嵌入式工程师的知识操作系统:Obsidian + AI 架构实践
在 AI 时代,嵌入式开发的效率差距不再来自工具,而来自是否建立系统化的知识结构。本文提出一种方法:利用 Obsidian + Claude 构建工程师的“数字外脑”。通过仿照嵌入式软件架构,将知识分为 Datasheets、Middlewares、Product Logs、AI Prompts、Hidden Knowledge 等层级,实现从硬件手册解析、代码复用到调试经验沉淀的完整体系。开发过
文章目录
嵌入式 AI 转型:构建基于 Obsidian + Claude 的“数字外脑”系统
前言:
别让你的嵌入式开发,沦为一场“低效的勤奋”
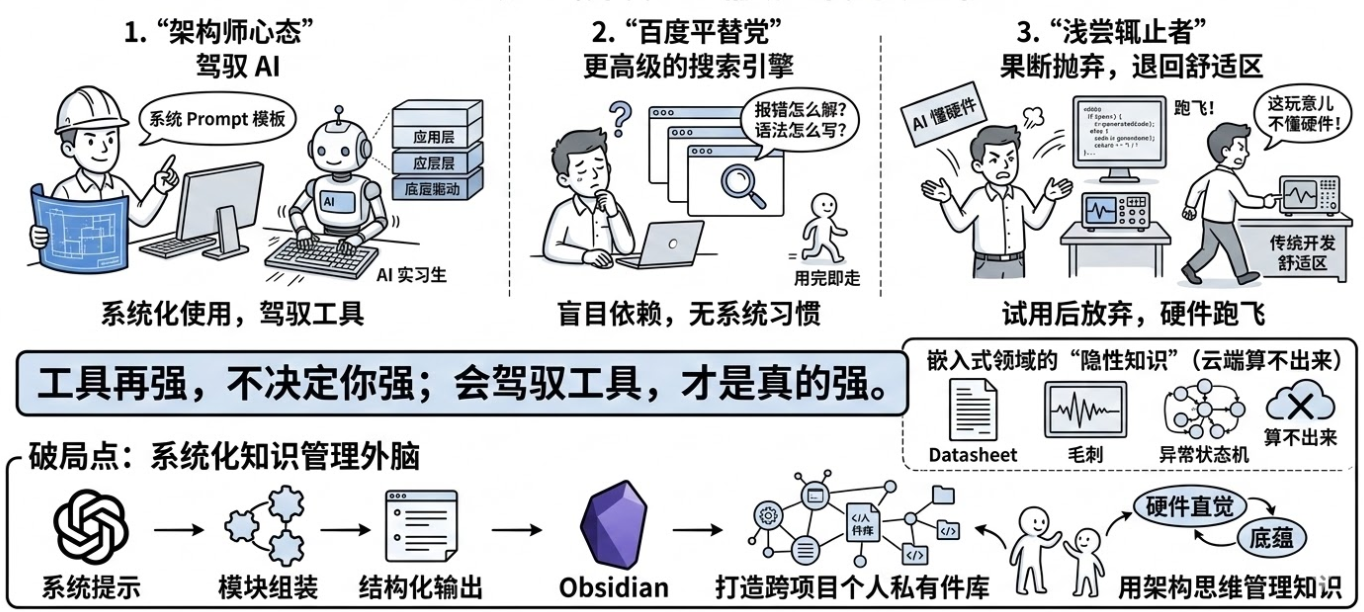
最近,公司在全面推行 AI 辅助编程以提升效率。但在真实的开发小组里,我观察到了极具戏剧性的“众生相”,大致可以分为三类人:
-
第一类是“架构师心态”: 他们每天都在积极摸索,不是简单地让 AI 写代码,而是结合项目实际,总结出了一套从底层驱动到应用层的标准 Prompt 模板,把 AI 变成了不知疲倦的“初级实习生”。
-
第二类是“百度平替党”: 他们对 AI 的理解仅限于“更高级的搜索引擎”。遇到报错查一下,忘了语法问一句,用完即走,根本没有建立起系统化的使用习惯。
-
第三类是“浅尝辄止者”: 稍微试用了一下,发现 AI 写的底层寄存器配置总是跑飞,或者给出的硬件时序根本不对,便果断抛下了一句“这玩意儿根本不懂硬件”,然后心安理得地退回了传统的开发舒适区。
看到这种分化,不禁反思:在 2026 年,AI 工具本身的强弱,早就不是工程师之间的胜负手了。 正如业内常说的那句话:“工具再强,不决定你强;会驾驭工具,才是真的强。”
尤其是在嵌入式开发这个特殊的领域,我们面临着极高的软硬件耦合度。一本几千页的 Datasheet、一次示波器上难以捕捉的毛刺、一段只在特定温度下才会触发的异常状态机……这些充满了玄学的“隐性知识”,是纯靠大模型在云端算不出来的。如果我们只是盲目地依赖 AI 生成千篇一律的样板代码,或者仅仅把它当成高级搜索,就极容易陷入一场“低效的勤奋”——看似每天都在敲代码,实则个人能力毫无壁垒。
那么,破局点在哪里?
本文将自我剖析,如何借用 Claude 的设计理念(系统化提示、模块化组装、结构化输出),在 Obsidian 中搭建一套专属嵌入式工程师的“外脑”知识管理模板。
这不是说明如何记笔记,而是教你如何打造一个跨项目的个人私有件库。我们将一起抹平对大模型的认知差,用架构的思维管理知识,并精准捕捉那些 AI 永远无法触及的“硬件直觉”与底蕴。
一、 设计哲学:为什么是 Obsidian + Claude?
Claude 的核心在于 Constitutional AI(宪法 AI)——它遵循原则、逻辑透明且极具逻辑深度。我们的知识管理系统也应如此:
- 原子化(Atomicity): 像 Claude 处理 Token 一样,每一条笔记只讲一个最小的技术点(如:一个 I2C 延时的坑)。
- 上下文感知(Context-Aware): 利用 Obsidian 的双向链接,模仿 LLM 的注意力机制,让硬件特性、软件协议、调试经验自动关联。
- 本地优先(Local-First): 嵌入式开发涉及大量私有协议和底层代码,本地化存储确保了数据的安全性与响应速度。
这种设计哲学的核心,是将大语言模型(LLM)的工程化处理逻辑,降维应用到个人的知识治理中。目的打造自己的私有私有知识库。
二、 模板架构:嵌入式工程师的“分层驱动”模型
我建议在 Obsidian 中采用类似于 嵌入式软件分层 的目录结构,这样符合工程师的思维惯性。
1. 目录结构设计
| 文件名称 | 对应层级 | 内容说明 |
|---|---|---|
00_MOCs |
路由层 | 利用索引笔记(Map of Content)链接全局,如《BLE 协议栈索引》。 |
10_Datasheets |
驱动层 | 存放芯片手册的 AI 总结、寄存器避坑指南、引脚定义。 |
20_Middlewares |
组件层 | RTOS 配置、通信协议库(Modbus, MQTT)、自建算法库。 |
30_Product_Logs |
应用层 | 智能锁等具体项目的开发日志、业务逻辑、Bug 演进。 |
40_AI_Prompts |
算力层 | 存放针对不同场景的 Claude 提示词模板(如:代码重构专用)。 |
50_Hidden_Knowledge |
底蕴层 | 最核心: 记录那些 Datasheet 没写、AI 搜不到的物理调测经验。 |
这个文件夹结构非常精妙,它本质上是将嵌入式软件架构(底层驱动 -> 中间件 -> 应用层)的思维,完美映射到了个人知识管理系统中。这种分类方式不仅符合工程开发的逻辑,还能让知识像代码库一样具备高复用性和可维护性。
下面我逐层为你展开说明,并配以具体的工程实战例子: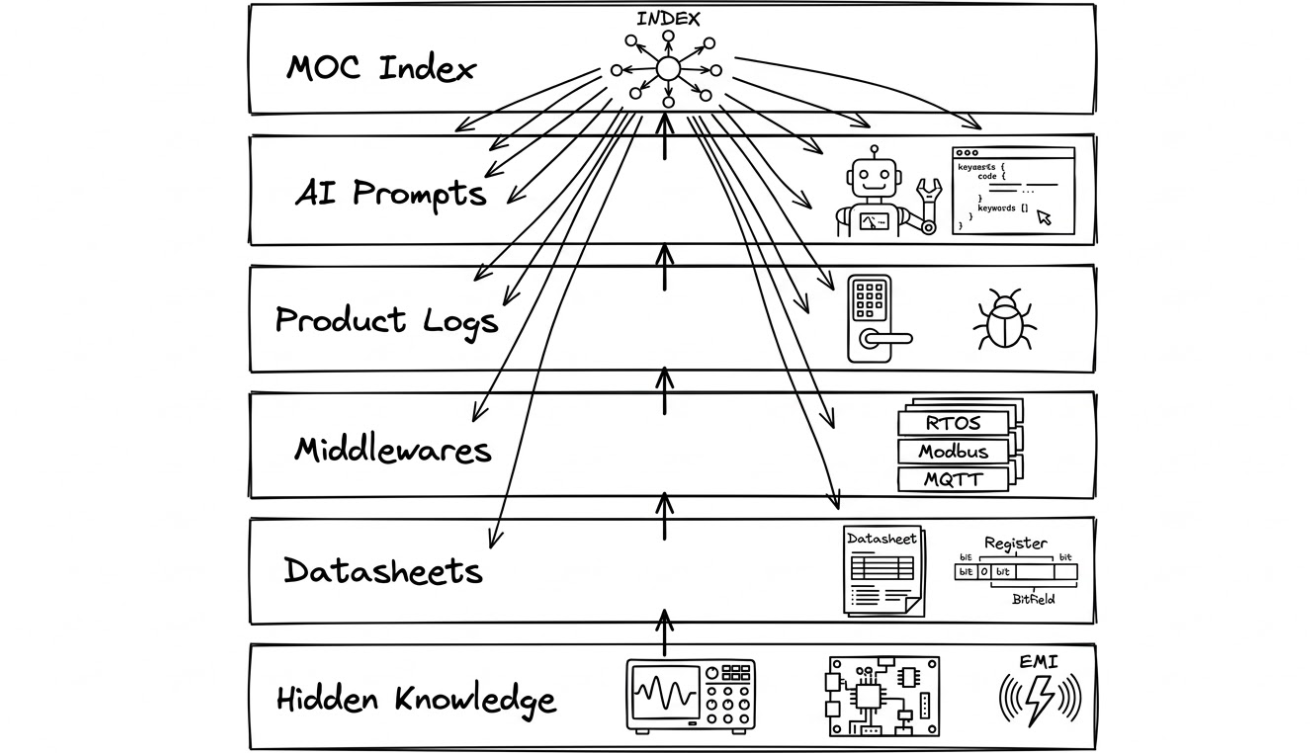
00_MOCs(路由层:全局导航与知识索引)
内容说明: MOC (Map of Content) 是整个知识库的“大脑皮层”。它不存放具体的长篇大论,而是作为一个目录节点,用双向链接将散落在各个文件夹中的碎片知识串联起来,形成知识网络。
实战例子:
假设你建立了一个笔记叫 《BLE 协议栈全局索引.md》,它的内容可能是一个超链接大纲:
- 基础概念: -> 链接到
[蓝牙广播机制详解] - 硬件对接: -> 链接到
[10_Datasheets/NRF52832_射频引脚配置] - 软件实现: -> 链接到
[20_Middlewares/L2CAP_分包逻辑] - 疑难杂症: -> 链接到
[50_Hidden_Knowledge/天线阻抗不匹配导致的断连分析]
通过这个路由,你复习或者排查 BLE 问题时,能瞬间顺藤摸瓜找到所有相关层级的资料。
10_Datasheets (驱动层:与硬件死磕的兵器谱)
内容说明: 这里不是用来堆砌几千页的原版 PDF 手册(原版 PDF 应该丢在归档盘),而是存放你消化过后的硬件交互指南。包含了引脚速查、寄存器配置要点、以及用 AI 提炼的核心时序图说明。
实战例子:
笔记名称:《STM32L451_I2C_防坑速查手册.md》
- 内容: “官方手册第 345 页的 I2C 硬件状态机有 Bug。如果在清除 ADDR 标志位时被打断,会导致总线死锁。解决方案: 放弃硬件 I2C,直接使用我在
20_Middlewares写的软件模拟 I2C 库,或者在硬件初始化中加入超时复位机制。”
20_Middlewares(组件层:跨项目复用的造轮子车间)
内容说明: 这里存放的是与具体业务无关、可以随时移植到下一个项目的通用软件模块。它的核心价值在于**“解耦”和“复用”**。
实战例子:
笔记名称:《Modbus_RTU_通用解析器实现.md》
- 内容: 记录了你手写的一个 Modbus 协议栈架构。里面说明了如何通过回调函数(Callback)将底层的串口发送/接收接口剥离出来。这样下次不管是换 NXP 的芯片还是 ESP32,这个组件都可以直接原封不动地拷过去用。同时记录了配合 FreeRTOS 队列使用的内存调优参数。
30_Product_Logs(应用层:具体战役的作战日记)
内容说明: 针对具体产品(如IPC、智能门锁、工业网关)的业务逻辑开发记录。这里关注的是需求如何实现、状态机如何流转、以及特定项目的 Bug 是如何一步步演进和修复的。
实战例子:
笔记名称:《智能锁 V2.0_主状态机演进日志.md》
- 内容: “2026年3月5日:发现电机堵转时会导致系统复位。排查业务逻辑发现,开锁指令下达时没有先检测电池电量(联动
20_Middlewares/电源管理组件)。修改记录: 在开锁状态前增加电量阈值判断,低于 15% 拒绝驱动电机并触发低电量语音播报。附:最新版本的 Mermaid 状态机流程图。”
40_AI_Prompts(算力层:外脑加速器的控制台)
内容说明: 把 AI 当作你的“初级代码实习生”,这里存放的是你调教这位实习生的标准化咒语(Prompt)。好的提示词可以帮你省去大量写样板代码、查语法结构的时间。
实战例子:
笔记名称:《Prompt_C语言重构_符合MISRA标准.md》
- 内容: 存放一段固定的模板:“你现在是一位拥有 20 年经验的嵌入式软件架构师。请审查并重构以下 C 语言代码。要求:1. 消除所有隐式类型转换;2. 变量命名必须符合我公司规范(前缀 g_ 表示全局,宏定义全大写);3. 为所有函数生成 Doxygen 格式的注释。代码如下:[填入代码]”
实际例子解析:
专门用于解决嵌入式开发中极其常见的“国产化替代”场景。以下内容存为 Obsidian 中的一个原子笔记:[[Prompt_MCU移植_STM32到GD32]]。
# Role / 角色设定
你是一位拥有 15 年经验的嵌入式底层架构师,精通 STM32 (HAL/标准库) 与 GD32 (固件库) 的底层差异。你擅长在保持代码逻辑不变的前提下,进行高性能、低功耗的硬件抽象层转换。
# Task / 任务目标
将我提供的 [STM32 驱动代码] 移植为 [GD32 驱动代码]。
# Context / 技术背景
- 硬件平台:从 STM32F103 系列移植到 GD32F10x 系列(或根据实际指定)。
- 开发库:STM32 使用 [HAL库/标准库],GD32 使用 [标准固件库]。
- 核心考量:GD32 的主频通常更高,Flash 访问机制不同,且某些外设(如 I2C、ADC)存在已知的寄存器级差异。
# Rules / 移植准则(必须严格遵守)
1. **头文件替换**:将 #include "stm32f1xx.h" 等替换为对应的 #include "gd32f10x.h"。
2. **外设使能逻辑**:GD32 的时钟使能通常使用 `rcu_periph_clock_enable()`。请务必确认外设挂载的总线(APB1/APB2/AHB)是否一致。
3. **GPIO 配置映射**:
- STM32 HAL: HAL_GPIO_Init() -> GD32: gpio_init()。
- 注意:GD32 的 GPIO 速度参数与 STM32 存在对应映射关系,请精确转换。
4. **中断处理**:保持中断优先级逻辑一致,但需更新 NVIC 配置函数的名称。
5. **性能优化补丁**:
- GD32 执行速度较快,若原代码中有软件延时(Software Delay Loop),请按比例调整或建议改用定时器。
- 针对 I2C 模块,若检测到原代码为硬件 I2C,请特别提醒 GD32 在高频下的稳定性处理。
6. **代码风格**:保持原有的函数入口参数和业务逻辑不变,仅更换底层调用。
# Output Format / 输出要求
1. **对比清单**:列出本次移植中关键的外设差异点。
2. **移植后代码**:完整的 .c 和 .h 文件,需包含详细的中文注释说明。
3. **避坑指南**:根据 GD32 的 Datasheet,指出该模块在实际调试中可能遇到的“玄学问题”(对应我的 50_Hidden_Knowledge 逻辑)。
# Input Data / 待处理代码/亦或者使用Claude学到这个再@原来文件
[在此处粘贴你的 STM32 源码]
为什么这样设计提示词能“抹平认知差”?
-
注入了“隐性知识”:提示词中明确提到了 “GD32 主频更高” 和 “Flash 访问机制不同”。这能引导 AI 不仅仅做简单的字符串替换,还会去思考定时器频率、I2C 时序等深层问题。
-
强制结构化输出:要求输出“对比清单”和“避坑指南”,这其实是在强迫 AI 调动其预训练数据中关于 Errata(勘误表) 的知识。
-
闭环反馈:输出的“避坑指南”可以直接剪辑到你的 50_Hidden_Knowledge 文件夹中,完成从 AI 辅助 -> 个人沉淀 的闭环。
50_Hidden_Knowledge (底蕴层:不可替代的工程师护城河)
内容说明: 这是整个系统里最值钱的地方。存放那些 Datasheet 里绝对不会写、StackOverflow 搜不到、AI 也算不出来的“物理世界玄学”。这些是靠烧毁的板子、熬夜的头发换来的软硬件联合调试经验。
实战例子:
笔记名称:《继电器动作导致 SPI 屏幕白屏的 EMI 污染分析.md》
- 内容: “现象: 设备偶尔在继电器吸合瞬间,SPI 驱动的 LCD 屏会白屏死机。软件逻辑查不出任何问题。真因: 示波器抓取发现,继电器线圈断开时的反向电动势产生了极强的 EMI 尖峰,耦合到了并排走线的 SPI SCK 时钟线上,导致单片机多读了一个时钟周期,时序彻底错乱。硬件对策: 在继电器两端反向并联续流二极管;在 SCK 线上靠近 MCU 端增加 22pF 滤波电容。血泪教训: 以后画 PCB 时,高频通讯线绝对不能和继电器控制线平行走线!”
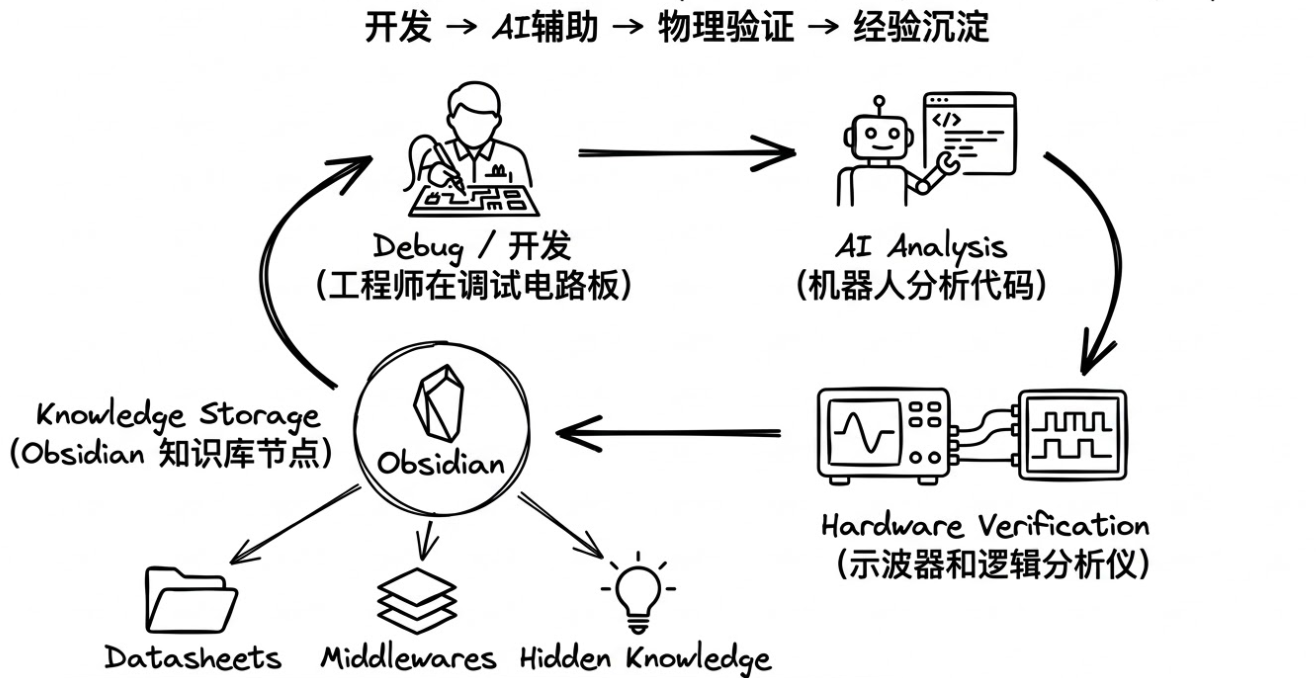
三、 核心工作流:捕获“隐性知识”
在真实的开发环境下,AI 的输出质量高度取决于你喂给它的上下文质量。我们将 Claude 的使用逻辑深度嵌入到嵌入式开发循环中,形成一个“输入 --> 碰撞 --> 沉淀”的闭环。
1. “冷启动”笔记模板:从调试到洞察
大多数工程师在解决 Bug 后,只会留下一个 Git Commit 记录。但在我们的系统中,每一次 Bug 修复都是一次“知识资产的增值”。
[模板案例:物理层异常记录]
# [BUG] 某型号 MCU 外部中断概率性丢失
- 物理现象: 示波器有波形,寄存器未触发。
- AI 的建议(显性): 检查配置、检查优先级、检查电平转换。
- 隐性真相(踩坑): 该批次芯片 IO 驱动能力不足,上拉电阻需从 10 k Ω 10k\Omega 10kΩ 改为 4.7 k Ω 4.7k\Omega 4.7kΩ。
- 底层逻辑: RC 电路充放电常数 τ = R C \tau = RC τ=RC 对高频信号的影响。
- 关联笔记: [[10_Datasheets/MCU_GPIO特性]] / [[50_Hidden_Knowledge/高频抗干扰指南]]
2. AI 协同:Claude 协同的核心流程:深度交互三部曲
不仅仅是“问问题”,而是要把 Claude 当作一个“代码审计师”和“架构顾问”。在 Obsidian 中,核心流程如下:
| 阶段 | 动作 | Claude 的核心作用 |
|---|---|---|
| 第一步:上下文注入 (Contextualize) | 复制 10_Datasheets 里的 AI 总结 + 当前代码片段给 Claude。 |
消除幻觉: 让 AI 基于你提供的硬件限制(如:Flash 等待周期、DMA通道冲突)进行思考,而非泛泛而谈。 |
| 第二步:苏格拉底式提问 (Dialogue) | 使用 40_AI_Prompts 里的模板:“分析这段驱动在 FreeRTOS 高频切换下,是否会因为临界区保护不足导致寄存器被重写?” |
深度探测: 引导 AI 去检查竞态条件(Race Condition)和内存屏障(Memory Barrier),这些是人类最易忽略的细节。 |
| 第三步:物理对齐 (Physical Alignment) | 关键环节: 将 AI 给出的重构方案下载到板子上,用示波器/逻辑分析仪验证。 | 去伪存真: 验证通过后,将方案存入 20_Middlewares;若失败,记录失败原因到 50_Hidden_Knowledge,并反馈给 Claude 修正逻辑。 |
3. 典型场景:利用 AI 捕捉“软件无法感知的硬件状态”
嵌入式开发最怕的是“逻辑上正确,物理上报错”。
操作示例:
你在 Obsidian 中打开 [[30_Product_Logs/低功耗唤醒失败]] 的日记,直接通过插件呼叫 Claude:
User: “Claude,根据我的
[[10_Datasheets/电源管理单元]]记录,进入深度睡眠需要 50 μ s \mu s μs 的稳压电容放电时间。请审查我的这段唤醒代码,是否在电源电压还没稳定到 3.3V 时就已经开始了 SPI 初始化?”
Claude 的反馈(示例):
“根据你提供的硬件上下文,确实存在风险。你的 SPI 配置在唤醒中断后的第 20 μ s \mu s μs 就触发了。此时 LDO 输出可能还在 2.8 V ∼ 3.1 V 2.8V \sim 3.1V 2.8V∼3.1V 摆动。重构建议: 在调用
SPI_Init()前增加一个基于硬件 Timer 的精确延时,或者轮询 PMU 寄存器的VCC_STABLE标志位。”
总结:为什么要通过这种流程“折磨”自己?
这种工作流初期看起来比“百度一下”要慢,但它在做两件极具长远价值的事:
- 训练 AI 的精准度: 你喂给它的结构化上下文越多,它给你的“嵌入式直觉”就越接近真实硬件。
- 构建你的护城河: 随着
50_Hidden_Knowledge(底蕴层)的丰满,你将拥有一个**“被物理现实验证过”**的私有知识库。这让你在面对新芯片时,不是从零开始,而是带着几百条“经过验证的原则”去俯视新架构。
四、 思维模型:如何实现 10x 效率?
为了避免“虚假掌控感”,我们需要在系统中嵌入两个思维模型:
1. 负向推演模型 (Pre-mortem)
在产品打样前,问 Claude:“假设这款智能锁在量产 1000 台后,出现了电池寿命缩短 50% 的问题,请推测最可能的 3 个硬件设计疏忽点。” 将这些点存入你的 50_Hidden_Knowledge。
2. 知识杠杆模型
个人竞争力 = ( 私有笔记的颗粒度 ) × ( AI 的逻辑推演速度 ) \text{个人竞争力} = (\text{私有笔记的颗粒度}) \times (\text{AI 的逻辑推演速度}) 个人竞争力=(私有笔记的颗粒度)×(AI 的逻辑推演速度)
你的笔记越细(颗粒度高),AI 帮你生成的方案就越精准。
五、 结语:从“用工具”到“养外脑”
工具的进化是为了解放我们的双手,让我们去思考更本质的问题:产品的温度、用户的习惯、以及技术的边界。
通过这套 Obsidian 模板,你不仅是在记录代码,更是在“喂养”一个懂你思维逻辑、懂你硬件平台的数字孪生体。当 AI 抹平了信息差,这套包含了你无数次凌晨调试经验的“私有知识库”,就是你对抗平庸的最高壁垒。
自我激励:AI 不会替代工程师,但会替代不会使用 AI 的工程师。
六、相关推荐

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)