【AI大模型前沿】Fun-Audio-Chat:阿里巴巴开源的高效语音交互大模型
Fun-Audio-Chat 是一款专注于自然、低延迟语音交互的大型音频语言模型。它通过引入双分辨率语音表征(5Hz 的高效共享主干 + 25Hz 的精细头部)大幅降低计算成本,同时保持高质量语音输出,并采用 Core-Cocktail 训练策略保留强大的文本语言模型能力。该模型在口语问答、音频理解、语音功能调用、语音指令跟随和语音共情等多个基准测试中均取得了顶尖成绩。
系列篇章💥
目录
前言
随着人工智能技术的不断发展,语音交互领域逐渐成为研究热点。Fun-Audio-Chat 是阿里巴巴通义百聆团队开源的新一代端到端语音交互模型,它凭借独特的双分辨率设计和高效的 Core-Cocktail 训练策略,在语音理解、情感感知和任务执行等方面展现出卓越性能,为语音交互领域带来了新的突破。
一、项目概述
Fun-Audio-Chat 是一款专注于自然、低延迟语音交互的大型音频语言模型。它通过引入双分辨率语音表征(5Hz 的高效共享主干 + 25Hz 的精细头部)大幅降低计算成本,同时保持高质量语音输出,并采用 Core-Cocktail 训练策略保留强大的文本语言模型能力。该模型在口语问答、音频理解、语音功能调用、语音指令跟随和语音共情等多个基准测试中均取得了顶尖成绩。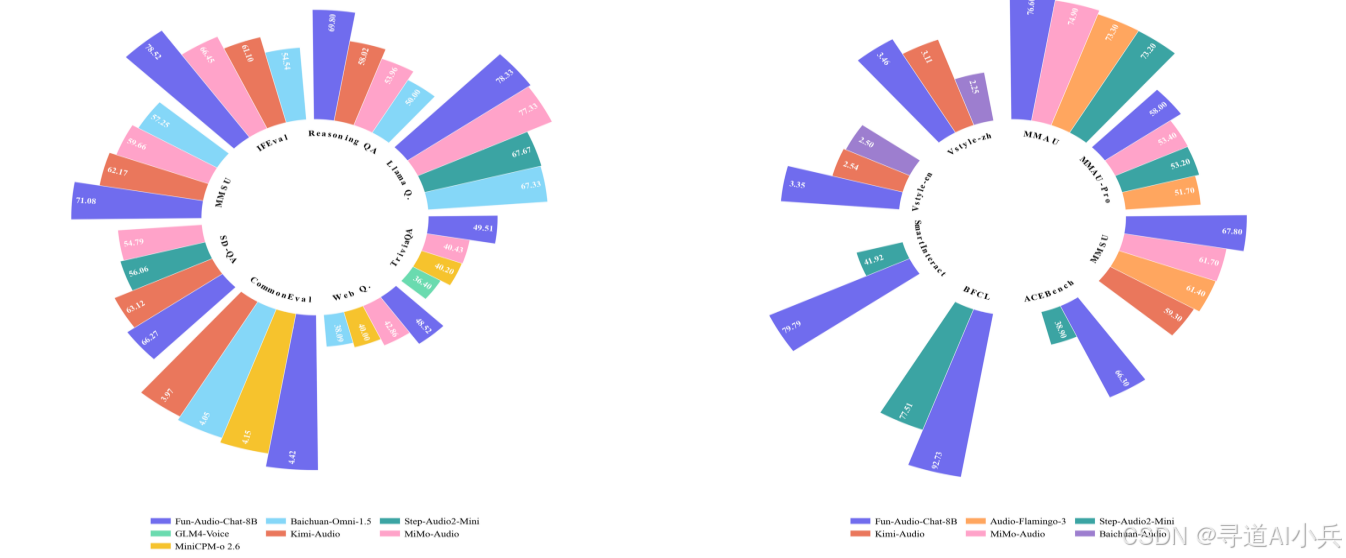
二、核心功能
(一)端到端语音交互
Fun-Audio-Chat 采用端到端的语音交互模式,直接从语音输入生成语音输出,无需传统模式中的语音识别(ASR)+ 语言模型(LLM)+ 文本转语音(TTS)的多模块拼接,从而实现更高的效率和更低的延迟。
(二)情绪感知与情感回应
该模型能够通过用户的语义、语气、语速、停顿等细节感知用户的情绪状态,并在用户生气、焦虑或开心时,给出恰到好处的安慰、陪伴或共鸣,提供类似朋友的对话体验。
(三)自然语音指令执行
Fun-Audio-Chat 支持 Speech Function Call 功能,用户只需用自然语音下达指令,系统能自动调用相关函数完成复杂任务,如设置闹钟、查询天气等。
三、技术揭秘
(一)端到端 S2S 架构
Fun-Audio-Chat 采用 Speech-to-Speech(S2S)端到端架构,直接从语音输入生成语音输出,无需传统的 ASR + LLM + TTS 多模块拼接。这种架构显著提升了处理效率,降低了系统延迟,实现了更流畅的语音交互体验。
(二)双分辨率设计
模型采用创新的双分辨率处理机制:Shared LLM 层以 5Hz 帧率进行高效语义处理,而 SRH(Speech Reconstruction Head)以 25Hz 帧率生成高质量语音。在保证语音质量的同时,将 GPU 计算开销降低了近 50%,实现了性能与效率的平衡。
(三)Core-Cocktail 训练策略
Fun-Audio-Chat 采用 Core-Cocktail 两阶段训练策略。第一阶段,模型在多任务数据上进行预训练,学习语音和文本的语义信息;第二阶段,模型在特定任务数据上进行微调,进一步提升性能。这种训练策略有效避免了灾难性遗忘,同时保留了强大的文本语言模型能力。
(四)海量多任务数据训练
Fun-Audio-Chat 经过数百万小时的多任务数据精心训练,覆盖了音频理解、语音问答、情感识别、工具调用等丰富多样的真实应用场景。这使得模型能够更“接地气”地理解用户意图,并在多个权威榜单上拔得头筹。
四、应用场景
(一)语音聊天
Fun-Audio-Chat 能与用户进行自然流畅的语音对话,提供类似真人交流的体验。它支持多种语言,能够理解并回应各种话题,适合日常聊天和社交互动,让用户感受到仿佛与朋友面对面交流的亲切感。
(二)情感陪伴
模型具备强大的情感感知能力,能够通过语气、语速等细节感知用户的情绪状态,并给予恰当的安慰、鼓励或共鸣。例如,当用户感到孤独或焦虑时,它会提供温暖的陪伴,帮助用户缓解情绪。
(三)智能设备控制
用户可以通过语音指令控制智能设备,如智能家居、智能穿戴等。Fun-Audio-Chat 能理解自然语音指令并执行相关操作,实现更便捷的操作体验,无需手动操作设备,提升生活和工作的智能化水平。
(四)语音客服
在客服场景中,Fun-Audio-Chat 能够理解用户的问题并提供准确的回答,提升客服效率和用户体验。它能够快速响应用户需求,解决常见问题,减轻人工客服的工作负担,同时为用户提供更高效的服务。
(五)角色扮演
用户可以指定 Fun-Audio-Chat 扮演特定角色,如电竞解说员、虚拟助手等,以满足不同的娱乐或工作需求。模型能够根据角色特点调整语音风格和回答方式,为用户提供沉浸式的角色互动体验。
五、快速使用
(一)环境准备
确保系统已安装 ffmpeg,推荐使用 conda 隔离环境:
conda create -n FunAudioChat python=3.12 -y
conda activate FunAudioChat
pip install torch==2.8.0 torchaudio==2.8.0 --index-url https://download.pytorch.org/whl/cu128
git clone --recurse-submodules https://github.com/FunAudioLLM/Fun-Audio-Chat
cd Fun-Audio-Chat
pip install -r requirements.txt
(二)下载模型
两种途径任选其一:
pip install huggingface-hub
hf download FunAudioLLM/Fun-Audio-Chat-8B --local-dir ./pretrained_models/Fun-Audio-Chat-8B
hf download FunAudioLLM/Fun-CosyVoice3-0.5B-2512 --local-dir ./pretrained_models/Fun-CosyVoice3-0.5B-2512
或者:
modelscope download --model FunAudioLLM/Fun-Audio-Chat-8B --local_dir pretrained_models/Fun-Audio-Chat-8B
modelscope download --model FunAudioLLM/Fun-CosyVoice3-0.5B-2512 --local_dir pretrained_models/Fun-CosyVoice3-0.5B-2512
完成后目录结构如下:
pretrained_models/
├── Fun-Audio-Chat-8B/ # 主模型
└── Fun-CosyVoice3-0.5B-2512/ # 去分词器
(三)运行基础推理
在项目根目录执行:
export PYTHONPATH=`pwd`
python examples/infer_s2t.py
python examples/infer_s2s.py
infer_s2t.py 默认使用 utils/constant.py 中的 DEFAULT_S2T_PROMPT,可手动修改以适应不同任务。
(四)启动 Web 演示
服务端(推荐用第二块 GPU):
pip install sphn aiohttp
python -m web_demo.server.server --model-path pretrained_models/Fun-Audio-Chat-8B --port 11236 --tts-gpu 1
客户端(Node.js):
cd web_demo/client
nvm use
openssl req -x509 -newkey rsa:4096 -keyout key.pem -out cert.pem -days 365 -nodes
echo "VITE_QUEUE_API_PATH=/api" > .env.local
npm install
npm run dev
六、结语
Fun-Audio-Chat 作为一款开源的语音交互大模型,凭借其高效的双分辨率设计和强大的 Core-Cocktail 训练策略,在语音交互领域展现出了巨大的潜力和优势。它不仅在多个基准测试中取得了优异的成绩,还具备丰富的应用场景和良好的易用性。未来,随着技术的进一步发展和优化,Fun-Audio-Chat 必将在语音交互领域发挥更重要的作用,为人们的生活和工作带来更多便利。
项目地址:
- 项目官网:https://funaudiollm.github.io/funaudiochat/
- Github 仓库:https://github.com/FunAudioLLM/Fun-Audio-Chat
- HuggingFace 模型库:https://huggingface.co/FunAudioLLM/Fun-Audio-Chat-8B
- 技术论文:https://github.com/FunAudioLLM/Fun-Audio-Chat/blob/main/Fun-Audio-Chat-Technical-Report.pdf

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)