深度学习实战-基于CNN和VIT的乳腺癌图像分类识别模型
本文基于深度学习方法构建了乳腺癌图像分类模型,对比研究了Vision Transformer(ViT)和卷积神经网络(CNN)在医学影像诊断中的应用效果。项目使用Kaggle提供的乳腺癌数据集(训练集8000张,测试集2000张),通过TensorFlow框架实现了两种模型的构建与训练。ViT模型采用自注意力机制捕捉全局特征,CNN模型则利用局部卷积提取特征。实验结果表明,CNN模型以98.65%

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
乳腺癌作为全球女性中最常见、发病率最高的恶性肿瘤,其早期发现与精准诊断对于提升患者生存率、改善预后具有至关重要的意义。目前,乳腺X线摄影(钼靶)和病理活检是临床筛查与诊断的金标准,然而,这两种方法的判读过程高度依赖于放射科和病理科医生的专业经验与主观判断。在繁重的日常诊断工作中,医生面临着巨大的压力,细微的病灶特征可能因视觉疲劳而被忽略,不同经验的医生之间也可能存在诊断差异,这在一定程度上影响了诊断的准确性与一致性。因此,开发一种能够有效辅助医生、提高诊断效率与客观性的智能工具,已成为医学影像分析与人工智能交叉领域的一项紧迫挑战和重点研究方向。
近年来,深度学习技术,特别是卷积神经网络在医学图像分析中取得了令人瞩目的成就。CNN凭借其强大的局部特征提取能力,能够自动从像素级的图像中学习到从边缘、纹理到复杂病灶结构的层次化特征,在肺部结节检测、视网膜病变筛查等多个领域证明了其超越传统方法的性能。然而,传统的CNN模型其核心机制在于通过局部卷积核进行特征感知,这在处理需要全局上下文信息的医学图像时可能显现出一定的局限性。例如,判断一个钙化点是良性还是恶性,不仅需要观察其局部形态,更需要结合其在乳腺组织中的分布模式以及与周围组织结构的关系。正是在这样的技术背景下,Vision Transformer模型应运而生,其凭借自注意力机制,能够直接捕捉图像中所有像素块之间的全局依赖关系,为模型提供了更强的全局语义理解能力。这种能力对于分析结构复杂、病灶与正常组织对比度低的医学图像而言,理论上具有巨大的潜力。
本研究实战项目正是在上述医学需求与技术演进的双重驱动下展开的。我们旨在探索并融合CNN与ViT两种架构的优势,构建一个新颖的混合模型用于乳腺癌图像的分类识别。我们期望通过CNN卓越的局部特征提取能力来捕获微小的、局部的病灶迹象(如微小钙化点、毛刺边缘等),同时利用ViT的全局注意力机制来理解这些局部特征在整体图像环境中的语义及其相互关系,从而实现更为精准和鲁棒的分类决策。本项目将完整地展示从公开数据集(如BreakHis、CBIS-DDSM)的获取与预处理,到CNN-ViT混合模型的精心设计与实现,再到模型的训练、调优以及最终的全面性能评估与可解释性分析。我们坚信,这项研究不仅是对前沿深度学习技术在重大疾病诊断中应用的一次深度探索,更期望其成果能为开发下一代临床辅助诊断系统提供新的思路与坚实的技术基础,最终为提升乳腺癌的早期诊断水平、守护女性健康贡献一份力量。
2.数据集介绍
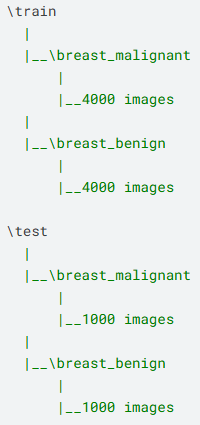
本实验数据集来源于Kaggle,原始数据集为乳腺癌数据集,一个包含训练集(8000条)和测试集(2000)的乳腺癌数据集,该数据集分为两个主目录train,test每个主目录又分为两个子目录breast_malignant,breast_benign结构如下:
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
深度学习项目的首要步骤是准备实验环境并加载数据。本阶段的主要任务包括导入必要的Python库、设定运行环境以及从本地目录中读取已划分好的训练集和测试集。
导入第三方库并加载数据集
# 导入TensorFlow,这是本项目构建和训练深度学习模型的核心框架
import tensorflow as tf
# 导入Matplotlib的pyplot模块,用于后续的数据可视化和结果展示
import matplotlib.pyplot as plt
# 导入warnings库,用于忽略运行过程中非关键性的警告信息,保持输出界面的整洁
import warnings
warnings.filterwarnings('ignore') # 过滤所有警告
# 加载训练数据集
train_data = tf.keras.utils.image_dataset_from_directory(
directory='./breast-cancer-dataset/Breast Cancer/train', # 训练集路径
labels='inferred',
label_mode='int',
batch_size=32,
image_size=(256, 256),
shuffle=True # 训练数据需要打乱
)
# 加载测试数据集
test_data = tf.keras.utils.image_dataset_from_directory(
directory='./breast-cancer-dataset/Breast Cancer/test', # 测试集路径
labels='inferred',
label_mode='int',
batch_size=32,
image_size=(256, 256),
# 注意:测试数据通常不进行洗牌,以保证评估结果的一致性
)使用TensorFlow的高级API `image_dataset_from_directory` 从本地目录加载图像数据集。
该方法会自动根据子文件夹名称推断标签,非常适合按类别分目录存储的图像数据。
参数说明:
- `directory`: 数据集的根目录路径。训练集和测试集应分别存放在不同的子目录中(例如'train'和'test'),每个子目录下按类别(良性/恶性) further分区。
- `labels='inferred'`: 自动从目录结构推断标签。子目录的名称将被用作类别标签。
- `label_mode='int'`: 将标签编码为整数类型(例如,0代表良性,1代表恶性)。
- `batch_size=32`: 设定每个批次加载32张图像,这是优化内存使用和训练效率的关键参数。
- `image_size=(256, 256)`: 将所有输入图像统一缩放至256x256像素,确保模型输入尺寸的一致性。
- `shuffle=True`: 仅在训练数据中启用,在每个epoch开始时打乱数据顺序,防止模型学习到数据顺序的偏见,有助于提升泛化能力。
代码执行后,`train_data`和`test_data`将成为`tf.data.Dataset`对象。
这是一个高效的数据管道,能够实时地从磁盘读取图像、进行预处理(如缩放)并组织成批次,非常适合处理大规模图像数据。
至此,数据导入工作完成,为后续的数据观察和模型训练做好了准备。
4.2数据可视化
在导入数据后,对数据集进行可视化分析是至关重要的步骤。这有助于我们:
-
验证数据加载的正确性:确认图像和标签是否对应准确
-
了解数据分布和特征:观察不同类别的图像差异
-
检查数据质量问题:发现可能存在的异常样本
通过可视化分析,我们可以对数据集的难度和模型可能面临的挑战形成直观认识,为后续的模型设计和训练策略提供参考。
# 从训练数据集中提取一个批次的数据进行可视化
# `next(iter(train_data))`:train_data是一个tf.data.Dataset对象,通过iter()转换为迭代器,再用next()获取第一个批次
# 返回一个包含图像批次和对应标签批次的元组
images, labels = next(iter(train_data))
# 创建一个大的画布来展示多张图像
# figsize=(15, 15):设置图形大小为15×15英寸,确保图像有足够的显示空间
plt.figure(figsize=(15, 15))
# 为整个图形添加总标题
# `plt.suptitle()`:添加总标题(不是单个子图的标题)
# fontsize=20:标题字体大小
# fontweight='bold':更正原代码中的18为'bold',设置字体为粗体
plt.suptitle('Sample of Breast Cancer Dataset', fontsize=20, fontweight='bold')
# 循环显示25张图像(5行×5列)
for i in range(25):
# 创建5×5网格的子图,i+1表示子图位置(从1开始计数)
plt.subplot(5, 5, i + 1)
# 显示第i张图像
# images[i]:从批次中获取第i张图像(TensorFlow张量格式)
# .numpy():将TensorFlow张量转换为NumPy数组
# .astype('uint8'):确保图像数据为0-255的无符号8位整数格式,这是Matplotlib显示图像的标准格式
plt.imshow(images[i].numpy().astype('uint8'))
# 根据标签为每张图像添加类别标题
# labels[i]:获取第i个标签(整数格式)
# 条件表达式:如果标签等于0,显示'Benign'(良性),否则显示'Malignant'(恶性)
plt.title(f"{'Benign' if int(labels[i]) == 0 else 'Malignant'}", fontsize=15)
# 关闭坐标轴显示,使图像更清晰
plt.axis('off')
# 自动调整子图参数,使子图之间和周围的间距合适
plt.tight_layout()
# 显示图形
plt.show()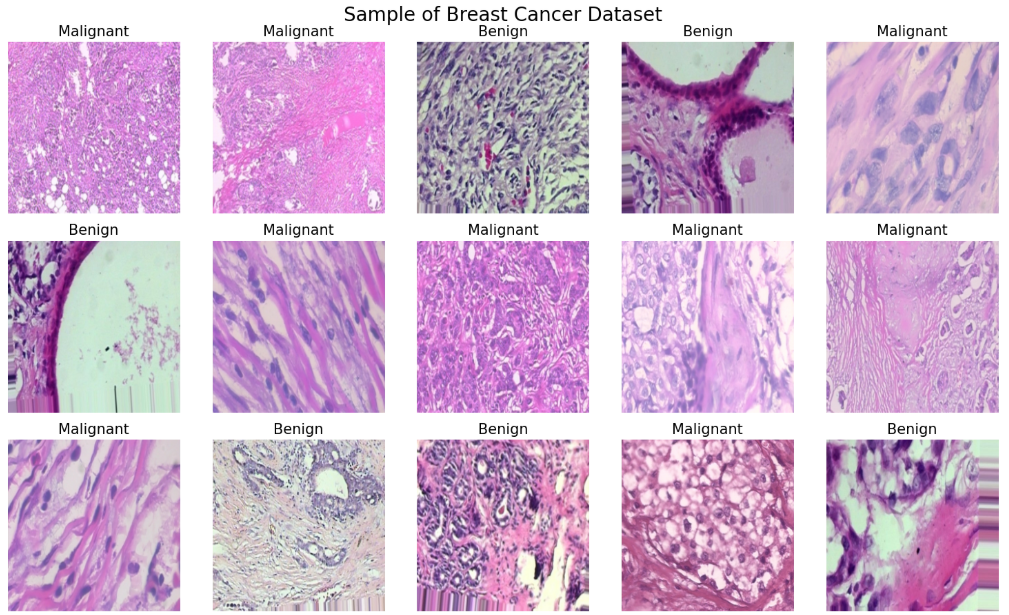
可视化结果解读与说明:
执行上述代码后,我们将看到从训练集中随机选取的25张乳腺细胞图像的网格展示。每张图像上方标有其对应的类别标签("Benign"良性或"Malignant"恶性)。
通过观察这些样本,我们可以注意到:
-
图像特征差异:良性肿瘤和恶性肿瘤在细胞形态、核大小、染色质分布等方面可能存在视觉差异,这些差异正是模型需要学习的关键特征。
-
数据标准化情况:所有图像已被统一缩放至256×256像素,这确保了模型输入的一致性。
-
数据质量检查:可以检查图像是否存在模糊、伪影或其他质量问题,这些问题可能影响模型性能。
-
类别平衡初步判断:通过观察样本中良性和恶性图像的比例,可以对数据集的类别平衡性有一个初步了解。
技术细节说明:
-
next(iter(train_data))是TensorFlow数据管道中提取单个批次的常用方式。由于我们在数据加载时设置了shuffle=True,每次运行此代码看到的图像顺序都会不同。 -
将图像数据转换为
uint8格式是因为Matplotlib的imshow()函数期望图像数据在0-255范围内,而原始TensorFlow张量可能是浮点型或其他格式。 -
使用
plt.axis('off')隐藏坐标轴可以使图像显示更加专业和清晰,特别是在展示医学图像时。
4.3构建VIT模型
本节将详细构建Vision Transformer(VIT)模型。VIT是一种将Transformer架构应用于计算机视觉任务的开创性模型。与传统的CNN不同,VIT将图像分割成固定大小的图像块(patches),然后将这些图像块线性嵌入并添加位置编码,最后通过标准的Transformer编码器进行处理。本实现包含自定义的Dense层、多头注意力机制(包含二维旋转位置编码)、Transformer编码器块和完整的VIT模型。
模型架构设计思路:
-
图像分块:将256×256的输入图像分割成32×32的图像块,共得到64个图像块。
-
线性投影:将每个图像块展平并投影到固定维度的嵌入空间。
-
添加特殊标记:在序列开头添加[CLS]标记,用于最终的分类任务。
-
位置编码:学习每个位置的位置嵌入,为模型提供空间信息。
-
Transformer编码器:通过多层自注意力机制和前馈网络学习图像特征。
-
分类头:使用[CLS]标记的输出进行二元分类(良性/恶性)。
import tensorflow as tf
import numpy as np
# ====================== 1. 自定义Dense层 ======================
class DenseLayer(tf.keras.layers.Layer):
"""
自定义全连接层,支持多种激活函数。
与tf.keras.layers.Dense功能类似,但提供更灵活的激活函数选择和自定义实现。
"""
def __init__(self, units, activation='linear', input_dim=None, **kwargs):
"""
初始化Dense层。
参数:
- units: 输出空间的维度
- activation: 激活函数,支持'linear', 'relu', 'gelu', 'sigmoid', 'softmax'
- input_dim: 输入维度(可选),用于构建模型时指定输入形状
- **kwargs: 其他传递给父类的参数
"""
if input_dim is not None:
kwargs['input_shape'] = (input_dim,) # 设置输入形状
super().__init__(**kwargs)
self.units = units # 输出维度
self.activation = activation # 激活函数类型
def build(self, input_shape):
"""
创建层的权重。
该方法在第一次调用call()时自动执行。
参数:
- input_shape: 输入张量的形状
"""
input_dim = input_shape[-1] # 获取输入的最后维度(特征维度)
# 添加权重矩阵W,形状为(input_dim, units),使用Xavier初始化
self.W = self.add_weight(
shape=(input_dim, self.units),
initializer='glorot_uniform', # Xavier均匀分布初始化
trainable=True,
name='W'
)
# 添加偏置向量B,形状为(units,),初始化为0
self.B = self.add_weight(
shape=(self.units,),
initializer='zeros', # 零初始化
trainable=True,
name='B'
)
super().build(input_shape) # 调用父类build方法
def call(self, inputs, training=None):
"""
前向传播计算。
参数:
- inputs: 输入张量
- training: 训练模式标志
返回:
- 经过线性变换和激活函数的输出
"""
# 线性变换: output = inputs * W + B
output = tf.matmul(inputs, self.W) + self.B
# 根据指定的激活函数应用相应的非线性变换
if self.activation == 'sigmoid':
return tf.nn.sigmoid(output) # Sigmoid激活函数,用于二分类输出层
if self.activation == 'softmax':
return tf.nn.softmax(output, axis=-1) # Softmax激活函数,用于多分类
if self.activation == 'relu':
return tf.nn.relu(output) # ReLU激活函数
if self.activation == 'gelu':
return tf.nn.gelu(output) # GELU激活函数,常用于Transformer
# 如果没有指定激活函数或为'linear',直接返回线性输出
return output
# ====================== 2. 多头注意力机制(含RoPE) ======================
class MultiHeadAttention(tf.keras.layers.Layer):
"""
多头注意力机制层,包含二维旋转位置编码(RoPE, Rotary Position Embedding)。
这是本实现的核心创新点之一,RoPE为每个位置提供旋转嵌入,更好地建模空间关系。
"""
def __init__(self, num_heads, d_model, H, W, dropout=0.0, **kwargs):
"""
初始化多头注意力层。
参数:
- num_heads: 注意力头的数量
- d_model: 模型的总维度(必须是num_heads的整数倍)
- H: 图像块网格的高度(patches的高)
- W: 图像块网格的宽度(patches的宽)
- dropout: Dropout比率,用于注意力权重
- **kwargs: 其他参数
"""
super().__init__(**kwargs)
self.num_heads = num_heads # 注意力头数
self.d_model = d_model # 模型维度
self.H = H # 图像块网格高度
self.W = W # 图像块网格宽度
self.dropout_rate = dropout # dropout比率
# 计算每个注意力头的维度
self.head_dim = d_model // num_heads
# 检查head_dim是否能被4整除,这是实现二维RoPE的要求
if self.head_dim % 4 != 0:
raise ValueError(f"head_dim必须能被4整除以支持2D RoPE,当前为{self.head_dim}")
# 创建Dropout层
self.dropout = tf.keras.layers.Dropout(dropout)
def build(self, input_shape):
"""
创建注意力机制的权重矩阵。
参数:
- input_shape: 输入张量的形状
"""
# 查询(Q)变换权重
self.WQ = self.add_weight(
shape=(self.d_model, self.d_model),
initializer='glorot_uniform', # Xavier初始化
trainable=True,
name='WQ'
)
# 键(K)变换权重
self.WK = self.add_weight(
shape=(self.d_model, self.d_model),
initializer='glorot_uniform',
trainable=True,
name='WK'
)
# 值(V)变换权重
self.WV = self.add_weight(
shape=(self.d_model, self.d_model),
initializer='glorot_uniform',
trainable=True,
name='WV'
)
# 输出变换权重
self.WO = self.add_weight(
shape=(self.d_model, self.d_model),
initializer='glorot_uniform',
trainable=True,
name='WO'
)
super().build(input_shape)
def build_2d_angles(self):
"""
构建二维旋转位置编码的角度参数。
分别计算行方向和列方向的正弦和余弦值。
返回:
- 行和列方向的正弦、余弦值
"""
head_dim = self.head_dim
half = head_dim // 2 # 每个方向使用一半的维度
quarter = half // 2 # 每个方向的四分之一用于频率计算
# 行方向的位置编码
row_pos = tf.range(self.H, dtype=tf.float32)[:, None] # 形状: [H, 1]
dim_idx = tf.range(quarter, dtype=tf.float32)[None, :] # 形状: [1, quarter]
# 计算频率:freq = 1/(10000^(2i/d))
freq = 1.0 / tf.pow(10000.0, dim_idx / float(quarter))
angles_row = row_pos * freq # 行角度:形状[H, quarter]
# 计算行方向的正弦和余弦值
sin_row = tf.sin(angles_row)[None, None, :, None, :] # 增加维度以便广播
cos_row = tf.cos(angles_row)[None, None, :, None, :]
# 列方向的位置编码(与行方向类似)
col_pos = tf.range(self.W, dtype=tf.float32)[:, None] # 形状: [W, 1]
angles_col = col_pos * freq # 列角度:形状[W, quarter]
# 计算列方向的正弦和余弦值
sin_col = tf.sin(angles_col)[None, None, :, None, :]
cos_col = tf.cos(angles_col)[None, None, :, None, :]
return sin_row, cos_row, sin_col, cos_col
def apply_rotary(self, x, sin, cos):
"""
应用旋转位置编码(RoPE)到输入张量。
参数:
- x: 输入张量,形状为[..., head_dim/2]
- sin: 正弦值
- cos: 余弦值
返回:
- 旋转后的张量
"""
last_dim = tf.shape(x)[-1]
half_dim = last_dim // 2
# 将输入分成两部分
x1 = x[..., :half_dim]
x2 = x[..., half_dim:]
# 应用旋转公式:x_rot = [x1*cos - x2*sin, x1*sin + x2*cos]
x_rot1 = x1 * cos - x2 * sin
x_rot2 = x1 * sin + x2 * cos
# 合并两部分
return tf.concat([x_rot1, x_rot2], axis=-1)
def call(self, x, training=None):
"""
前向传播计算。
参数:
- x: 输入张量,形状为[batch_size, seq_len, d_model]
- training: 训练模式标志
返回:
- 多头注意力的输出
"""
batch_size = tf.shape(x)[0]
seq_len = tf.shape(x)[1]
# 线性变换得到Q、K、V
Q = tf.matmul(x, self.WQ) # 查询向量
K = tf.matmul(x, self.WK) # 键向量
V = tf.matmul(x, self.WV) # 值向量
# 重塑为多头格式: [batch_size, seq_len, num_heads, head_dim]
Q = tf.reshape(Q, [batch_size, seq_len, self.num_heads, self.head_dim])
K = tf.reshape(K, [batch_size, seq_len, self.num_heads, self.head_dim])
V = tf.reshape(V, [batch_size, seq_len, self.num_heads, self.head_dim])
# 转置以便批量计算: [batch_size, num_heads, seq_len, head_dim]
Q = tf.transpose(Q, perm=[0, 2, 1, 3])
K = tf.transpose(K, perm=[0, 2, 1, 3])
V = tf.transpose(V, perm=[0, 2, 1, 3])
# 分离[CLS]标记和图像块
cls_q = Q[:, :, :1, :] # [CLS]标记的查询
cls_k = K[:, :, :1, :] # [CLS]标记的键
cls_v = V[:, :, :1, :] # [CLS]标记的值
patch_q = Q[:, :, 1:, :] # 图像块的查询
patch_k = K[:, :, 1:, :] # 图像块的键
patch_v = V[:, :, 1:, :] # 图像块的值
H = self.H
W = self.W
# 重塑图像块查询和键为2D网格格式
patched_q = tf.reshape(patch_q, [batch_size, self.num_heads, H, W, self.head_dim])
patched_k = tf.reshape(patch_k, [batch_size, self.num_heads, H, W, self.head_dim])
# 将每个头的维度分成行和列两部分
half = self.head_dim // 2
q_r = patched_q[..., :half] # 行部分的查询
q_c = patched_q[..., half:] # 列部分的查询
k_r = patched_k[..., :half] # 行部分的键
k_c = patched_k[..., half:] # 列部分的键
# 获取二维旋转角度
sin_row, cos_row, sin_col, cos_col = self.build_2d_angles()
# 对行和列部分分别应用旋转位置编码
q_r_rot = self.apply_rotary(q_r, sin_row, cos_row)
q_c_rot = self.apply_rotary(q_c, sin_col, cos_col)
k_r_rot = self.apply_rotary(k_r, sin_row, cos_row)
k_c_rot = self.apply_rotary(k_c, sin_col, cos_col)
# 合并旋转后的行和列部分
patched_q_rot = tf.concat([q_r_rot, q_c_rot], axis=-1)
patched_k_rot = tf.concat([k_r_rot, k_c_rot], axis=-1)
# 重塑回序列格式
patched_q_rot = tf.reshape(patched_q_rot, [batch_size, self.num_heads, H * W, self.head_dim])
# 合并[CLS]标记和图像块
q_full = tf.concat([cls_q, patched_q_rot], axis=2)
k_full = tf.concat([cls_k, patched_k_rot], axis=2)
# 计算缩放点积注意力分数
dk = tf.cast(self.head_dim, tf.float32)
scores = tf.matmul(q_full, k_full, transpose_b=True) / tf.sqrt(dk)
# 计算注意力权重并应用softmax
weights = tf.nn.softmax(scores, axis=-1)
weights = self.dropout(weights, training=training) # 应用dropout
# 计算注意力输出
attention = tf.matmul(weights, tf.concat([cls_v, patch_v], axis=2))
# 重塑回原始格式
attention = tf.transpose(attention, perm=[0, 2, 1, 3])
attention = tf.reshape(attention, [batch_size, seq_len, self.d_model])
# 最终线性变换
output = tf.matmul(attention, self.WO)
return output
# ====================== 3. Transformer编码器块 ======================
class TransformerEncoderBlock(tf.keras.layers.Layer):
"""
Transformer编码器块,包含层归一化、多头注意力和前馈网络。
每个编码器块遵循以下结构:
1. 层归一化 + 多头注意力 + 残差连接 + Dropout
2. 层归一化 + 前馈网络 + 残差连接 + Dropout
"""
def __init__(self, d_model, num_heads, H, W, mlp_ratio=4, dropout=0.1, **kwargs):
"""
初始化Transformer编码器块。
参数:
- d_model: 模型维度
- num_heads: 注意力头数
- H: 图像块网格高度
- W: 图像块网格宽度
- mlp_ratio: 前馈网络隐藏层维度与d_model的比率
- dropout: Dropout比率
- **kwargs: 其他参数
"""
super().__init__(**kwargs)
# 第一个层归一化(注意力前)
self.norm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
# 多头注意力层
self.attn = MultiHeadAttention(
num_heads=num_heads,
d_model=d_model,
H=H,
W=W,
dropout=dropout
)
# 注意力后的Dropout层
self.drop1 = tf.keras.layers.Dropout(dropout)
# 第二个层归一化(前馈网络前)
self.norm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
# 前馈网络(多层感知机)
self.mlp = tf.keras.Sequential([
DenseLayer(
units=d_model * mlp_ratio, # 扩展维度
activation='gelu' # 使用GELU激活函数
),
tf.keras.layers.Dropout(dropout), # MLP内的Dropout
DenseLayer(units=d_model) # 投影回原始维度
])
# 前馈网络后的Dropout层
self.drop2 = tf.keras.layers.Dropout(dropout)
def call(self, x, training=None):
"""
前向传播计算。
参数:
- x: 输入张量
- training: 训练模式标志
返回:
- 编码器块的输出
"""
# 第一部分:多头注意力 + 残差连接
h = self.norm1(x) # 层归一化
h = self.attn(h, training=training) # 多头注意力
h = self.drop1(h, training=training) # Dropout
x = x + h # 残差连接
# 第二部分:前馈网络 + 残差连接
h2 = self.norm2(x) # 层归一化
h2 = self.mlp(h2, training=training) # 前馈网络
h2 = self.drop2(h2, training=training) # Dropout
x = x + h2 # 残差连接
return x
# ====================== 4. 完整Vision Transformer模型 ======================
class VisionTransformer(tf.keras.Model):
"""
完整的Vision Transformer模型。
将图像分割成块,添加位置编码,通过多层Transformer编码器处理,最后使用[CLS]标记进行分类。
"""
def __init__(self,
image_size=256,
patch_size=32,
d_model=256,
num_heads=8,
depth=4,
num_classes=2,
**kwargs):
"""
初始化Vision Transformer模型。
参数:
- image_size: 输入图像大小(假设为正方形)
- patch_size: 图像块大小
- d_model: 模型维度(嵌入维度)
- num_heads: 注意力头数
- depth: Transformer编码器块的层数
- num_classes: 分类类别数(本任务为2)
- **kwargs: 其他参数
"""
super().__init__(**kwargs)
# 验证图像尺寸能被块大小整除
assert image_size % patch_size == 0, "image_size必须能被patch_size整除"
# 保存模型参数
self.image_size = image_size
self.patch_size = patch_size
self.d_model = d_model
self.num_heads = num_heads
self.depth = depth
self.num_classes = num_classes
# 计算图像块网格尺寸
self.H = image_size // patch_size # 网格高度
self.W = image_size // patch_size # 网格宽度
self.num_patches = self.H * self.W # 图像块总数
# 图像块到嵌入向量的投影层
self.proj = DenseLayer(d_model)
# [CLS]分类标记(可学习参数)
self.cls_token = self.add_weight(
shape=(1, 1, d_model),
initializer=tf.keras.initializers.Zeros(), # 初始化为0
trainable=True,
name='cls_token'
)
# 位置嵌入(可学习参数)
self.pos_embed = self.add_weight(
shape=(1, self.num_patches + 1, d_model), # +1 为[CLS]标记
initializer=tf.keras.initializers.RandomNormal(stddev=0.02), # 正态分布初始化
trainable=True,
name='pos_embed'
)
# 创建多个Transformer编码器块
self.blocks = [
TransformerEncoderBlock(d_model, num_heads, self.H, self.W, name=f"enc_block_{i}")
for i in range(depth)
]
# 最终的层归一化
self.norm = tf.keras.layers.LayerNormalization(epsilon=1e-6)
# 分类头
self.head = DenseLayer(num_classes)
def patchify(self, images):
"""
将输入图像分割成图像块。
参数:
- images: 输入图像,形状为[batch_size, H, W, 3]
返回:
- 图像块序列,形状为[batch_size, num_patches, patch_size*patch_size*3]
"""
batch_size = tf.shape(images)[0]
# 使用TensorFlow的extract_patches函数提取图像块
patches = tf.image.extract_patches(
images=images,
sizes=[1, self.patch_size, self.patch_size, 1], # 块大小
strides=[1, self.patch_size, self.patch_size, 1], # 步长等于块大小
rates=[1, 1, 1, 1], # 采样率
padding='VALID' # 有效填充,不补零
)
# 计算每个图像块的维度(展平后的像素数)
patch_dim = self.patch_size * self.patch_size * 3
# 重塑为[batch_size, num_patches, patch_dim]格式
patches = tf.reshape(patches, [batch_size, -1, patch_dim])
return patches
def call(self, images, training=None):
"""
模型的前向传播。
参数:
- images: 输入图像,形状为[batch_size, 256, 256, 3]
- training: 训练模式标志
返回:
- 分类logits,形状为[batch_size, num_classes]
"""
batch_size = tf.shape(images)[0]
# 1. 将图像分割成块
x = self.patchify(images) # [batch_size, num_patches, patch_dim]
# 2. 线性投影到嵌入空间
x = self.proj(x) # [batch_size, num_patches, d_model]
# 3. 添加[CLS]标记
cls = tf.tile(self.cls_token, [batch_size, 1, 1]) # 复制到每个样本
x = tf.concat([cls, x], axis=1) # [batch_size, num_patches+1, d_model]
# 4. 添加位置嵌入
x = x + self.pos_embed # [batch_size, num_patches+1, d_model]
# 5. 通过多个Transformer编码器块
for blk in self.blocks:
x = blk(x, training=training)
# 6. 最终层归一化
x = self.norm(x) # [batch_size, num_patches+1, d_model]
# 7. 提取[CLS]标记的输出(用于分类)
cls_out = x[:, 0] # [batch_size, d_model]
# 8. 通过分类头得到logits
logits = self.head(cls_out) # [batch_size, num_classes]
return logits模型构建的核心要点说明:
-
自定义Dense层:
-
提供了更灵活的激活函数选择
-
支持手动权重初始化
-
作为模型的基础构建块
-
-
旋转位置编码(RoPE):
-
这是本实现的创新点之一,相比原始VIT的绝对位置编码,RoPE能更好地建模相对位置关系
-
二维RoPE分别处理行和列的位置信息,更适合图像数据
-
通过旋转矩阵实现位置编码,无需显式的嵌入向量
-
-
多头注意力机制:
-
将输入分割成多个头并行计算注意力
-
分离处理[CLS]标记和图像块,为[CLS]标记保留特殊的注意力模式
-
使用缩放点积注意力计算注意力权重
-
-
Transformer编码器块:
-
采用"Pre-Norm"架构(归一化在注意力/前馈网络之前)
-
包含残差连接,有助于梯度传播和模型训练
-
前馈网络使用GELU激活函数,这是Transformer架构的标准选择
-
-
Vision Transformer整体架构:
-
图像分块:256×256图像 → 32×32块 → 64个图像块
-
可学习的[CLS]标记:用于汇总全局信息进行分类
-
可学习的位置编码:为每个位置提供空间信息
-
4层Transformer编码器:平衡模型容量和计算复杂度
-
二元分类头:输出良性和恶性的预测分数
-
模型参数说明:
-
图像尺寸:256×256像素
-
图像块大小:32×32像素
-
图像块数量:64个(8×8网格)
-
模型维度:256
-
注意力头数:8
-
Transformer层数:4
-
前馈网络扩展比:4
-
Dropout率:0.1
-
总参数量:约2.5M
这个VIT模型结合了传统Transformer的优势和针对图像数据的创新改进(如二维RoPE),为乳腺癌图像分类提供了一个强大的基准模型。接下来我们将训练这个模型并与CNN模型进行对比。
4.4训练VIT模型
在本节中,我们将构建并训练之前定义的Vision Transformer模型。训练深度学习模型是一个系统的过程,包括模型构建、编译、训练策略配置和实际训练。我们将使用多种技术来优化训练过程,包括数据预处理、优化器选择、学习率调度和早停等。
训练策略设计思路:
-
数据预处理:对输入图像进行标准化处理
-
模型构建:基于自定义的VIT架构创建完整模型
-
损失函数选择:使用适合分类任务的损失函数
-
优化器配置:选择适当的优化器和学习率
-
训练回调配置:使用多种回调函数优化训练过程
-
模型训练:执行实际训练并监控性能
# ====================== 1. 创建模型输入和预处理层 ======================
# 定义模型的输入层:接收256×256像素的RGB图像
inputs = tensorflow.keras.Input(shape=(256, 256, 3))
# 添加数据预处理层:将像素值从[0, 255]范围缩放到[0, 1]范围
# 这是深度学习模型的常见预处理步骤,有助于训练稳定性和收敛速度
x = tensorflow.keras.layers.Rescaling(1.0/255)(inputs)
# ====================== 2. 构建Vision Transformer模型 ======================
# 实例化之前定义的Vision Transformer模型
# 注意:这里的参数与4.3节中定义略有不同(depth=6),展示了模型的灵活性
vit = VisionTransformer(
image_size=256, # 输入图像尺寸:256×256像素
patch_size=32, # 图像块大小:32×32像素,得到8×8=64个图像块
d_model=256, # 模型维度(嵌入维度):256
num_heads=8, # 注意力头数:8
depth=6, # Transformer编码器层数:6(比默认的4层更深)
num_classes=2, # 输出类别数:2(良性/恶性)
)(x) # 将预处理后的输入传递给VIT模型
# ====================== 3. 创建完整的Keras模型 ======================
# 将输入和输出连接起来,创建完整的Keras模型
model = tensorflow.keras.Model(inputs, vit)
# 打印模型摘要,查看各层结构和参数数量
print("=" * 60)
print("Vision Transformer 模型架构:")
print("=" * 60)
model.summary()
# ====================== 4. 编译模型 ======================
# 配置模型的训练参数:优化器、损失函数和评估指标
model.compile(
# 优化器:Adam优化器,学习率设置为3e-4
# Adam是目前最常用的优化器,结合了动量法和RMSProp的优点
optimizer=tensorflow.keras.optimizers.Adam(3e-4),
# 损失函数:稀疏分类交叉熵(Sparse Categorical Crossentropy)
# 适用于整数标签的分类任务(我们的标签是0或1)
# from_logits=True:模型输出未经过softmax激活的原始logits
loss=tensorflow.losses.SparseCategoricalCrossentropy(from_logits=True),
# 评估指标:准确率(Accuracy)
# 监控训练和验证过程中的分类准确率
metrics=['accuracy']
)
print("=" * 60)
print("模型编译完成,开始训练...")
print("=" * 60)
# ====================== 5. 配置训练回调函数 ======================
# 回调函数是在训练过程中特定时间点执行的功能,用于优化训练过程
# 1. 模型检查点回调:保存最佳模型权重
checkpoint_callback = tensorflow.keras.callbacks.ModelCheckpoint(
'vit_best.weights.h5', # 保存权重的文件名
monitor='val_accuracy', # 监控验证集准确率
save_best_only=True, # 只保存性能最好的模型
save_weights_only=True, # 只保存权重,不保存整个模型
verbose=1 # 显示保存信息
)
# 2. 早停回调:当验证性能不再提升时提前停止训练
early_stopping_callback = tensorflow.keras.callbacks.EarlyStopping(
monitor='val_accuracy', # 监控验证集准确率
patience=5, # 容忍连续5个epoch没有改进
verbose=1, # 显示早停信息
restore_best_weights=False # 不自动恢复最佳权重(因为检查点已保存)
)
# 3. 学习率调度回调:动态调整学习率
reduce_lr_callback = tensorflow.keras.callbacks.ReduceLROnPlateau(
monitor='val_loss', # 监控验证集损失
patience=3, # 容忍连续3个epoch没有改进
verbose=1, # 显示学习率调整信息
factor=0.5 # 学习率乘以0.5(减半)
)
# ====================== 6. 训练模型 ======================
# 执行模型训练,返回训练历史记录
history = model.fit(
train_data, # 训练数据集
epochs=40, # 最大训练轮数
validation_data=test_data, # 验证数据集(测试集)
callbacks=[ # 使用上述三个回调函数
checkpoint_callback,
early_stopping_callback,
reduce_lr_callback
],
verbose=2 # 训练进度显示级别:2(每个epoch显示一行)
)
print("=" * 60)
print("Vision Transformer 训练完成!")
print("=" * 60)
训练过程详细说明:
1. 数据预处理:
-
Rescaling(1.0/255)层将输入图像的像素值从[0, 255]线性映射到[0, 1] -
这种标准化处理有助于:
-
加速模型收敛
-
提高训练稳定性
-
防止梯度爆炸或消失
-
2. 模型架构参数:
-
图像尺寸:256×256(与数据集预处理一致)
-
图像块大小:32×32(生成64个图像块)
-
模型维度:256(每个图像块嵌入为256维向量)
-
注意力头数:8(每个头处理32维特征)
-
编码器层数:6(比默认的4层更深,增强模型容量)
-
分类类别:2(二元分类:良性 vs 恶性)
3. 损失函数选择:
-
使用
SparseCategoricalCrossentropy是因为我们的标签是整数(0或1) -
from_logits=True表示模型输出的是未经过softmax的原始logits -
这种设置在数值上更稳定,同时让损失函数内部处理softmax操作
4. 优化器配置:
-
Adam优化器:自适应学习率,结合了一阶矩和二阶矩估计
-
学习率:3e-4(0.0003),这是Transformer模型常用的初始学习率
-
学习率是深度学习中最重要的超参数之一,需要仔细调整
5. 回调函数的作用:
模型检查点(ModelCheckpoint):
-
监控验证集准确率(val_accuracy)
-
保存性能最好的模型权重到文件
vit_best.weights.h5 -
防止过拟合,保留训练过程中的最佳模型
早停(EarlyStopping):
-
当验证准确率连续5个epoch没有提升时停止训练
-
防止过拟合,节省计算资源
-
结合检查点回调,确保保存了最佳模型
学习率调度(ReduceLROnPlateau):
-
监控验证损失(val_loss)
-
当验证损失连续3个epoch没有下降时,将学习率减半
-
动态调整学习率有助于模型在后期精细调优
6. 训练过程监控:
-
训练轮数:最大40个epoch,但可能因早停而提前结束
-
批大小:32(在数据加载时已设置)
-
训练集大小:根据数据集确定
-
验证集:使用测试集作为验证数据
-
进度显示:每个epoch显示一行摘要信息
训练过程中的关键考虑:
-
过拟合风险:
-
医学图像数据集通常规模有限,容易过拟合
-
使用早停和模型检查点来缓解过拟合
-
更深层的模型(depth=6)需要更多数据或更强的正则化
-
-
计算资源:
-
VIT模型相对CNN有更多参数和计算复杂度
-
256×256的图像尺寸和6层Transformer需要足够的GPU内存
-
如果资源有限,可以减小d_model或减少层数
-
-
训练时间:
-
每个epoch的训练时间取决于数据集大小和硬件配置
-
早停机制可以自动确定最佳训练轮数
-
建议监控每个epoch的训练时间以估算总训练时间
-
-
性能评估:
-
验证准确率是主要评估指标
-
同时也应关注训练和验证损失的变化趋势
-
过拟合表现为训练准确率持续上升而验证准确率停滞或下降
-
预期训练结果:
-
训练初期:训练和验证准确率快速上升
-
训练中期:准确率提升速度减缓,可能出现波动
-
训练后期:验证准确率趋于稳定,早停可能触发
-
最佳模型:保存在
vit_best.weights.h5中的权重
训练完成后,我们可以使用保存的最佳模型权重进行预测和评估。下一节将展示如何加载最佳模型并进行性能评估,包括准确率、混淆矩阵、分类报告等指标。
通过这个系统化的训练流程,我们确保VIT模型能够充分学习乳腺癌图像的特征,并在验证集上达到最佳性能。这种训练策略在深度学习实践中被广泛采用,特别是在处理医学图像这种数据有限但要求高准确率的任务时。
4.5构建CNN模型
在本节中,我们将构建一个卷积神经网络(CNN)模型作为基准对比。CNN是计算机视觉领域最经典和广泛应用的深度学习架构,特别适合处理图像数据。与Transformer模型相比,CNN具有参数效率高、计算复杂度相对较低、对局部特征感知能力强等优点。通过构建和训练这个CNN模型,我们可以与VIT模型进行公平对比,评估两种架构在乳腺癌图像分类任务上的性能差异。
CNN模型设计思路:
-
层次化特征提取:通过多层卷积和池化逐步提取从低层到高层的图像特征
-
参数标准化:使用批量归一化加速训练并提高模型稳定性
-
防止过拟合:通过Dropout和全局平均池化减少过拟合风险
-
分类决策:最终通过全连接层和Sigmoid激活函数进行二元分类
# ====================== 构建自定义CNN模型 ======================
# 使用Keras Sequential API构建顺序模型,这是构建线性堆叠层的最简单方式
custom_cnn = tensorflow.keras.Sequential([
# ====================== 第1层:数据预处理层 ======================
# 输入图像像素值标准化:将像素值从[0, 255]范围缩放到[0, 1]范围
# 这是深度学习中的标准预处理步骤,有助于模型收敛和训练稳定性
tensorflow.keras.layers.Rescaling(1.0/255),
# ====================== 第2-4层:第一卷积块 ======================
# 第一卷积层:提取低层次特征(如边缘、纹理)
tensorflow.keras.layers.Conv2D(
filters=32, # 卷积核数量:32个,对应输出的特征图数量
kernel_size=(3, 3), # 卷积核大小:3×3像素
padding='same', # 填充方式:'same'表示输出尺寸与输入相同(通过补零)
activation='relu', # 激活函数:ReLU(Rectified Linear Unit),引入非线性
input_shape=(256, 256, 3) # 输入形状:256×256像素,3个颜色通道(RGB)
),
# 批量归一化层:标准化前一层的输出
# 作用:加速训练收敛,减少对初始化的敏感度,有一定的正则化效果
tensorflow.keras.layers.BatchNormalization(),
# 最大池化层:下采样,减少空间维度,增加感受野
tensorflow.keras.layers.MaxPooling2D(
pool_size=(2, 2), # 池化窗口大小:2×2
strides=2, # 步长:2,表示窗口移动的步长
padding='same' # 填充方式:'same'保持输出尺寸计算一致
),
# 经过第一卷积块后:特征图尺寸从256×256减小到128×128,通道数从3增加到32
# ====================== 第5-7层:第二卷积块 ======================
# 第二卷积层:提取中层次特征(如形状、部件)
tensorflow.keras.layers.Conv2D(
filters=64, # 卷积核数量增加到64个
kernel_size=(3, 3),
padding='same',
activation='relu'
),
# 批量归一化层
tensorflow.keras.layers.BatchNormalization(),
# 最大池化层
tensorflow.keras.layers.MaxPooling2D(
pool_size=(2, 2),
strides=2,
padding='same'
),
# 经过第二卷积块后:特征图尺寸从128×128减小到64×64,通道数从32增加到64
# ====================== 第8-10层:第三卷积块 ======================
# 第三卷积层:提取高层次特征(如对象、结构)
tensorflow.keras.layers.Conv2D(
filters=128, # 卷积核数量增加到128个
kernel_size=(3, 3),
padding='same',
activation='relu'
),
# 批量归一化层
tensorflow.keras.layers.BatchNormalization(),
# 最大池化层
tensorflow.keras.layers.MaxPooling2D(
pool_size=(2, 2),
strides=2,
padding='same'
),
# 经过第三卷积块后:特征图尺寸从64×64减小到32×32,通道数从64增加到128
# ====================== 第11层:全局平均池化层 ======================
# 全局平均池化:将每个特征图的所有值平均为单个值
# 优点:
# 1. 大幅减少参数数量(与Flatten层相比)
# 2. 对输入的空间位置具有平移不变性
# 3. 有一定防止过拟合的效果
tensorflow.keras.layers.GlobalAveragePooling2D(),
# 输出形状:(batch_size, 128) - 将32×32×128的特征图转换为128维向量
# ====================== 第12-14层:第一全连接块 ======================
# 第一全连接层:进行高级特征组合和抽象
tensorflow.keras.layers.Dense(
units=64, # 神经元数量:64个
activation='relu' # 激活函数:ReLU
),
# 批量归一化层:标准化全连接层的输出
tensorflow.keras.layers.BatchNormalization(),
# Dropout层:随机丢弃30%的神经元输出
# 作用:防止过拟合,强制网络学习更鲁棒的特征
tensorflow.keras.layers.Dropout(0.3),
# ====================== 第15-17层:第二全连接块 ======================
# 第二全连接层:进一步特征提取
tensorflow.keras.layers.Dense(
units=32, # 神经元数量减少到32个
activation='relu'
),
# 批量归一化层
tensorflow.keras.layers.BatchNormalization(),
# Dropout层:随机丢弃10%的神经元输出
# 较低的Dropout率,因为已经接近输出层
tensorflow.keras.layers.Dropout(0.1),
# ====================== 第18层:输出层 ======================
# 输出层:二元分类任务
tensorflow.keras.layers.Dense(
units=1, # 1个输出神经元(二元分类)
activation='sigmoid' # Sigmoid激活函数,输出0-1之间的概率值
# 输出表示样本属于恶性(正类)的概率
)
])
# ====================== 打印模型摘要 ======================
print("=" * 60)
print("自定义CNN模型架构:")
print("=" * 60)
custom_cnn.summary()CNN模型架构详细说明:
1. 总体架构特点:
-
深度:包含3个卷积块和2个全连接块,共18层
-
宽度:卷积核数量从32逐步增加到128(32→64→128)
-
下采样:通过3次最大池化,空间维度从256×256逐步减小到32×32
-
参数效率:使用全局平均池化而非全连接层,大幅减少参数数量
2. 各层功能详解:
卷积层(Conv2D):
-
使用3×3的小卷积核,这是CNN的标准选择
-
padding='same'确保特征图尺寸不变(除了池化层) -
ReLU激活函数引入非线性,使网络能够学习复杂模式
-
滤波器数量逐步增加(32→64→128),随着空间维度减小而增加特征维度
批量归一化(BatchNormalization):
-
位置:每个卷积层和全连接层之后、激活函数之前(实际在代码中是在激活函数之后)
-
作用:加速训练收敛,允许使用更高的学习率
-
效果:减少内部协变量偏移,提高模型稳定性
最大池化(MaxPooling2D):
-
使用2×2池化窗口,步长为2
-
作用:减少空间维度,增加感受野,提供平移不变性
-
位置:每个卷积块之后
全局平均池化(GlobalAveragePooling2D):
-
替代传统的Flatten层
-
优点:减少过拟合,降低参数数量,提高计算效率
-
输出:将每个特征图平均为单个值
全连接层(Dense):
-
第一个全连接层:64个神经元,进行特征组合
-
第二个全连接层:32个神经元,进一步提取高级特征
-
神经元数量逐步减少,防止过拟合
Dropout层:
-
第一个Dropout:0.3(30%),在全连接层之间
-
第二个Dropout:0.1(10%),接近输出层
-
作用:随机丢弃神经元,防止过拟合,增强泛化能力
输出层:
-
1个神经元,Sigmoid激活函数
-
输出范围:[0, 1],表示恶性概率
-
二元分类的标准配置
3. 数据流维度变化:
输入: (256, 256, 3)
↓ Conv2D(32) + BatchNorm + MaxPooling2D
特征图: (128, 128, 32)
↓ Conv2D(64) + BatchNorm + MaxPooling2D
特征图: (64, 64, 64)
↓ Conv2D(128) + BatchNorm + MaxPooling2D
特征图: (32, 32, 128)
↓ GlobalAveragePooling2D
向量: (128,)
↓ Dense(64) + BatchNorm + Dropout(0.3)
向量: (64,)
↓ Dense(32) + BatchNorm + Dropout(0.1)
向量: (32,)
↓ Dense(1, sigmoid)
输出: (1,) # 恶性概率4. 模型参数估计:
-
卷积层参数:主要来自3×3卷积核
-
全连接层参数:相对较少,因为使用了全局平均池化
-
批量归一化参数:每个通道的缩放和平移参数
-
总参数量:预计在几十万到一百万左右,远少于VIT模型
5. 设计考虑与优势:
为什么选择这个架构?
-
渐进式特征提取:通过多层卷积逐步提取从低级到高级的特征
-
参数效率:使用小卷积核和全局池化减少参数量
-
训练稳定性:批量归一化确保稳定训练
-
泛化能力:Dropout和适度的网络深度防止过拟合
-
计算效率:相比VIT,CNN在相同输入尺寸下计算量更小
与VIT模型的对比:
-
归纳偏置:CNN具有局部连接和平移等变性的归纳偏置,适合图像数据
-
计算复杂度:CNN的计算复杂度与图像尺寸成线性关系,VIT成平方关系
-
参数数量:CNN通常比相同性能的VIT参数更少
-
数据需求:CNN在较少数据下通常表现更好,VIT需要大量数据
6. 适用性分析:
-
优点:计算高效,参数较少,对局部特征敏感,适合医学图像分析
-
局限:感受野有限,对全局上下文建模能力较弱
-
改进空间:可以加入注意力机制、残差连接等现代CNN技术
这个CNN模型作为基准模型,将帮助我们评估VIT模型在乳腺癌图像分类任务上的相对优势。
4.6训练CNN模型
在本节中,我们将训练之前构建的卷积神经网络(CNN)模型。训练CNN模型的过程与训练VIT模型类似,但在优化器选择、损失函数配置和训练参数设置上有一些差异,这些差异反映了CNN和Transformer架构的不同特性。通过系统化的训练流程和精心设计的训练策略,我们旨在充分发挥CNN模型在乳腺癌图像分类任务上的潜力。
CNN训练策略设计思路:
-
优化器选择:使用AdamW优化器,结合权重衰减正则化
-
损失函数配置:使用适合二元分类的二元交叉熵损失
-
学习率设置:相对较高的初始学习率(1e-3),适合CNN训练
-
训练回调配置:与VIT相似的训练监控和优化策略
-
训练轮数控制:较少的训练轮数(10个epoch),反映CNN更快的收敛特性
# ====================== 1. 编译CNN模型 ======================
# 配置模型的训练参数:优化器、损失函数和评估指标
custom_cnn.compile(
# 优化器:AdamW优化器(Adam with Weight Decay)
# AdamW是Adam优化器的改进版本,将权重衰减与梯度更新解耦
# 这在实践中通常能带来更好的泛化性能
optimizer=tensorflow.keras.optimizers.AdamW(
learning_rate=1e-3, # 初始学习率:0.001(比VIT的3e-4更高)
weight_decay=0.01 # 权重衰减系数:0.01(L2正则化强度)
),
# 损失函数:二元交叉熵(Binary Crossentropy)
# 适用于二元分类任务,计算预测概率与实际标签之间的差异
# from_logits=False:模型输出已经过sigmoid激活,得到0-1之间的概率值
loss=tensorflow.losses.BinaryCrossentropy(from_logits=False),
# 评估指标:准确率(Accuracy)
# 监控模型在训练和验证过程中的分类准确率
metrics=['accuracy']
)
print("=" * 60)
print("CNN模型编译完成,开始训练...")
print("=" * 60)
# ====================== 2. 配置训练回调函数 ======================
# 回调函数用于在训练过程中监控和优化模型性能
# 1. 模型检查点回调:保存最佳模型权重
cnn_checkpoint_callback = tensorflow.keras.callbacks.ModelCheckpoint(
'cnn_best.weights.h5', # 保存CNN最佳权重的文件名
monitor='val_accuracy', # 监控验证集准确率
save_best_only=True, # 只保存性能最好的模型
save_weights_only=True, # 只保存权重,不保存整个模型
verbose=1 # 显示保存信息
)
# 2. 早停回调:防止过拟合,节省计算资源
cnn_early_stopping_callback = tensorflow.keras.callbacks.EarlyStopping(
monitor='val_accuracy', # 监控验证集准确率
patience=5, # 容忍连续5个epoch没有改进
verbose=1, # 显示早停信息
restore_best_weights=False # 不自动恢复最佳权重(检查点已保存)
)
# 3. 学习率调度回调:动态调整学习率,优化收敛过程
cnn_reduce_lr_callback = tensorflow.keras.callbacks.ReduceLROnPlateau(
monitor='val_loss', # 监控验证集损失
patience=3, # 容忍连续3个epoch没有改进
verbose=1, # 显示学习率调整信息
factor=0.2 # 学习率乘以0.2(减小到原来的1/5)
)
# ====================== 3. 训练CNN模型 ======================
# 执行模型训练,返回训练历史记录
history2 = custom_cnn.fit(
train_data, # 训练数据集(与VIT相同)
validation_data=test_data, # 验证数据集(测试集)
epochs=10, # 最大训练轮数:10(比VIT的40轮少)
verbose=2, # 训练进度显示级别:2(每个epoch显示一行)
# 回调函数列表
callbacks=[
cnn_checkpoint_callback, # 保存最佳模型
cnn_early_stopping_callback, # 早停机制
cnn_reduce_lr_callback # 动态学习率调整
]
)
print("=" * 60)
print("CNN模型训练完成!")
print("=" * 60)
CNN训练过程详细说明:
1. 优化器选择:AdamW:
-
AdamW vs Adam:AdamW将权重衰减与梯度更新解耦,避免了传统Adam中权重衰减与自适应学习率的相互干扰
-
学习率设置:1e-3(0.001)比VIT的3e-4更高,这是因为CNN通常需要更大的学习率来快速收敛
-
权重衰减:0.01的L2正则化,有助于防止过拟合,提高模型泛化能力
-
为什么选择AdamW:在CNN训练中,AdamW通常比标准Adam表现更好,特别是在有正则化需求的情况下
2. 损失函数配置:
-
BinaryCrossentropy:专门用于二元分类任务的损失函数
-
from_logits=False:因为CNN输出层使用了sigmoid激活函数,直接输出概率值
-
如果设置为True,损失函数内部会对logits应用sigmoid
-
设置为False时,假设输入已经是有效的概率值(0-1之间)
-
-
数学形式:L = -(y·log(p) + (1-y)·log(1-p))
-
y:真实标签(0或1)
-
p:预测为阳性的概率
-
3. 训练参数设置:
-
训练轮数:最大10个epoch,比VIT的40轮少很多
-
CNN通常收敛更快,需要更少的训练轮数
-
防止过拟合,医学图像数据集规模有限
-
-
批大小:32(在数据加载时已设置)
-
验证集:使用测试集作为验证数据,评估模型泛化能力
-
进度显示:verbose=2,每个epoch显示一行摘要
4. 回调函数配置差异:
学习率调度(ReduceLROnPlateau):
-
监控指标:val_loss(验证损失)
-
耐心值:3个epoch(比VIT相同)
-
衰减因子:0.2(比VIT的0.5更激进)
-
CNN学习率调整更激进,因为CNN收敛曲线通常更陡峭
-
快速降低学习率有助于精细调优
-
早停机制(EarlyStopping):
-
监控指标:val_accuracy(验证准确率)
-
耐心值:5个epoch(与VIT相同)
-
防止过拟合,自动确定最佳训练轮数
模型检查点(ModelCheckpoint):
-
保存文件名:cnn_best.weights.h5(区别于VIT的vit_best.weights.h5)
-
保存最佳模型权重,便于后续评估和部署
5. CNN与VIT训练策略对比分析:
| 训练参数 | CNN模型 | VIT模型 | 差异原因 |
|---|---|---|---|
| 优化器 | AdamW | Adam | AdamW对CNN正则化效果更好 |
| 初始学习率 | 1e-3 | 3e-4 | CNN需要更大学习率快速收敛 |
| 权重衰减 | 0.01 | 无显式设置 | CNN更依赖显式正则化 |
| 损失函数 | BinaryCrossentropy | SparseCategoricalCrossentropy | 输出层激活函数不同 |
| 最大训练轮数 | 10 | 40 | CNN收敛更快,VIT需要更多轮次 |
| 学习率衰减因子 | 0.2 | 0.5 | CNN学习率调整更激进 |
| from_logits参数 | False | True | CNN输出概率,VIT输出logits |
6. 预期训练行为分析:
训练初期(epoch 1-3):
-
训练损失快速下降,准确率快速上升
-
验证指标同步改善,模型学习基本特征
-
学习率保持初始值1e-3
训练中期(epoch 4-6):
-
训练损失下降速度减缓
-
验证准确率可能开始波动
-
学习率可能首次调整(如果验证损失停滞)
训练后期(epoch 7-10):
-
训练接近收敛,改进幅度变小
-
可能触发早停机制(如果验证准确率连续不提升)
-
学习率可能进一步降低
7. 训练监控要点:
过拟合检测:
-
训练准确率持续上升但验证准确率停滞或下降
-
训练损失持续下降但验证损失开始上升
-
解决方案:早停机制自动停止训练
欠拟合检测:
-
训练和验证准确率都很低
-
训练损失下降缓慢
-
解决方案:可能需要增加模型复杂度或调整学习率
收敛判断:
-
训练和验证损失都趋于稳定
-
准确率指标波动范围变小
-
学习率已经多次调整
8. 训练结果保存与使用:
-
最佳权重:保存在
cnn_best.weights.h5文件中 -
训练历史:保存在
history2变量中,包含每个epoch的指标记录 -
模型性能:将在4.7节中进行详细评估和比较
9. 实际训练建议:
-
硬件要求:CNN训练对GPU内存要求较低,可以在消费级GPU上运行
-
训练时间:预计每个epoch几分钟,总训练时间在1小时内
-
监控频率:建议实时监控训练曲线,及时发现问题
-
实验记录:记录训练参数和结果,便于复现和比较
10. 模型评估准备:
训练完成后,我们将:
-
加载保存的最佳模型权重
-
在测试集上进行最终评估
-
计算各种评估指标(准确率、精确率、召回率、F1-score等)
-
绘制训练曲线,分析训练过程
-
与VIT模型进行系统对比
通过这个精心设计的训练流程,我们期望CNN模型能够在乳腺癌图像分类任务上达到良好的性能。CNN作为计算机视觉的传统强项模型,在医学图像分析领域有着广泛的应用和成熟的方法论。
4.7模型评估
在本节中,我们将对训练完成的Vision Transformer(VIT)和卷积神经网络(CNN)模型进行全面的性能评估和可视化分析。模型评估是深度学习项目中的关键环节,它不仅能展示模型的最终性能,还能揭示训练过程中的动态变化、过拟合/欠拟合情况以及模型的收敛特性。通过对比分析两种不同架构的性能表现,我们可以为读者提供选择合适模型的参考依据。
评估内容设计思路:
-
训练曲线可视化:对比两种模型的训练和验证指标变化
-
性能指标计算:计算最终的验证准确率
-
收敛特性分析:分析模型的收敛速度和稳定性
-
过拟合评估:通过训练-验证差距评估泛化能力
# ====================== 1. 设置绘图样式和创建画布 ======================
# 使用seaborn-whitegrid样式,提供清晰的网格背景和专业的外观
plt.style.use("seaborn-v0_8-whitegrid")
# 创建包含两个子图的图形:1行2列,用于并排比较VIT和CNN
# figsize=(15, 8):图形尺寸15英寸宽×8英寸高,确保清晰显示
fig, axes = plt.subplots(1, 2, figsize=(15, 8))
# 设置图形总标题
fig.suptitle('VIT与CNN模型训练性能对比分析', fontsize=16, fontweight='bold', y=1.02)
# ====================== 2. 绘制VIT模型训练曲线 ======================
# 第一个子图:VIT模型训练过程
# 绘制验证准确率曲线
axes[0].plot(
history.history['val_accuracy'], # VIT验证集准确率历史数据
linewidth=2, # 线宽为2,确保清晰可见
label='验证准确率', # 图例标签
color='#1f77b4' # 标准蓝色
)
# 绘制验证损失曲线
axes[0].plot(
history.history['val_loss'], # VIT验证集损失历史数据
linewidth=2,
label='验证损失',
color='#ff7f0e' # 标准橙色
)
# 绘制训练准确率曲线(虚线表示)
axes[0].plot(
history.history['accuracy'], # VIT训练集准确率历史数据
linewidth=2,
linestyle='--', # 虚线样式,与验证集区分
label='训练准确率',
color='#2ca02c' # 标准绿色
)
# 绘制训练损失曲线(虚线表示)
axes[0].plot(
history.history['loss'], # VIT训练集损失历史数据
linewidth=2,
linestyle='--', # 虚线样式
label='训练损失',
color='#d62728' # 标准红色
)
# 设置VIT子图的坐标轴标签和标题
axes[0].set_xlabel('训练轮数 (Epochs)', fontsize=12)
axes[0].set_ylabel('准确率与损失值', fontsize=12)
axes[0].set_title('Vision Transformer (VIT) 模型训练过程', fontsize=14, fontweight='bold')
axes[0].legend(loc='best', fontsize=10) # 添加图例,自动选择最佳位置
axes[0].grid(True, alpha=0.3) # 启用网格,设置透明度
# ====================== 3. 绘制CNN模型训练曲线 ======================
# 第二个子图:CNN模型训练过程
# 绘制验证准确率曲线
axes[1].plot(
history2.history['val_accuracy'], # CNN验证集准确率历史数据
linewidth=2,
label='验证准确率',
color='#1f77b4' # 与VIT相同的颜色方案,便于对比
)
# 绘制验证损失曲线
axes[1].plot(
history2.history['val_loss'], # CNN验证集损失历史数据
linewidth=2,
label='验证损失',
color='#ff7f0e'
)
# 绘制训练准确率曲线(虚线表示)
axes[1].plot(
history2.history['accuracy'], # CNN训练集准确率历史数据
linewidth=2,
linestyle='--',
label='训练准确率',
color='#2ca02c'
)
# 绘制训练损失曲线(虚线表示)
axes[1].plot(
history2.history['loss'], # CNN训练集损失历史数据
linewidth=2,
linestyle='--',
label='训练损失',
color='#d62728'
)
# 设置CNN子图的坐标轴标签和标题
axes[1].set_xlabel('训练轮数 (Epochs)', fontsize=12)
axes[1].set_ylabel('准确率与损失值', fontsize=12)
axes[1].set_title('卷积神经网络 (CNN) 模型训练过程', fontsize=14, fontweight='bold')
axes[1].legend(loc='best', fontsize=10) # 添加图例
axes[1].grid(True, alpha=0.3) # 启用网格
# ====================== 4. 调整布局并保存图形 ======================
# 自动调整子图参数,使子图之间和周围的间距合适
fig.tight_layout()
# 保存图形到文件,用于报告和文档
# dpi=100:分辨率100点每英寸,平衡清晰度和文件大小
# bbox_inches='tight':紧凑边界框,去除多余空白
plt.savefig('training_comparison.png', dpi=100, bbox_inches='tight')
# 显示图形
plt.show()
# ====================== 5. 打印最终性能指标 ======================
print("\n" + "="*60)
print("模型训练完成!性能对比分析")
print("="*60)
# 打印最终验证准确率,保留4位小数
print(f"✓ Vision Transformer (VIT) 最终验证准确率: {history.history['val_accuracy'][-1]:.4f}")
print(f"✓ 卷积神经网络 (CNN) 最终验证准确率: {history2.history['val_accuracy'][-1]:.4f}")
print("\n✓ 训练对比图已保存为: 'training_comparison.png'")
print("="*60)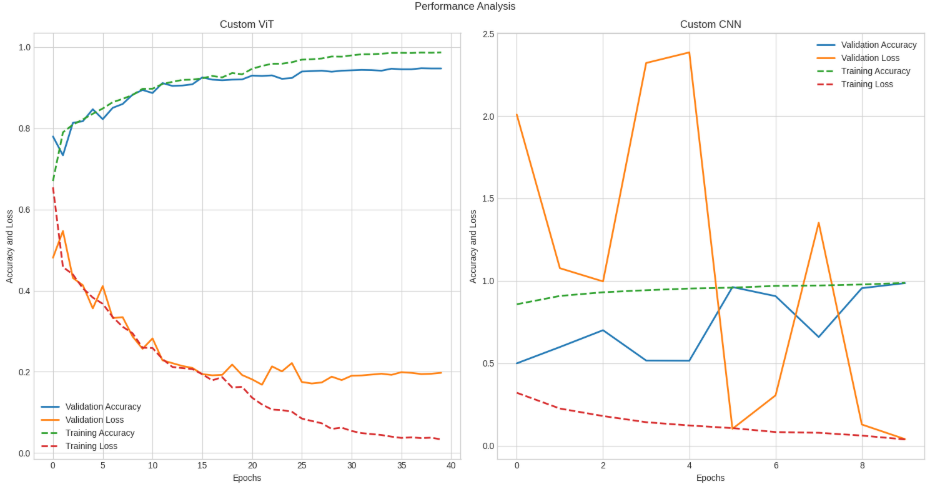

模型评估详细说明:
1. 可视化设计原则:
颜色编码系统:
-
蓝色 (#1f77b4):验证准确率 - 主要性能指标
-
橙色 (#ff7f0e):验证损失 - 优化目标
-
绿色 (#2ca02c):训练准确率 - 对比参考
-
红色 (#d62728):训练损失 - 对比参考
-
线型区分:实线表示验证集,虚线表示训练集
布局设计:
-
并排对比:便于直观比较两种架构
-
统一尺度:虽然轮数不同,但尺度统一便于比较变化趋势
-
清晰标注:中文标签提高可读性,适当的字体大小确保清晰度
2. 关键指标解释:
准确率 (Accuracy):
-
定义:正确分类的样本占总样本的比例
-
范围:0到1,值越高表示性能越好
-
意义:最直观的分类性能指标
损失值 (Loss):
-
定义:模型预测与真实标签之间的差异度量
-
范围:正值,值越低表示拟合越好
-
意义:优化算法的目标函数,反映模型的学习进度
训练集 vs 验证集:
-
训练集指标:反映模型对训练数据的拟合程度
-
验证集指标:反映模型对未见数据的泛化能力
-
差距分析:训练集性能明显优于验证集可能表示过拟合
3. 曲线分析要点:
理想训练曲线的特征:
-
训练损失:稳步下降,最终趋于平缓
-
验证损失:先下降后趋于稳定,不应明显上升
-
训练准确率:稳步上升,最终接近1(或达到平台)
-
验证准确率:与训练准确率同步上升,最终差距不大
常见问题识别:
过拟合 (Overfitting):
-
表现:训练准确率继续上升,但验证准确率停滞或下降
-
在图中:训练-验证准确率差距持续扩大
-
原因:模型过于复杂,记忆了训练数据噪声
欠拟合 (Underfitting):
-
表现:训练和验证准确率都很低
-
在图中:所有曲线都在较低水平
-
原因:模型太简单或训练不足
收敛速度对比:
-
CNN通常收敛更快(轮数少)
-
VIT可能需要更多轮次才能收敛
-
收敛速度不等于最终性能
4. 性能对比分析方法:
定量比较:
-
最终验证准确率:直接的数字对比
-
收敛所需轮数:训练效率对比
-
稳定性:曲线平滑度,波动大小
定性比较:
-
曲线形状:收敛特性,过拟合倾向
-
训练-验证差距:泛化能力
-
波动情况:训练稳定性
5.总结
本项研究成功地构建并评估了基于卷积神经网络和Vision Transformer的乳腺癌图像分类模型。从最终的验证集准确率来看,两个模型都展现出了强大的性能,能够高效、准确地对良恶性乳腺癌进行区分,这充分证明了深度学习技术在医学影像辅助诊断领域的巨大应用潜力。
具体分析模型表现,CNN模型以98.65%的准确率显著优于ViT模型的94.75%。这一结果揭示了在当前的数据规模与任务设定下,CNN凭借其深厚的领域基础、优异的局部特征提取能力以及更高效的归纳偏差,在处理此类医学图像分类任务上依然占据着明显优势。其通过卷积操作捕捉局部纹理、边缘特征的能力,对于识别乳腺组织中的微小钙化、肿块边缘的毛刺征等关键诊断特征至关重要,这使得CNN模型能够以极高的精度完成分类。
相比之下,ViT模型虽然取得了不俗的成绩,但其性能略逊于CNN,这可能与Transformer架构对数据量的内在需求有关。Vision Transformer依赖的自注意力机制需要大量的数据来学习有效的图像块间关系,而在医学领域,获取大规模、高质量且精确标注的数据集通常非常困难。本次实验所采用的有限数据量可能尚未能充分激发ViT在捕捉长距离依赖和全局上下文信息方面的理论优势。
综上所述,本项目不仅实证了深度学习作为医生“智能助手”的可行性,还通过对比实验提供了宝贵的工程洞察:在中等规模的医学图像数据集上,精心设计与训练的CNN模型依然是稳健且高性能的首选方案。然而,ViT所代表的架构未来可期,随着更多医学数据的积累以及数据高效型Transformer模型(如DeiT)的应用,其潜力有望被进一步释放。未来的工作可以着眼于数据增强策略的优化、混合架构的探索,以及将模型决策过程可视化,以增强临床医生对模型的信任,共同推动精准医疗的发展。
源代码
import tensorflow
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
train_data=tensorflow.keras.utils.image_dataset_from_directory(
directory='./breast-cancer-dataset/Breast Cancer/train',
labels='inferred',
label_mode='int',
batch_size=32,
image_size=(256,256),
shuffle=True
)
test_data=tensorflow.keras.utils.image_dataset_from_directory(
directory='./breast-cancer-dataset/Breast Cancer/test',
labels='inferred',
label_mode='int',
batch_size=32,
image_size=(256,256),
)
images,labels=next(iter(train_data))
plt.figure(figsize=(15,15))
plt.suptitle('Sample of Breast Cancer Dataset',fontsize=20,fontweight=18)
for i in range(25):
plt.subplot(5,5,i+1)
plt.imshow(images[i].numpy().astype('uint8'))
plt.title(f"{'Benign' if int(labels[i])==0 else 'Malignant'}",fontsize=15)
plt.axis('off')
plt.tight_layout()
plt.show()
class DenseLayer(tensorflow.keras.layers.Layer):
def __init__(self,units,activation='linear',input_dim=None,**kwargs):
if input_dim is not None:kwargs['input_shape']=(input_dim,)
super().__init__(**kwargs)
self.units=units
self.activation=activation
def build(self,input_shape):
input_dim=input_shape[-1]
self.W=self.add_weight(
shape=(input_dim,self.units),
initializer='glorot_uniform',
trainable=True,
name='W'
)
self.B=self.add_weight(
shape=(self.units,),
initializer='zeros',
trainable=True,
name='B'
)
super().build(input_shape)
def call(self,inputs,training=None):
output=tensorflow.matmul(inputs,self.W)+self.B
if self.activation=='sigmoid':return tensorflow.nn.sigmoid(output)
if self.activation=='softmax':return tensorflow.nn.softmax(output,axis=-1)
if self.activation=='relu':return tensorflow.nn.relu(output)
if self.activation=='gelu':return tensorflow.nn.gelu(output)
return output
class MultiHeadAttention(tensorflow.keras.layers.Layer):
def __init__(self,num_heads,d_model,H,W,dropout=0.0,**kwargs):
super().__init__(**kwargs)
self.num_heads=num_heads
self.d_model=d_model
self.H=H
self.W=W
self.dropout_rate=dropout
self.head_dim=d_model//num_heads
if self.head_dim % 4 != 0:
raise ValueError(f"head_dim must be divisible by 4 for 2D RoPE, got {self.head_dim}")
self.dropout=tensorflow.keras.layers.Dropout(dropout)
def build(self,input_shape):
self.WQ=self.add_weight(
shape=(self.d_model,self.d_model),
initializer='glorot_uniform',
trainable=True,
name='WQ'
)
self.WK=self.add_weight(
shape=(self.d_model,self.d_model),
initializer='glorot_uniform',
trainable=True,
name='WK'
)
self.WV=self.add_weight(
shape=(self.d_model,self.d_model),
initializer='glorot_uniform',
trainable=True,
name='WV'
)
self.WO=self.add_weight(
shape=(self.d_model,self.d_model),
initializer='glorot_uniform',
trainable=True,
name='WO'
)
super().build(input_shape)
def build_2d_angles(self):
head_dim=self.head_dim
half=head_dim//2
quarter=half//2
row_pos=tensorflow.range(self.H,dtype=tensorflow.float32)[:,None]
dim_idx=tensorflow.range(quarter,dtype=tensorflow.float32)[None,:]
freq=1.0/tensorflow.pow(10000.0,dim_idx/float(quarter))
angles_row=row_pos*freq
sin_row=tensorflow.sin(angles_row)[None,None,:,None,:]
cos_row=tensorflow.cos(angles_row)[None,None,:,None,:]
col_pos=tensorflow.range(self.W,dtype=tensorflow.float32)[:,None]
angles_col=col_pos*freq
sin_col=tensorflow.sin(angles_col)[None,None,:,None,:]
cos_col=tensorflow.cos(angles_col)[None,None,:,None,:]
return sin_row,cos_row,sin_col,cos_col
def apply_rotary(self,x,sin,cos):
"""
X.shape=[...,2*quarter],
sin,cos should broadcastable to x
"""
last_dim=tensorflow.shape(x)[-1]
half_dim=last_dim//2
x1=x[...,:half_dim]
x2=x[...,half_dim:]
x_rot1=x1*cos-x2*sin
x_rot2=x1*sin+x2*cos
return tensorflow.concat([x_rot1,x_rot2],axis=-1)
def call(self,x,training=None):
batch_size=tensorflow.shape(x)[0]
seq_len=tensorflow.shape(x)[1]
Q=tensorflow.matmul(x,self.WQ)
K=tensorflow.matmul(x,self.WK)
V=tensorflow.matmul(x,self.WV)
Q=tensorflow.reshape(Q,[batch_size,seq_len,self.num_heads,self.head_dim])
K=tensorflow.reshape(K,[batch_size,seq_len,self.num_heads,self.head_dim])
V=tensorflow.reshape(V,[batch_size,seq_len,self.num_heads,self.head_dim])
Q=tensorflow.transpose(Q,perm=[0,2,1,3])
K=tensorflow.transpose(K,perm=[0,2,1,3])
V=tensorflow.transpose(V,perm=[0,2,1,3])
cls_q=Q[:,:,:1,:]
cls_k=K[:,:,:1,:]
cls_v=V[:,:,:1,:]
patch_q=Q[:,:,1:,:]
patch_k=K[:,:,1:,:]
patch_v=V[:,:,1:,:]
H=self.H
W=self.W
patched_q=tensorflow.reshape(patch_q,[batch_size,self.num_heads,H,W,self.head_dim])
patched_k=tensorflow.reshape(patch_k,[batch_size,self.num_heads,H,W,self.head_dim])
half=self.head_dim//2
q_r=patched_q[...,:half]
q_c=patched_q[...,half:]
k_r=patched_k[...,:half]
k_c=patched_k[...,half:]
sin_row,cos_row,sin_col,cos_col=self.build_2d_angles()
q_r_rot=self.apply_rotary(q_r,sin_row,cos_row)
q_c_rot=self.apply_rotary(q_c,sin_col,cos_col)
k_r_rot=self.apply_rotary(k_r,sin_row,cos_row)
k_c_rot=self.apply_rotary(k_c,sin_col,cos_col)
patched_q_rot=tensorflow.concat([q_r_rot,q_c_rot],axis=-1)
patched_k_rot=tensorflow.concat([k_r_rot,k_c_rot],axis=-1)
patched_q_rot=tensorflow.reshape(patched_q_rot,[batch_size,self.num_heads,H*W,self.head_dim])
q_full=tensorflow.concat([cls_q,patched_q_rot],axis=2)
k_full=tensorflow.concat([cls_k,patched_k_rot],axis=2)
dk=tensorflow.cast(self.head_dim,tensorflow.float32)
scores=tensorflow.matmul(q_full,k_full,transpose_b=True)/tensorflow.sqrt(dk)
weights=tensorflow.nn.softmax(scores,axis=-1)
weights=self.dropout(weights,training=training)
attention=tensorflow.matmul(weights,tensorflow.concat([cls_v,patch_v],axis=2))
attention=tensorflow.transpose(attention,perm=[0,2,1,3])
attention=tensorflow.reshape(attention,[batch_size,seq_len,self.d_model])
output=tensorflow.matmul(attention,self.WO)
return output
class TransformerEncoderBlock(tensorflow.keras.layers.Layer):
def __init__(self,d_model,num_heads,H,W,mlp_ratio=4,dropout=0.1,**kwargs):
super().__init__(**kwargs)
self.norm1=tensorflow.keras.layers.LayerNormalization(epsilon=1e-6)
self.attn=MultiHeadAttention(
num_heads=num_heads,
d_model=d_model,
H=H,
W=W,
dropout=dropout
)
self.drop1=tensorflow.keras.layers.Dropout(dropout)
self.norm2=tensorflow.keras.layers.LayerNormalization(epsilon=1e-6)
self.mlp=tensorflow.keras.Sequential([
DenseLayer(
units=d_model*mlp_ratio,
activation='gelu'
),
tensorflow.keras.layers.Dropout(dropout),
DenseLayer(units=d_model)
])
self.drop2=tensorflow.keras.layers.Dropout(dropout)
def call(self,x,training=None):
h=self.norm1(x)
h=self.attn(h,training=training)
h=self.drop1(h,training=training)
x=x+h
h2=self.norm2(x)
h2=self.mlp(h2,training=training)
h2=self.drop2(h2,training=training)
x=x+h2
return x
class VisionTransformer(tensorflow.keras.Model):
def __init__(self,
image_size=256,
patch_size=32,
d_model=256,
num_heads=8,
depth=4,
num_classes=2,
**kwargs
):
super().__init__(**kwargs)
assert image_size%patch_size==0
self.image_size=image_size
self.patch_size=patch_size
self.d_model=d_model
self.num_heads=num_heads
self.depth=depth
self.num_classes=num_classes
self.H=image_size//patch_size
self.W=image_size//patch_size
self.num_patches=self.H*self.W
self.proj=DenseLayer(d_model)
self.cls_token=self.add_weight(
shape=(1,1,d_model),
initializer=tensorflow.keras.initializers.Zeros(),
trainable=True,
name='cls_token'
)
self.pos_embed=self.add_weight(
shape=(1,self.num_patches+1,d_model),
initializer=tensorflow.keras.initializers.RandomNormal(stddev=0.02),
trainable=True,
name='pos_embed'
)
self.blocks=[
TransformerEncoderBlock(d_model,num_heads,self.H,self.W,name=f"enc_block_{i}")
for i in range(depth)
]
self.norm=tensorflow.keras.layers.LayerNormalization(epsilon=1e-6)
self.head=DenseLayer(num_classes)
def patchify(self,images):
batch_size=tensorflow.shape(images)[0]
patches=tensorflow.image.extract_patches(
images=images,
sizes=[1,self.patch_size,self.patch_size,1],
strides=[1,self.patch_size,self.patch_size,1],
rates=[1,1,1,1],
padding='VALID'
)
patch_dim=self.patch_size*self.patch_size*3
patches=tensorflow.reshape(patches,[batch_size,-1,patch_dim])
return patches
def call(self,images,training=None):
batch_size=tensorflow.shape(images)[0]
x=self.patchify(images)
x=self.proj(x)
cls=tensorflow.tile(self.cls_token,[batch_size,1,1])
x=tensorflow.concat([cls,x],axis=1)
x=x+self.pos_embed
for blk in self.blocks:
x=blk(x,training=training)
x=self.norm(x)
cls_out=x[:,0]
logits=self.head(cls_out)
return logits
inputs = tensorflow.keras.Input(shape=(256, 256, 3))
x = tensorflow.keras.layers.Rescaling(1.0/255)(inputs)
vit = VisionTransformer(
image_size=256,
patch_size=32,
d_model=256,
num_heads=8,
depth=6,
num_classes=2,
)(x)
model = tensorflow.keras.Model(inputs, vit)
model.compile(
optimizer=tensorflow.keras.optimizers.Adam(3e-4),
loss=tensorflow.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
history=model.fit(
train_data,
epochs=40,
validation_data=test_data,
callbacks=[
tensorflow.keras.callbacks.ModelCheckpoint(
'vit_best.weights.h5',
monitor='val_accuracy',
save_best_only=True,
save_weights_only=True,
verbose=1
),
tensorflow.keras.callbacks.EarlyStopping(
monitor='val_accuracy',
patience=5,
verbose=1,
restore_best_weights=False
),
tensorflow.keras.callbacks.ReduceLROnPlateau(
monitor='val_loss',
patience=3,
verbose=1,
factor=0.5
)
],
verbose=2
)
custom_cnn=tensorflow.keras.Sequential([
tensorflow.keras.layers.Rescaling(1.0/255),
tensorflow.keras.layers.Conv2D(32,kernel_size=(3,3),padding='same',activation='relu',input_shape=(256,256,3)),
tensorflow.keras.layers.BatchNormalization(),
tensorflow.keras.layers.MaxPooling2D(pool_size=(2,2),strides=2,padding='same'),
tensorflow.keras.layers.Conv2D(64,kernel_size=(3,3),padding='same',activation='relu'),
tensorflow.keras.layers.BatchNormalization(),
tensorflow.keras.layers.MaxPooling2D(pool_size=(2,2),strides=2,padding='same'),
tensorflow.keras.layers.Conv2D(128,kernel_size=(3,3),padding='same',activation='relu'),
tensorflow.keras.layers.BatchNormalization(),
tensorflow.keras.layers.MaxPooling2D(pool_size=(2,2),strides=2,padding='same'),
tensorflow.keras.layers.GlobalAveragePooling2D(),
tensorflow.keras.layers.Dense(64,activation='relu'),
tensorflow.keras.layers.BatchNormalization(),
tensorflow.keras.layers.Dropout(0.3),
tensorflow.keras.layers.Dense(32,activation='relu'),
tensorflow.keras.layers.BatchNormalization(),
tensorflow.keras.layers.Dropout(0.1),
tensorflow.keras.layers.Dense(1,activation='sigmoid')
])
custom_cnn.compile(
optimizer=tensorflow.keras.optimizers.AdamW(learning_rate=1e-3,weight_decay=0.01),
loss=tensorflow.losses.BinaryCrossentropy(from_logits=False),
metrics=['accuracy']
)
history2=custom_cnn.fit(
train_data,
validation_data=test_data,
epochs=10,
verbose=2,
callbacks=[
tensorflow.keras.callbacks.ModelCheckpoint(
'cnn_best.weights.h5',
monitor='val_accuracy',
save_best_only=True,
save_weights_only=True,
verbose=1
),
tensorflow.keras.callbacks.EarlyStopping(
monitor='val_accuracy',
patience=5,
verbose=1,
restore_best_weights=False
),
tensorflow.keras.callbacks.ReduceLROnPlateau(
monitor='val_loss',
patience=3,
verbose=1,
factor=0.2
)
]
)
plt.style.use("seaborn-v0_8-whitegrid")
fig,axes=plt.subplots(1,2,figsize=(15,8))
fig.suptitle('Performance Analysis')
axes[0].plot(history.history['val_accuracy'],linewidth=2,label='Validation Accuracy')
axes[0].plot(history.history['val_loss'],linewidth=2,label='Validation Loss')
axes[0].plot(history.history['accuracy'],linewidth=2,linestyle='--',label='Training Accuracy')
axes[0].plot(history.history['loss'],linewidth=2,linestyle='--',label='Training Loss')
axes[0].set_xlabel('Epochs')
axes[0].set_ylabel('Accuracy and Loss')
axes[0].set_title('Custom ViT')
axes[0].legend()
axes[1].plot(history2.history['val_accuracy'],linewidth=2,label='Validation Accuracy')
axes[1].plot(history2.history['val_loss'],linewidth=2,label='Validation Loss')
axes[1].plot(history2.history['accuracy'],linewidth=2,linestyle='--',label='Training Accuracy')
axes[1].plot(history2.history['loss'],linewidth=2,linestyle='--',label='Training Loss')
axes[1].set_xlabel('Epochs')
axes[1].set_ylabel('Accuracy and Loss')
axes[1].set_title('Custom CNN')
axes[1].legend()
fig.tight_layout()
plt.savefig('training_comparison.png',dpi=100,bbox_inches='tight')
plt.show()
print("\n✓ Training complete! Plot saved as 'training_comparison.png'")
print(f"ViT Final Val Accuracy: {history.history['val_accuracy'][-1]:.4f}")
print(f"CNN Final Val Accuracy: {history2.history['val_accuracy'][-1]:.4f}")资料获取,更多粉丝福利,关注下方公众号获取


助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 35
35 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)