人工智能芯片的整体构架设计
本文系统介绍了人工智能芯片的架构设计原理与实现方法。首先从计算原理出发,详细阐述了深度学习中的张量运算、并行化计算架构以及三级存储结构的设计理念。接着,文章具体分析了人工智能芯片的实现步骤,包括计算架构中的脉动阵列设计、存储架构的优化策略、互联网络的设计方法以及量化压缩技术。最后探讨了时域和空域两种不同的计算架构设计思路,展示了脉冲编码和并行处理等创新技术。全文通过数学公式和工程实例,全面展现了人
目录
随着人工智能技术的迅猛发展,对计算能力的需求呈指数级增长。人工智能芯片作为专门为人工智能算法和应用设计的芯片,其架构设计的优劣直接影响到人工智能系统的性能、能效和成本。与传统通用芯片不同,人工智能芯片旨在高效处理大规模数据和复杂计算,以满足深度学习、机器学习等人工智能应用的需求。
1.人工智能芯片架构设计原理
1.1 深度学习计算的数学原理
深度学习的核心运算可抽象为张量操作,其中矩阵乘法和卷积运算是最为基础和频繁的操作。在卷积神经网络(CNN)中,输入特征图与卷积核的卷积运算可表示为如下数学公式:
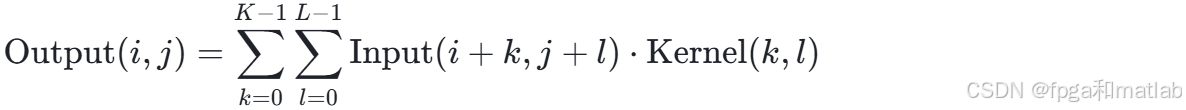
这里,Output(i,j) 是输出特征图在(i,j)位置的值,Input(i+k,j+l)是输入特征图在 (i+k,j+l)位置的值,Kernel(k,l)是卷积核在(k,l)位置的值,K和 L分别是卷积核的高度和宽度。
1.2 计算架构的并行化原理
为了提升计算效率,人工智能芯片普遍采用并行计算架构,其中脉动阵列(Systolic Array)架构是一种非常有效的方式。脉动阵列通过数据在处理单元(PE)间的流水化传递,实现矩阵乘法等运算的时空复用。脉动阵列的计算效率可以用以下公式表示:

其中,Throughput表示吞吐量,即单位时间内完成的运算量;Latency表示延迟,与脉动阵列的规模成正比。以Google TPU v3的72×72脉动阵列为例,其峰值算力可达420 TOPS(INT8)。通过这种并行化架构,芯片能够在一个时钟周期内完成大量的乘加运算,极大地加速了深度学习模型的训练和推理过程。
1.3 存储架构的分层设计
存储架构在人工智能芯片中起着至关重要的作用,合理的存储设计能够有效减少数据访问延迟,提高计算效率。典型的人工智能芯片采用三级存储结构:
片上SRAM:片上SRAM具有高速访问的特性,访问延迟通常在0.5 - 2ns之间。它主要用于暂存高频访问的数据,如正在处理的神经网络层的输入和输出数据,能够快速为计算单元提供数据,但其容量相对较小。
高带宽内存(HBM):HBM通过多通道设计和高速接口,能够提供GB/s级别的高带宽,满足芯片对大数据量的快速读写需求。其功耗可以用公式:
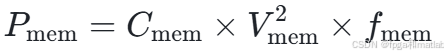
其中,Cmem是电容,Vmem是电压,fmem是频率。HBM在GPU等人工智能芯片中的应用,有效地避免了数据传输成为计算瓶颈。
外部DRAM:外部DRAM具有大容量的存储能力,可达GB级甚至更高,用于存储大量的训练数据和模型参数。然而,其访问延迟较高,通常在50 - 100ns之间。为了减少对外部DRAM的访问次数,芯片通常采用数据缓存、预取等技术,将常用的数据存储在片上SRAM或HBM中。
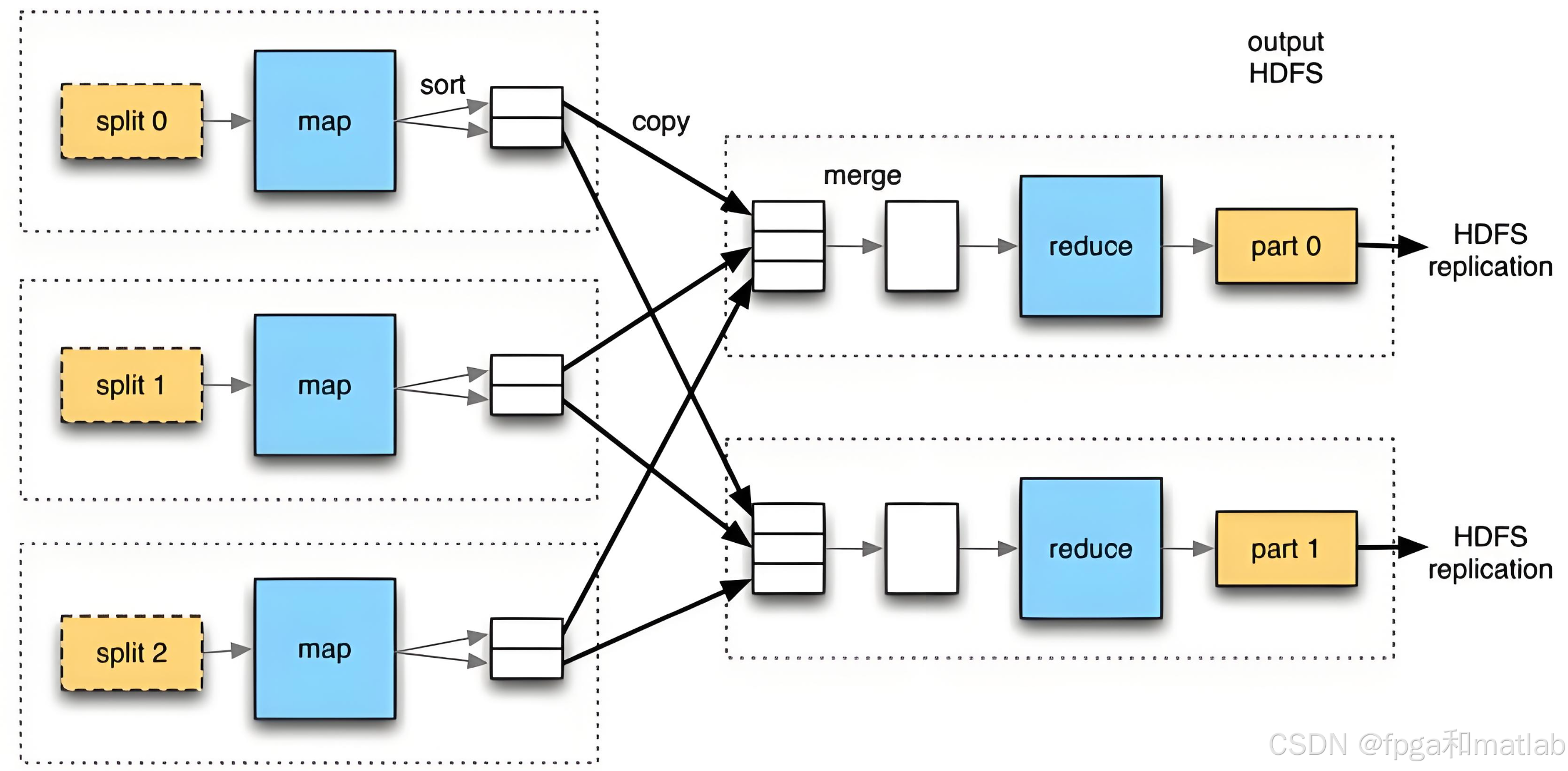
2.人工智能芯片架构设计实现步骤
2.1 计算架构
计算架构设计是人工智能芯片架构设计的核心环节,涉及到张量计算单元、并行处理机制等方面的设计。
脉动阵列设计:脉动阵列是一种高效的矩阵乘法计算架构,其设计涉及到对矩阵乘法时空复杂度的优化。通过循环展开等技术,脉动阵列可以将计算密度提升,其利用率可以用公式:
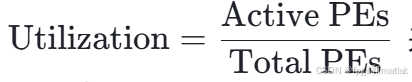
其中Active PEs是实际参与计算的处理单元数量,Total PEs是总的处理单元数量。通过合理的设计,利用率可以达到较高水平。
动态电压频率调整(DVFS):为了优化能效,人工智能芯片通常采用动态电压频率调整技术。功耗与性能之间存在着密切的关系,功耗公式为P=C×V2×f,且频率f与电压 V成正比。通过根据计算任务的负载动态调整电压和频率,可以在保证性能的前提下降低功耗。
在实现方法上,一般会采用Verilog/SystemVerilog等硬件描述语言来描述处理单元(PE)阵列,设计可配置的运算单元,以支持FP32/FP16/INT8等混合精度计算。例如,英伟达的GPU在计算架构设计上,通过不断优化张量核心的设计,实现了在一个时钟周期内完成大量矩阵乘法和累加运算的能力,从而极大地加速了深度学习模型的训练和推理过程。
2.2 存储架构
存储架构设计的目标是在满足计算需求的前提下,优化存储访问速度和容量,降低存储成本。
数据复用率:数据复用率是衡量存储架构效率的重要指标,其计算公式为:
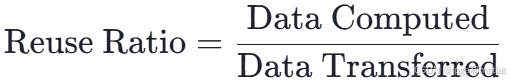
在典型的CNN中,数据复用率可达10-100倍。通过提高数据复用率,可以减少数据在存储层次之间的传输,从而降低功耗和延迟。
存算一体架构:存算一体架构是近年来的研究热点,其核心思想是将计算和存储功能融合在一起,减少数据传输开销。例如,电阻式存储器(RRAM)的电导变化模型可以用公式:
![]()
其中G(t)是时刻t的电导,G0是初始电导,ΔG是电导变化量,sgn(V(t))是电压的符号函数,τ是弛豫时间常数。基于这种模型,存算一体架构可以实现原位计算,提升计算效率。
在实现方法上,设计片上SRAM缓存层次,采用基于乒乓操作的双缓冲机制,以提高数据访问的并行性。同时,集成HBM控制器,支持3D堆叠封装技术,进一步提高存储带宽和容量。例如,一些人工智能芯片通过采用3D堆叠的HBM,将存储带宽提升到了TB/s级别,有效缓解了存储瓶颈。
2.3 互联架构
互联架构负责芯片内部各个组件之间的数据传输,其性能直接影响芯片的整体性能。
片上网络(NoC)延迟:片上网络的延迟可以用公式
![]()
其中,Hop Count是数据包传输经过的跳数,与片上网络的拓扑结构(如Mesh、Crossbar等)相关,Switch Delay是交换机延迟,Link Delay是链路延迟。通过优化拓扑结构和减少跳数,可以降低延迟。
全局异步局部同步(GALS):为了降低功耗,一些芯片采用全局异步局部同步的设计。其功耗公式为:
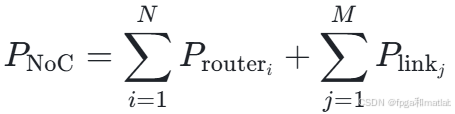
其中Prouteri是第i个路由器的功耗,Plinkj是第j条链路的功耗。通过这种设计,可以根据不同组件的工作频率和负载,独立控制各个局部区域的时钟,从而降低整体功耗。
在实现方法上,通常会采用Mesh或Crossbar等拓扑结构来构建片上网络,并设计自适应路由算法,以降低网络拥塞概率。例如,在一些大规模人工智能芯片中,采用 Mesh 拓扑结构结合自适应路由算法,能够在保证数据传输可靠性的同时,提高网络的传输效率。
2.4 量化与压缩
随着深度学习模型规模的不断增大,数据量和计算量也随之增加,量化与压缩技术成为降低存储和计算成本的关键。
对称量化公式:对称量化是一种常用的数据量化方法,其公式为:
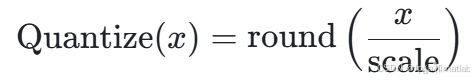
其中:
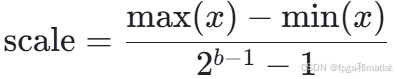
b为量化位宽。通过量化,可以将高精度的数据转换为低精度的数据,减少存储需求和计算量。
剪枝算法:剪枝算法通过去除神经网络中不重要的连接或神经元,实现模型的压缩。例如,通过 L1正则化实现权重稀疏,损失函数为:
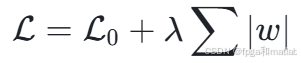
其中L0是原始损失函数,λ是正则化参数,w是权重。通过剪枝,可以减少模型的参数量,提高计算效率。
在实现方法上,通常会使用TensorRT等工具进行量化感知训练(QAT),在训练过程中考虑量化误差,以提高量化后模型的精度。同时,设计硬件支持稀疏矩阵运算,如COO/CSR等稀疏矩阵格式,进一步加速计算过程。
3.时域和空域设计架构
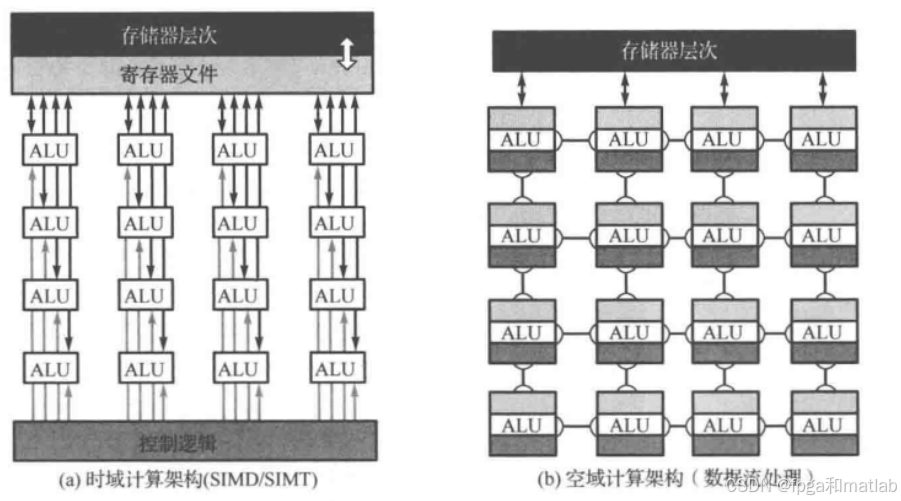
3.1 时域设计架构
时域设计架构是人工智能芯片设计中的一种重要架构,它通过时间域上的信号处理来实现计算任务。在时域存算一体芯片中,基于脉冲的计算方式具有较低的能耗。例如,清华大学设计的时域存算一体AI芯片TIMAQ,通过融合时域SRAM存内计算和数字可重构架构,克服了时域计算的一些瓶颈问题。
在时域计算中,数据通常以脉冲序列的形式表示,通过脉冲的宽度、频率或相位等特征来携带信息。以脉冲宽度调制(PWM)为例,数据值可以通过脉冲的宽度来编码,较宽的脉冲表示较大的数据值,较窄的脉冲表示较小的数据值。在进行乘法和累加运算时,通过对脉冲序列的处理来实现。例如,两个脉冲序列相乘,可以通过将它们的脉冲宽度进行相应的调制来实现,累加则可以通过对调制后的脉冲序列进行时间上的叠加来完成。
3.2 空域计算架构
空域计算架构主要关注在空间维度上的计算资源分配和数据处理。在人工智能芯片中,空域计算架构通常通过构建并行的计算单元来实现高效的数据处理。例如,在GPU中,拥有大量的流处理器(SP),这些流处理器可以并行处理不同的数据,从而实现大规模的并行计算。在空域计算中,数据被分配到不同的计算单元同时进行处理,通过充分利用空间上的并行性,提高芯片的计算效率。
空域计算架构的核心在于如何合理地划分计算任务和数据,使得各个计算单元能够高效地协同工作。例如,在处理图像数据时,可以将图像分割成多个子块,每个子块由不同的计算单元进行处理,然后将处理结果进行合并,得到最终的输出。这种方式能够充分利用芯片的计算资源,加快数据处理速度。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 19
19 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)