第三章 卷积神经网络
第三章 卷积神经网络:计算机视觉的核心架构
一、卷积基础
1. 卷积的定义与数学表示
卷积是卷积神经网络的核心操作,主要功能是在图像或特征上滑动卷积核(滤波器),提取新的特征。根据维度不同可分为:
一维卷积

用于信号处理中的延迟累积计算:
yt=∑k=1Kwkxt−k+1 y_t=\sum_{k=1}^{K} w_k x_{t-k+1} yt=k=1∑Kwkxt−k+1
- 移动平均滤波器:
w=[1/K,\cdots,1/K]可平滑信号 - 微分滤波器:
w=[1,-2,1]可近似信号二阶微分

二维卷积

用于图像处理:
yij=∑u=1U∑v=1Vwuvxi−u+1,j−v+1 y_{ij}=\sum_{u=1}^{U}\sum_{v=1}^{V} w_{uv} x_{i-u+1,j-v+1} yij=u=1∑Uv=1∑Vwuvxi−u+1,j−v+1
图像处理中常用滤波器:
- 均值滤波:区域像素平均值
- 边缘检测:提取图像轮廓
- 锐化滤波:增强图像细节

2. 互相关操作
在深度学习实现中,常用互相关代替严格数学定义的卷积:
yij=∑u=1m∑v=1nwuv⋅xi+u−1,j+v−1 y_{ij}=\sum_{u=1}^{m}\sum_{v=1}^{n} w_{uv}\cdot x_{i+u-1,j+v-1} yij=u=1∑mv=1∑nwuv⋅xi+u−1,j+v−1
互相关与卷积的区别仅在于卷积核是否翻转,这种实现减少了不必要的操作开销,且特征提取能力相同。

3. 卷积的变种
步长与填充

-
步长(S):卷积核滑动间隔
-
零填充§:输入边界补零数量
-
输出尺寸公式:
O=I−K+2PS+1 O=\frac{I-K+2P}{S}+1 O=SI−K+2P+1
不同配置示例:
- 窄卷积:S=1, P=0
- 等宽卷积:S=1, P=(K-1)/2
- 步长2卷积:S=2, P=0或P=1


4. 高级卷积技术
转置卷积(反卷积)
将低维特征映射到高维空间,常用于图像分割和生成任务:
- 通过插入零值实现上采样
- 卷积核尺寸为K时,需补零P=K-1


空洞卷积
不增加参数数量而扩大感受野:
-
在卷积核元素间插入D-1个空洞
-
有效卷积核尺寸:
K′=K+(K−1)×(D−1) K'=K+(K-1)\times(D-1) K′=K+(K−1)×(D−1)

二、卷积神经网络结构
1. 核心组件
卷积层
-
功能:提取局部区域特征
-
计算过程:
Zp=∑d=1DWp,d⊗Xd+bpYp=f(Zp) \begin{aligned}&Z^{p}=\sum_{d=1}^{D}W^{p,d}\otimes X^{d}+b^{p}\\ &Y^{p}=f(Z^{p})\end{aligned} Zp=d=1∑DWp,d⊗Xd+bpYp=f(Zp) -
特性:
- 局部连接:每个神经元仅连接局部窗口
- 权重共享:同特征映射共享卷积核

汇聚层(池化层)

- 功能:特征降维与不变性增强
- 类型:
- 最大池化:提取最显著特征
- 平均池化:保留区域平均信息
- 作用:
- 减少参数数量
- 增强平移不变性
- 防止过拟合
2. 整体架构
典型卷积网络结构:

- 卷积块:连续M个卷积层(M=2~5)+ 0或1个汇聚层
- 发展趋势:
- 使用更小卷积核(1×1, 3×3)
- 更深层结构(>50层)
- 减少汇聚层比例
三、参数学习
1. 梯度计算

卷积网络通过反向传播算法计算参数梯度:
-
损失函数关于卷积核的梯度:
∂L∂W(l,p,d)=δ(l,p)⊗X(l−1,d) \frac{\partial\mathcal{L}}{\partial W^{(l,p,d)}}=\delta^{(l,p)}\otimes X^{(l-1,d)} ∂W(l,p,d)∂L=δ(l,p)⊗X(l−1,d) -
损失函数关于偏置的梯度:
∂L∂b(l,p)=∑i,j[δ(l,p)]i,j \frac{\partial\mathcal{L}}{\partial b^{(l,p)}}=\sum_{i,j}\left[\delta^{(l,p)}\right]_{i,j} ∂b(l,p)∂L=i,j∑[δ(l,p)]i,j
2. 池化层反向传播
不同类型池化层的误差传播:
- 最大池化:误差仅传递给最大值位置
- 平均池化:误差平均分配到所有位置

3. 自动梯度计算
现代框架实现方式:
- 数值微分:近似计算,效率低
- 符号微分:编译时优化表达式
- 自动微分:
- 前向模式:与计算方向相同
- 反向模式:与计算方向相反(效率更高)
四、典型卷积网络
1. LeNet-5
- 历史地位:首个成功应用的卷积网络(1998)
- 结构:7层网络(2卷积+2池化+3全连接)
- 应用:银行支票手写数字识别

2. AlexNet
- 突破创新(2012 ImageNet冠军):
- 首次使用ReLU激活函数
- 引入Dropout防止过拟合
- 采用数据增强技术
- 使用GPU并行训练
- 结构:5卷积层+3池化层+3全连接层


3. Inception系列

Inception v1 (GoogLeNet)
- 核心思想:并行多尺度卷积
- 同时使用1×1、3×3、5×5卷积核
- 特征映射深度拼接
- 创新点:
- 引入1×1卷积降维
- 辅助分类器防止梯度消失
- 性能:2014 ImageNet冠军(6.7%错误率)

Inception v3
- 改进:
- 用两层3×3卷积替代5×5卷积
- 用n×1+1×n卷积替代n×n卷积
- 引入批量归一化

4. ResNet

-
核心创新:残差连接
H(x)=F(x)+x \mathcal{H}(x)=\mathcal{F}(x)+x H(x)=F(x)+x -
优势:
- 解决深度网络梯度消失
- 允许训练超过1000层的网络
-
性能:2015 ImageNet冠军(3.6%错误率)

5. SENet
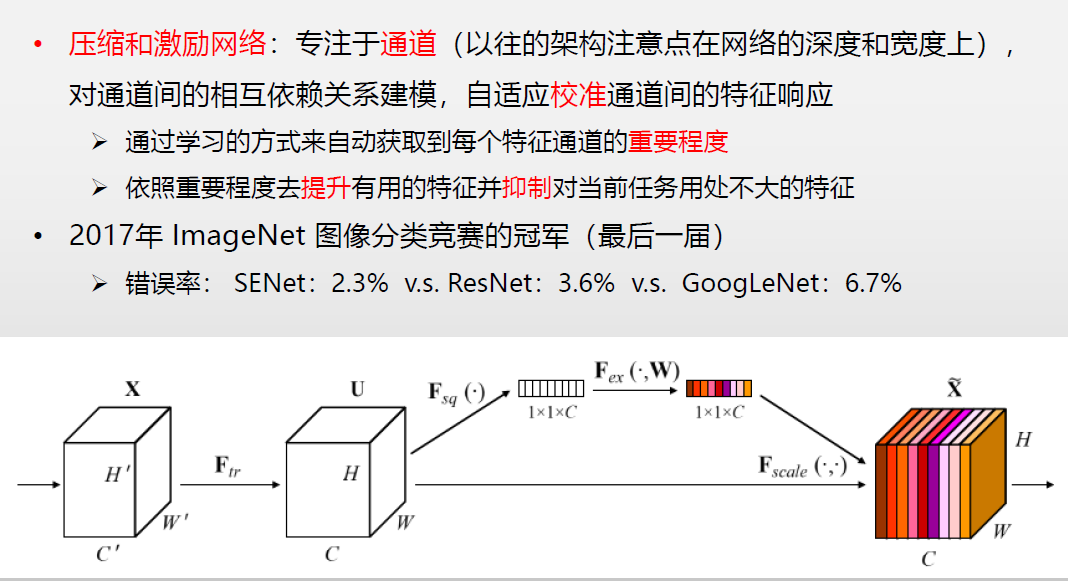
- 创新点:通道注意力机制
- Squeeze:全局平均池化获取通道信息
- Excitation:学习通道间依赖关系
- 性能:2017 ImageNet冠军(2.3%错误率)

6. DenseNet

-
核心思想:密集连接
xl=Hl([x0,x1,⋯ ,xl−1]) x_l=H_l([x_0,x_1,\cdots,x_{l-1}]) xl=Hl([x0,x1,⋯,xl−1]) -
优势:
- 特征重用,减少参数
- 缓解梯度消失
-
结构特点:
- 跨层特征拼接(Concatenation)
- 瓶颈层设计(1×1卷积降维)

五、总结
卷积神经网络通过局部连接、权重共享和空间降采样等机制,有效解决了全连接网络处理图像时的参数爆炸和局部不变性问题。从LeNet-5到DenseNet的发展历程中,网络架构经历了多尺度并行处理(Inception)、残差学习(ResNet)、通道注意力(SENet)和密集连接(DenseNet)等重要创新,不断突破深度学习的性能边界。
这些架构创新使卷积神经网络不仅在计算机视觉领域取得革命性进展,还成功应用于自然语言处理、推荐系统等多个领域,成为现代人工智能的核心技术之一。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 34
34 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)