深入UDP与sk_buff:掌握Linux网络协议栈的核心机制
本文系统剖析 UDP 协议在 TCP/IP 栈中的精简设计与核心特性——无连接、不可靠、面向数据报,并详解其 8 字节定长头部如何实现高效解析与端口分用。同时深入 Linux 内核,揭示 sk_buff 数据结构如何通过动态指针管理网络报文的封装、传递与生命周期。结合缓冲区机制、典型应用场景及现代协议(如 QUIC)演进,阐明为何 UDP 仍是实时通信与高性能系统的首选。掌握 UDP 与 sk_b
目录
四、UDP 如何将数据交付给正确的应用进程?——端口分用(Demultiplexing)
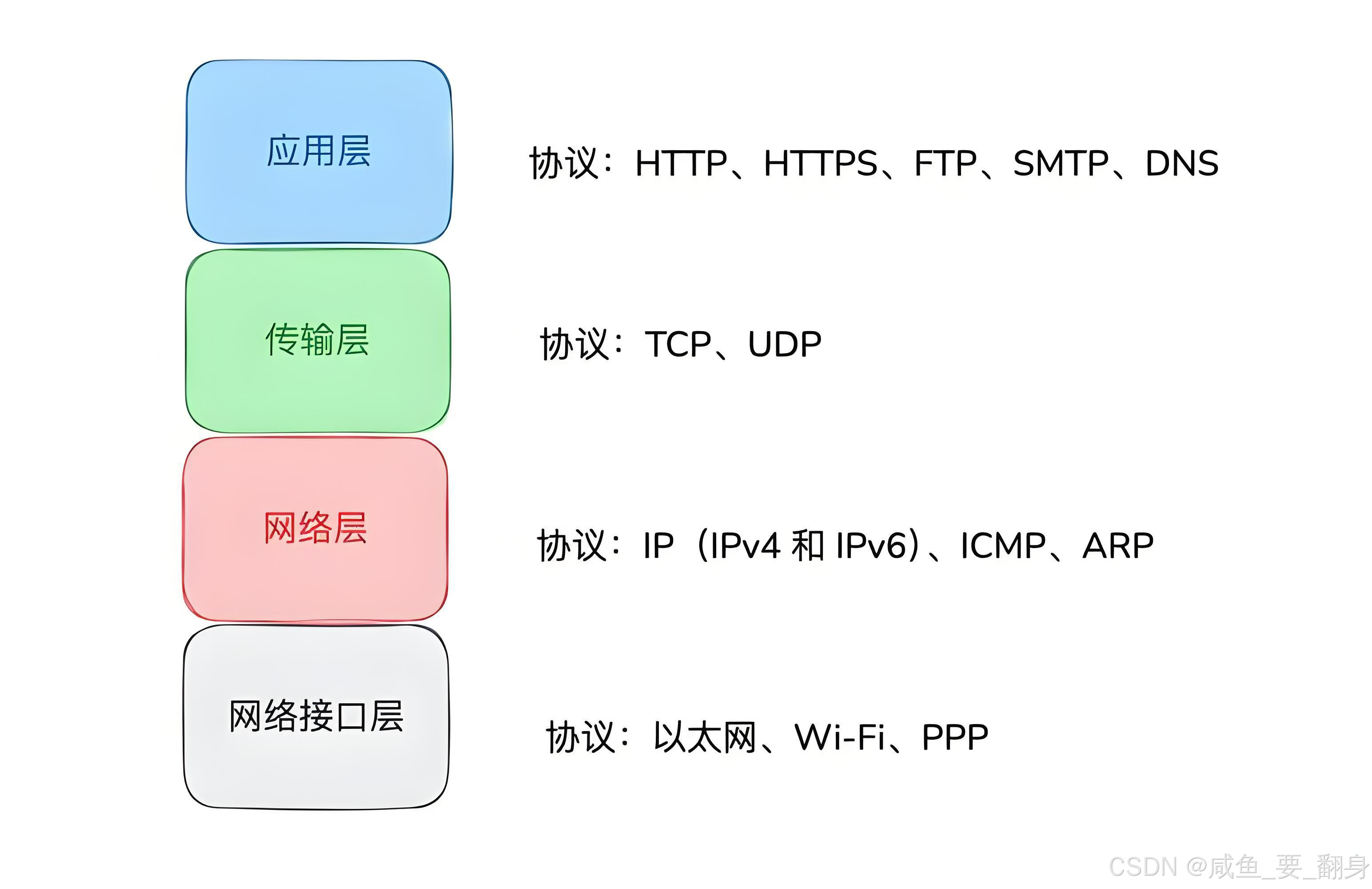
一、UDP 在网络协议栈中的位置
在 TCP/IP 协议栈中,UDP(User Datagram Protocol,用户数据报协议) 位于 传输层(Transport Layer),介于应用层与网络层(IP 层)之间。
关键理解:
-
应用程序(如 DNS 客户端、视频流软件)通过 Socket API(如
sendto/recvfrom)与传输层交互。 -
Socket 接口是 操作系统提供的系统调用,属于 应用层与传输层之间的桥梁。
-
实际的 UDP 协议实现(包括封装、校验、分用等)完全由 操作系统内核 完成,用户程序无法修改其底层逻辑。
-
因此,网络协议栈是操作系统内核的重要组成部分。
例如,我们常说 “HTTP 是基于 TCP 的”,本质上是指:
-
HTTP 协议的数据通过 TCP 套接字 发送;
-
而若某个协议(如 DNS)使用
sendto发送数据,则说明它是 基于 UDP 的。
二、UDP 报文格式(RFC 768)
UDP 报文结构极其简洁,仅包含 8 字节固定长度的头部(内核读取前 8 字节即可分离头部与有效载荷),后接可变长度的有效载荷(Payload):
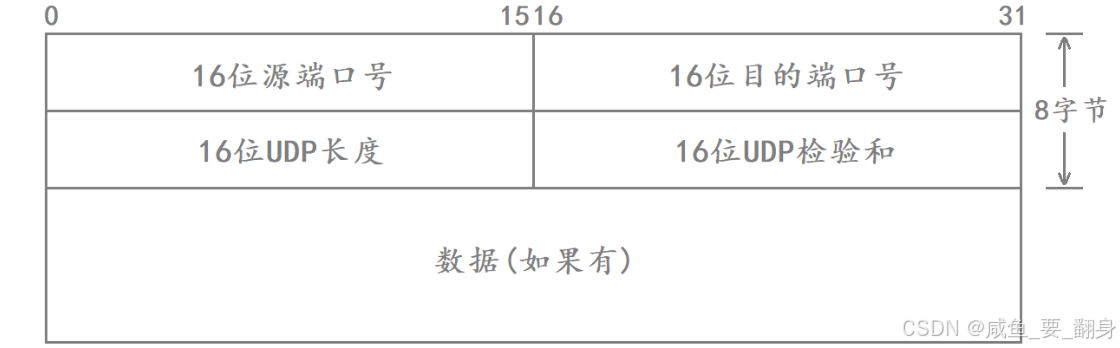
字段详解
| 字段 | 长度 | 说明 |
|---|---|---|
| 源端口号 | 16 位 | 标识发送方进程(客户端通常由系统自动分配) |
| 目的端口号 | 16 位 | 标识接收方进程(服务端需显式绑定) |
| UDP 长度 | 16 位 | 整个 UDP 报文的字节数(含头部 + 数据),最小值为 8(仅头部) |
| 校验和 | 16 位 | 可选字段(IPv4 中可设为 0 表示不校验;IPv6 中强制启用)。用于检测传输过程中是否发生比特错误。若校验失败,直接丢弃该报文,且不通知发送方。 |
为什么端口号是 16 位?正是因为 UDP(和 TCP)头部中端口号字段定义为 16 位,所以所有基于传输层的应用都继承了这一限制,端口号范围为 0 ~ 65535。
三、UDP 如何解析报文?——定长头部分离机制
由于 UDP 头部 固定为 8 字节,内核在处理接收到的 IP 数据报时,只需:
-
读取前 8 字节 → 解析出源/目的端口、长度、校验和;
-
剩余部分即为有效载荷 → 直接交付给上层应用。
这种 “定长头部 + 剩余即数据” 的设计,使得 UDP 解析效率极高,无需复杂状态机或长度推断。
1、理解UDP报头
操作系统内核使用C语言实现,而UDP协议作为内核协议栈的一部分,自然也是用C语言编写的。UDP报头本质上就是一个位段(bit-field)类型的数据结构。
struct udp_header {
unsigned int src_port:16; // 源端口号(16位)
unsigned int dst_port:16; // 目的端口号(16位)
unsigned int udp_len:16; // UDP 数据报长度(含头部,16位)
unsigned int udp_chk:16; // UDP 检验和(16位)
};说明
-
unsigned int:使用无符号整型,但通过:16指定只使用其中 16 位(即 2 字节)。 -
位域(bit-field):这种写法是 C 语言中的“位域”特性,用于节省内存空间,特别适合协议头这类固定格式的数据。
-
字段含义:
-
src_port:发送方端口。 -
dst_port:接收方端口。 -
udp_len:整个 UDP 数据报的长度(首部 + 数据),单位为字节。 -
udp_chk:UDP 检验和,用于校验数据完整性(可选,若为 0 表示不使用)。
-
注意事项
-
字节序问题:实际网络传输中需按 大端序(Big-Endian) 发送,因此在程序中可能需要调用
htons()等函数转换。 -
对齐问题:由于是位域结构,不同编译器可能有不同对齐方式,建议在实际项目中使用标准的
uint16_t类型并手动定义,或使用__packed属性避免填充。 -
标准实现参考:这是 Linux 内核中定义的标准形式(通常在
<linux/udp.h>中)。struct udphdr { uint16_t source; uint16_t dest; uint16_t len; uint16_t check; };
2、UDP数据封装流程:(自上而下)
-
应用层数据传递到传输层时,系统会创建一个UDP报头变量
-
填充报头各字段,形成完整的UDP报头
-
内核分配内存空间,将UDP报头与有效载荷合并,最终生成UDP报文
3、UDP数据分用流程:(自下往上)
-
传输层接收到下层报文后,首先读取前8个字节
-
从中解析出目的端口号
-
根据端口号定位对应的应用层进程
-
将剩余的有效载荷数据传递给该进程
四、UDP 如何将数据交付给正确的应用进程?——端口分用(Demultiplexing)
当 UDP 从 IP 层接收到一个数据报后,需决定将其交给哪个上层进程。这一过程称为 分用(Demultiplexing),其实现依赖于 端口号到进程的映射表。
工作流程
-
提取 UDP 报文中的 目的端口号;
-
查询内核维护的 端口-进程映射表(通常用哈希表实现,以 O(1) 时间复杂度查找);
-
若找到匹配项,则将有效载荷放入该进程对应的 UDP 接收缓冲区;
-
若未找到(如端口未监听),则 丢弃该报文(可能返回 ICMP Port Unreachable,但非必须)。
服务端 vs 客户端
-
服务端:必须显式调用
bind()绑定知名端口(如 DNS 用 53); -
客户端:通常不调用
bind(),由内核自动分配一个 临时端口(ephemeral port,49152~65535) 作为源端口。
五、UDP 的核心特性
注意: 报文在网络中进行路由转发时,并不是每一个报文选择的路由路径都是一样的,因此报文发送的顺序和接收的顺序可能是不同的!!!
1、无连接(Connectionless)
-
发送前 无需建立连接(不像 TCP 的三次握手);
-
只要知道对方的 IP 地址 + 端口号,即可直接发送数据;
-
每个 UDP 报文都是独立的,彼此无关联。
2、不可靠(Unreliable)
-
无确认机制(ACK):发送后不知道对方是否收到;
-
无重传机制:丢包不会自动重发;
-
无错误通知:即使校验失败或端口不可达,UDP 层通常不会向上层报告错误(除非应用层主动处理 ICMP 消息)。
⚠️ 后果:应用层必须自行处理丢包、乱序、重复等问题(如 QUIC 协议在 UDP 上实现了可靠传输)。
3、面向数据报(Message-Oriented)
注意!!!这一点是 UDP 与 TCP(字节流)的根本区别之一!!!
-
保持消息边界:应用层调用一次
sendto发送 N 字节,接收方必须一次recvfrom读取全部 N 字节; -
不会合并或拆分:即使多次发送小包,接收方也不会自动拼接;反之,大包也不会被拆成多个小包(受限于 MTU 和 UDP 最大长度)。
-
简单来说就是:UDP协议采用数据报传输方式,应用层提交的报文会被完整发送,既不拆分也不合并。
示例:
// 发送端
sendto(sockfd, "Hello", 5, ...); // 发送 5 字节
// 接收端
char buf[10];
recvfrom(sockfd, buf, 10, ...); // 必须一次读完 5 字节
// 若 recvfrom(buf, 2),则只读前 2 字节,剩余 3 字节被丢弃!以传输100字节数据为例:发送端单次调用sendto发送100字节时,接收端必须通过单次recvfrom完整接收这100字节数据,不能通过多次recvfrom(每次10字节)的方式分批接收。
六、UDP 的缓冲区机制
1、无发送缓冲区
-
调用
sendto()时,数据 直接拷贝到内核空间,由内核立即尝试封装并交给 IP 层; -
若网络拥塞或接口忙,可能丢包,但 不会在 UDP 层排队等待。
2、有接收缓冲区
-
内核为每个 UDP socket 维护一个 接收队列(缓冲区);
-
当数据到达时,若缓冲区未满,则入队;若已满,则 新到达的报文被丢弃;
-
这个接收缓冲区不能保证收到的UDP报的顺序和发送UDP报的顺序一致;
-
应用调用
recvfrom()时,从缓冲区取出一个完整数据报。 - UDP套接字支持同时读写操作,具备全双工通信能力。
3、为什么需要接收缓冲区?
-
避免因应用层处理慢而导致 合法报文被丢弃;
-
允许应用以自己的节奏读取数据(异步处理);
-
提高系统吞吐能力,防止瞬时流量冲击导致服务崩溃;
-
防止因应用处理慢导致合法报文被丢弃,提升系统鲁棒性。
注意:UDP 接收缓冲区 不保证顺序!由于网络路由差异,后发的包可能先到。
| 方向 | 是否存在缓冲区 | 行为说明 |
|---|---|---|
| 发送 | ❌ 无真正发送缓冲区 | sendto() 直接将数据交内核,立即尝试发送;失败即丢弃 |
| 接收 | ✅ 有接收缓冲区 | 内核暂存到达的数据报;若缓冲区满,新报文被丢弃;应用通过 recvfrom() 读取完整报文 |
简单来说就是:
-
若UDP不设置接收缓冲区,上层应用必须立即读取接收到的报文。若某个报文未被及时读取,后续到达的报文将被迫丢弃。
-
报文传输过程会消耗主机和网络资源。若UDP仅因前一个报文未被上层读取就丢弃后续可能正确的报文,这将造成资源浪费。
-
因此,UDP实际会维护接收缓冲区。当新报文到达时,会被存入缓冲区等待上层读取。上层读取数据时直接从缓冲区获取,若缓冲区为空则读取操作会被阻塞。UDP接收缓冲区的主要作用就是临时存储接收到的报文,供上层应用按需读取。
七、UDP 的限制与注意事项
1、最大报文长度限制
-
UDP 长度字段为 16 位 → 最大值 65535 字节(≈64KB);
-
实际可用 payload ≈ 65507 字节(65535 - 8 字节头部 - 20 字节 IP 头部,假设无选项);
-
但受 MTU(Maximum Transmission Unit,默认 1500 字节) 限制,大 UDP 包会被 IP 层 分片(Fragmentation);
-
IP 分片易导致丢包(任一片丢失则整个 UDP 报文失效),因此强烈建议应用层控制单个 UDP 报文 ≤ 1400 字节(留出 IP+UDP 头部空间)。
2、超过 64KB 的数据如何传输?
-
必须在应用层手动分包:将大数据切分为多个 ≤1400 字节的 UDP 报文;
-
添加序号、校验、重传机制(如 TFTP、自定义协议);
-
或改用 TCP(天然支持流式大文件传输)。
八、基于 UDP 的典型应用层协议
尽管 UDP 不可靠,但其 低延迟、低开销、无连接 的特性使其适用于以下场景:
| 协议 | 端口 | 用途 | 为何选择 UDP |
|---|---|---|---|
| DNS | 53 | 域名解析 | 查询/响应短小,容忍偶尔失败,追求速度 |
| DHCP | 67/68 | 动态分配 IP | 客户端初始无 IP,需广播通信 |
| TFTP | 69 | 简单文件传输 | 实现简单,常用于嵌入式设备启动 |
| NFS(早期) | 2049 | 网络文件系统 | 对延迟敏感,可容忍少量丢包 |
| SNMP | 161/162 | 网络管理 | 监控数据小,实时性要求高 |
| VoIP / 视频会议 | 动态 | 实时音视频 | 宁可丢帧也不愿延迟(TCP 重传会卡顿) |
| QUIC | 443 | HTTP/3 传输层 | 在 UDP 上构建可靠、安全、多路复用的新协议 |
自定义协议:许多游戏、IoT 设备、金融行情系统也基于 UDP 构建私有协议,以换取极致性能。
九、传输层的核心职责
在 TCP/IP 协议栈中,传输层(Transport Layer) 位于应用层与网络层之间,其核心使命是:确保数据能够从一台主机上的某个应用程序,可靠或高效地传输到另一台主机上的目标应用程序。为实现这一目标,传输层需解决以下关键问题:
-
如何区分同一主机上多个并发通信的应用程序? → 端口号(Port)
-
如何标识一次完整的通信会话? → 五元组(5-tuple)
-
如何提供不同质量的服务? → TCP(可靠) vs UDP(高效)
十、总结:UDP 的适用场景与权衡
| 特性 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| 无连接 | 启动快,开销小 | 无状态,难追踪 | 广播、多播、短交互 |
| 不可靠 | 无重传,低延迟 | 可能丢包 | 实时音视频、监控数据 |
| 面向数据报 | 保留消息边界 | 需处理大包分片 | 小消息通信(<1400B) |
| 无拥塞控制 | 全速发送 | 可能加剧网络拥塞 | 内网可控环境 |
选择 UDP 还是 TCP?
-
要 可靠性、顺序、流量控制 → 选 TCP;
-
要 低延迟、高吞吐、容忍丢包 → 选 UDP,并在应用层补足缺失功能。
十一、Linux 网络栈核心:sk_buff 深度解析
1、引言:为什么需要 sk_buff?
在 Linux 内核中,网络数据包(报文)从网卡接收,经过多层协议处理(链路层 → 网络层 → 传输层 → 应用层),最终交付给用户程序。这个过程中,如何高效、安全地管理这些数据?
答案就是:struct sk_buff(通常简写为 skb)——它是 Linux 内核网络子系统中最核心的数据结构之一,用于表示一个网络数据包的完整生命周期。
类比理解:你可以把 sk_buff 想象成“快递包裹”——它不仅包含货物(有效载荷),还记录了收件人信息(IP/端口)、运输方式(协议头)、物流轨迹(指针偏移)等元数据。
总的来说,掌握 sk_buff = 掌握 Linux 网络之魂。sk_buff 不只是一个简单的结构体,它是整个 Linux 网络栈的灵魂所在。理解它的内存布局、指针机制和生命周期管理,是深入学习操作系统、网络编程、内核开发的必经之路。
2、sk_buff 结构详解
基本结构定义(简化版)
struct sk_buff {
/* 链表节点,用于将多个 skb 组织成队列 */
struct sk_buff *next;
struct sk_buff *prev;
/* 关联的 socket,标识该数据属于哪个连接或套接字 */
struct sock *sk;
/* 时间戳、设备信息等上下文 */
struct sk_buff_timestamp timestamp;
struct net_device *dev; // 接收/发送设备
struct net_device *input_dev; // 入口设备
/* 协议头联合体(union):支持多种协议 */
union {
struct tcphdr *th; // TCP 头
struct udphdr *uh; // UDP 头
struct icmp_hdr *icmph; // ICMP 头
struct igmphdr *igmph; // IGMP 头
struct iphdr *iph; // IPv4 头
struct ipv6hdr *ipv6h; // IPv6 头
unsigned char *raw; // 原始指针
} h;
union {
struct iphdr *iph; // IP 层头
struct ipv6hdr *ipv6h;
struct arphdr *arph;
unsigned char *raw;
} nh; // network header
union {
unsigned char *raw;
} mac; // MAC 层头
/* 目标路由信息 */
struct dst_entry *dst;
struct sec_path *sp;
/* 数据区相关指针(关键!)*/
unsigned int truesize;
atomic_t users;
unsigned char *head; // 缓冲区起始地址
unsigned char *data; // 当前数据起始位置(可变)
unsigned char *tail; // 当前数据末尾位置
unsigned char *end; // 缓冲区结束地址
};3、sk_buff 内存布局详解(图解说明)
内存空间划分
| 区域 | 说明 |
|---|---|
head |
缓冲区的物理起始地址,固定不变 |
data |
当前指向的数据起始位置,可动态移动 |
tail |
当前已使用数据的结尾位置 |
end |
缓冲区的物理结束地址 |
核心思想:通过 data 和 tail 指针控制“视窗”,实现对同一块内存的不同解读。
图形化展示
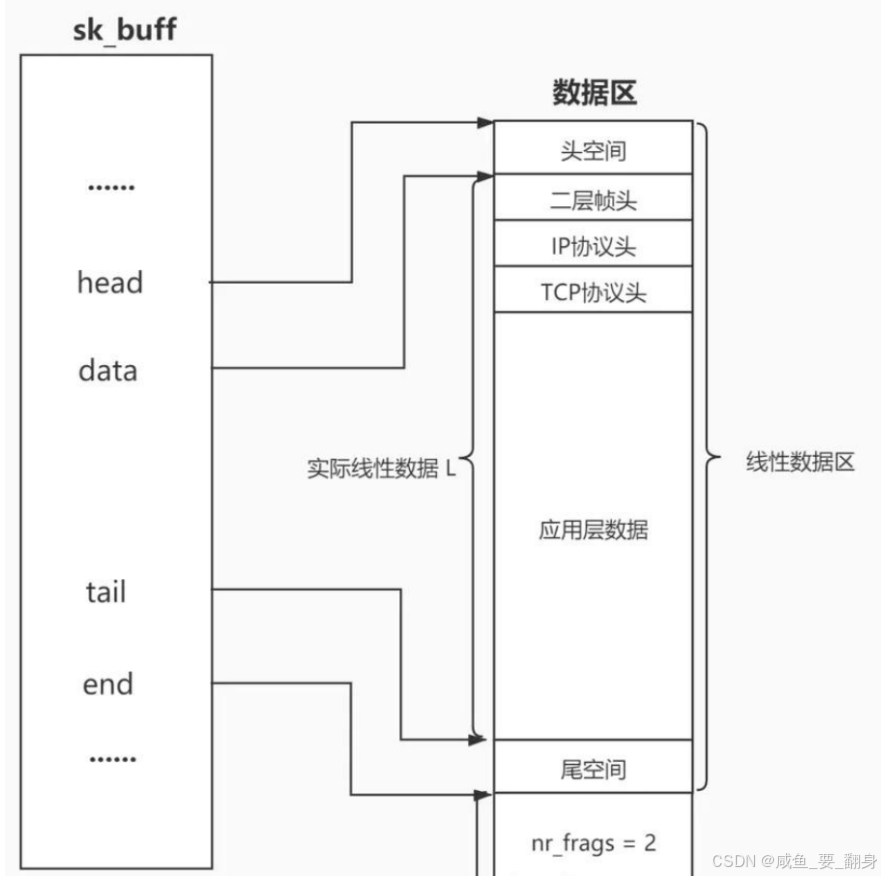
-
头空间:存放链路层、网络层、传输层的头部信息。
-
线性数据区:实际存储的数据部分,包括应用层数据。
-
尾空间:预留扩展空间,可用于添加新头部或扩容。
4、封装与解包的本质:移动 data 指针!
关键洞见
所谓的“封装”和“解包”,本质就是移动 data 指针在缓冲区中的指向!(可以反映出对应层的协议长度!!!)
示例流程:
-
接收数据:
-
网卡收到原始帧 → 放入
sk_buff的data开始处。 -
此时
data指向 MAC 头。
-
-
逐层解析(自底向上):
-
解析 MAC 头 → 移动
data指针跳过 MAC 头长度。 -
解析 IP 头 → 移动
data指针跳过 IP 头长度。 -
解析 TCP/UDP 头 → 移动
data指针跳过传输层头。 -
最终
data指向应用层数据(如 HTTP 请求体)。
-
-
发送数据(自顶向下):
-
应用层数据放在
data开始处。 -
添加 TCP 头 →
data向前移动,腾出空间。 -
添加 IP 头 →
data再次前移。 -
添加 MAC 头 →
data再次前移。
-
注意:data 是逻辑起点,而 head 是物理起点。data 可以在 [head, tail] 范围内滑动。
5、sk_buff 的典型应用场景
1. 协议栈分层处理
每层协议都通过调整 data 指针来访问自己的头部,并利用 nh, h 等联合体字段快速提取协议头。例如:
struct udphdr *udp_header = (struct udphdr *)skb->data;此时 skb->data 已经跳过了所有前面的头部,直接指向 UDP 头。
2. 内存复用与零拷贝优化
-
sk_buff可以引用外部内存(如 DMA 缓冲区),避免频繁复制。 -
使用
skb_clone()实现浅拷贝,提升性能。 -
支持分片(fragmentation)和拼接(reassembly)。
3. 队列管理
-
多个
sk_buff构成链表(通过next/prev字段)。 -
在接收队列(如
sock->sk_receive_queue)中排队等待上层处理。 -
发送时也通过队列调度。
6、OS 如何管理大量报文?——sk_buff 的角色
提问:如果应用层正在解析报文,会影响 OS 读取吗?
答案:不会影响!原因如下:
-
分离机制:
-
应用层调用
recv()读取数据时,内核会将sk_buff中的有效载荷复制到用户空间。 -
原始
sk_buff仍保留在内核中,供后续处理(如统计、日志、防火墙规则等)。
-
-
引用计数(
users字段):-
atomic_t users记录有多少实体正在使用该sk_buff。 -
只有当
users == 0且无引用时,才会释放内存。
-
-
并发安全:所有操作都加锁保护(如
spinlock),保证多线程环境下的安全性。 -
缓存池机制:内核预分配
sk_buff缓存池(slab allocator),提高分配效率。
7、重要概念总结
| 概念 | 说明 |
|---|---|
sk_buff |
内核网络数据包的核心容器 |
data 指针 |
动态滑动,决定当前“看到”的数据起点 |
head / end |
物理内存边界 |
tail |
当前数据末尾 |
nh, h |
协议头联合体,支持多种协议 |
sk |
关联的 socket,绑定具体连接 |
dst |
路由目标信息 |
users |
引用计数,控制内存生命周期 |
8、扩展知识:sk_buff 与现代网络架构
-
eBPF & XDP:可以在
sk_buff创建之前就对其进行拦截和处理(如在驱动层),实现高性能过滤。 -
Netfilter:基于
sk_buff实现防火墙、NAT、包过滤等功能。 -
TCP Fast Open、TSO/LRO 等高级特性也都依赖于
sk_buff的灵活操作。

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)