【完整源码+数据集+部署教程】肺炎类型检测系统源码和数据集:改进yolo11-CSP-EDLAN
【完整源码+数据集+部署教程】肺炎类型检测系统源码和数据集:改进yolo11-CSP-EDLAN
背景意义
肺炎作为一种常见的呼吸系统疾病,严重影响了全球范围内的公共健康。根据世界卫生组织的统计,肺炎每年导致数百万人的死亡,尤其是在儿童和老年人群体中。传统的肺炎诊断方法依赖于医生的临床经验和影像学检查,这不仅耗时且容易受到主观因素的影响。因此,开发一种高效、准确的肺炎类型检测系统显得尤为重要。
近年来,深度学习技术在医学影像分析领域取得了显著进展,尤其是目标检测和实例分割等任务。YOLO(You Only Look Once)系列模型因其快速的推理速度和较高的检测精度,成为了计算机视觉领域的热门选择。随着YOLOv11的推出,其在处理复杂场景和多类别目标检测方面的能力进一步增强,为肺炎类型的自动检测提供了新的可能性。本研究旨在基于改进的YOLOv11模型,构建一个肺炎类型检测系统,能够准确识别高肺炎、低肺炎和无肺炎三种类别。
本项目所使用的数据集包含9200幅胸部影像,涵盖了三种肺炎类型的标注信息。这一数据集的丰富性和多样性为模型的训练和验证提供了坚实的基础。通过对这些影像进行实例分割,系统能够在不同的肺炎类型中进行更精细的区分,从而提高诊断的准确性和可靠性。此外,改进的YOLOv11模型在处理速度上的优势,将有助于在临床环境中实现实时检测,进而提高医疗服务的效率。
综上所述,基于改进YOLOv11的肺炎类型检测系统不仅具有重要的学术价值,也为实际医疗应用提供了新的解决方案。通过提升肺炎的早期诊断能力,有望降低疾病的死亡率,改善患者的生活质量,进而为公共健康做出积极贡献。
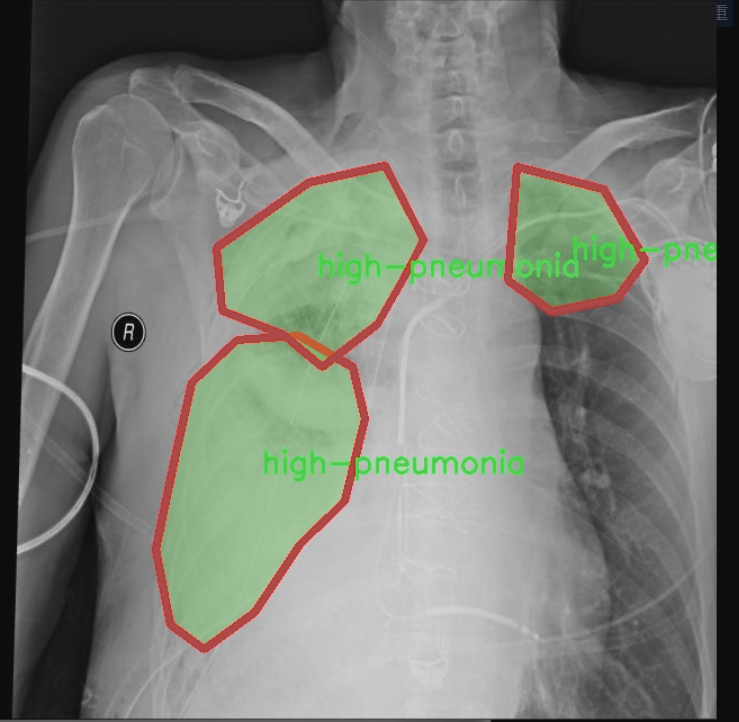
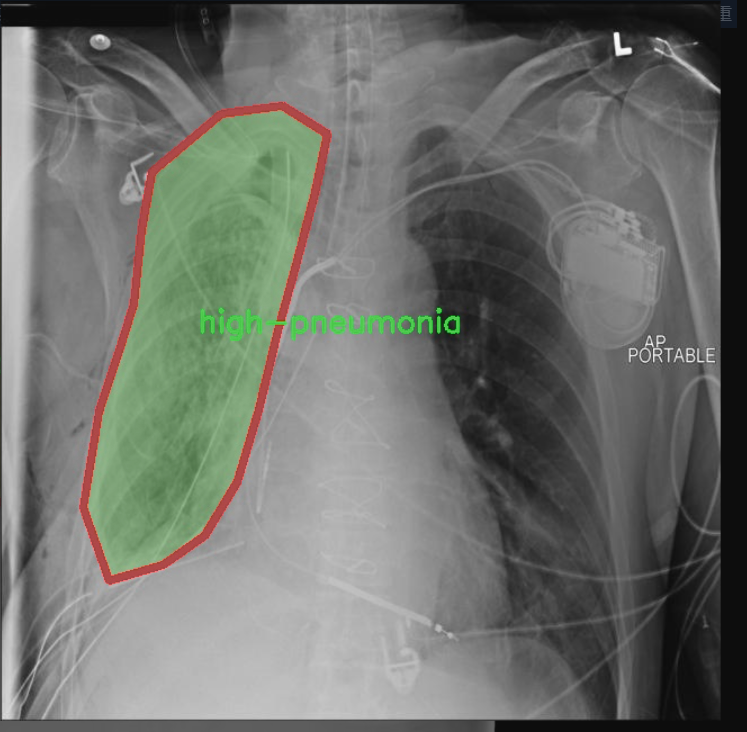
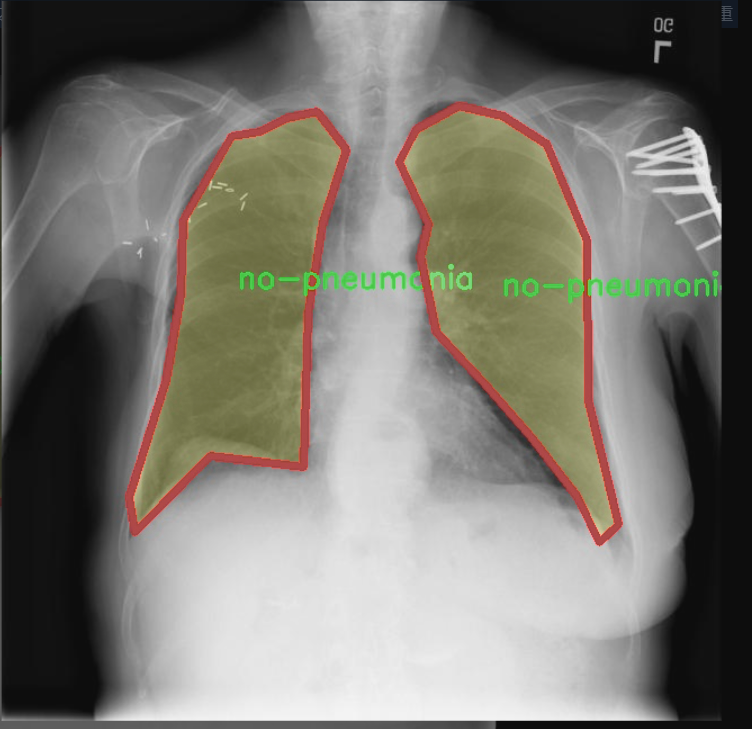
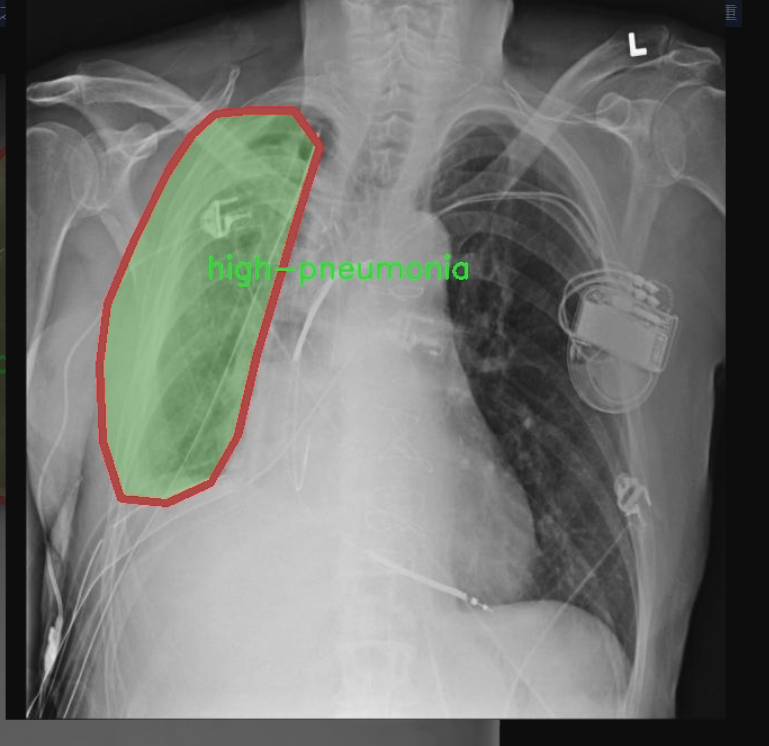
图片效果
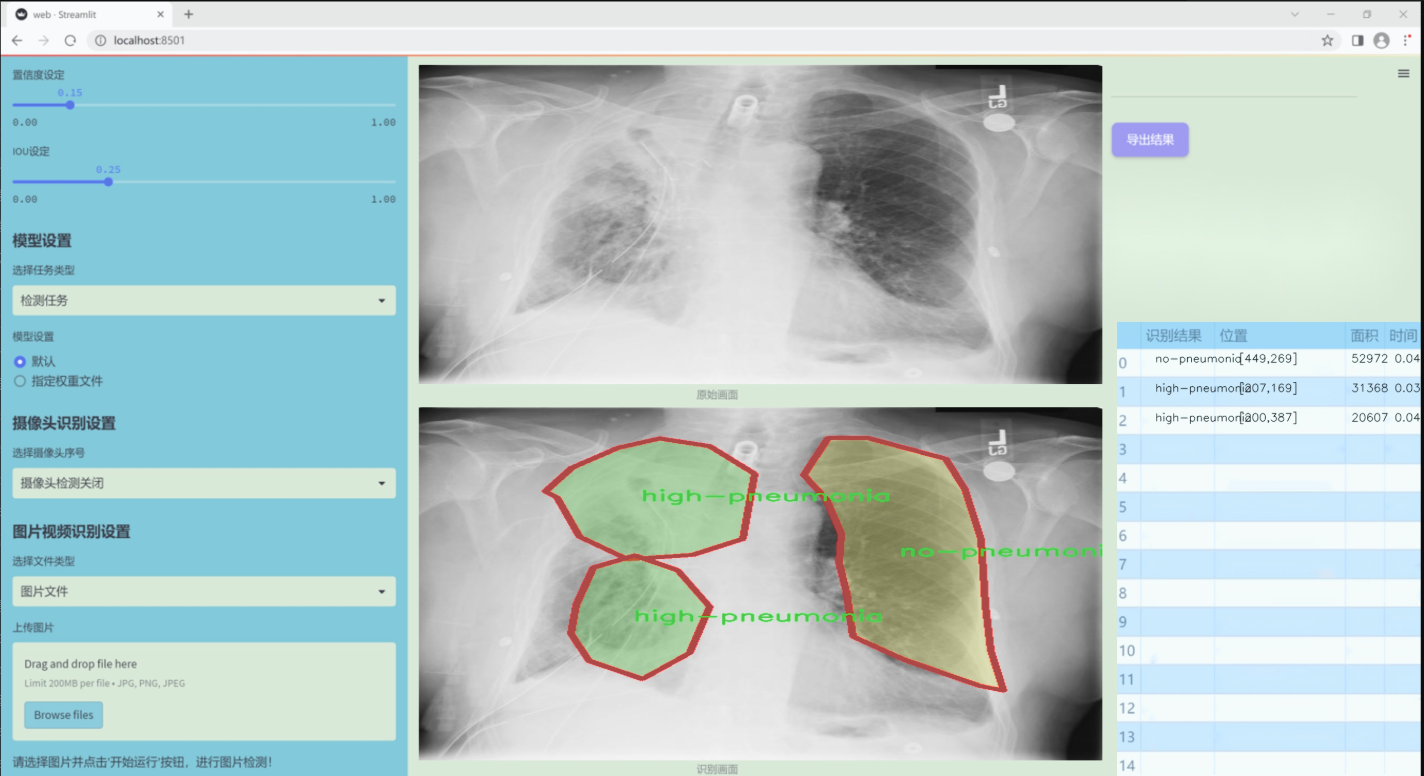
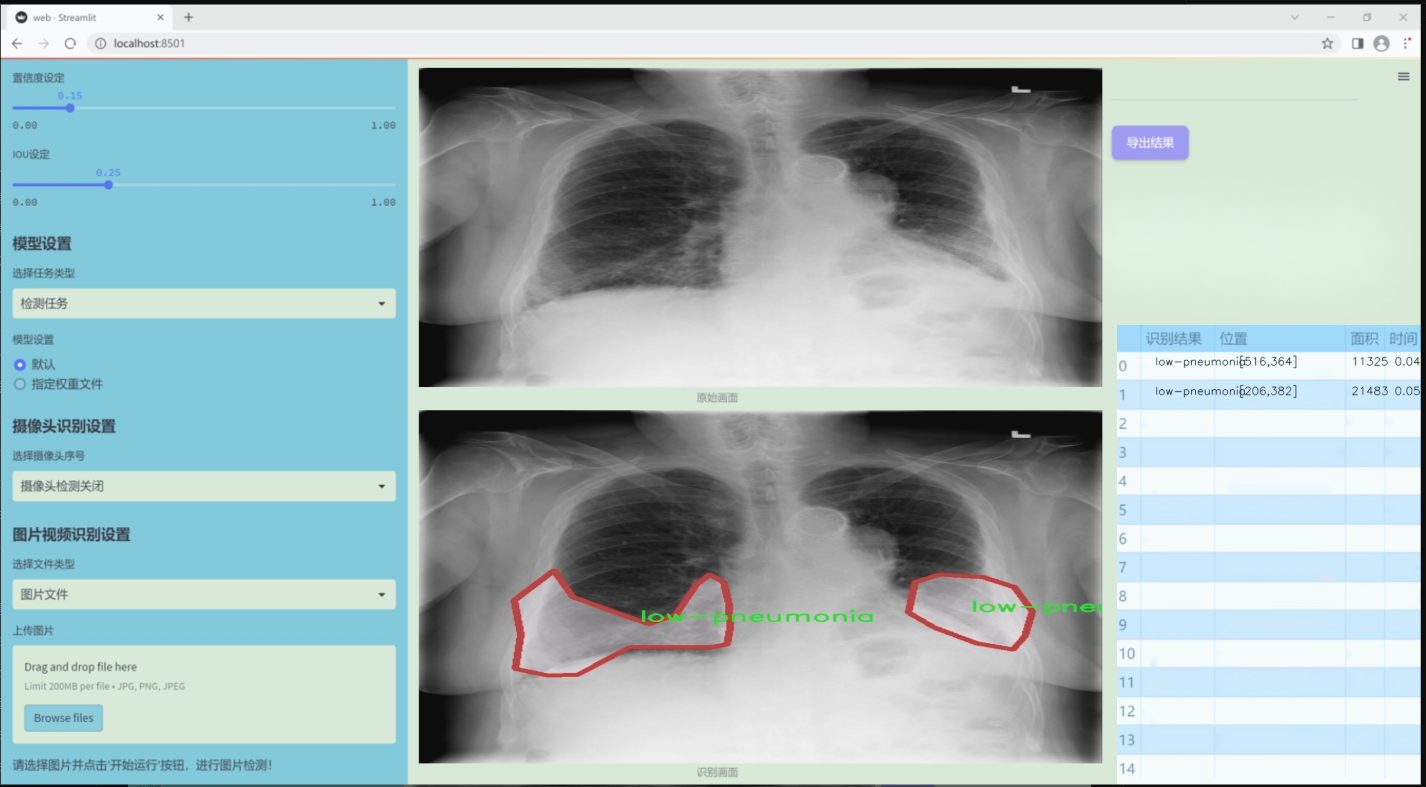
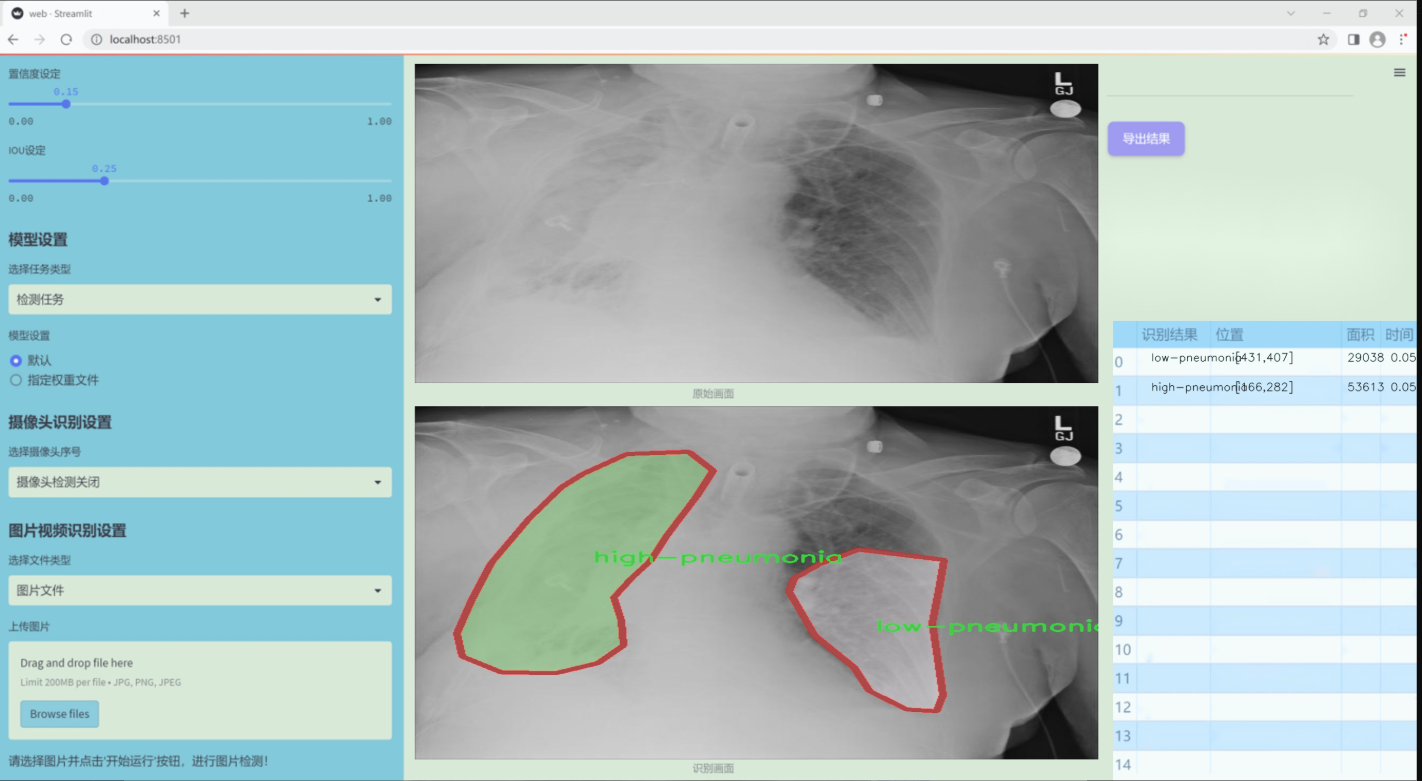
数据集信息
本项目所使用的数据集专注于胸部影像学(chest imaging),旨在为改进YOLOv11的肺炎类型检测系统提供高质量的训练样本。该数据集包含三种主要类别,分别是“高肺炎”(high-pneumonia)、“低肺炎”(low-pneumonia)和“无肺炎”(no-pneumonia),总类别数量为三。这一分类设计旨在帮助模型更好地识别和区分不同类型的肺炎,从而提高其在临床应用中的准确性和可靠性。
在数据集的构建过程中,特别注重样本的多样性和代表性,以确保模型能够适应不同患者的影像特征。每个类别的样本均来自真实的临床病例,涵盖了不同年龄段、性别及病程的患者。这种多样性不仅有助于提高模型的泛化能力,还能有效降低过拟合的风险。此外,数据集中的影像数据经过严格的标注和审核,确保每一张图像都准确反映其对应的肺炎类型。
通过使用这一数据集,改进后的YOLOv11模型将能够在实时检测中迅速识别出肺炎的类型,为医生提供有力的辅助决策支持。数据集的设计与构建充分考虑了实际应用中的需求,力求在保证检测精度的同时,提升处理速度,以满足临床环境中对快速诊断的迫切需求。总之,本项目的数据集不仅为模型训练提供了坚实的基础,也为肺炎的早期检测和干预提供了重要的数据支持。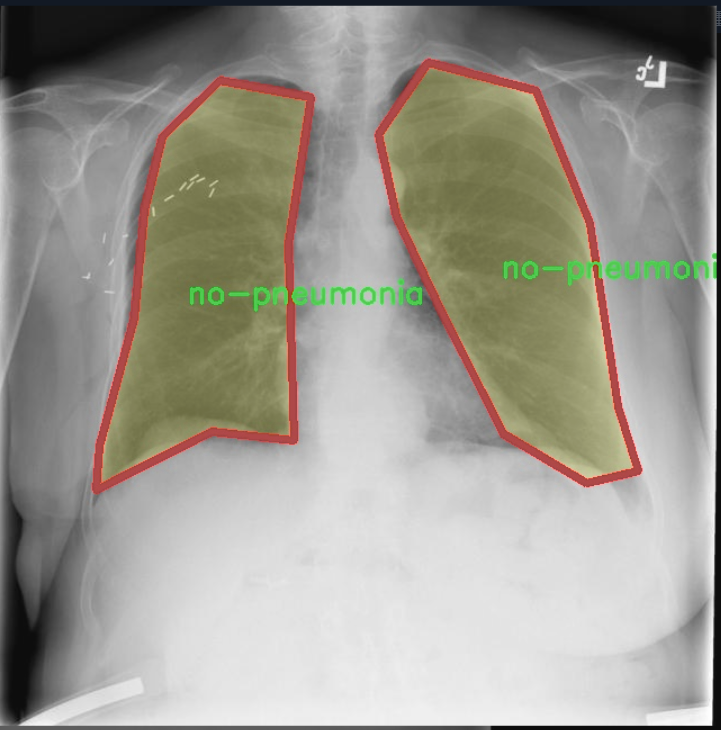
核心代码
以下是经过简化和注释的核心代码部分:
import torch
import torch.nn as nn
class KANConvNDLayer(nn.Module):
def init(self, conv_class, norm_class, input_dim, output_dim, spline_order, kernel_size,
groups=1, padding=0, stride=1, dilation=1,
ndim: int = 2, grid_size=5, base_activation=nn.GELU, grid_range=[-1, 1], dropout=0.0):
super(KANConvNDLayer, self).init()
# 初始化参数
self.inputdim = input_dim # 输入维度
self.outdim = output_dim # 输出维度
self.spline_order = spline_order # 样条阶数
self.kernel_size = kernel_size # 卷积核大小
self.padding = padding # 填充
self.stride = stride # 步幅
self.dilation = dilation # 膨胀
self.groups = groups # 分组数
self.ndim = ndim # 维度
self.grid_size = grid_size # 网格大小
self.base_activation = base_activation() # 基础激活函数
self.grid_range = grid_range # 网格范围
# 设置dropout层
self.dropout = nn.Dropout(p=dropout) if dropout > 0 else None
# 参数检查
if groups <= 0:
raise ValueError('groups must be a positive integer')
if input_dim % groups != 0:
raise ValueError('input_dim must be divisible by groups')
if output_dim % groups != 0:
raise ValueError('output_dim must be divisible by groups')
# 初始化基础卷积层
self.base_conv = nn.ModuleList([conv_class(input_dim // groups,
output_dim // groups,
kernel_size,
stride,
padding,
dilation,
groups=1,
bias=False) for _ in range(groups)])
# 初始化样条卷积层
self.spline_conv = nn.ModuleList([conv_class((grid_size + spline_order) * input_dim // groups,
output_dim // groups,
kernel_size,
stride,
padding,
dilation,
groups=1,
bias=False) for _ in range(groups)])
# 初始化归一化层
self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])
# 初始化PReLU激活函数
self.prelus = nn.ModuleList([nn.PReLU() for _ in range(groups)])
# 生成网格
h = (self.grid_range[1] - self.grid_range[0]) / grid_size
self.grid = torch.linspace(
self.grid_range[0] - h * spline_order,
self.grid_range[1] + h * spline_order,
grid_size + 2 * spline_order + 1,
dtype=torch.float32
)
# 使用Kaiming均匀分布初始化卷积层权重
for conv_layer in self.base_conv:
nn.init.kaiming_uniform_(conv_layer.weight, nonlinearity='linear')
for conv_layer in self.spline_conv:
nn.init.kaiming_uniform_(conv_layer.weight, nonlinearity='linear')
def forward_kan(self, x, group_index):
# 对输入应用基础激活函数并进行线性变换
base_output = self.base_conv[group_index](self.base_activation(x))
# 扩展维度以进行样条操作
x_uns = x.unsqueeze(-1)
target = x.shape[1:] + self.grid.shape
grid = self.grid.view(*list([1 for _ in range(self.ndim + 1)] + [-1, ])).expand(target).contiguous().to(x.device)
# 计算样条基
bases = ((x_uns >= grid[..., :-1]) & (x_uns < grid[..., 1:])).to(x.dtype)
# 计算多阶样条基
for k in range(1, self.spline_order + 1):
left_intervals = grid[..., :-(k + 1)]
right_intervals = grid[..., k:-1]
delta = torch.where(right_intervals == left_intervals, torch.ones_like(right_intervals),
right_intervals - left_intervals)
bases = ((x_uns - left_intervals) / delta * bases[..., :-1]) + \
((grid[..., k + 1:] - x_uns) / (grid[..., k + 1:] - grid[..., 1:(-k)]) * bases[..., 1:])
bases = bases.contiguous()
bases = bases.moveaxis(-1, 2).flatten(1, 2)
# 通过样条卷积层得到输出
spline_output = self.spline_conv[group_index](bases)
x = self.prelus[group_index](self.layer_norm[group_index](base_output + spline_output))
# 应用dropout
if self.dropout is not None:
x = self.dropout(x)
return x
def forward(self, x):
# 将输入按组分割
split_x = torch.split(x, self.inputdim // self.groups, dim=1)
output = []
for group_ind, _x in enumerate(split_x):
y = self.forward_kan(_x.clone(), group_ind)
output.append(y.clone())
y = torch.cat(output, dim=1) # 合并输出
return y
代码注释说明:
类的初始化:__init__方法中定义了卷积层、归一化层、激活函数等的初始化,以及参数的合法性检查。
前向传播:forward_kan方法实现了基础卷积和样条卷积的前向传播逻辑,包括样条基的计算和最终输出的生成。
分组处理:forward方法将输入数据按组分割,分别通过forward_kan处理后再合并输出。
这个程序文件定义了一个名为 KANConvNDLayer 的神经网络层,主要用于实现一种新的卷积操作,结合了基于样条(spline)的特性。该层支持多维卷积(如1D、2D、3D),并且通过继承的方式,提供了专门的1D、2D和3D卷积层的实现。
在 KANConvNDLayer 的构造函数中,初始化了一系列参数,包括输入和输出维度、卷积核大小、样条的阶数、分组数、填充、步幅、扩张率等。构造函数还根据分组数创建了多个基础卷积层和样条卷积层,并为每个组创建了归一化层和激活函数(PReLU)。如果指定了 dropout 率,则会根据维度选择相应的 dropout 层。
在 forward_kan 方法中,首先对输入进行基础激活处理,然后通过基础卷积层进行线性变换。接着,计算样条基函数,使用输入值和预定义的网格进行样条插值。计算完成后,将样条卷积的输出与基础卷积的输出相加,并通过归一化和激活函数处理,最后应用 dropout(如果有的话)。
forward 方法则负责处理输入数据,首先将输入数据按照分组进行切分,然后对每个组调用 forward_kan 方法进行处理,最后将所有组的输出拼接在一起,形成最终的输出。
此外,文件中还定义了三个类 KANConv1DLayer、KANConv2DLayer 和 KANConv3DLayer,分别继承自 KANConvNDLayer,用于实现一维、二维和三维卷积的具体实现。这些类在初始化时调用父类的构造函数,并传入相应的卷积类型和归一化类型。
整体来看,这个程序文件实现了一种灵活且强大的卷积层,能够处理多维数据,并结合了样条插值的特性,以增强模型的表达能力。
10.4 prepbn.py
以下是经过简化和注释的核心代码部分:
import torch
import torch.nn as nn
自定义的批量归一化类
class RepBN(nn.Module):
def init(self, channels):
super(RepBN, self).init()
# 初始化一个可学习的参数 alpha
self.alpha = nn.Parameter(torch.ones(1))
# 使用 PyTorch 的 BatchNorm1d 进行一维批量归一化
self.bn = nn.BatchNorm1d(channels)
def forward(self, x):
# 将输入的维度进行转置,以适应 BatchNorm1d 的输入格式
x = x.transpose(1, 2)
# 进行批量归一化,并加上 alpha 乘以原始输入
x = self.bn(x) + self.alpha * x
# 再次转置回原来的维度
x = x.transpose(1, 2)
return x
自定义的线性归一化类
class LinearNorm(nn.Module):
def init(self, dim, norm1, norm2, warm=0, step=300000, r0=1.0):
super(LinearNorm, self).init()
# 注册一些缓冲区变量,用于控制训练过程中的参数
self.register_buffer(‘warm’, torch.tensor(warm)) # 预热步数
self.register_buffer(‘iter’, torch.tensor(step)) # 当前迭代步数
self.register_buffer(‘total_step’, torch.tensor(step)) # 总步数
self.r0 = r0 # 初始比例
self.norm1 = norm1(dim) # 第一个归一化层
self.norm2 = norm2(dim) # 第二个归一化层
def forward(self, x):
if self.training: # 如果模型在训练状态
if self.warm > 0: # 如果还有预热步数
self.warm.copy_(self.warm - 1) # 减少预热步数
x = self.norm1(x) # 使用第一个归一化层
else:
# 计算当前的 lambda 值,用于加权两个归一化结果
lamda = self.r0 * self.iter / self.total_step
if self.iter > 0:
self.iter.copy_(self.iter - 1) # 减少迭代步数
x1 = self.norm1(x) # 第一个归一化的输出
x2 = self.norm2(x) # 第二个归一化的输出
# 根据 lambda 加权合并两个归一化的输出
x = lamda * x1 + (1 - lamda) * x2
else:
x = self.norm2(x) # 如果不是训练状态,直接使用第二个归一化层
return x
代码说明:
RepBN 类:
这是一个自定义的批量归一化层,除了标准的批量归一化操作外,还引入了一个可学习的参数 alpha,用于对输入进行加权。
在 forward 方法中,输入的维度会被转置,以适应 BatchNorm1d 的输入格式,处理后再转置回原来的维度。
LinearNorm 类:
这个类实现了一个线性归一化机制,结合了两个不同的归一化层(norm1 和 norm2)。
在训练过程中,使用预热机制逐步引入第二个归一化层的影响,通过计算 lambda 值来动态调整两个归一化结果的权重。
在非训练状态下,直接使用第二个归一化层的输出。
这个程序文件 prepbn.py 定义了两个神经网络模块,分别是 RepBN 和 LinearNorm,它们都是继承自 PyTorch 的 nn.Module 类,用于构建深度学习模型中的特定功能。
RepBN 类实现了一种新的归一化方法。它的构造函数接收一个参数 channels,表示输入数据的通道数。在初始化过程中,创建了一个可学习的参数 alpha,并实例化了一个一维批量归一化层 bn。在 forward 方法中,输入 x 首先进行维度转置,以适应批量归一化的要求。接着,输入经过批量归一化处理后,加上 alpha 乘以原始输入 x,然后再进行一次维度转置,最后返回处理后的结果。这种方法可以在归一化的基础上引入原始输入的影响,可能有助于提高模型的性能。
LinearNorm 类则实现了一种线性归一化策略。构造函数接收多个参数,包括维度 dim、两个归一化方法 norm1 和 norm2,以及一些用于控制训练过程的参数。它使用 register_buffer 方法注册了一些状态变量,如 warm(用于控制预热阶段的步数)、iter(当前迭代步数)和 total_step(总步数)。在 forward 方法中,首先检查模型是否处于训练模式。如果是且 warm 大于零,则执行 norm1 进行归一化,并减少 warm 的值。当预热阶段结束后,计算一个线性插值系数 lamda,然后分别使用 norm1 和 norm2 对输入 x 进行归一化,最后根据 lamda 的值对两者的结果进行加权平均。如果模型不在训练模式下,则直接使用 norm2 对输入进行归一化。
整体来看,这个文件中的模块提供了灵活的归一化机制,可以在不同的训练阶段和条件下调整输入的处理方式,以提高模型的学习能力和性能。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐

 32
32 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)