Starrocks 简介
Starrocks 是新一代极速全场景 MPP 数据库。StarRocks 采用分布式架构,对数据表进行水平划分并以多副本存储。集群规模可以灵活伸缩,能够支持 10PB 级别的数据分析;支持 MPP 框架,并行加速计算;支持多副本,具有弹性容错能力。StarRocks 采用关系模型,使用严格的数据类型和列式存储引擎,通过编码和压缩技术,降低读写放大;使用向量化执行方式,充分挖掘多核 CPU 的并行
一、定义
Starrocks 是新一代极速全场景 MPP 数据库。StarRocks 采用分布式架构,对数据表进行水平划分并以多副本存储。集群规模可以灵活伸缩,能够支持 10PB 级别的数据分析; 支持 MPP 框架,并行加速计算; 支持多副本,具有弹性容错能力。
StarRocks 采用关系模型,使用严格的数据类型和列式存储引擎,通过编码和压缩技术,降低读写放大;使用向量化执行方式,充分挖掘多核 CPU 的并行计算能力,从而显著提升查询性能。
二、适用场景
StarRocks 可以满足企业级用户的多种分析需求,包括 OLAP 多维分析、定制报表、实时数据分析和 Ad-hoc 数据分析等。具体的业务场景包括:
- OLAP 多维分析:用户行为分析、用户画像、财务报表、系统监控分析;
- 实时数据分析:电商数据分析、直播质量分析、物流运单分析、广告投放分析;
- 高并发查询:广告主表分析、Dashbroad 多页面分析;
- 统一分析:通过使用一套系统解决上述场景,降低系统复杂度和多技术栈开发成本;
三、基本概念
- FE:FrontEnd 简称 FE,是 StarRocks 的前端节点,负责管理元数据,管理客户端连接,进行查询规划,查询调度等工作;
- BE:BackEnd 简称 BE,是 StarRocks 的后端节点,负责数据存储,计算执行,以及 compaction,副本管理等工作;
- Broker:StarRocks 中和外部 HDFS / 对象存储等外部数据对接的中转服务,辅助提供导入导出功能;
- StarRocksManager:StarRocks 的管理工具,提供 StarRocks 集群管理、在线查询、故障查询、监控报警的可视化工具;
- Tablet:StarRocks 中表的逻辑分片,也是 StarRocks 中副本管理的基本单位,每个表根据分区和分桶机制被划分成多个 Tablet 存储在不同 BE 节点上;
四、系统架构
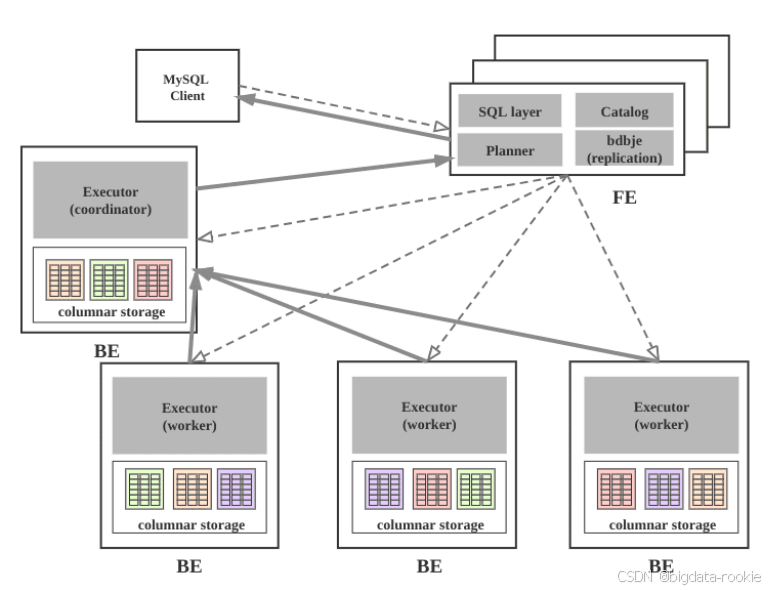
StarRocks 集群由 FE 和 BE 构成, 可以使用 MySQL 客户端访问 StarRocks 集群。
4.1 FE
- FE 接收 MySQL 客户端的连接, 解析并执行 SQL 语句;
- 管理元数据, 执行 SQL DDL 命令, 用 Catalog 记录库, 表, 分区, tablet 副本等信息;
- FE 高可用部署, 使用复制协议选主和主从同步元数据, 所有的元数据修改操作, 由 FE leader 节点完成, FE follower 节点可执行读操作。元数据的读写满足顺序一致性。FE 的节点数目采用 2n+1, 可容忍 n 个节点故障。当 FE leader故障时, 从现有的 follower 节点重新选主, 完成故障切换;
- FE 的 SQL layer 对用户提交的 SQL 进行解析, 分析, 改写, 语义分析和关系代数优化, 生产逻辑执行计划;
- FE 的 Planner 负责把逻辑计划转化为可分布式执行的物理计划, 分发给一组 BE;
- FE 监督 BE, 管理 BE 的上下线, 根据 BE 的存活和健康状态, 维持 tablet 副本的数量;
- FE 协调数据导入, 保证数据导入的一致性;
4.2 BE
- BE 管理 tablet 副本, tablet 是 table 经过分区分桶形成的子表, 采用列式存储;
- BE 受 FE 指导, 创建或删除子表;
- BE 接收 FE 分发的物理执行计划并指定 BE coordinator 节点, 在 BE coordinator 的调度下, 与其他 BE worker 共同协作完成执行;
- BE 读本地的列存储引擎获取数据,并通过索引和谓词下沉快速过滤数据;
- BE 后台执行 compact 任务, 减少查询时的读放大;
- 数据导入时, 由 FE 指定 BE coordinator, 将数据以 fanout 的形式写入到 tablet 多副本所在的 BE 上;
五、存储结构
5.1 列式存储
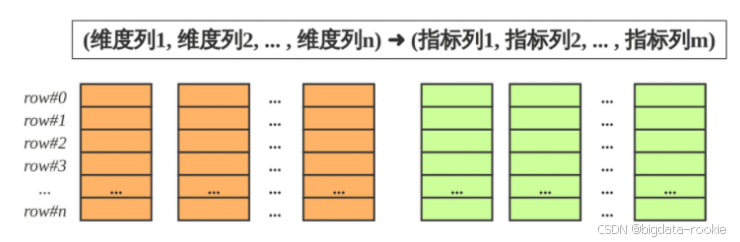
Starrocks 的表和关系型数据库相同,由行和列构成,每行数据对应用户一条记录,每列数据有相同数据类型,所有数据行的列数相同,可以动态增删列。
Starrocks 中,一张表的列可以分为维度列(也称为 key 列)和指标列(value 列),维度列用于分组和排序,指标列可通过聚合函数 SUM、COUNT、MIN、MAX 等累加起来。因此,Starrocks 的表也可以认为是多维的 key 列到多维指标的映射。
Starrocks 表中数据按列存储,一列数据会经过分块编码压缩等操作,然后持久化到磁盘。但在逻辑上,一列数据可以看成由相同类型的元素构成的数组,一行数据的所有列在各自的列数组中保持对齐,即拥有相同用的数组下标,该下标称之为序号或者行号。该序号是隐式,不需要存储的,表中的所有行按照维度列,做多重排序,排序后的位置就是改行的行号。
查询时,如果指定了维度列的等值条件或者范围条件,并且这些条件中维度列可构成表维度列的前缀,则可以利用数据的有序性,适用 range-scan 快速锁定目标行。例如:对于表 table1: (event_day, siteid, citycode, username)➜(pv);当查询条件为 event_day > 2020-09-18 and siteid = 2, 则可以使用范围查找;如果指定条件为 citycode = 4 and username in ["Andy", "Boby", "Christian", "StarRocks"],则无法使用范围查找。
5.2 稀疏索引
当进行范围查找时,Starrocks 会通过使用 shortkey index 稀疏索引快速定位目标起始行。
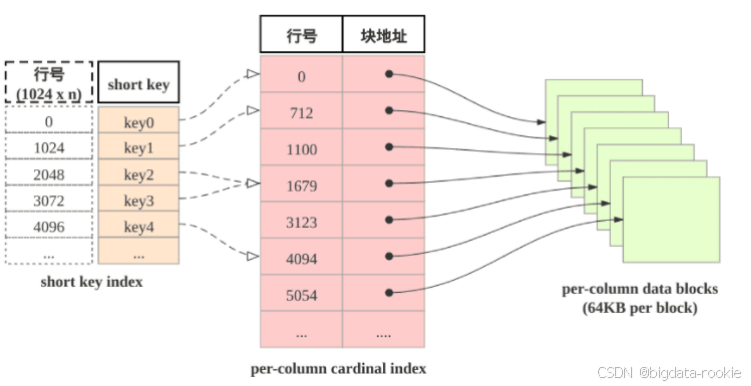
- shortkey index 表:表中数据每 1024 行构成一个逻辑 block,每个逻辑 block 在 shortkey index 表中存储一项索引,内容为表的维度列的前缀,并且不超过 36 字节。shortkey index 为稀疏索引,用数据行的维度列的前缀查找索引表,可以确定该行数据所在逻辑块的起始号;
- Per-column cardinal index:表中每列数据都有各自的行号索引,列的数据块和行号索引项一一对应,索引项由数据块的起始行号和数据块的位置和长度信息构成,用数据行的行号查找行号索引表,可以获取包含行号的数据块所在位置读取目标数据块后,可以进一步查找数据;
- Per-column data block:表中没一列数据按 64KB 分块存储,数据块作为一个单位,单独编码压缩,也作为 I/O 单位,整体写回设备或者读出;
总结:
查找维度列的前缀的查找过程为:
- 先查找 shortkey index 获得逻辑块的起始行号;
- 查找维度列的行号索引,获得目标列的数据块;
- 读取数据块,解压解码,从数据块中找到维度列前缀对应的数据项;
5.3 加速数据处理
- 预先聚合:Starrock 支持聚合模型,维度列取值相同数据行可以合并成一行,合并后数据行的维度列值不变,指标列的取值为这些数据行的聚合结果,用户需要给指标列指定聚合函数,通过预先聚合,可以加速聚合操作;
- 分区分桶:Starrocks 的表被划分为 tablet,每个 tablet 多副本冗余存储在 BE 上,BE 和 tablet 的数量可以根据计算资源和数据规模弹性伸缩。查询时,多台 BE 可以并行查找 tablet 快速获取数据。此外,tablet 的副本可以复制和迁移,这增强了数据的可靠性,避免了数据倾斜。总之,分区分桶保证了数据访问的高效性和稳定性;
- RollUp 表索引:shortkey index 可加快数据查找,然而 shortkey index 依赖维度列排列次序,如果使用非前缀的唯独列构造查找谓词,则无法使用 shortkey index。此时,用户可以为数据表创建若干 RollUp 表索引,RollUp 表索引的数据组织和存储与数据表相同,但 RollUp 表拥有自身的 shortkey index。用户创建 RollUp 表索引时,可以选择聚合的粒度、列的数量、维度列的次序,使频繁使用的查询条件能够命中相应的 RollUp 索引;
- 列级别的索引技术:Bloomfilter 可以快速判断数据块中是否含有所查找的值;ZoneMap 通过数据范围快速过来待查找指;Bitmap 索引可快速计算出枚举类型的列满足条件的行;

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)