【大数据技术实战】大数据典型框架解析
摘要:大数据技术实战类博客聚焦技术落地应用,通过具体案例、操作步骤和踩坑复盘等形式,分享真实业务中的实践经验。这类博客可分为工具实操类、业务场景落地类、性能优化类和全链路项目类,覆盖数据处理到应用全链路。其优势在于实用性强、降低学习门槛,但也存在时效性短、场景局限等不足。常用技术架构围绕"采集-存储-计算-可视化"链路展开,包含Hadoop生态、Flink、Spark等主流工具
前言
在大数据技术飞速迭代的当下,从 Hadoop 生态到 Flink 实时计算,从离线数据仓库到实时推荐系统,技术理论与工具文档已不再稀缺,但 “如何将技术落地到真实业务”“如何解决实操中的各类坑”,仍是开发者面临的核心痛点。大数据技术实战类博客恰好填补了这一空白 —— 它以场景为锚点、以实操为核心,将抽象的技术转化为可复制的方案,成为连接理论与生产的 “桥梁”。本文将系统拆解这类博客的定义、分类、优缺点,深入剖析其背后的技术架构,并补充高质量博客的判断标准与创作技巧,帮助读者既能快速识别优质内容,也能为自身创作或技术选型提供全面参考。
一、大数据技术实战类技术博客的定义
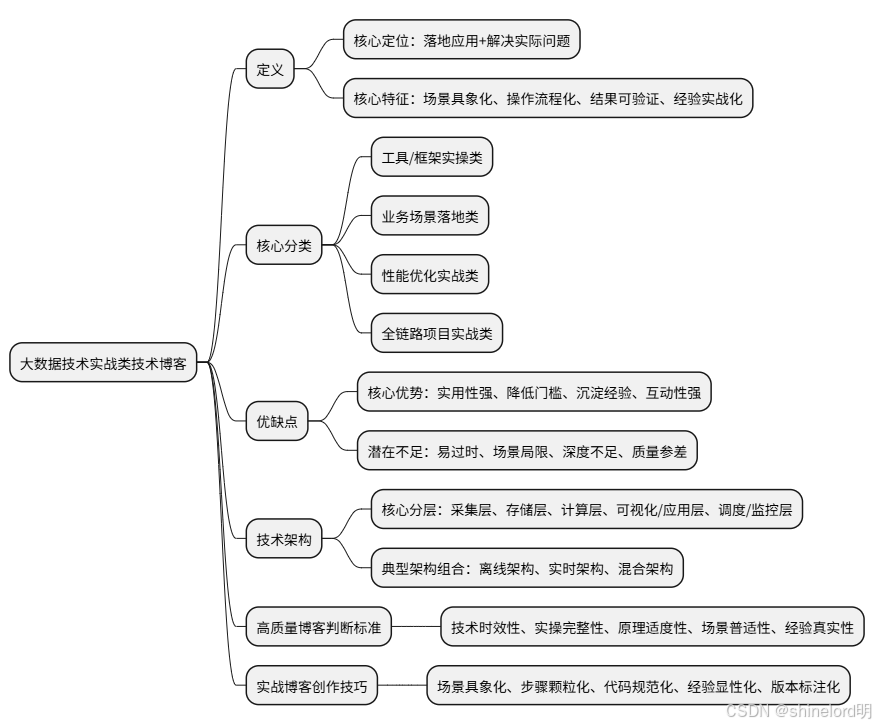
大数据技术实战类技术博客,是聚焦大数据领域落地应用场景,以 “解决实际问题” 为核心目标,通过具体案例、操作步骤、代码实现、踩坑复盘等形式,分享大数据技术在真实业务中实践经验的技术内容载体。它区别于纯理论型博客(侧重技术原理、算法推导)和资讯型博客(侧重技术动态、趋势分析),更强调 “可复制性” 和 “实用性”—— 读者能够跟随博客的步骤复现实验、迁移方案,或直接借鉴思路解决自身工作中的同类问题。
其核心特征可进一步细化为:
- 场景具象化:明确业务背景、数据量级、硬件环境等前提(如 “日均 10TB 电商日志”“3 节点 Hadoop 集群”“CentOS7 系统”),避免模糊表述;
- 操作流程化:按 “环境准备→核心步骤→结果验证” 的逻辑拆解,每个步骤包含具体指令(如 Linux 命令、SQL 语句、代码片段);
- 结果可验证:提供明确的验证方法(如 “执行 XX 命令查看数据写入量”“通过 Superset 生成可视化报表”)和预期结果(如 “数据处理延迟≤5 秒”“查询响应时间≤300ms”);
- 经验实战化:不仅包含成功步骤,还会披露 “踩坑记录”(如 “Java8 与 Flink1.15 版本兼容问题”)、“边界场景处理”(如 “数据为空时的异常捕获”)、“版本适配技巧”(如 “Spark3.x 与 Hive2.x 的配置兼容”)等官方文档少见的细节。
二、大数据技术实战类博客的核心分类(补充案例细节)
根据实战场景的侧重点不同,这类博客可分为以下 4 类,覆盖从数据处理到落地应用的全链路,新增具体案例的技术细节:
1. 工具 / 框架实操类
聚焦单一大数据工具或框架的 “上手使用”,目标是帮助读者快速掌握工具核心功能,解决 “从 0 到 1 能用” 的问题。
典型场景:
- Hadoop HDFS 集群搭建(含 SSH 免密配置、core-site.xml/hdfs-site.xml 核心配置、集群格式化与启动 命令);
- Spark Streaming 实时数据处理入门(基于 Kafka 数据源,实现单词计数,含依赖包引入、代码编写、本地调试与集群提交);
- Flink SQL 实战案例(创建 Kafka 连接器、定义水印、窗口聚合,解决迟到数据处理问题);Hive 分桶表优化实操(分桶字段选择、分桶数计算、动态分区配置,对比分桶前后查询效率)。
- 核心特点:步骤清晰、代码完整(含注释)、环境配置细节丰富(如 JDK 版本要求、依赖包版本号),适合新手入门或开发者快速查阅工具用法。
2. 业务场景落地类
围绕具体行业 / 业务的大数据解决方案,展现技术与业务的结合过程,解决 “技术如何适配业务” 的问题。
典型场景:
- 电商平台用户画像构建实战(业务痛点:精准营销需求,技术方案:用户行为数据采集(Flume+Kafka)→ 数据清洗(Spark)→ 标签计算(Hive)→ 画像存储(Redis)→ 应用对接(推荐系统 API));
- 金融风控数据建模与实时预警系统落地(业务痛点:欺诈交易识别,技术方案:交易数据实时采集(Flink CDC)→ 特征工程(Flink SQL)→ 模型推理(TensorFlow On Spark)→ 预警推送(消息队列));
- 物流行业路径优化数据分析(业务痛点:配送效率低,技术方案:GPS 轨迹数据存储(HBase)→ 路径特征提取(Spark MLlib)→ 优化算法实现(遗传算法)→ 结果可视化(ECharts))。
- 核心特点:先明确业务指标(如 “用户画像覆盖率≥90%”“风控预警准确率≥85%”),再倒推技术方案,强调业务逻辑与技术实现的衔接,附业务流程图。
3. 性能优化实战类
针对大数据系统运行中的性能瓶颈,分享优化思路、操作方法与效果验证,解决 “系统跑不快、跑不稳” 的问题。
典型场景:
- Spark 作业 OOM 问题排查与优化(瓶颈成因:数据倾斜、内存分配不合理;优化步骤:数据预处理打散倾斜 Key、调整 executor 内存与 cores 参数、开启内存管理优化;优化效果:OOM 报错消失,作业执行时间从 2 小时缩短至 40 分钟);
- HBase 读写性能调优(读优化:开启布隆过滤器、调整 BlockCache 大小;写优化:批量提交、关闭 WAL 日志(非核心数据)、调整 Region 拆分策略;优化效果:读吞吐量提升 60%,写延迟降低 45%);
- Flink 状态后端优化实践(原架构:HashMapStateBackend + 文件系统,瓶颈: checkpoint 耗时过长;优化方案:切换至 RocksDBStateBackend + 增量 checkpoint;优化效果:checkpoint 时间从 15 分钟缩短至 2 分钟,状态存储占用降低 70%)。
- 核心特点:以 “问题现象→根因分析→优化方案→效果验证” 的逻辑展开,提供可落地的参数配置示例(如 “spark.sql.adaptive.enabled=true”)、代码重构前后对比,附性能监控图表(如 Grafana 监控曲线)。
4. 全链路项目实战类
完整呈现一个大数据项目的从 0 到 1 搭建过程,覆盖需求分析、架构设计、技术选型、开发实现、测试部署全流程,解决 “如何搭建完整大数据系统” 的问题。
典型场景:
- 用户行为分析平台实战(需求:统计 UV/PV、用户访问路径、热门商品;架构设计:采集(Flume+Kafka)→ 存储(HDFS+Hive)→ 计算(Spark SQL+Flink)→ 可视化(Superset)→ 调度(Airflow);技术选型考量:“选 Flink 而非 Spark Streaming 是因为需支持事件时间窗口”);
- 实时推荐系统大数据链路搭建(需求:实时推荐用户感兴趣的商品;架构设计:采集(Kafka)→ 实时计算(Flink)→ 特征存储(Redis)→ 推荐模型(TensorFlow)→ 应用接口(Spring Boot);部署方案:Docker 容器化 + Kubernetes 调度)。
- 核心特点:体系化强,包含项目架构图、技术选型对比表(如 “离线计算工具对比:Spark vs MapReduce”)、测试用例(如压力测试场景设计)、部署脚本(如 Shell 脚本、Docker Compose 配置),适合读者借鉴完整项目经验。
三、大数据技术实战类博客的优缺点(补充细节说明)
1. 核心优势
- 实用性极强:直接对接工作场景,读者可快速将内容转化为生产力 —— 如照搬 Flink SQL 代码解决实时统计需求,借鉴 Spark OOM 优化方案解决自身集群问题,甚至直接复用全链路项目的架构设计;
- 降低学习门槛:通过 “工具实操 + 案例演示” 拆解复杂技术,例如用 “电商日志分析” 案例讲解 Spark Streaming,比单纯讲解 DStream API 更易理解,帮助新手 3 天内上手核心工具;
- 沉淀实战经验:博主分享的 “踩坑记录” 往往是生产环境中高频出现的问题,如 “Kafka 消费者组重平衡导致的数据重复消费”“Hive 动态分区与静态分区混用的报错”,这些经验需要开发者花费大量时间踩坑才能积累;
- 强互动性:读者常围绕实操细节提问(如 “Flink CDC 同步 MySQL 数据时,binlog 格式要求是什么”“Spark 作业提交时依赖包冲突如何解决”),博主与读者的互动会补充更多边界场景的解决方案,让内容更完整。
2. 潜在不足
- 时效性强,易过时:大数据技术迭代快,例如 Flink 1.17 版本新增的 Python API 与 1.10 版本差异较大,2020 年的 Flink 实操博客可能因 API 废弃导致步骤失效;Hadoop 3.x 与 2.x 的配置文件、命令行工具也有明显变化;
- 场景局限性:部分方案依赖特定环境,如 “基于 10 节点集群的 Spark 优化方案” 在 3 节点小规模集群中可能不适用;“处理结构化数据的 Hive 优化技巧” 对非结构化日志数据可能无效;
- 深度可能不足:为兼顾 “实操性”,部分博客会简化原理讲解,例如只讲 “如何调整 Spark 内存参数”,却不解释 “executor 内存由哪些部分组成”,导致读者遇到类似问题时无法举一反三;
- 质量参差不齐:部分博主为追求流量,存在 “步骤缺失”(如省略环境依赖安装)、“代码无法复现”(如遗漏核心配置)、“优化效果夸大”(如无真实数据支撑)等问题,需要读者结合自身经验甄别。
四、大数据技术实战类博客常用的技术架构(补充选型对比)
实战类博客的技术架构围绕大数据 “采集 - 存储 - 计算 - 可视化 / 应用” 全链路展开,不同场景下技术选型有所差异,以下是主流技术栈组合及选型逻辑:
1. 核心技术架构分层(可视化图表 + 表格 + 选型对比)
架构分层示意图

架构分层详情表(补充选型对比)
|
架构分层 |
核心功能 |
常用技术选型 |
选型对比(适用场景) |
实战场景示例 |
|
数据采集层 |
收集分散的结构化 / 非结构化数据,传输至存储层 |
离线:Sqoop、DataX、LogstashFlume、Kafka、FileBeat、Flink CDC |
离线采集:Sqoop(适配 Hadoop 生态)、DataX(跨数据源支持好)、Logstash(日志采集更优)实时采集:Flume(日志实时传输)、Kafka(高吞吐缓存)、Flink CDC(数据库实时同步,无侵入) |
日志采集(Flume+Kafka)、数据库数据同步(Sqoop/ DataX)、实时数据捕获(Flink CDC) |
|
数据存储层 |
存储海量原始数据 / 加工后数据,支持高吞吐读写 |
分布式文件存储:HDFS、MinIO > 数据库存储:HBase(实时)、Hive(离线)、ClickHouse(OLAP)、Redis(缓存) |
分布式文件存储:HDFS(大数据生态标配)、MinIO(对象存储,轻量化):HBase(实时随机读写)、Hive(离线批量存储)、ClickHouse(OLAP 分析,查询快)、Redis(高频数据缓存) |
离线数据仓库存储(HDFS+Hive)、实时高频查询数据存储(HBase+Redis)、OLAP 分析存储(ClickHouse) |
|
数据计算层 |
对存储数据进行离线 / 实时计算,完成数据加工、分析、建模 |
离线计算:Spark Core/Spark SQL、MapReduce、Hive SQLFlink、Spark Streaming、Storm |
离线计算:Spark(速度比 MapReduce 快 10-100 倍,支持 SQL)、MapReduce(稳定,适合超大规模数据)实时计算:Flink(低延迟、支持事件时间)、Spark Streaming(微批处理,生态完善)、Storm(纯实时,吞吐量低) |
离线批量分析(Spark SQL+Hive)、实时流处理(Flink+Kafka)、机器学习建模(Spark MLlib) |
|
数据可视化 / 应用层 |
将计算结果以直观形式呈现,或对接业务应用 |
可视化工具:Superset、Metabase、ECharts > 应用对接:API 接口(Spring Boot)、推荐系统(Redis + 业务服务) |
可视化工具:Superset(开源,支持多数据源)、Metabase(易用性强)、ECharts(自定义程度高)对接:Spring Boot(快速开发 API)、Redis(缓存计算结果,提升接口响应) |
用户行为报表可视化(Superset)、实时预警通知(Flink + 消息推送 API) |
|
调度 / 监控层 |
管理作业生命周期、监控系统运行状态 |
调度工具:Airflow、Azkaban、DolphinScheduler:Prometheus、Grafana、ELK Stack |
调度工具:Airflow(灵活,支持复杂依赖)、Azkaban(简单易用,适合 Hadoop 生态)、DolphinScheduler(国产化,可视化操作)监控工具:Prometheus+Grafana(指标监控)、ELK(日志收集与分析) |
离线作业定时调度(Airflow)、Flink 作业监控(Prometheus+Grafana)、日志告警(ELK) |
2. 典型架构组合示例(可视化图表 + 架构说明)
(1)离线大数据实战架构

架构说明:适用于离线数据分析场景(如日 / 周 / 月报表统计),特点是数据量大、对延迟要求低(允许 T+1 延迟),技术栈成熟稳定,运维成本低。
(2)实时大数据实战架构


助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)