OpenClaw - Day 8 用这 4 个 Skills,把 OpenClaw 的搜索能力拉到天花板
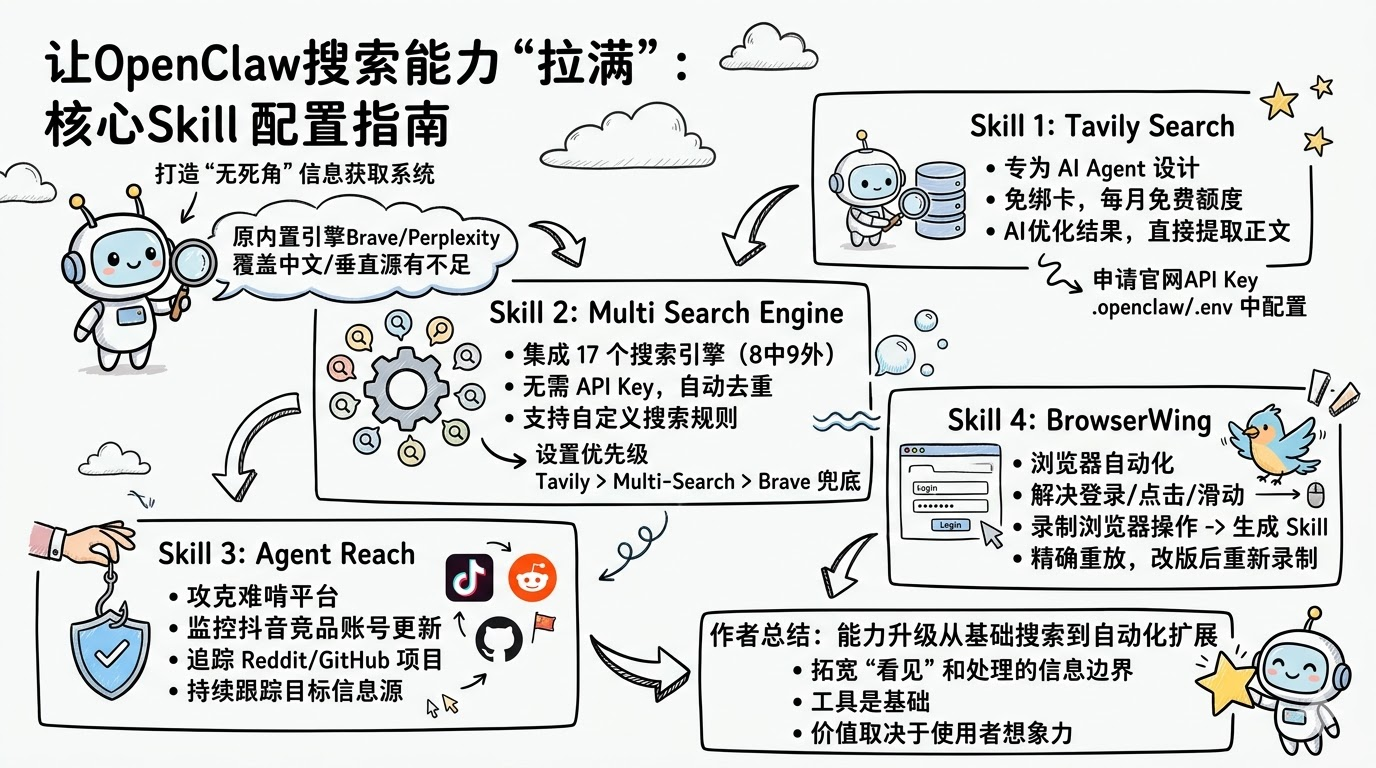
本文介绍了为OpenClaw AI助手重构搜索系统的方案。原系统存在中文覆盖不足、API限制等问题,新方案采用分层架构:1)用Tavily作为主力搜索,提供AI优化结果;2)整合17个搜索引擎实现多源补全;3)通过Agent Reach抓取抖音、GitHub等平台内容;4)用BrowserWing实现浏览器自动化操作。这套系统显著扩展了信息获取边界,使AI助手能从网页搜索延伸到平台级数据抓取,最终
文章目录
一、为什么要给 OpenClaw 重做搜索系统?
很多人第一次接触 OpenClaw,只是把它当成「本地版 ChatGPT」,问问问题、写点代码、改改文档。 但作者在用了一个月之后发现:如果不强化联网搜索,它离「真正可用的 AI 助手」还差一个量级。
从 Agent 能力视角看,一个实用的 AI 助理至少要具备三件事:
- 主动获取信息:不仅能回答你问什么,还能自己知道去哪儿找答案。
- 有效分析信息:能过滤噪音、结构化整理,而不是把一堆网页丢给你。
- 做出判断与决策:在多种来源之间对比、取舍,给出靠谱结论。
这三件事的前提,都是强大的联网搜索能力。 如果搜索做不好,后面的分析和决策都是无源之水。
内置搜索为什么不够用?
OpenClaw 官方默认集成了 Brave Search 和 Perplexity,但作者实际体验下来有几个明显问题:
- Brave Search:
- 需要绑卡才能用 API。
- 免费额度有限,稍微用勤快一点就不够用。
- Perplexity:
- 需要付费订阅。
- 在国内网络环境下,稳定性一般,经常连不上或延迟很高。
- 通用痛点:
- 对中文生态的覆盖有限。
- X、小红书、微信公众号、B 站、播客等常用信息源,传统搜索很难搜全甚至直接搜不到。
作者给出的总体目标是:让 OpenClaw 拥有一个「无死角的信息获取系统」——既能覆盖广度(多搜索引擎、多语种),又能深入到特定平台,甚至能在需要登录和交互的网站里自动操作。
接下来的 4 个 Skill,就是围绕这个目标逐步搭起来的。
二、整体思路:从“换引擎”到“扩边界”
这套方案不是简单「把默认搜索换掉」这么粗糙,而是有一个清晰分层:
- 用 Tavily 替代 Brave/Perplexity,作为高质量主力搜索。
- 用 Multi Search Engine 聚合 17 个搜索引擎,作为多源补全与兜底。
- 用 Agent Reach 打通抖音、Reddit、GitHub 等特定平台的数据抓取与跟踪。
- 用 BrowserWing 做浏览器录制与自动化,搞定必须登录、点击、滑动才能访问的复杂网站。
你可以把这 4 层理解为:
- 第一层:高质量网页搜索。
- 第二层:多搜索引擎综合视野。
- 第三层:面向平台的结构化抓取。
- 第四层:通用浏览器自动化兜底(实在没有 API 的场景)。
这种分层结构的意义在于:每加一层,OpenClaw 能「看见」的世界就更大一圈,而 Agent 的决策质量也随之提高。
三、Skill 1:Tavily Search——给 Agent 设计的搜索 API
3.1 Tavily 是什么?
推荐的第一个 Skill 是 Tavily Search,一个「专门为 AI Agent 设计的搜索 API」。 与传统面向人类用户的搜索引擎不同,Tavily 的目标是:让机器能够直接拿来用,而不必先打开网页、再解析内容。
3.2 核心优势
几个关键优势:
- 不用绑卡:官方提供免费配额,按月计数。
- 每月免费额度:默认有约 1000 次调用,足够个人/小团队开发与使用。
- 结果经 AI 优化:
- 返回的不是原始网页 HTML,而是经过模型归纳过的结构化结果。
- 垃圾信息和广告大幅减少,更适合二次加工与推理。
- 支持直接内容提取:
- 你不需要再写一个「爬网页+提取正文」的 Pipeline。
- Tavily 返回的就是能直接喂给大模型的内容格式。
| 特性 | Brave | Tavily |
|---|---|---|
| 免费额度 | 有限 | 约 1000 次/月 |
| 结果形态 | 原始网页 | AI 优化内容 |
| 内容提取 | 需要自己处理 | 直接可用 |
| 绑卡要求 | 需要 | 不需要 |
这张表背后的本质区别是:Brave 是「给人看的搜索结果」,Tavily 是「给 Agent 用的数据源」。
3.3 如何在 OpenClaw 中配置 Tavily?
关键步骤:
-
前往 Tavily 官网注册账号,申请 API Key(有免费额度)。
-
在本地 OpenClaw 项目的
.openclaw/.env文件中,增加一行环境变量:TAVILY_API_KEY=你的密钥 -
确保 OpenClaw 中对应的 Skill(如
tavily_search)引用了该环境变量。
完成这一步后,所有调用通用搜索的 Agent,就可以优先走 Tavily,而不是默认的 Brave/Perplexity。
3.4 一个典型使用场景示例
假设你想让 OpenClaw 做这样一件事:
「帮我调研最近 3 个月国内外关于 Function Calling Agent 最好的实践和开源项目,给出结论与推荐。」
如果用传统搜索,Pipeline 大致是:
- 调用搜索引擎拿到一堆链接。
- 针对每个链接再做一次 HTTP 抓取。
- 写正文抽取、噪音过滤、去重逻辑。
- 把结果再丢给大模型总结。
而用 Tavily,流程会变成:
- 一次 Tavily 搜索,即返回结构化的摘要与关键内容。
- 直接交给大模型做聚合和分析。
对于 Agent 来说,链路长度缩短,可靠性反而提高,这也是作者强推 Tavily 的核心原因。
四、Skill 2:Multi Search Engine——一次打包 17 个搜索引擎
4.1 为什么需要“多搜索引擎聚合”?
即便有了 Tavily,仍然不可避免存在盲区:
- 某些垂直领域搜索引擎本身就更专业。
- 某些地区和语种在本地搜索引擎中的覆盖更好。
- 某些问题需要从多个来源交叉验证,避免单一信息源偏见。
为此,推荐 Multi Search Engine 的 Skill,它集成了 17 个搜索引擎,其中包含 8 个中文搜索源和 9 个全球搜索源。
4.2 这个 Skill 的特点
- 不需要任何 API Key:开箱即用,更适合快速试验或部署环境复杂的场景。
- 自动去重:当多个搜索引擎返回相似结果时,会在聚合层面做去重,避免信息「刷屏」。
- 支持搜索规则自定义:你可以通过配置,指定某些 Engine 的优先级,或对不同 Agent 使用不同的引擎组合。
这意味着,Multi Search Engine 更像是一个「搜索编排层」,而不是单一搜索工具。
4.3 在 Agents.md 中配置搜索优先级
一个非常实用的建议:在 OpenClaw 的 Agents.md 中显式配置搜索顺序。
推荐的优先级是:
- Tavily Search —— 质量优先。
- Multi Search Engine —— 补全与多源视角。
- Brave Search —— 作为最后兜底。
并提出一个简单的原则:
能用 Tavily 就尽量不用 Multi Search Engine,能用 Multi Search Engine 就尽量不用 Brave。
这种设计逻辑是:「先用最省事、最适合 Agent 的源,如果不够再逐步降级」,既保证质量也兼顾覆盖度。
4.4 示例:如何设计一个“研究型 Agent”的搜索策略
假设你要设计一个「技术趋势研究型 Agent」,它的工作是:
- 追踪 AI 编译器、新型 Agent 框架等前沿技术。
- 为你定期生成「技术雷达」报告。
可以这样设置:
- 默认搜索:Tavily —— 负责综合性信息、英文前沿论文/博客。
- 补充搜索:Multi Search Engine —— 同时打到国内中文搜索和海外特定搜索源。
- 降级搜索:Brave —— 当前两者都失败或超时时兜底。
在实现层面,只需要在 Agent 的配置中按顺序挂上这几个 Skill,OpenClaw 调用时就会按优先级自动走。
五、Skill 3:Agent Reach——攻克抖音、Reddit、GitHub 等“难啃平台”
5.1 通用搜索的盲点:平台内容
即便你把常规网页搜索做到极致,仍有一大类内容几乎搜不到或搜不全:
- 短视频平台(抖音、快手等)中的账号更新和评论趋势。
- 社区平台(Reddit、V2EX 等)的具体话题讨论。
- 开发者平台(GitHub、Hugging Face 等)的最新项目与 Issue 动态。
这些平台通常:
- 对爬虫有限制。
- 需要复杂的分页、滚动加载。
- 有自己的搜索 API 或非公开接口。
因此,作者引入了第三个 Skill:Agent Reach。
5.2 Agent Reach 能做什么?
一些典型使用场景:
- 监控竞品抖音账号更新:
- 定期抓取指定抖音号的新视频、互动数据。
- 让 OpenClaw 总结「最近他们在讲什么」「内容策略有什么变化」。
- 追踪 Reddit 上某个话题的讨论:
- 不仅抓热帖,还抓评论区的观点分布和情绪倾向。
- 搜索 GitHub 上的最新项目:
- 按关键词、Star 数、更新时间筛选,提炼出值得关注的仓库列表。
可以看到,Agent Reach 更像是「平台级数据抓取框架」,让 OpenClaw 能对接到各种非网页形式的数据源。
5.3 与前三个 Skill 的关系
如果把前两个 Skill 看作是「网页世界的视野扩展」,Agent Reach 就是在「平台世界」再开一扇门。
一个更完整的 Agent 工作流可能是:
- 用 Tavily+Multi Search Engine 做宏观趋势调研。
- 用 Agent Reach 在抖音、Reddit、GitHub 等具体平台拿案例、讨论和代码实现。
- 综合多方信息,输出一份真正有细节、有案例、有代码链接的分析报告。
这一层配合得好,会让你的 Agent 从「泛泛而谈」变成「有例有据、有实战链接」。
六、Skill 4:BrowserWing——用录制的方式做浏览器自动化
6.1 为什么还需要浏览器自动化?
即便有了多搜索引擎和平台抓取,依然会遇到这种网站:
- 必须登录才能查看内容。
- 页面需多次点击、滚动才能加载出完整信息。
- 内容结构不稳定,难以用简单的抓取脚本处理。
这时常用方案是用 Playwright/Selenium 之类的浏览器自动化框架,模拟人类操作。但问题是:
- 要写代码。
- 要处理选择器、等待时间、页面异常。
- 页面一改版,脚本经常大面积失效,需要重新调试。
为此引入了第四个 Skill:BrowserWing。
6.2 BrowserWing 的核心创新:录制即 Skill
可以概括为一句话:
用「录制浏览器操作」的方式,生成可复用的 OpenClaw Skill。
其基本工作流程是:
- 人类正常在浏览器中操作(点击、输入、滚动等)。
- BrowserWing 在后台记录这些操作步骤。
- 录制结束后,这段「操作脚本」被保存为一个 Skill。
- 之后 OpenClaw 就可以像调用普通函数那样,调用这个 Skill 来重复执行整套操作。
和 Playwright 的对比表中,作者给出了几个维度:
| 特性 | Playwright | BrowserWing |
|---|---|---|
| 使用方式 | 写代码 | 录制操作 |
| 学习成本 | 高 | 低 |
| 精确度 | 需要调试 | 精确重放 |
| 维护成本 | 页面改版需改代码 | 重新录制即可 |
实质上,这是在「浏览器自动化」这个层面做了一次「无代码化」。
6.3 一个实战例子:自动抓取内部 BI 报表
假设你公司有一个内部 BI 系统:
- 必须公司 VPN + 登录。
- 要先选择时间区间,再点开某个图表。
- 最后点导出按钮才能拿到 CSV。
传统 Playwright 做法:
- 写一堆 CSS/XPath 选择器。
- 调试等待时间、处理偶发的弹窗。
- 每次前端改版都要重新修。
用 BrowserWing 的做法:
- 打开 BI 页面。
- 手工完成一遍「登录 → 选择时间 → 导出」流程。
- 让 BrowserWing 录制这一串操作,并保存成 Skill。
- 以后只要 Agent 想定期跑这个报表,调用该 Skill 即可。
对非前端/自动化方向的工程师来说,这种路径要友好得多。
七、整体搭建:把这 4 个 Skills 组合成一套「无死角信息系统」
OpenClaw 的「高级化」不是某个单一工具带来的,而是一个逐步扩展能力边界的过程:
- 从基础搜索开始:先用 Tavily 把「能查到什么」做厚实。
- 通过 Multi Search Engine 扩展到更多搜索源:减少漏网内容。
- 再用 Agent Reach 打通关键平台:抖音、Reddit、GitHub 等。
- 最后用 BrowserWing 处理剩余「必须浏览器交互」的场景。
如果你从 0 到 1 搭建自己的 OpenClaw 环境,可以参考这样的实践顺序:
- 第一步:配置 Tavily,替换内置 Brave/Perplexity 为默认主力搜索。
- 第二步:增加 Multi Search Engine,在
Agents.md设定好优先级策略。 - 第三步:根据自己常用的平台(比如抖音+GitHub),接入 Agent Reach,写 1~2 个专用调研 Agent。
- 第四步:挑一两个需要登录或复杂操作的业务网站,尝试用 BrowserWing 录制自动化流程,沉淀成可复用 Skill。
做到这一步,你就不再是在用「一个更聪明的搜索框」,而是在养成一只真的能「帮你跑腿、帮你查、帮你整理、还能帮你点点点」的小龙虾 Agent。
八、提醒
- 工具只是工具,再强大的 Skills,如果只是停留在「感觉很酷」的阶段,其实不会产生真正价值。
- 这些 Skills 帮你解决的是「看见更多信息」的问题,而不是替你决定该做什么。
- 真正拉开差距的,是你对问题的拆解能力、对流程的设计能力,以及持续迭代工作流的耐心。
如果你是开发者或研究人员,建议你从一个具体场景入手,比如:
- 跟踪一个技术领域的所有最新论文+GitHub 项目。
- 监控几个竞品的内容更新和用户反馈。
- 自动整理行业政策、新闻与数据指标,做成日/周报。
然后,用这 4 个 Skills 把这个场景从「手工信息搜索」逐步升级成「Agent 自动采集 + 你做决策」,这才是 OpenClaw 真正的用法。
九、小结
结合整篇文章内容,如果你现在就想动手,可以按下面这个 checklist 自查:
- 本地 OpenClaw 环境已可正常运行。
- 已注册 Tavily,配置好
TAVILY_API_KEY。 - 在
Agents.md中将 Tavily 设为通用搜索首选。 - 已安装并启用 Multi Search Engine,确认 17 个搜索引擎聚合正常。
- 针对你关注的平台(抖音/Reddit/GitHub 等)配置好了 Agent Reach,并做过至少一次完整调研任务。
- 至少录制过一个 BrowserWing 流程,把「某个网站的一套操作」封装成了可复用 Skill。
当你把这些环节跑通,你就已经将「OpenClaw 搜索做到极致」的门槛上,接下来,就是用想象力去设计属于你自己的 Agent 工作流了。


助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 13
13 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)