智能客服API选型犯难?这个评测工具帮我少走弯路
总的来说,AI Ping虽然不是完美的,但作为免费评测平台,已经帮我解决了大模型选型的核心痛点。要是你也属于这几类人,强烈建议试试:经常调用大模型API的开发者(不管是做客服、内容生成还是数据分析);对服务稳定性、响应速度敏感的业务方(比如电商、教育这类用户量大的行业);负责技术选型,需要对比多家厂商的工程师(省时间又省成本)。最后放个官网链接,要是你也在为大模型选型头疼,不妨去看看。
每日一句
一生中你唯一需要回头的时候,
是为了看自己到底走了多远。

目录
引
最近接手公司智能客服系统的迭代项目,卡在了大模型API选型这一步——原本以为挑个口碑好的厂商就行,实际测试才发现麻烦不断:同样是生成客服回复,甲厂商上午响应快得像闪电,下午高峰时段就卡得让人着急;乙厂商报价便宜,但测试时总出现语义理解偏差;丙厂商功能全,可按调用次数收费的模式,让我算不清长期成本。更头疼的是,市面上主流的MaaS供应商掰着指头数都有二十多家,光适配过的客服类模型就有上百个,每次选型号都像拆盲盒,不知道下一个会不会踩坑。
一.偶然挖到的“选型神器”
上周在开发者社群里刷到有人分享一个叫AI Ping的平台,说是专门做MaaS服务评测的。我第一反应是:会不会又是只堆技术参数、不落地的花架子?毕竟之前用过不少评测工具,要么只测模型精度,要么数据是几个月前的,对实际开发没多大用。但抱着“试试不亏”的心态点进去,发现这平台还真有点不一样。
它最让我眼前一亮的是评测角度——不盯着实验室里的“精度得分”,反而聚焦我们开发者最关心的实际性能:API调用延迟、token吞吐速度、高峰期可靠性,甚至不同时段的性能波动。这些指标,恰恰是智能客服场景的“生命线”——用户等回复超2秒就可能流失,高峰期掉单更是直接影响口碑,之前踩过的坑全是因为没提前摸清这些数据。
二.实际用下来:比预想中更贴业务
1. 实时性能榜:一眼看清“谁在裸泳”
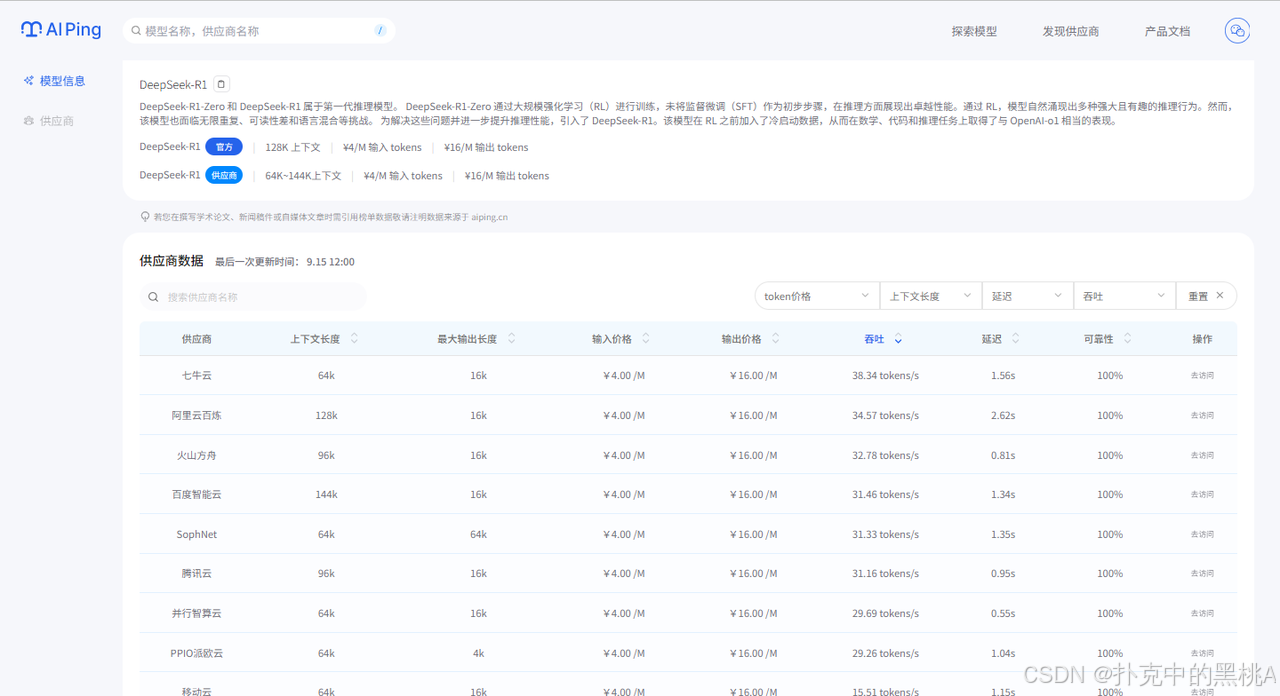
打开AI Ping官网,最显眼的就是实时更新的性能排行榜,不是简单的“谁第一谁第二”,而是能按模型类型筛选。
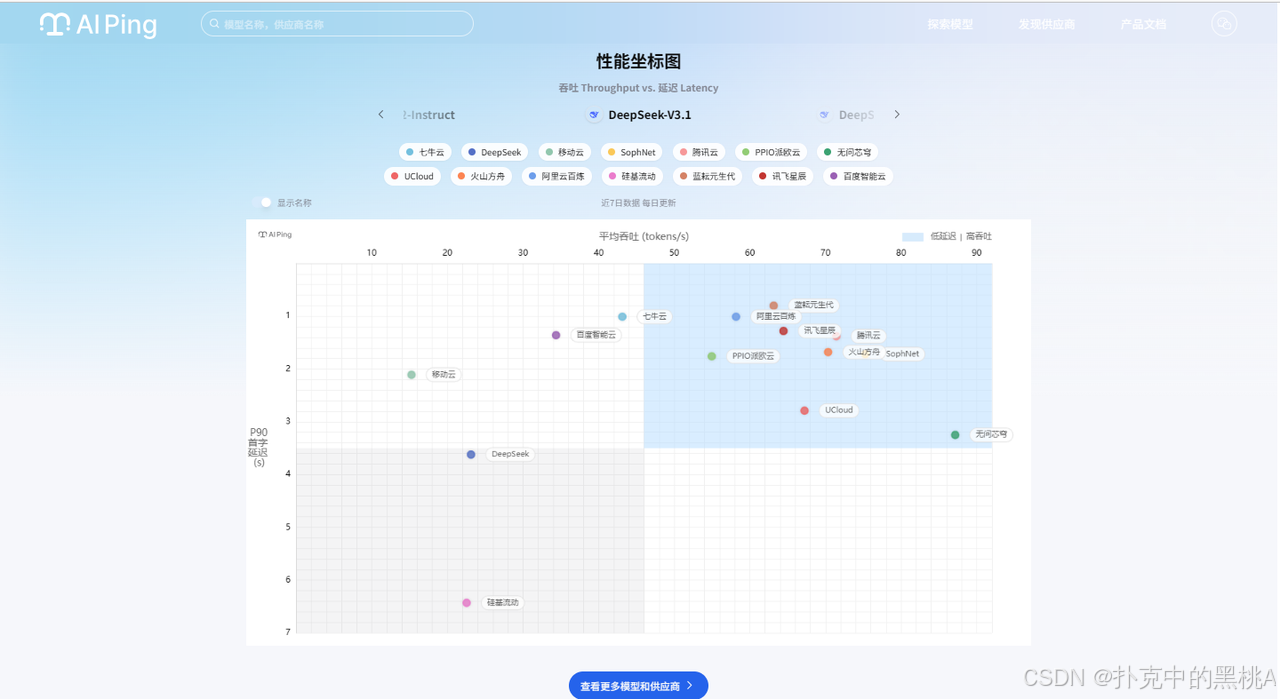
我当时要找适配客服场景的长文本模型,就选了常用的DeepSeek,立刻跳出十几家供应商的实时数据:
从坐标图能清晰看到差异:华为云在延迟控制上特别突出,平均延迟只有0.82s,适合需要实时响应的客服对话;七牛云的吞吐更强,能到37.2 tokens/s,批量生成FAQ回复效率更高;而某家小厂商虽然价格低,但延迟飘到1.8s,直接被我排除。
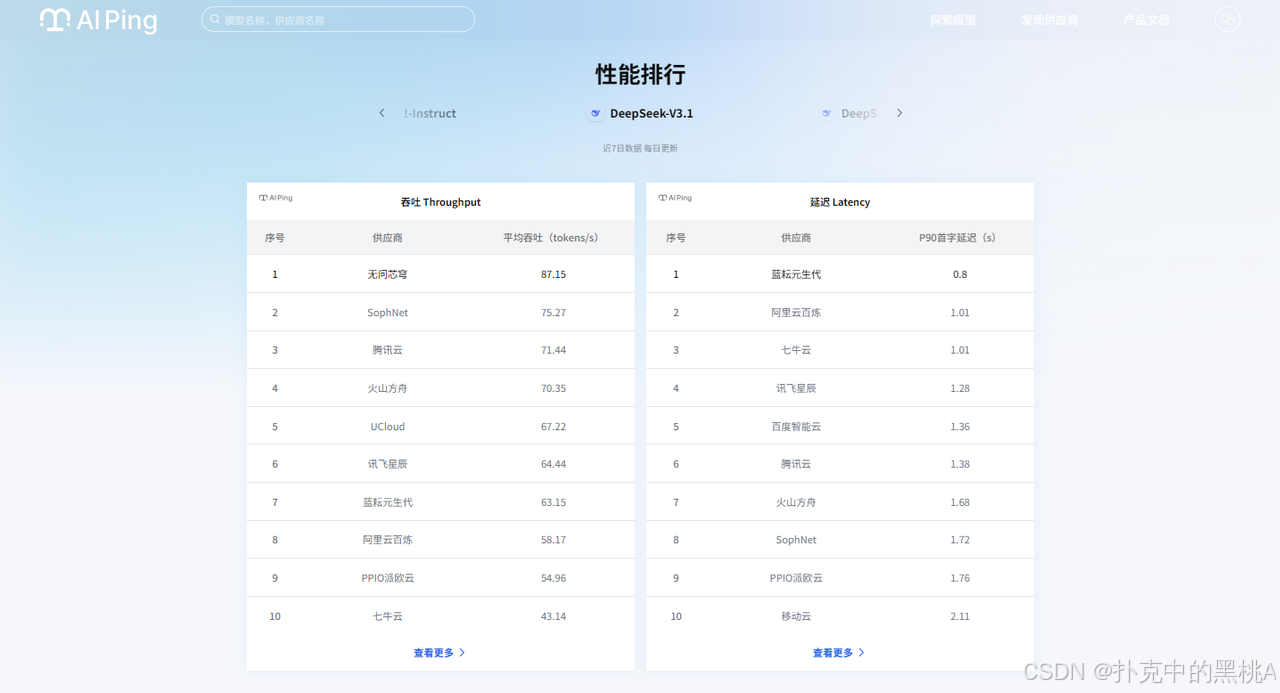
2. 模型筛选:精准定位“我的菜”
作为对参数敏感的开发者,我特别在意筛选功能。AI Ping的筛选维度很实在,除了常规的上下文长度(小于16k、16-64k、大于64k)、输入输出价格,还能按“最大输出token限制”筛选——客服场景经常要生成500字以上的详细回复,那些最大输出只有2k token的模型,直接就能筛掉。
点进模型库,每个模型的信息都标得很细:
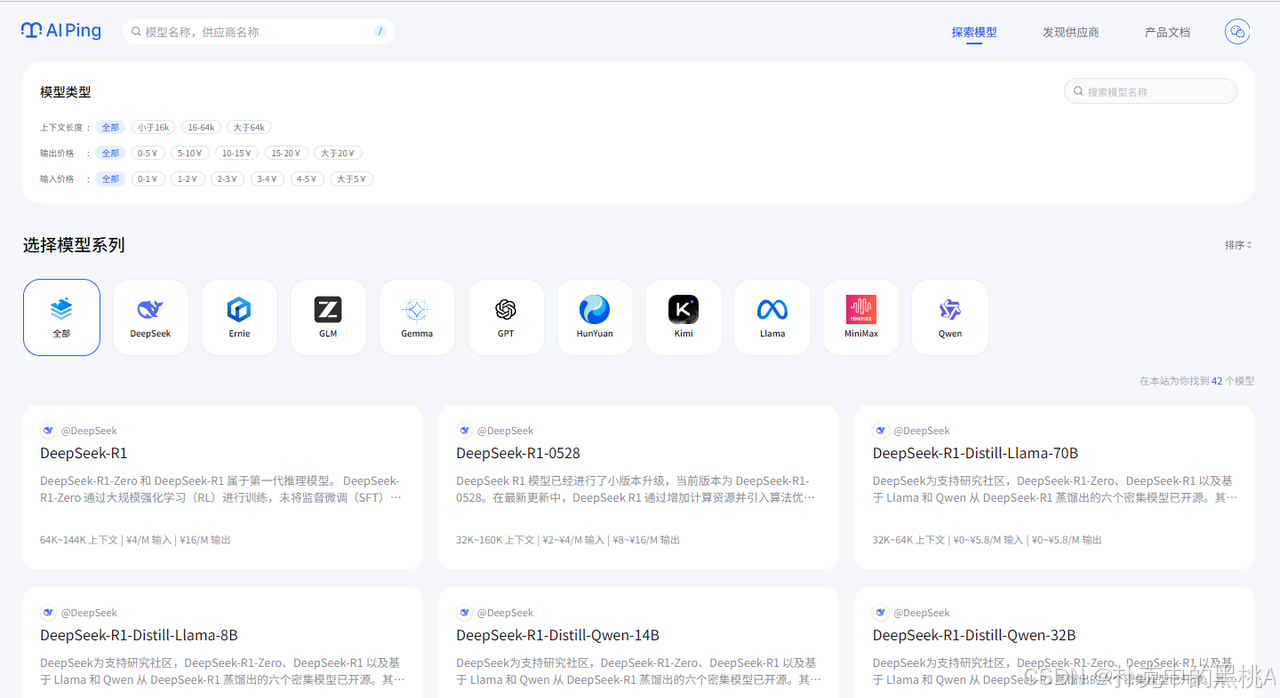
点击详情时,可以发现不同厂商的对比。同样的价格,火山方舟延迟最低,百度智能云吞吐最高——要是做实时客服,优先选火山方舟;要是批量生成客服知识库,百度智能云更高效。这种横向对比,比我自己一家家测快多了。

3. 实战测试:真能解决问题
这次项目要给500+个行业FAQ生成标准化回复,还要支持实时客服对话,对延迟(≤1.2s)和可靠性(≥99.9%)要求很高。我就用AI Ping的数据筛选出3个候选方案:
-
火山方舟Llama 3-70B:延迟0.8s,吞吐32.5 tokens/s
-
移动云Llama 3-70B:延迟1.0s,吞吐34.3 tokens/s
-
百度智能云Llama 3-70B:延迟1.1s,吞吐36.1 tokens/s
先拿50个FAQ做小规模测试:火山方舟的实时响应确实快,咨询时基本“秒回”;百度智能云批量生成回复时,1小时能处理80+个,比另外两家快15%;移动云表现中规中矩,但高并发(模拟50人同时咨询)时,偶尔会有0.2s的延迟波动。
测试中还发现个平台数据没直接标的点:早9-11点、晚7-9点这两个客服高峰时段,所有供应商的延迟都会上升10%-20%。我赶紧调整策略:实时客服用火山方舟,避开高峰时段;批量生成FAQ放在凌晨2-6点,用百度智能云跑,既保证速度又不影响实时服务。
上线后实时客服的平均响应时间控制在0.9s以内,FAQ生成准确率也达标。
三.背景扒一扒:清华团队的“严谨范儿”
后来查了下平台背景,发现是清华系AI公司清程极智做的。难怪评测方法这么严谨,不是随便测几次就出数据——他们用的是匿名测试,避免厂商针对性优化;而且数据还被清华大学AI基础设施实验室纳入了行业报告,甚至中国软件评测中心做相关评测时也会参考,可信度确实比小平台高。
1. 做得好的地方
-
抓痛点准:不搞虚的,专测开发者关心的性能指标,比测“模型在学术数据集上的得分”实用多了;
-
数据够客观:持续监测+匿名测试,避免“单次跑分好看,实际用着拉胯”的情况;
-
覆盖够全:20多家主流供应商、200多个模型,基本不用再去别的地方查数据;
-
更新够快:厂商出新模型、调价格,平台几天内就能更新,不会拿旧数据误导人。
2. 还能再优化的点
-
缺场景化推荐:比如“智能客服场景优先选哪些模型”“内容生成该看吞吐还是延迟”,要是能有现成的场景模板就好了;
-
历史数据短:目前只能看7天内的性能趋势,要是能看30天的,就能更清楚厂商的长期稳定性;
-
少成本测算:虽然有价格,但没算“每处理1000条客服消息的成本”,对预算紧的中小企业不够友好。
总结:必须收藏的“选型神器”
总的来说,AI Ping虽然不是完美的,但作为免费评测平台,已经帮我解决了大模型选型的核心痛点。要是你也属于这几类人,强烈建议试试:
-
经常调用大模型API的开发者(不管是做客服、内容生成还是数据分析);
-
对服务稳定性、响应速度敏感的业务方(比如电商、教育这类用户量大的行业);
-
负责技术选型,需要对比多家厂商的工程师(省时间又省成本)。
最后放个官网链接,要是你也在为大模型选型头疼,不妨去看看。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐

 107
107 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)