec
return vecs
def __len__(self):
"""返回词表总大小"""
return len(self.idx_to_token)1. 建立类,加载 GloVe;并验证 token <-> idx
print("开始加载GloVe预训练词向量...")
glove_embed = TokenEmbedding("glove.6B.50d.txt")
print(f"词向量加载完成!词表总大小:{len(glove_embed)}")
# 2. 测试映射:token <-> idx
token = "beautiful"
idx = glove_embed.token_to_idx[token]
print(f"单词【{token}】的索引:{idx}")
print(f"索引【{idx}】对应的单词:{glove_embed.idx_to_token[idx]}")2. 核心函数1:余弦相似度(向量计算) + K近邻查找(topk)
def knn(W, x, k):
# 计算向量x和矩阵W中所有向量的余弦相似度,返回相似度最高的k个索引+对应相似度
x = x.reshape(-1,) # 转为一维向量
# 计算所有余弦相似度 cos(a,b) = a·b / (||a|| * ||b||)
cos_sim = torch.mv(W, x) / (torch.sqrt(torch.sum(W * W, dim=1) + 1e-9)
* torch.sqrt(torch.sum(x * x) + 1e-9))
# 取相似度最高的k个
return torch.topk(cos_sim, k=k)2. 获取相似词
def get_similar_tokens(query_token, k, embed):
query_vec = embed[query_token] # 获取输入单词的词向量
# 找k+1个是为了排除自身
cos_sims, topk_indices = knn(embed.idx_to_vec, query_vec, k + 1)
print(f"与【{query_token}】最相似的{k}个单词:")
# 遍历输出(跳过第一个,第一个是输入单词本身)
for idx, cos in zip(topk_indices[1:], cos_sims[1:]):
token = embed.idx_to_token[idx]
print(f" {token} → 余弦相似度:{cos:.3f}")
# 3. 测试:词相似性检索
get_similar_tokens("chip", 3, glove_embed)
get_similar_tokens("baby", 3, glove_embed)
get_similar_tokens("beautiful", 3, glove_embed)3. 词类比任务 vec(d) ≈ vec(b) - vec(a) + vec(c)
def get_analogy(token_a, token_b, token_c, embed):
# 获取三个单词的词向量
vec_a, vec_b, vec_c = embed[[token_a, token_b, token_c]]
# 计算目标向量
target_vec = vec_b - vec_a + vec_c
# 找相似度最高的1个
_ , topk_indices = knn(embed.idx_to_vec, target_vec, 1)
# 返回对应的单词
return embed.idx_to_token[topk_indices[0]]
print("词类比任务测试:")
print(f"man : woman ≈ son : {get_analogy('man', 'woman', 'son', glove_embed)}")
print(f"beijing : china ≈ tokyo : {get_analogy('beijing', 'china', 'tokyo', glove_embed)}")
print(f"bad : worst ≈ big : {get_analogy('bad', 'worst', 'big', glove_embed)}")
print(f"do : did ≈ go : {get_analogy('do', 'did', 'go', glove_embed)}")6. 子词嵌入 FastText + BPE
传统词嵌入(Word2Vec、GloVe)的核心缺陷是将每个单词视为原子单位,完全忽略内部结构:
- 对变形词不友好:
help、helps、helped、helping会被当成 4 个独立单词,无法共享语义信息; - 对罕见词 / 未登录词无效:词表外的单词直接被标记为
[UNK],无法生成有效向量; - 跨语言适配差:像法语、芬兰语这类词形变化丰富的语言,传统词嵌入的词表会异常臃肿。
fastText模型 中心词的向量不再是单独的词向量,而是其子词向量 z 的总和。
![]() 字词集合为 用小窗口对词进行分割。
字词集合为 用小窗口对词进行分割。
如:单词 where 的 3-gram 子词集合 G_where 就是:{<wh, whe, her, ere, re>, <where>}
好处:helps 和 helped会共享大量子词(<he、hel、elp等),因此它们的向量也会高度相似,
自然捕捉到 “都是 help 的变形” 这一语义。
优点
- 天然支持词形变化:变形词因共享子词,向量会自动关联,无需额外规则;
- 处理罕见词 / 未登录词:哪怕是词表外的单词,只要能拆分子词,就能生成向量;
- 词表规模更可控:子词的数量远小于所有单词的数量,尤其适合形态丰富的语言。
缺点
- 计算复杂度更高:每个单词的向量需要累加多个子词向量,训练和推理速度比 Word2Vec 慢;
- 参数规模更大:词表从 “单词集合” 变成 “子词集合”,参数数量会有所增加。
FastText 的子词是固定长度的 n-gram,存在三个问题:
- 子词长度被硬限制死,无法表达
fast/tall/er这类语义完整的变长核心子词; - 词表大小不可控,无法精准控制最终的子词表规模;
- 对低频词的切分很僵硬,比如
unhappiness用固定 n-gram 切分会破坏语义,而 BPE 能切出un/happy/ness。
字节对编码(Byte Pair Encoding, BPE)数据驱动的变长子词提取算法。
符号词表初始化为所有英文小写字符、特殊的词尾符号 '_' 和特殊的未知符号 '[UNK]'。
给每一个单词的末尾都加上一个特殊符号,每个单词内部的所有字符之间,都用「空格」分隔。
贪心策略:每次合并「当前频率最高」的字符对,不断迭代实现:
- 高频的字符组合,一定是具有完整语义的子词(比如
fast/tall/er出现频率高,本身就是有意义的子词); - 低频的字符组合,保留成单个字符即可(比如生僻的字母组合);
7. BERT
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
同一个词不同上下文 意思可能不一样。(而 word2vec 和 GloVe 对同一个词的嵌入是固定的)
动机:类似 CV 里前面的神经网络层都在抽取特征,可以修改最后的分类头 迁移到其他任务。
- ELMo:首次证明了上下文敏感词嵌入比静态词嵌入(Word2Vec/GloVe)更有效,开启了预训练模型的先河。需要为每个下游任务单独设计专属模型架构。预训练的双向 LSTM 参数全程冻结,只训练下游任务的模型部分。
- GPT:预训练的 Transformer 所有参数都会参与下游任务的微调,所有下游任务都复用 Transformer 解码器架构,仅在输出层添加简单的线性层。但单向编码导致无法处理需要双向上下文的任务。
- BERT:融合前两者的优点,预训练-微调的范式 + encoder-only 的 transformer
输入表示通过将对应的词元嵌入、片段嵌入(区分不同句子)和位置编码相加来构建。
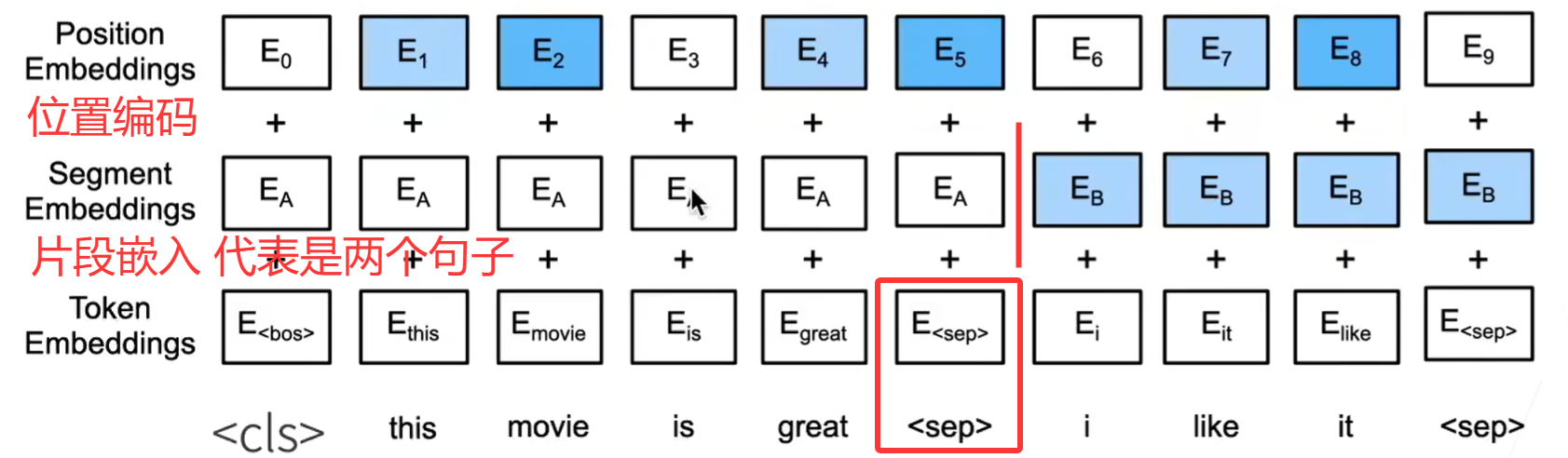
def get_tokens_and_segments(tokens_a, tokens_b=None):
# 获取输入序列的词元及其片段索引
tokens = ['<cls>'] + tokens_a + ['<sep>']
# 0和1分别标记片段A和B
segments = [0] * (len(tokens_a) + 2)
if tokens_b is not None:
tokens += tokens_b + ['<sep>']
segments += [1] * (len(tokens_b) + 1)
return tokens, segments预训练任务1:masked LM (Cloze task完形填空)
训练数据生成器随机选择15%的词元位置进行预测。
如果选择了第 i 个词元,我们用以下方式替换第 i 个词元:
(1)80%的时间使用 [MASK] 词元;
(2)10%的时间使用一个随机词元;
(3)10%的时间保持第 i 个词元不变。
不都改成 [MASK] 因为 微调中没有[MASK]:
-
传统方法(全部用
_代替):试卷上全是我爱_北京。学生只学会了根据_这个符号去猜词。但到了期末考试(微调),试卷上全是完整的句子我爱去北京、中国首都是北京。学生懵了:“没有_啊,我该干什么?” -
BERT的方法(80-10-10):
-
80%的题目是
我爱_北京。(学习核心技能:根据上下文填空) -
10%的题目是
我爱香蕉北京,并问“香蕉是对的吗?”(学习技能:上下文不合理时,敢于判断原词是错的,并纠正它) -
10%的题目是
我爱去北京,并问“去是对的吗?”(学习技能:上下文合理时,敢于判断原词是对的,保持原样)
-
预训练任务2:Next Sentence Prediction(为了帮助理解两个文本序列之间的关系)
许多重要的下游任务,如问答(QA)和自然语言推理(NLI),都基于理解两个句子之间的关系。
50%的时候 B是实际跟在A后面的下一个句子(标记为IsNext),50%是语料库的随机句子。
数据集:BooksCorpus + English Wikipedia
benchmark GLUE:The General Language Understanding Evaluation
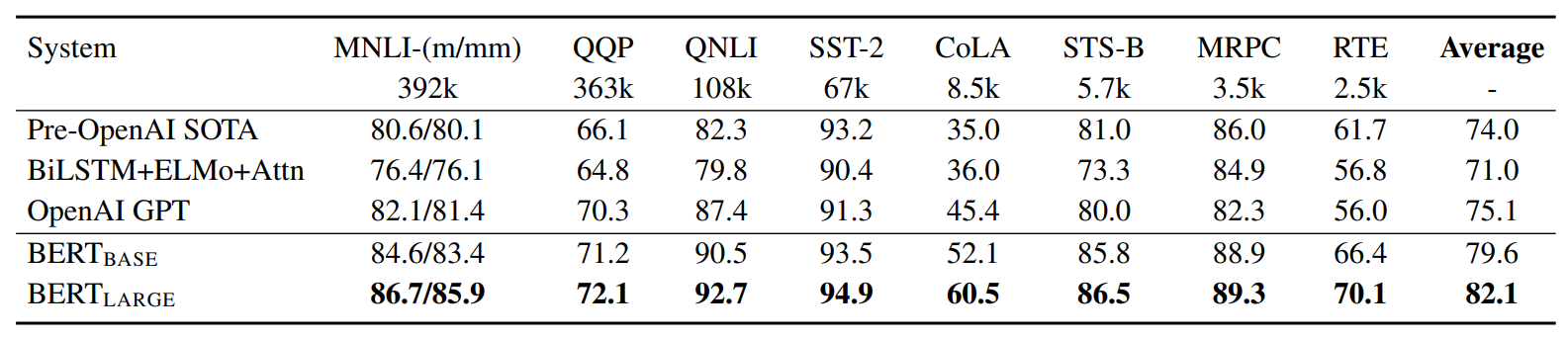
(SQuAD) Stanford Question Answering Dataset
(SWAG) The Situations With Adversarial Generations
8. bert-base-chinese 加载分词方法
https://huggingface.co/docs/transformers/model_doc/bert
(tokenizer + datasets + evaluate + pipeline)- csdn
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(pretrained_model_name_or_path='bert-base-chinese')
tokenizerspecial_tokens: 0: [PAD] 100: [UNK] 101: [CLS] 102: [SEP] 103: [MASK]
开始 [CLS] 句子
sents = [
'选择珠江花园的原因就是方便。',
'笔记本的键盘确实爽。',
]
out = tokenizer.encode(
text=sents[0],
text_pair=sents[1], # 一次编码两个句子,若没有text_pair这个参数,就一次编码一个句子
truncation=True, #当句子长度大于max_length时,截断
padding='max_length', #一律补pad到max_length长度
add_special_tokens=True,
max_length=30,
return_tensors=None, # None表示不指定数据类型,默认返回list
)
print(out)
tokenizer.decode(out)
'''
[101, 6848, 2885, 4403, 3736, 5709, 1736, 4638, 1333, 1728, 2218, 3221, 3175, 912, 511, 102, 5011, 6381, 3315, 4638, 7241, 4669, 4802, 2141, 4272, 511, 102, 0, 0, 0]
'[CLS] 选 择 珠 江 花 园 的 原 因 就 是 方 便 。 [SEP] 笔 记 本 的 键 盘 确 实 爽 。 [SEP] [PAD] [PAD] [PAD]'
'''获取词汇表
zidian = tokenizer.get_vocab() # 获取词表
type(zidian), len(zidian), '月光' in zidian, # (dict, 21128, False)添加新的词汇和符号(在整个词表的最后继续加)
#添加新词
tokenizer.add_tokens(new_tokens=['月光', '希望'])
#添加特殊符号
tokenizer.add_special_tokens({'eos_token': '[EOS]'}) # End Of Sentence
new_zidian = tokenizer.get_vocab()
type(new_zidian), len(new_zidian), new_zidian['月光'], new_zidian['[EOS]'] # (dict, 21131, 21128, 21130)再次编码 得到 “月光” “希望” 合并的分词。
out = tokenizer.encode(
text='月光的新希望[EOS]',
text_pair=None,
truncation=True, # 当句子长度大于max_length时,截断
padding='max_length', # 一律补pad到max_length长度
add_special_tokens=True,
max_length=8,
return_tensors=None,
)
print(out)
tokenizer.decode(out)
'''
[101, 21128, 4638, 3173, 21129, 21130, 102, 0]
'[CLS] 月光 的 新 希望 [EOS] [SEP] [PAD]'
'''
助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)