LangChain文档加载器实战,轻松搞定PDF/Markdown/Word
本文系统介绍了检索增强生成(RAG)技术的核心原理与实践流程,指出其通过结合外部知识库与大模型能力,有效解决了模型知识时效性不足与私有数据泄露风险。文章详述了RAG“离线构建”(文档加载、文本分割、向量存储)与“在线检索”(查询向量化、相似度搜索、答案生成)的两阶段流程,并重点讲解了LangChain框架下文档加载器的关键作用——将PDF、Markdown、Word等异构文档统一转换为包含内容与元
文章目录

1. RAG 介绍(Retrieval-Augmented Generation,检索增强生成)
1.1 RAG 概念
RAG 通过外部知识库来增强大模型的能力,为了更好的理解 RAG,我们从 AI 搜索的角度来理解:
对于【AI 大模型】来说,它能提供的知识是训练数据中包含的,属于长期记忆的知识库。因为方式模型的训练数据取决于训练的截止日期,所以模型的知识是有时效性的。
对于【检索引擎】来说,它能提供的是搜索数据取决于的知识库,就是最新信息分类,每次都能返回最为相关的信息。
大模型与搜索引擎的结合,就是最新的 AI 搜索工具了,让 AI 能够了解了不在本子符串,大模型也可以从搜索引擎中获取最新的信息,从而提供更准确的答案。
下图展示了一个典型的 AI 搜索工作流程:
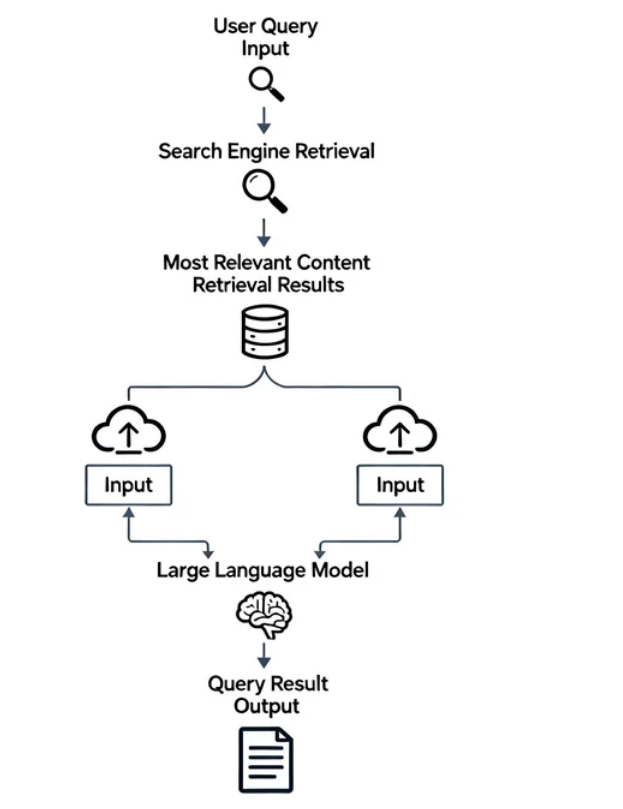
有了以上流程的描述,接下来,正式进入 RAG 的学习。
RAG 知识库可以是一个问答系统,也可以是一个文档库,或者是一个数据库。根据用户的输入,组装成相关的文档,然后将这些文档输入到大模型中,大模型根据这些文档生成答案。
只能根据我们给的文档内容进行回答,而不能根据自己的知识库进行回答,这样就能保证答案的准确性,也能保证答案的私有性,避免泄露公司内部的私有数据,提高了数据的安全性。
客观地说,RAG(检索增强生成)技术上,当前用户 LLM 提问时,系统首先在知识库(如公司内部文档)中进行文本检索,找到相关的文档内容,然后将这些相关文档作为上下文输入给 LLM,最后 LLM 基于这些文档内容生成答案,从而确保回答的准确性和私有性。这样既能利用 LLM 的生成能力,又能限制其只根据提供的文档回答,避免泄露公司内部的私有数据,提高了数据的安全性。
1.2 RAG 流程
上面提到,RAG 知识库可以以【离线构建】和【在线检索】两个过程。RAG 的流程可以分为以下几个步骤:
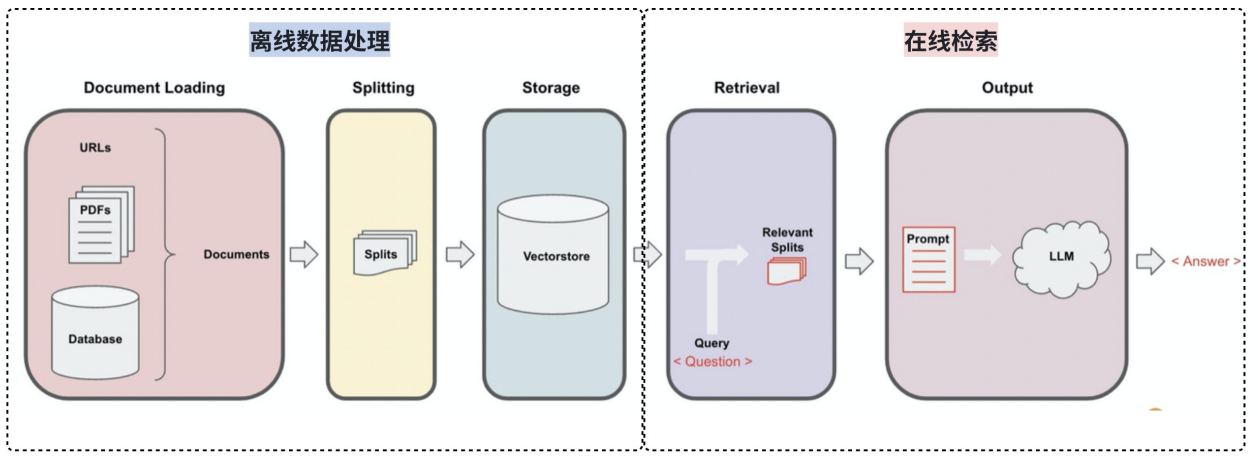
离线构建流程:
-
文档加载(Document Loading):加载各种格式的源文档,LangChain 提供了 100 多种不同的文档加载器,包括 PDF 在内的非结构化数据格式、SQL 在内的结构化数据格式,以及 Python、Java 之类的代码等。
-
文本分割(Splitting):文本分割器把 Documents 切分为指定大小的小块。
-
存储(Storage):存储是为了后续方便查询,分两部分:
- 将分割好的文本块输入(Embedding):即把文本转换成向量表示形式
- 将 Embedding 后的向量数据,存储到向量数据库中
在线检索流程:
-
检索(Retrieval):数据库入库完成后,当有用户输入查询时,会通过相同的 Embedding 模型将查询转换成向量,在向量数据库中进行相似度搜索,找到最相关的文档块。
-
输出(Output):把问题以及检索出来的文档块一起输入给 LLM,LLM 会综合问题和检索到的相关文档块来生成最终答案。
2. 文档加载器(Document Loaders)
我们现在已经知道了 RAG 的完整流程,但是仅仅知道 RAG 操作了,关于仅仅知道 RAG 操作了,关于流程中的关键步骤,文本分割、存储、检索、输出等,LangChain 组件都对应了不同的实现方式,接下来我们就来学习这些组件。
这些组件会按照下图的顺序来学习,所有组件都是基于 LangChain 框架来实现的:
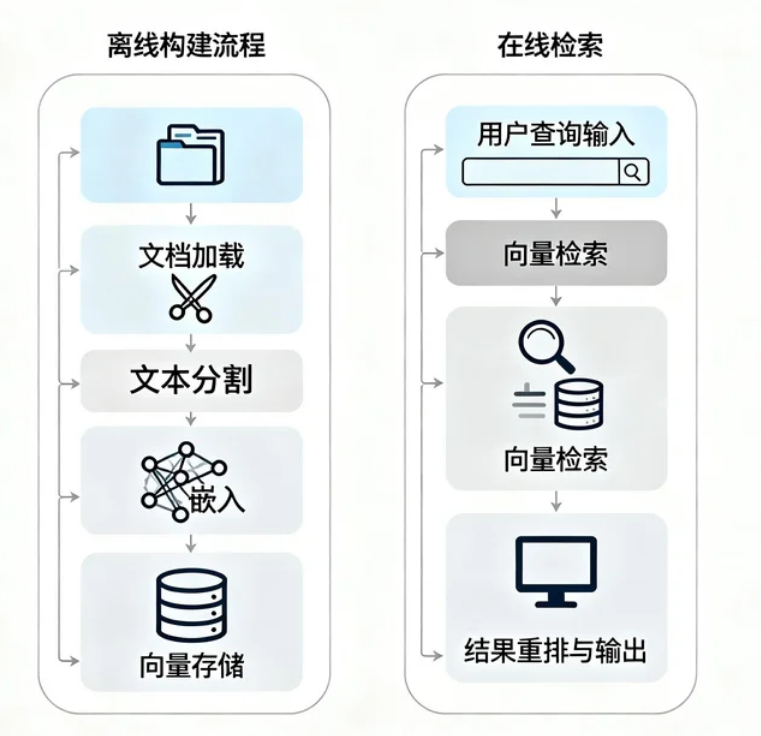
这张图展示了完整的 RAG 流程中各个组件的关系,所有组件都是基于 LangChain 框架来实现的,所以我们接下来就来学习 LangChain 组件都对应了不同的实现方式。
2.1 什么是文档加载器?
文档加载器(Document Loaders):加载各种格式的源文档。LangChain 提供了 100 多种不同的文档加载器,包括:
- PDF 在内的非结构化数据格式
- SQL 在内的结构化数据格式
- Python、Java 之类的代码等
文档加载器的作用就是将不同格式的文档转换为 LangChain 可以处理的 Document 对象。
2.2 Document 对象
在 LangChain 中,Document 是一个核心数据结构,包含两个主要属性:
- page_content:文档的文本内容
- metadata:文档的元数据(如来源、页码等)
2.2.1 创建 Document 对象
# 基于document的文档加载器
from langchain_core.documents import Document
# 构造document对象
document = [
Document(page_content="这是一个文档", metadata={"source": "本地"}),
Document(page_content="这是第二个文档", metadata={"source": "本地"}),
]
# 打印document对象
print(document)
代码说明:
- 直接使用
Document类创建文档对象 page_content存储文档内容metadata存储文档的元信息
3. 常用文档加载器
3.1 Markdown 文档加载器
Markdown 是一种轻量级标记语言,广泛用于文档编写。LangChain 提供了专门的 Markdown 加载器。
3.1.1 安装依赖
pip install "unstructured[md]" nltk
python -m spacy download en_core_web_sm
3.1.2 代码示例
# 基于markdown的文档加载器
from langchain_community.document_loaders.markdown import UnstructuredMarkdownLoader
from langchain_core.documents import Document
# 定义加载对象,默认是single document
loader = UnstructuredMarkdownLoader(
"Claude-Skills实战:从安装到实践.md",
mode="elements" # 加载模式
)
# 加载文档
documents = loader.load()
# 打印文档信息
print(f"文档数量: {len(documents)}")
print(f"第一个文档的元数据: {documents[0].metadata}")
print(f"第一个文档的内容: {documents[0].page_content}")
# 打印所有文档内容
for doc in documents:
print(doc.page_content)
print("\n ------------------\n")
3.1.3 加载模式说明
- mode=“single”:将整个文档作为一个 Document 对象加载
- mode=“elements”:按元素(标题、段落、列表等)分别加载,每个元素是一个 Document 对象
选择建议:
- 如果文档较小或需要整体处理,使用
single模式 - 如果文档较大或需要按结构处理,使用
elements模式
3.2 PDF 文档加载器
PDF 是最常见的文档格式之一,LangChain 提供了多种 PDF 加载器。
3.2.1 安装依赖
pip install pypdf
3.2.2 代码示例
# 基于pdf的文档加载器
from langchain_community.document_loaders import PyPDFLoader
# 定义加载对象,默认是加载成多个document(每页一个)
loader = PyPDFLoader("基于微服务的即时通讯系统.pdf")
# 加载文档
documents = loader.load()
# 打印文档信息
print(f"文档数量: {len(documents)}")
print(f"第一个文档的元数据: {documents[0].metadata}")
print(f"第一个文档的内容: {documents[0].page_content}")
# 打印所有文档内容
for i, doc in enumerate(documents, 1):
print(f"--- 第 {i} 页 ---")
print(doc.page_content)
print("\n")
3.2.3 PyPDFLoader 特点
- 自动分页:每一页 PDF 会被加载为一个独立的 Document 对象
- 元数据:自动提取页码、文件路径等信息
- 文本提取:自动提取 PDF 中的文本内容
metadata 示例:
{
'source': '基于微服务的即时通讯系统.pdf',
'page': 0 # 页码从0开始
}
4. 其他常用文档加载器
LangChain 提供了 100+ 种文档加载器,以下是一些常用的:
4.1 文本文件加载器
from langchain_community.document_loaders import TextLoader
loader = TextLoader("example.txt", encoding="utf-8")
documents = loader.load()
4.2 CSV 文件加载器
from langchain_community.document_loaders import CSVLoader
loader = CSVLoader("data.csv")
documents = loader.load()
4.3 JSON 文件加载器
from langchain_community.document_loaders import JSONLoader
loader = JSONLoader(
file_path="data.json",
jq_schema=".messages[].content", # 使用 jq 语法提取数据
text_content=False
)
documents = loader.load()
4.4 网页加载器
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://example.com")
documents = loader.load()
4.5 Word 文档加载器
from langchain_community.document_loaders import Docx2txtLoader
loader = Docx2txtLoader("example.docx")
documents = loader.load()
5. 文档加载器的通用方法
所有文档加载器都实现了以下通用方法:
5.1 load() 方法
documents = loader.load()
- 一次性加载所有文档
- 返回
List[Document] - 适合小文件
5.2 lazy_load() 方法
for document in loader.lazy_load():
print(document.page_content)
- 逐个加载文档(生成器模式)
- 节省内存
- 适合大文件
6. 实践建议
6.1 选择合适的加载器
| 文档类型 | 推荐加载器 | 特点 |
|---|---|---|
| PyPDFLoader | 自动分页,提取文本 | |
| Markdown | UnstructuredMarkdownLoader | 支持结构化解析 |
| Word | Docx2txtLoader | 简单易用 |
| 网页 | WebBaseLoader | 自动爬取网页内容 |
| CSV | CSVLoader | 每行作为一个文档 |
| JSON | JSONLoader | 支持 jq 语法提取 |
6.2 处理大文件
对于大文件,建议:
- 使用
lazy_load()方法 - 配合文本分割器使用
- 分批处理文档
6.3 元数据的重要性
元数据在 RAG 中非常重要:
- 用于文档溯源
- 用于过滤和筛选
- 用于构建上下文
示例:
# 添加自定义元数据
loader = PyPDFLoader("example.pdf")
documents = loader.load()
for doc in documents:
doc.metadata["category"] = "技术文档"
doc.metadata["author"] = "张三"
7. 常见问题
7.1 中文乱码问题
# 指定编码
loader = TextLoader("example.txt", encoding="utf-8")
7.2 PDF 提取不完整
- 使用
PyMuPDFLoader替代PyPDFLoader - 或使用
PDFPlumberLoader
from langchain_community.document_loaders import PyMuPDFLoader
loader = PyMuPDFLoader("example.pdf")
documents = loader.load()
7.3 权限问题
某些文档加载器需要额外的系统权限或依赖:
- Markdown 需要 spacy 模型
- PDF 需要 poppler(某些系统)
- 网页需要网络访问权限
8. 总结
文档加载器是 RAG 流程的第一步,主要作用是:
- 统一格式:将不同格式的文档转换为 Document 对象
- 提取内容:从源文档中提取文本内容
- 保留元数据:记录文档来源、页码等信息
关键要点:
- 选择合适的加载器
- 注意编码问题
- 合理使用元数据
- 大文件使用 lazy_load()
9. 参考资源

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 96
96 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)